系统学习Pytorch笔记一:Pytorch的数据载体张量与线性回归
系统学习Pytorch笔记一:Pytorch的数据载体张量与线性回归
- Pytorch的数据载体张量与线性回归
-
- 背景
- 张量的简介与创建
-
- 张量的简介
-
- 1、张量的基本概念
- 2、Tensor与Variable
- 张量的创建
-
- 1、直接创建张量
- 2、通过numpy数组来创建
- 3、依据数值创建
- 4、依概率分布创建张量
- 张量的操作
-
- 张量的基础操作
-
- 1、张量的拼接
- 2、张量的切分
- 3、张量的索引
- 4、张量的变换
- 5、其他
- 张量的数学运算
-
- 1、标量运算
- 2、向量运算
- 矩阵运算
- 线性回归模型
- 总结
Pytorch的数据载体张量与线性回归
背景
学习知识先有框架(至少先知道有啥东西)然后再通过实战(各个东西具体咋用)来填充这个框架。 而这个系列的目的就是在脑海中先建一个Pytorch的基本框架出来。关于系统学习Pytorch,逻辑上就是按照机器学习的那五大步骤进行的, 步骤为:数据模块 -> 模型模块 -> 损失函数 -> 优化器 -> 迭代训练。本篇文章主要学习一下Pytorch中数据载体:张量及相关操作。
张量的简介与创建
pytorch中的数据结构——Tensor,Tensor是PyTorch中最基础的概念。主要介绍张量的概念和属性,如data, device, dtype等,并介绍tensor的基本创建方法,如直接创建、依数值创建和依概率分布创建等。
张量的简介
1、张量的基本概念
张量其实是一个多维数组,它是标量、向量、矩阵的高维拓展
2、Tensor与Variable
在Pytorch0.4.0版本之后其实Variable已经并入Tensor, Variable这个数据类型到底是什么。
Variable是torch.autograd中的数据类型
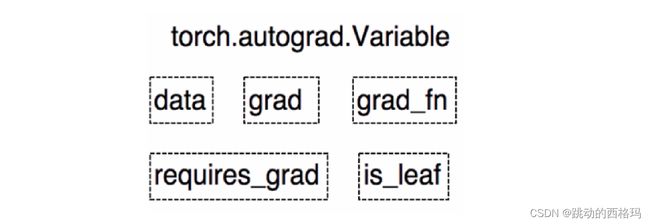
Variable有下面的5个属性
- data: 被包装的Tensor
- grad: data的梯度
- grad_fn: fn表示function的意思,记录我么创建的创建张量时用到的方法,比如说加法,乘法,这个操作在求导过程需要用到,Tensor的Function, 是自动求导的关键
- requires_grad: 指示是否需要梯度, 有的不需要梯度
- is_leaf: 指示是否是叶子节点(张量)
这些属性都是为了张量的自动求导而设置的, 从Pytorch0.4.0版开始,Variable并入了Tensor, 看看张量里面的属性:
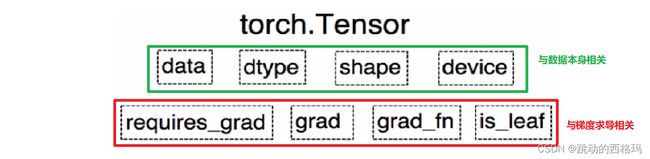
可以发现,如今版本里面的Tensor共有8个属性,上面四个与数据本身相关,下面四个与梯度求导相关。 其中有五个是Variable并入过来的,而还有三个属性没有说
- dtype: 张量的数据类型, 如torch.FloatTensor, torch.cuda.FloatTensor, 用的最多的一般是float32和int64(torch.long)
- shape: 张量的形状, 如(64, 3, 224, 224)
- device: 张量所在的设备, GPU/CPU, 张量放在GPU上才能使用加速。
张量的创建
1、直接创建张量
torch.Tensor(): 功能: 从data创建Tensor

这里的data,就是我们的数据,可以是list,也可以是ndarray。 dtype这个是指明数据类型, 默认与data的一致。 device是指明所在的设备, requires_grad是是否需要梯度, 在搭建神经网络的时候需要求导的那些参数这里要设置为true。 pin_memory是否存于锁页内存,这个设置为False就可以。
arr = np.ones((3, 3))
print('ndarry的数据类型:', arr.dtype)
t = torch.tensor(arr, device='cuda')
print(t)
## 结果如下:
ndarry的数据类型: float64
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], device='cuda:0', dtype=torch.float64)
2、通过numpy数组来创建
torch.from_numpy(ndarry): 从numpy创建tensor
注意:这个创建的Tensor与原ndarray共享内存, 当修改其中一个数据的时候,另一个也会被改动。
arr = np.array([[1, 2, 3], [4, 5, 6]])
t = torch.from_numpy(arr)
print(arr, '\n',t)
arr[0, 0] = 0
print('*' * 10)
print(arr, '\n',t)
t[1, 1] = 100
print('*' * 10)
print(arr, '\n',t)
## 结果:
[[1 2 3]
[4 5 6]]
tensor([[1, 2, 3],
[4, 5, 6]], dtype=torch.int32)
**********
[[0 2 3]
[4 5 6]]
tensor([[0, 2, 3],
[4, 5, 6]], dtype=torch.int32)
**********
[[ 0 2 3]
[ 4 100 6]]
tensor([[ 0, 2, 3],
[ 4, 100, 6]], dtype=torch.int32)
3、依据数值创建
torch.zeros(): 依size创建全0的张量

layout这个是内存中的布局形式, 一般采用默认就可以。 这个out,表示输出张量,就是再把这个张量赋值给别的一个张量,但是这两个张量是一样的,指的同一个内存地址。
out_t = torch.tensor([1])
t = torch.zeros((3, 3), out=out_t)
print(out_t, '\n', t)
print(id(t), id(out_t), id(t) == id(out_t)) # 这个看内存地址
## 结果:
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
2575719258696 2575719258696 True
torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False) : 这个是创建与input同形状的全0张量
除了全0张量, 还可以创建全1张量, 用法和上面一样,torch.ones(), torch.ones_like(), 还可以自定义数值张量:torch.full(), torch.full_like()

torch.arange(): 创建等差的1维张量,数值区间[start, end), 注意这是右边开,取不到最后的那个数。
torch.linspace(): 创建均分的1维张量, 数值区间[start, end] 注意这里都是闭区间,和上面的区分
torch.logspace(): 创建对数均分数列
torch.eye(): 创建单位对角矩阵, 默认是方阵
4、依概率分布创建张量
torch.normal():生成正态分布(高斯分布), 这个使用的比较多
torch.randn(), torch.randn_like():生成标准正态分布
torch.rand(), rand_like(): 在[0,1)生成均匀分布
torch.randint(), torch.randint_like(): 区间[low,hight)生成整数均匀分布
torch.randperm(n): 生成从0 - n-1的随机排列, n是张量的长度, 经常用来生成一个乱序索引。
torch.bernoulli(input): 以input为概率,生成伯努利分布(0-1分布,两点分布), input: 概率值
张量的操作
张量的基础操作
张量的拼接,切分,索引和变换以及数学运算
1、张量的拼接
torch.cat(tensors, dim=0, out=None): 将张量按维度dim进行拼接, tensors表示张量序列, dim要拼接的维度torch.stack(tensors, dim=0, out=None): 在新创建的维度dim上进行拼接, tensors表示张量序列, dim要拼接的维度
# 张量的拼接
t = torch.ones((2, 3))
print(t)
t_0 = torch.cat([t, t], dim=0) # 行拼接
t_1 = torch.cat([t, t], dim=1) # 列拼接
print(t_0, t_0.shape)
print(t_1, t_1.shape)
# 结果:
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]) torch.Size([4, 3])
tensor([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]]) torch.Size([2, 6])
.cat是在原来的基础上根据行和列,进行拼接,浮点数类型拼接可以,long类型拼接也可以。
# long类型张量的拼接
t = torch.ones((2, 3),dtype=torch.long)
print(t)
tensor([[1, 1, 1],
[1, 1, 1]])
t_0 = torch.cat([t, t], dim=0) # 行拼接
t_1 = torch.cat([t, t], dim=1) # 列拼接
print(t_0, t_0.shape)
print(t_1, t_1.shape)
tensor([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]]) torch.Size([4, 3])
tensor([[1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1]]) torch.Size([2, 6])
# 浮点数类型张量与long类型张量拼接
# 张量的拼接
t1 = torch.ones((2, 3),dtype=torch.float64)
print(t1)
print(t)
t_0 = torch.cat([t, t1], dim=0) # 行拼接
print(t_0, t_0.shape)
tensor([[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
tensor([[1, 1, 1],
[1, 1, 1]])
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64) torch.Size([4, 3])
t_stack = torch.stack([t,t,t], dim=0)
print(t_stack)
print(t_stack.shape)
t_stack1 = torch.stack([t, t, t], dim=1)
print(t_stack1)
print(t_stack1.shape)
## 结果:
tensor([[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]])
torch.Size([3, 2, 3])
tensor([[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]])
torch.Size([2, 3, 3])
.stack是根据给定的维度新增了一个新的维度,在这个新维度上进行拼接。
2、张量的切分
torch.chunk(input, chunks, dim=0): 将张量按维度dim进行平均切分, 返回值是张量列表,注意,如果不能整除, 最后一份张量小于其他张量。 chunks代表要切分的维度。torch.split(tensor, split_size_or_sections, dim=0): 这个也是将张量按维度dim切分,但是这个更加强大, 可以指定切分的长度, split_size_or_sections为int时表示每一份的长度, 为list时,按list元素切分。
a = torch.ones((2, 7)) # 7
list_of_tensors = torch.chunk(a, dim=1, chunks=3) # 第一个维度切成三块, 那么应该是(2,3), (2,3), (2,1) 因为7不能整除3,所以每一份应该向上取整,最后不够的有多少算多少
print(list_of_tensors)
for idx, t in enumerate(list_of_tensors):
print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
## 结果:
(tensor([[1., 1., 1.],
[1., 1., 1.]]), tensor([[1., 1., 1.],
[1., 1., 1.]]), tensor([[1.],
[1.]]))
第1个张量:tensor([[1., 1., 1.],
[1., 1., 1.]]), shape is torch.Size([2, 3])
第2个张量:tensor([[1., 1., 1.],
[1., 1., 1.]]), shape is torch.Size([2, 3])
第3个张量:tensor([[1.],
[1.]]), shape is torch.Size([2, 1])
.chunk切分的规则就是提供张量,切分的维度和几份, 比如三份, 先计算每一份的大小,也就是这个维度的长度除以三,然后上取整,就开始沿着这个维度切,最后不够一份大小的,就是最后的大小。
# split
t = torch.ones((2, 5))
list_of_tensors = torch.split(t, [2, 1, 2], dim=1) # [2 , 1, 2], 这个要保证这个list的大小正好是那个维度的总大小,这样才能切
for idx, t in enumerate(list_of_tensors):
print("第{}个张量:{}, shape is {}".format(idx+1, t, t.shape))
## 结果
第1个张量:tensor([[1., 1.],
[1., 1.]]), shape is torch.Size([2, 2])
第2个张量:tensor([[1.],
[1.]]), shape is torch.Size([2, 1])
第3个张量:tensor([[1., 1.],
[1., 1.]]), shape is torch.Size([2, 2])
.split这个函数的功能更加强大,它可以指定每一份的长度,只要传入一个列表即可,或者也有一个整数,表示每一份的长度,这个就根据每一份的长度先切着。 不过列表的那个好使,可以自己指定每一块的长度,但是注意一下,这个长度的总和必须是维度的那个总长度才用办法切。
3、张量的索引
torch.index_select(input, dim, index, out=None): 在维度dim上,按index索引数据,返回值,以index索引数据拼接的张量。torch.masked_select(input, mask, out=None): 按mask中的True进行索引,返回值:一维张量。 input表示要索引的张量, mask表示与input同形状的布尔类型的张量。 这种情况在选择符合某些特定条件的元素的时候非常好使, 注意这个是返回一维的张量。
t = torch.randint(0, 9, size=(3, 3)) # 从0-8随机产生数组成3*3的矩阵
print(t)
idx = torch.tensor([0, 2], dtype=torch.long) # 这里的类型注意一下,要是long类型
t_select = torch.index_select(t, dim=1, index=idx) #第0列和第2列拼接返回
print(t_select)
## 结果:
tensor([[3, 7, 3],
[4, 3, 7],
[5, 8, 0]])
tensor([[3, 3],
[4, 7],
[5, 0]])
.index_select: 按照索引查找 需要先指定一个Tensor的索引量,然后指定类型是long的
mask = t.ge(5) # le表示<=5, ge表示>=5 gt >5 lt <5
print("mask: \n", mask)
t_select1 = torch.masked_select(t, mask) # 选出t中大于5的元素
print(t_select1)
## 结果:
mask:
tensor([[False, True, False],
[False, False, True],
[ True, True, False]])
tensor([7, 7, 5, 8])
.masked_select: 就是按照值的条件进行查找,需要先指定条件作为mask
4、张量的变换
torch.reshape(input, shape): 变换张量的形状,这个很常用,input表示要变换的张量,shape表示新张量的形状。 但注意,当张量在内存中是连续时, 新张量与input共享数据内存torch.transpose(input, dim0, dim1): 交换张量的两个维度, 矩阵的转置常用, 在图像的预处理中常用, dim0要交换的维度, dim1表示要交换的问题
# torch.reshape
t = torch.randperm(8) # randperm是随机排列的一个函数
print(t)
t_reshape = torch.reshape(t, (-1, 2, 2)) # -1的话就是根据后面那两个参数,计算出-1这个值,然后再转
print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
t[0] = 1024
print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
print("t.data 内存地址:{}".format(id(t.data)))
print("t_reshape.data 内存地址:{}".format(id(t_reshape.data))) # 这个注意一下,两个是共内存的
## 结果:
tensor([2, 4, 3, 1, 5, 6, 7, 0])
t:tensor([2, 4, 3, 1, 5, 6, 7, 0])
t_reshape:
tensor([[[2, 4],
[3, 1]],
[[5, 6],
[7, 0]]])
t:tensor([1024, 4, 3, 1, 5, 6, 7, 0])
t_reshape:
tensor([[[1024, 4],
[ 3, 1]],
[[ 5, 6],
[ 7, 0]]])
t.data 内存地址:1556953167336
t_reshape.data 内存地址:1556953167336
# torch.transpose
t = torch.rand((2, 3, 4)) # 产生0-1之间的随机数
print(t)
t_transpose = torch.transpose(t, dim0=0, dim1=2) # c*h*w h*w*c, 这表示第0维和第2维进行交换
print("t shape:{}\nt_transpose shape: {}".format(t.shape, t_transpose.shape))
## 结果:
tensor([[[0.7480, 0.5601, 0.1674, 0.3333],
[0.4648, 0.6332, 0.7692, 0.2147],
[0.7815, 0.8644, 0.6052, 0.3650]],
[[0.2536, 0.1642, 0.2833, 0.3858],
[0.8337, 0.6173, 0.3923, 0.1878],
[0.8375, 0.2109, 0.4282, 0.4974]]])
t shape:torch.Size([2, 3, 4])
t_transpose shape: torch.Size([4, 3, 2])
tensor([[[0.7480, 0.2536],
[0.4648, 0.8337],
[0.7815, 0.8375]],
[[0.5601, 0.1642],
[0.6332, 0.6173],
[0.8644, 0.2109]],
[[0.1674, 0.2833],
[0.7692, 0.3923],
[0.6052, 0.4282]],
[[0.3333, 0.3858],
[0.2147, 0.1878],
[0.3650, 0.4974]]])
5、其他
torch.t(input): 2维张量的转置, 对矩阵而言,相当于torch.transpose(inpuot, 0,1)
# torch.squeeze
t = torch.rand((1, 2, 3, 1))
t_sq = torch.squeeze(t)
t_0 = torch.squeeze(t, dim=0)
t_1 = torch.squeeze(t, dim=1)
print(t.shape) # torch.Size([1, 2, 3, 1])
print(t_sq.shape) # torch.Size([2, 3])
print(t_0.shape) # torch.Size([2, 3, 1])
print(t_1.shape) # torch.Size([1, 2, 3, 1])
torch.squeeze(input, dim=None, out=None): 压缩长度为1的维度, dim若为None,移除所有长度为1的轴,若指定维度,当且仅当该轴长度为1时可以被移除
torch.unsqueeze(input, dim, out=None): 依据dim扩展维度
张量的数学运算
1、标量运算
Pytorch中提供了丰富的数学运算,可以分为三大类: 加减乘除, 对数指数幂函数,三角函数

torch.add(input, alpha=1, other, out=None): 逐元素计算input+alpha * other。 注意人家这里有个alpha,叫做乘项因子。类似权重的个东西。 这个东西让计算变得更加简洁, 比如线性回归我们知道有个 y = w x + b y = wx + b y=wx+b, 在这里直接一行代码torch.add(b, w, x)就搞定。
类似的还有两个方法:

2、向量运算
向量运算符只在一个特定轴上运算,将一个向量映射到一个标量或者另外一个向量。
统计值
a = torch.arange(1,10).float()
print(torch.sum(a))
print(torch.mean(a))
print(torch.max(a))
print(torch.min(a))
print(torch.prod(a)) #累乘
print(torch.std(a)) #标准差
print(torch.var(a)) #方差
print(torch.median(a)) #中位数
累加累乘
#cum扫描
a = torch.arange(1,10)
print(torch.cumsum(a,0)) # 累加
print(torch.cumprod(a,0)) # 累乘
print(torch.cummax(a,0).values)
print(torch.cummax(a,0).indices)
print(torch.cummin(a,0))
张量排序
#torch.sort和torch.topk可以对张量排序
a = torch.tensor([[9,7,8],[1,3,2],[5,6,4]]).float()
print(torch.topk(a,2,dim = 0),"\n")
print(torch.topk(a,2,dim = 1),"\n")
print(torch.sort(a,dim = 1),"\n")
#利用torch.topk可以在Pytorch中实现KNN算法
矩阵运算
矩阵必须是二维的。类似torch.tensor([1,2,3])这样的不是矩阵。
矩阵运算包括:矩阵乘法,矩阵转置,矩阵逆,矩阵求迹,矩阵范数,矩阵行列式,矩阵求特征值,矩阵分解等运算
1、矩阵乘法
#矩阵乘法
a = torch.tensor([[1,2],[3,4]])
b = torch.tensor([[2,0],[0,2]])
print(a@b) #等价于torch.matmul(a,b) 或 torch.mm(a,b)
2、转置
#矩阵转置
a = torch.tensor([[1.0,2],[3,4]])
print(a.t())
3、矩阵求逆
#矩阵逆,必须为浮点类型
a = torch.tensor([[1.0,2],[3,4]])
print(torch.inverse(a))
4、矩阵求迹
#矩阵求trace
a = torch.tensor([[1.0,2],[3,4]])
print(torch.trace(a))
5、求范数和行列式
#矩阵求范数
a = torch.tensor([[1.0,2],[3,4]])
print(torch.norm(a))
#矩阵行列式
a = torch.tensor([[1.0,2],[3,4]])
print(torch.det(a))
6、特征值和特征向量
#矩阵特征值和特征向量
a = torch.tensor([[1.0,2],[-5,4]],dtype = torch.float)
print(torch.eig(a,eigenvectors=True))
#两个特征值分别是 -2.5+2.7839j, 2.5-2.7839j
7、QR分解
#矩阵QR分解, 将一个方阵分解为一个正交矩阵q和上三角矩阵r
#QR分解实际上是对矩阵a实施Schmidt正交化得到q
a = torch.tensor([[1.0,2.0],[3.0,4.0]])
q,r = torch.qr(a)
print(q,"\n")
print(r,"\n")
print(q@r)
8、SVD分解
#矩阵svd分解
#svd分解可以将任意一个矩阵分解为一个正交矩阵u,一个对角阵s和一个正交矩阵v.t()的乘积
#svd常用于矩阵压缩和降维
a=torch.tensor([[1.0,2.0],[3.0,4.0],[5.0,6.0]])
u,s,v = torch.svd(a)
print(u,"\n")
print(s,"\n")
print(v,"\n")
print(u@torch.diag(s)@v.t())
#利用svd分解可以在Pytorch中实现主成分分析降维
线性回归模型

# 首先我们得有训练样本X,Y, 这里我们随机生成
x = torch.rand(20, 1) * 10
y = 2 * x + (5 + torch.randn(20, 1))
# 构建线性回归函数的参数
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True) # 这俩都需要求梯度
for iteration in range(100):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算loss
loss = (0.5 * (y-y_pred)**2).mean()
# 反向传播
loss.backward()
# 更新参数
b.data.sub_(lr * b.grad) # 这种_的加法操作时从自身减,相当于-=
w.data.sub_(lr * w.grad)
# 梯度清零
w.grad.data.zero_()
b.grad.data.zero_()
print(w.data, b.data)
总结
今天的学习内容结束, 下面简单的梳理一遍,其实小东西还是挺多的, 首先我们从Pytorch最基本的数据结构开始,认识了张量,说白了就是个多维数组,然后张量本身有很多的属性, 有关于数据本身的data, dtype, shape, device, 也有关于求导的requires_grad, grad, grad_fn, is_leaf。 然后学习了张量的创建方法, 比如直接创建,从数组创建,数值创建,按照概率创建等。 这里面涉及到了很多的创建函数tensor(), from_numpy(), ones(), zeros(), eye(), full(), arange(), linspace(), normal(), randn(), rand(), randint(), randperm()等等吧。
接着就是张量的操作部分, 有基本操作和数学运算, 基本操作部分有张量的拼接两个函数(.cat, .stack), 张量的切分两个函数(.chunk, .split), 张量的转置(.reshape, .transpose, .t), 张量的索引两个函数(.index_select, .masked_select)。 数学运算部分,也是很多数学函数,有加减乘除的,指数底数幂函数的,三角函数的很多。
下一篇文章将继续学习pytorch基本概念,如动态图、自动求导等知识。
参考:
[1]: http://meta.math.stackexchange.com/questions/5020/mathjax-basic-tutorial-and-quick-reference
[2]: https://mermaidjs.github.io/
[3]: https://zhongqiang.blog.csdn.net/article/details/105465136
[4]: http://adrai.github.io/flowchart.js/