自动驾驶之—LaneAF学习相关总结
0.前言:
最近在学习自动驾驶方向的东西,简单整理一些学习笔记,学习过程中发现宝藏up 手写AI
1. 概述
Laneaf思想是把后处理放在模型里面。重点在于理解vaf, haf,就是横向聚类:中心点,纵向聚类:利用vaf学到的单位向量去预测下一行中心点与haf预测到的当前中心点做匹配,根据距离error阈值判断是否属于同一个lane id。主要了解标签和decode,decode就是标签制作的逆过程,decode部分主要是cost代价矩阵理解,loss针对正负样本不平衡,可以使用OHEM或者focal loss。
2. 算法结构

使用DLA-34作为Backbone,网络输出二值的分割结果、Vertical Affinity Field(VAF)和Horizontal Affinity Field(HAF)。其中:Affinity Field. 亲和域
使用HAF、VAF,结合二值分割结果(三个头可以产生一个实例),能够在后处理中对任意数量的车道线进行聚类,得到多个车道线实例。
3. Affinity Field 构建
给定图像中的每个位置 ( x , y ) (x,y) (x,y),HAF和VAF为每个位置分配一个向量,将HAF记作 H → ( ⋅ , ⋅ ) \overset{\rightarrow}H(\cdot,\cdot) H→(⋅,⋅),将VAF记作 V → ( ⋅ , ⋅ ) \overset{\rightarrow}V(\cdot,\cdot) V→(⋅,⋅)。
AF的生成都是从最下面一行往上面扫描
使用ground truth构建HAF和VAF,将ground truth到HAF和VAF的映射函数分别记作 H → g t ( ⋅ , ⋅ ) \overset{\rightarrow}H_{gt}(⋅,⋅) H→gt(⋅,⋅)和 V → g t ( ⋅ , ⋅ ) \overset{\rightarrow}V_{gt}(⋅,⋅) V→gt(⋅,⋅)。
对于图像第 y y y行中车道线 l l l所包含的每个点 ( x i l , y ) (x_i^l, y) (xil,y),HAF由下式得到:
H → g t ( x i l , y ) = ( x − y l − x i l ∣ x − y l − x i l ∣ , y − y ∣ y − y ∣ ) T = ( x − y l − x i l ∣ x − y l − x i l ∣ , 0 ) T \overset{\rightarrow}H_{gt}(x^l_i , y) = (\frac{{\overset{-} x}^l_y − x^l _i} {|{\overset{-} x}^l_ y − x^ l_ i | }, \frac{y − y}{ |y − y|})^T = (\frac{{\overset{-} x}^l_ y − x^l_i} {|{\overset{-} x}^ l_ y − x ^l _i | }, 0 )^T H→gt(xil,y)=(∣x−yl−xil∣x−yl−xil,∣y−y∣y−y)T=(∣x−yl−xil∣x−yl−xil,0)T
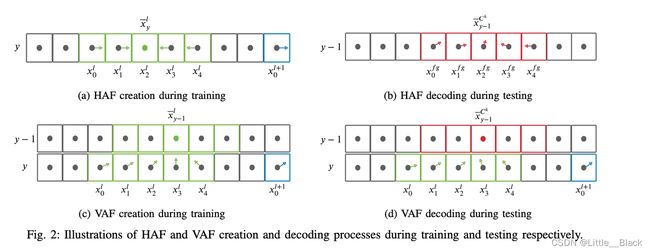
上式中的 x − y l \overset{-}x^l_y x−yl表示第 y y y行中属于车道线 l l l的所有点的横坐标平均值,求解HAF的过程如下图所示:

上图中绿色框表示属于车道线 l l l的点,蓝色框表示属于车道线 l + 1 l+1 l+1的点。箭头表示某个位置处HAF中的向量。
对于图像第 y y y行中属于车道线 l l l的每个点 ( x i l , y ) (x^l_i,y) (xil,y),VAF由下式得到:
V → g t ( x i l , y ) = ( x − y − 1 l − x i l ∣ x − y − 1 l − x i l ∣ , y − 1 − y ∣ y − 1 − y ∣ ) T = ( x − y − 1 l − x i l ∣ x − y − 1 l − x i l ∣ , − 1 ) T \overset{\rightarrow}V_{gt}(x^l_i , y) = (\frac{{\overset{-} x}^l_{y-1} − x^l _i} {|{\overset{-} x}^l_ {y-1} − x^ l_ i | }, \frac{y -1− y}{ |y -1− y|})^T = (\frac{{\overset{-} x}^l_ {y-1} − x^l_i} {|{\overset{-} x}^ l_ {y-1} − x ^l _i | }, -1)^T V→gt(xil,y)=(∣x−y−1l−xil∣x−y−1l−xil,∣y−1−y∣y−1−y)T=(∣x−y−1l−xil∣x−y−1l−xil,−1)T
上式中的 x − y − 1 l \overset{-}x^l_{y-1} x−y−1l示第 y − 1 y-1 y−1行中属于车道线 l l l的所有点的横坐标平均值。求解VAF的过程如下图所示:
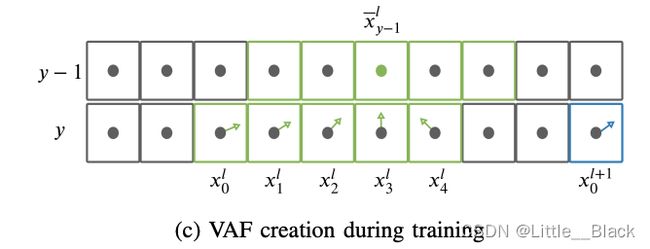
需要注意的是,VAF中每行的向量指向上一行中属于该车道线实例的点的平均位置。
- HAF parsing
水平方向的聚类就是逐行根据点的像素判断,直接根据两个邻近像素的HAF是否符合如下规则来判断是否属于同一个群组(cluster), 当然邻近像素如果相隔的位置超过设定的阈值,也会被分配到不同的cluster。
只有当前面像素指向左并且当前像素指向右时,才会为当前像素重新分配一个cluster,令 H → p r e d \overset{\rightarrow}H_{pred} H→pred表示HAF的预测结果, i i i表示列, y y y表示行。
c h a f ∗ ( x i f g , y − 1 ) = { C k + 1 i f H ⃗ p r e d ( x i − 1 f g , y − 1 ) 0 ≤ 0 ∧ H ⃗ p r e d ( x i f g , y − 1 ) 0 > 0 , C k otherwise, c_{haf}^*(x_i^{fg},y-1)=\begin{cases}C^{k+1}&\mathrm{if}\quad\vec{H}_{pred}(x_{i-1}^{fg},y-1)_0\leq0\\&\wedge\vec{H}_{pred}(x_i^{fg},y-1)_0>0,\\C^k&\text{otherwise,}&\end{cases} chaf∗(xifg,y−1)=⎩ ⎨ ⎧Ck+1CkifHpred(xi−1fg,y−1)0≤0∧Hpred(xifg,y−1)0>0,otherwise, - VAF parsing
那由haf聚类的clusters是怎么在行与行之间进行匹配呢?
这个时候VAF就派上用场了。前面我们提到过,VAF表示指向上一行车道线实例中心像素的单位向量,那么上一行车道线实例中心像素可以由两种方式计算得到,第一种方式是直接对cluster取平均,另外一种方式就是由active lane里的end points加上向量表示的平移得到,只不过网络预测出来的HAF是单位向量,需要考虑向量的模长而已。那这两种方式计算出来的结果都表示上一行车道线实例中心像素,它们之间的距离即可表示前面的误差。下面公式是在计算每一个线头坐标点结合vaf推算出来的点坐标与当前行的聚类点之间的dist_error。
d C k ( l ) = 1 N y l ∑ i = 0 N y l − 1 ∣ ∣ ( x ‾ C k , y − 1 ) ⊺ − ( x i l , y ) ⊺ − V ⃗ p r e d ( x i l , y ) ⋅ ∣ ∣ ( x ‾ C k , y − 1 ) ⊺ − ( x i l , y ) ⊺ ∣ ∣ ∣ ∣ \begin{aligned} d^{C^k}(l)=& \frac1{N_y^l}\sum_{i=0}^{N_y^l-1}\left|\left|(\overline{x}^{C^k},y-1)^\intercal-(x_i^l,y)^\intercal\right.\right. \\ &-\vec{V}_{pred}(x_i^l,y)\cdot||(\overline{x}^{C^k},y-1)^\intercal-(x_i^l,y)^\intercal||\bigg|\bigg| \end{aligned} dCk(l)=Nyl1i=0∑Nyl−1 (xCk,y−1)⊺−(xil,y)⊺−Vpred(xil,y)⋅∣∣(xCk,y−1)⊺−(xil,y)⊺∣∣ - label generate code
由于网络的AF分支会预测每个像素点的HAF和VAF,因此Affinity Fields需要作为ground truth来监督这一过程。算法流程也很简单,自底向上逐行扫描,在每一行对属于当前车道线实例的像素点按照计算HAF和VAF,即为当前像素点的Affinity Fields编码。
VAF,HAF,label,模型监督三者,知道三者可以反向求解
这段代码定义了一个名为generateAFs的函数,它的目的是为输入的车道标签图生成锚帧(AFs)。代码中涉及两种锚帧:垂直锚帧(VAF)和水平锚帧(HAF)。
def generateAFs(label, viz=False):
# 创建透视场数组
num_lanes = np.amax(label) # 获取车道线的数量
VAF = np.zeros((label.shape[0], label.shape[1], 2)) # 垂直透视场
HAF = np.zeros((label.shape[0], label.shape[1], 1)) # 水平透视场
# 对每条车道线进行循环处理
for l in range(1, num_lanes+1):
# 初始化先前的行和列值
prev_cols = np.array([], dtype=np.int64)
prev_row = label.shape[0]
# 从下到上解析每一行
for row in range(label.shape[0]-1, -1, -1):
# [0] :np.where 返回一个元组,其每一维都是一个数组,表示该维度上满足条件的索引。
# 在这里,我们只关心列索引,所以我们取出这个元组的第一个元素
cols = np.where(label[row, :] == l)[0] # 获取当前行的前景列值(即车道线位置)
# 为每个列值生成水平方向向量
for c in cols:
if c < np.mean(cols):
HAF[row, c, 0] = 1.0 # 向右指示
elif c > np.mean(cols):
HAF[row, c, 0] = -1.0 # 向左指示
else:
HAF[row, c, 0] = 0.0 # 保持不变
# 检查先前的列和当前的列是否都非空
if prev_cols.size == 0: # 如果没有先前的行/列,更新并继续
prev_cols = cols
prev_row = row
continue
if cols.size == 0: # 如果当前没有列,继续
continue
col = np.mean(cols) # 计算列的均值
# 为先前的列生成垂直方向向量
for c in prev_cols:
# 计算方向向量的位置
vec = np.array([col - c, row - prev_row], dtype=np.float32)
# 单位标准化
vec = vec / np.linalg.norm(vec) # 标准化为单位向量 # 模
VAF[prev_row, c, 0] = vec[0]
VAF[prev_row, c, 1] = vec[1] # 具有像两方向的增值
# 使用当前的行和列值更新先前的行和列值
prev_cols = cols
prev_row = row
decode code
cost矩阵:
当提到“建立每条线与头坐标与当前行聚类点之间的cost矩阵”,这很有可能是在一个场景中,例如图像或传感器数据处理,你想要在平面上追踪或匹配多个线对象。让我为你详细解释一下。
背景概念
- 线对象:这可能是在图像或其他数据源中检测到的直线或曲线。
- 头坐标:每条线的起始点或参考点。
- 当前行的聚类点:这可能是在某一特定行(水平方向)上检测到的点,它们可能是由于某种特性(例如颜色、强度等)而被聚类在一起的。
- 目的:为了确定哪条线与哪个聚类点最为匹配或最为接近,你需要计算每个线与聚类点之间的距离或相似度。Cost矩阵就是用来存储这些计算结果的。
- 矩阵形状:假设你有m条线和n个聚类点,那么你的cost矩阵将是一个m x n的矩阵。
- 元素的值:矩阵中的每个元素代表一条线与一个聚类点之间的“cost”。这个“cost”可以是他们之间的距离、差异或其他度量方式。较低的cost意味着线和点之间的匹配度较高;较高的cost意味着匹配度较低。
应用
一旦你有了cost矩阵,你可以使用一些优化算法(如匈牙利算法)来确定最佳的匹配方式,这样每条线都将与一个聚类点匹配,以最小化总体的cost。
简而言之,通过构建一个cost矩阵,你可以量化每条线与每个聚类点之间的关系,并使用这个矩阵来找出最佳的匹配方案。

AF loss
语义分割图:分类损失+iou 损失;
AF损失: 回归损失;
L B C E = − 1 N ∑ i [ w ⋅ t i ⋅ l o g ( o i ) + ( 1 − t i ) ⋅ l o g ( 1 − o i ) ] L_{BCE}=-\frac1N\sum_i\left[w\cdot t_i\cdot log(o_i)+(1-t_i)\cdot log(1-o_i)\right] LBCE=−N1i∑[w⋅ti⋅log(oi)+(1−ti)⋅log(1−oi)]
L I o U = 1 N ∑ i [ 1 − t i ⋅ o i t i + o i − t i ⋅ o i ] L_{IoU}=\frac1N\sum_i\left[1-\frac{t_i\cdot o_i}{t_i+o_i-t_i\cdot o_i}\right] LIoU=N1i∑[1−ti+oi−ti⋅oiti⋅oi]
L A F = 1 N f g ∑ i [ ∣ t i h a f − o i h a f ∣ + ∣ t i v a f − o i v a f ∣ ] L_{AF}=\frac1{N_{fg}}\sum_i\left[|t_i^{haf}-o_i^{haf}|+|t_i^{vaf}-o_i^{vaf}|\right] LAF=Nfg1i∑[∣tihaf−oihaf∣+∣tivaf−oivaf∣]