Redis
一、常识
1、内存和硬盘对比
磁盘:
- 寻址:毫秒ms
- 硬盘带宽:G/M
内存:
- 寻址:纳秒ns
- 硬盘带宽:很大
秒>毫秒>微秒>纳秒
磁盘比内存在寻址上慢了10W倍
2、I/O buffer的成本问题
磁盘划分:从磁盘到磁道,到扇区,再到每个扇区512byte,划分成一个一个的区域后,索引变大。
格式化的时候,会有个对其选择,一般选4k,选择后,通过操作系统读数据时,无论你读多少数据,一次都是读取4K
问题:java读取文件,文件变大,速度变慢,为什么?
硬盘I/O成为瓶颈
3、mysql的存储
mysql里也是使用文件存储的,取数据的时候也是按data page(4K)取的。索引就是把“相近”的数据存一起,B+ Tree的树干是存在内存中的。索引目的就是减少IO次数。
问题:数据表很大的时候,性能下降?
如果表有索引的话
- 增删改变慢,因为要维护索引;
- 查询速度分情况
- 1个或少量查询依然很快
- 并发的的时候会受硬盘带宽影响速度
4、为何使用redis
常识:数据在内存和磁盘体积不一样
SAP HANA 是内存级别的关系型数据库,收费的。那么买不起内存级别的关系型数据库怎么办,这时候可以用缓存。(memcached、redis)
memcached、redis的一点区别:
- memcached的value没有类型的概念
- redis的value有String、hashes、Lists、Sets、sorted sets
问题:为什么redis要有数据类型,我直接使用json不就好了?
场景:client要取value中的某个值,如果用json,那么要把value一下全取出来返回client,并且再写代码自己解析。
使用redis的数据类型的好处:redis提供了对应数据结构的方法,我们不需要自己写代码解析,并且不需要把整个value返回给client,减少了网络IO。
用大数据里词汇来说:计算向数据移动
5、官网
数据库引擎排名、介绍
中文官网
官网
二、下载安装
可以使用wget来下载
yum install wget
wget https://download.redis.io/releases/redis-6.2.6.tar.gz
# 进入目录执行make,make会找本目录下的MakeFile文件,成功后src下会生成可执行文件
make
# 执行make后报错 缺少cc(c语言环境)
# g是单词“全局”的缩写
yum install gcc
# 清理之前make报错的后的垃圾文件, 然后再make
make distclean
# 启动
./redis-server
# 安装到指定目录 执行完后到该目录下,可以看到只有执行文件,就没有和源码混在一起
make install PREFIX=/opt/yuchao/redis6
#添加redis的环境变量
vi /etc/profile
# 添加一行
export REDIS_HOME=/opt/yuchao/redis6
export PATH=$PATH:$REDIS_HOME/bin
#更新配置
source /etc/profile
#查看path
echo $PATH
# 把它变成一个服务 utils下有个脚本,执行即可
cd utils
./install_server.sh
# 执行完后看输出的信息,写了在/etc/init.d/下创建了redis_6379的脚本。并启动了服务
#查看服务状态
service redis_6379 status
#使用redis-server启动的时候要加上这个配置文件
redis-server /etc/redis/6379.conf
#退出
redis-cli shutdown
下载下来解压后是c语言源码,需要安装,安装方式其实在README.MD中有。以上操作README.MD中都有
一个机器上可以跑多个redis,用port区分,并且执行utils/install server.sh是可以配置
执行 utils/install_server.sh后打印的相关路径
Port : 6380
Config file : /etc/redis/6380.conf
Log file : /var/log/redis_6380.log
Data dir : /var/lib/redis/6380
Executable : /opt/yuchao/redis6/bin/redis-server
Cli Executable : /opt/yuchao/redis6/bin/redis-cli
三、原理
1、epoll
windows有AIO,linux没有AIO,epoll也是NIO
#查看文件描述符
ps -ef | grep reids
cd /proc/进程id/fd
ll
BIO -> NIO(同步非阻塞) -> 多路复用NIO(减少用户态和内核态切换) -> AIO
IO演化:

2、零拷贝

3、redis原理
redis操作数据是单进程、单线程、单实例(他可能还有其他的线程);那么并发,请求很多的时候,是如何变得很快的?
使用了epoll。
Nginx也使用了epoll
JVM:一个线程的成本:1MB(栈),可以调低
(1)线程多了调度成本CPU良妃
(2)内存消耗大
四、redis使用
- redis默认有16个库,从0-15
- redis的方法是和value的类型绑定的,当客户端调一个方法的时候,Redis会使用type命令查看value的类型,发现类型不一致,会直接返回错误。这也是Redis的一个优化点
- 使用的命令是哪个分组的,value的类型就是哪个
- key是一个object,包含
- value的type
- encoding
- value的长度
- redis对cpu亲和性的支持
1、通用命令
(1)redis-cli
# 连接redis
redis-cli
# 如果linux上启了多个redis,可以通过端口号连接不同的
redis-cli -p 端口号
#直接连接redis的8号库
redis-cli -p 端口号 -n 8
#查看redis-cli具体参数
redis-cli -h
#在这种状态下,会把get获取的16进制xshell的编码显示;比如显示“中”,而不是16进制
redis-cli --raw
(2)help
#连接redis后,通过help命令来查学习
help
#输入 help 和字母,然后按tab键,redis会给你补全命令
help SE
#查看命令分组@开头;查看generic命令
help @generic
help @string
help @hash
(3)object
命令object encoding k1结果:
- int
- embstr
- raw
类型改变:
- append后会变成raw
- incr后会变成int
#查看object命令
object help
#object后面可以接一个子命令 如果k1为99,则返回int,
object encoding k1
(4)select
#连接redis后,也可以通过select 命令来切换库
select 8
(5)keys
# 查询 匹配符合的key keys pattern
keys *
(6)flush
# 清库 运维一般会把这个命令重命名
FLUSHDB
FLUSHALL
(7)type
#查看value的方法
type k1
2、概念
(1)二进制安全
二进制安全(只有字节流,没有字符流;把内容变成字节存入redis中)
- 执行incr时,先取出转换成int,再加一,然后把encoding改为int;下一次就可以直接加。
- set k1 中(strlen k1 显示的是3;原因是xshell的编码设置的是UTF-8;改成GBK的话,长度就是2个字节)
#取出的k1长度,取决于xshell的编码;在UTF-8中“中”是3个字符,在GBK中是2个字符
set k1 中
setlen k1
#显示的是16进制(超过了ASCII码)
get k1
(2)字符集
字符集说的是ascii,用一个字节表示一个字符,八位: 0xxxxxxx(开头以为一定是0 );其他一般叫扩展字符集,复用ASCII有的编码,扩展其他字符
例子:
读出一个字节,是0开头可以直接转为ascii对应的字符;如果是三个1,表示还需要读出两个字节,然后去掉开头的三个1,去找对应字符集的字符。
3、String(byte)
(1)字符串
命令:
- set
- get
- append
- setrange
- getrange
- strlen
- mset
- mget
- msetnx
- getset
#设置值
#nx参数,表示key不存在的时候才能设置(分布式锁的时候用)
#xx参数,key存在的时候才可以设置
set key value [nx | xx]
#取值
get key
#批量设置
mset k1 a k2 b
#批量获取
mget k1 k2
#原子操作,有一个失败,全失败
msetnx k1 a k2 b
#追加
appen k1 " world"
#截取string
setrange k1 6 10
#正负索引
setrange k1 6 -1
#重下标6开始覆盖
setrange k1 6 'yuchao'
#获取长度
strlen k1
#set新值,get老值
getset k1 yyy
(2)数值
- incr(抢购,秒杀,详情页,点赞,评论;规避并发下,对数据库的事务操作完全由redis内存代替操作)
#加一
incr k1
#加一个数
incrby k1 20
#减一
decr k1
#减一个数
decrby k1 20
#加小数
INCRBYFLOAT k1 0.5
(3)bitmap
命令:
- setbit key offset value(offset是二进制位偏移量,不是二进制数组)
- bitcount key bit [start] [end]
- bitpos key bit [start] [end](这里的start、end是字节的偏移量) 查询start到end中bit出现的第一个位置,具体看以下命令
- bitop operation destkey key [key …]
数据结构:每一个字节有一套下标;每一位也有一套下标

#--------------------------------------------- setbit操作
# 0100 0000
127.0.0.1:6379> setbit k1 1 1
0
127.0.0.1:6379> get k1
@
# 0100 0001
127.0.0.1:6379> setbit k1 7 1
0
127.0.0.1:6379> get k1
A
127.0.0.1:6379> strlen k1
1
# 0100 0001 0100 0000
127.0.0.1:6379> setbit k1 9 1
0
127.0.0.1:6379> strlen k1
2
127.0.0.1:6379> get k1
A@
#linux查看ascii
man ascii
#--------------------------------------------- bitpos查询
127.0.0.1:6379> bitpos k1 1 0 0
1
127.0.0.1:6379> bitpos k1 1 1 1
9
#--------------------------------------------- BITCOUNT统计
127.0.0.1:6379> BITCOUNT k1 0 1
3
127.0.0.1:6379> BITCOUNT k1 0 0
2
127.0.0.1:6379> BITCOUNT k1 1 1
1
#--------------------------------------------- bitop位运算
# k1:0100 0010 A
# k2:0100 0100 B
# andkey:0100 0000 @
# orkey:0100 0110 C
127.0.0.1:6379> setbit k1 1 1
0
127.0.0.1:6379> setbit k1 7 1
0
127.0.0.1:6379> get k1
A
127.0.0.1:6379> setbit k2 1 1
0
127.0.0.1:6379> setbit k2 6 1
0
127.0.0.1:6379> get k2
B
127.0.0.1:6379> bitop and andkey k1 k2
1
127.0.0.1:6379> get andkey
@
127.0.0.1:6379> bitop or orkey k1 k2
1
127.0.0.1:6379> get orkey
C
bitmap使用场景:
(1)有用户系统,统计用户登录天数,且窗口随机(一位表示一天)
(2)登录送礼,用户有2亿,大库要备多少货(计算活跃用户,日期为key,用户id对应位;如果要计算3天内登录的,只要bitop or 最近三天的key,然后统计即可)
4、List
数据结构:

同向命令实现栈
反向命令实现队列
使用index操作,数组
阻塞,单薄队列(FIFO)
127.0.0.1:6379> lpush k1 a b c d e f
(integer) 6
127.0.0.1:6379> lpop k1
"f"
127.0.0.1:6379> lpop k1
"e"
127.0.0.1:6379> LRANGE k1 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
#通过下标操作
127.0.0.1:6379> LINDEX k1 0
"d"
127.0.0.1:6379> LSET k1 0 dd
OK
127.0.0.1:6379> LINDEX k1 0
"dd"
# 从左删除两个a
127.0.0.1:6379> lpush k2 1 a 2 b 3 a 4 c 5 a 6 d
(integer) 12
127.0.0.1:6379> LRANGE k2 0 -1
1) "d"
2) "6"
3) "a"
4) "5"
5) "c"
6) "4"
7) "a"
8) "3"
9) "b"
10) "2"
11) "a"
12) "1"
127.0.0.1:6379> LREM k2 2 a
(integer) 2
127.0.0.1:6379> LRANGE k2 0 -1
1) "d"
2) "6"
3) "5"
4) "c"
5) "4"
6) "3"
7) "b"
8) "2"
9) "a"
10) "1"
# 在6的后面插入一个a
127.0.0.1:6379> LINSERT k2 after 6 a
(integer) 11
127.0.0.1:6379> LRANGE k2 0 -1
1) "d"
2) "6"
3) "a"
4) "5"
5) "c"
6) "4"
7) "3"
8) "b"
9) "2"
10) "a"
11) "1"
# 在3的前面插入一个a
127.0.0.1:6379> LINSERT k2 before 3 a
(integer) 12
127.0.0.1:6379> LRANGE k2 0 -1
1) "d"
2) "6"
3) "a"
4) "5"
5) "c"
6) "4"
7) "a"
8) "3"
9) "b"
10) "2"
11) "a"
12) "1"
#查询元素个数
127.0.0.1:6379> llen k2
(integer) 12
# 阻塞弹出 0-表示一致阻塞(阻塞时间);list中无数据,会阻塞,知道有值push到list中
blpop k2 0
#去除开头和结尾的元素
127.0.0.1:6379> lpush k3 a b c d e f
(integer) 6
127.0.0.1:6379> lrange k3 0 -1
1) "f"
2) "e"
3) "d"
4) "c"
5) "b"
6) "a"
127.0.0.1:6379> ltrim k3 0 -1
OK
127.0.0.1:6379> lrange k3 0 -1
1) "f"
2) "e"
3) "d"
4) "c"
5) "b"
6) "a"
127.0.0.1:6379> lrange k3 2 -2
1) "d"
2) "c"
3) "b"
127.0.0.1:6379> lrange k3 0 -1
1) "f"
2) "e"
3) "d"
4) "c"
5) "b"
6) "a"
5、Hash
#存取
127.0.0.1:6379> hset sean name yc
(integer) 1
127.0.0.1:6379> hset sean age 18 address sz
(integer) 2
127.0.0.1:6379> hget sean name
"yc"
127.0.0.1:6379> hmget sean name age
1) "yc"
2) "18"
127.0.0.1:6379> hkeys sean
1) "name"
2) "age"
3) "address"
127.0.0.1:6379> hvals sean
1) "yc"
2) "18"
3) "sz"
127.0.0.1:6379> hgetall sean
1) "name"
2) "yc"
3) "age"
4) "18"
5) "address"
6) "sz"
#计算
127.0.0.1:6379> HINCRBYFLOAT sean age 0.5
"18.5"
127.0.0.1:6379> hget sean age
"18.5"
127.0.0.1:6379> HINCRBYFLOAT sean age -1
"17.5"
127.0.0.1:6379> hget sean age
"17.5"
使用场景:
- 商品详情
- 微博关注数、点赞数
6、Set
去重、无序
127.0.0.1:6379> sadd k1 tom jack peter tom xxoo
(integer) 4
127.0.0.1:6379> SMEMBERS k1
1) "xxoo"
2) "peter"
3) "jack"
4) "tom"
127.0.0.1:6379> srem k1 xxoo peter
(integer) 2
127.0.0.1:6379> SMEMBERS k1
1) "jack"
2) "tom"
#交集 并集 差集
#交集
127.0.0.1:6379> sadd k2 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd k3 4 5 6 7 8
(integer) 5
#直接输出交集
127.0.0.1:6379> SINTER k2 k3
1) "4"
2) "5"
#把交集存到dest中
127.0.0.1:6379> SINTERSTORE dest k2 k3
(integer) 2
127.0.0.1:6379> SMEMBERS dest
1) "4"
2) "5"
#并集
127.0.0.1:6379> sunion k2 k3
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
#差集
127.0.0.1:6379> SDIFF k2 k3
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> SDIFF k3 k2
1) "6"
2) "7"
3) "8"
#随机事件
127.0.0.1:6379> sadd k4 tom peter tony jack xx oo ox xo
(integer) 8
127.0.0.1:6379> SRANDMEMBER k4 5 -5 10 -10 0
SRANDMEMBER
正数:取出一个去重的结果集(不超过已有集合)
负数:取出一个带重复的结果集,一定满足你要的数量
0:不返回
SPOP:随机弹出一个元素
使用场景:
抽奖:
10个奖品
用户:<10 >10
中奖:是否重复
7、sorted_set
默认字典序排序,物理内存左小右大(按score)
具备集合操作(交、并、差)
127.0.0.1:6379> zadd k1 8 apple 2 banana 3 orange
(integer) 3
127.0.0.1:6379> ZRANGE k1 0 -1
1) "banana"
2) "orange"
3) "apple"
127.0.0.1:6379> ZRANGE k1 0 -1 withscores
1) "banana"
2) "2"
3) "orange"
4) "3"
5) "apple"
6) "8"
127.0.0.1:6379> ZRANGEBYSCORE k1 3 8
1) "orange"
2) "apple"
#倒序取出
127.0.0.1:6379> ZREVRANGE k1 0 -1 withscores
1) "apple"
2) "8"
3) "banana"
4) "4.5"
5) "orange"
6) "3"
#查score
127.0.0.1:6379> ZSCORE k1 apple
"8"
#查下标
127.0.0.1:6379> ZRANk k1 apple
(integer) 2
#计算——添加score
127.0.0.1:6379> ZINCRBY k1 2.5 banana
"4.5"
127.0.0.1:6379> ZRANGE k1 0 -1 withscores
1) "orange"
2) "3"
3) "banana"
4) "4.5"
5) "apple"
6) "8"
做结合操作的时候(交、并、差),有一个问题,就是当两个集合都有的元素取那个的score,这时候可以取min、max、sum(默认sum)
#默认
127.0.0.1:6379> zadd k2 80 tom 60 sean 70 baby
(integer) 3
127.0.0.1:6379> zadd k3 60 tom 100 sean 40 jack
(integer) 3
127.0.0.1:6379> ZUNIONSTORE unkey 2 k2 k3
(integer) 4
127.0.0.1:6379> ZRANGE unkey 0 -1 withscores
1) "jack"
2) "40"
3) "baby"
4) "70"
5) "tom"
6) "140"
7) "sean"
8) "160"
#设置权重 最后score等于 sum(原来的score * 权重)
127.0.0.1:6379> ZUNIONSTORE unkey1 2 k2 k3 weights 1 0.5
(integer) 4
127.0.0.1:6379> ZRANGE unkey1 0 -1 withscores
1) "jack"
2) "20"
3) "baby"
4) "70"
5) "sean"
6) "110"
7) "tom"
8) "110"
#取最大值
127.0.0.1:6379> ZUNIONSTORE unkey2 2 k2 k3 aggregate max
(integer) 4
127.0.0.1:6379> ZRANGE unkey2 0 -1 withscores
1) "jack"
2) "40"
3) "baby"
4) "70"
5) "tom"
6) "80"
7) "sean"
8) "100"
sorted_set底层实现:skip list(类平衡树)
问题:排序是怎么实现的?增删查改的速度?
在压测下,和其他数据结构比,使用调表的增删查改的平均效率是最高的
插入后,随机造层
五、redis进阶
1、管道(Pipelining)
如果机器上没有redis客户端,可以用nc命令连接redis进行操作。因为redis支持这种socket的连接
[root@iZwz91n56f8y4m7ta0i7xoZ ~]# nc localhost 6379
keys *
*6
$2
k2
$2
k1
$2
k3
$5
unkey
$6
unkey2
$6
unkey1
管道,可以把多个 命令一次性发给service,降低了我们的通信成本
使用:
[root@iZwz91n56f8y4m7ta0i7xoZ ~]# echo -e "set key2 99\n incr key2\n get key2" | nc localhost 6379
+OK
:100
$3
100
管道使用:Redis从文件中批量插入数据
这里有个换行符(linux中和windows的换行符不一样,一个是\n,一个是\r\n)转码的问题
redis冷启动
2、发布订阅
查看命令:
127.0.0.1:6379> help @pubsub
发布订阅测试:
#开两个连接测试,一个用来发布,一个用来订阅
#发布
127.0.0.1:6379> publish ooxx hello
(integer) 0
127.0.0.1:6379> publish ooxx hello
(integer) 1
127.0.0.1:6379>
#订阅(可以有多个) 第一次并没有接受到消息(因为必须先有订阅,再发布才能收到);
127.0.0.1:6379> SUBSCRIBE ooxx
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "ooxx"
3) (integer) 1
1) "message"
2) "ooxx"
3) "hello"
查看历史消息,思考比如微信要看历史消息,这个消息咋存,消息分类:

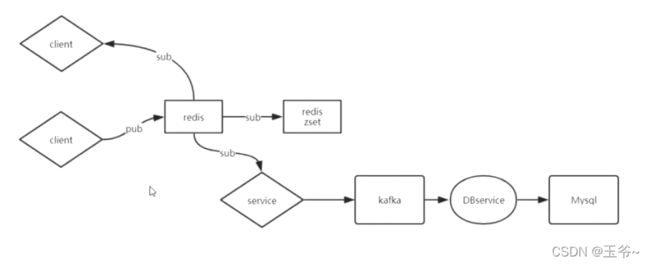
图中的sorted set:以时间排序消息,设立3天的窗口,删除之前的
以上redis可以拆分为两个:
3、事务
redis的使用,主要是它快。
redis的事务没有回滚:为什么Redis不支持rollback
#开启事务,开启后,下面的命令会通过cli发送到service,但不会执行,调用exec后才执行
multi
#执行
exec
#取消
discard
#乐观锁 配合multi/exec执行 使用顺序:watch、multi、exec
watch k1
以下:谁的exec先到达,先执行谁的,另一个后执行,可能执行失败(先delete,后get不到)

乐观锁:以下情况,当client执行exec会失败,因为这个过程中监控的k1变了,失败的处理需要client自己考虑

4、modules之布隆过滤器
modules:redis支持添加扩展库来实现一些功能
redis是C语言开发的,模块也是C语言的。编译RedisBloom源码后得到扩展库。
.so是linux的扩展库
.dll是windows的扩展库
启动redis服务的时候加上扩展库的参数,redis就有了扩展库的功能
#使用wget下载github上redisbloom的源码,解压并make生成.so扩展库
# 把生成的redisbloom.so放到/opt/yuchao/redis6(该目录为生成的执行文件的目录,具体看 二、下载安装)目录下, 和bin同一目录
#启动
redis-server --loadmodule /opt/yuchao/redis6/redisbloom.so /etc/redis/6379.conf
#启动后,连接
redis-cli
#这时候会多了一组命令,以BF开头
BF
#添加
BF.ADD ooxx abc
#判断是否存在 存在返回-1,不存在返回-0
BF.EXISTS ooxx abc
#CF命令 布谷鸟过滤器
解决的问题:缓存穿透
原理:使用bitmap映射数据库中有的数据(函数计算,不保证100%映射,有可能不同的key生成相同的bitmap下标),有则把请求放行,让他访问关系数据库。
过滤器:
bloom:counting bloom
cukcoo:布谷鸟过滤器
使用时的一些点:
- 通过了bloom过滤器,关系数据库中不存在,client可以在redis中添加key,value值标记它不存在
- 数据库增加元素,必须完成元素对bloom的添加
问题:布隆过滤器不支持删除
5、配置文件
(1)redis作为数据库/缓存的区别
- 缓存数据不重要(热数据)
- 不是全量数据
- 缓存应该随着访问变化
- 内存有限,所以要淘汰冷数据
(2)查看redis的配置文件:
- 里面可以加载其他配置文件
- 也可以加载module
- 限制访问的ip
- 是否开启远程访问
- 端口号修改
- 是否后台运行:daemonize yes
- 设置默认数据库的个数
- rdb
- 主从复制
- 客户端访问密码设置:requirepass foobared
- 重命名命令:rename-command CONFIG “”
- 最大连接数:maxclients 10000
- 内存管理:
- 最大可以使用多大内存(maxmeory 最好1G-10的范围)
- 内存回收策略:maxmemory-policy noeviction;中文文档(不一定全,配置文件中介绍是全的)
- noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkeys-random: 回收随机的键使得新添加的数据有空间存放。
- volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
- lru:多久没碰了;lfu:碰了多少次;
#查看配置文件
more /etc/redis/6379.conf
#设置20秒后过期时间 有效期不会随访问延迟 但重新set后,会去掉过期时间,一直存在
set k1 aaa ex 20
#查看还有多少秒过期 -1表示一直存在 -2表示不存在这个key
ttl k1
#单独设置过期时间
expire k1 50
#定时过期
expireat key timstamp
#linux取时间戳
time
过期原理
6、单机持久化
(1)RDB
默认开启了这个功能
问题:8:00开始持久化,到8:30介绍,期间数据有修改,那么持久化的是8:00这个状态的数据,还是8:30这个状态的数据?
与内核有关,使用cow(copy on write)机制。8:00开始持久化的时候使用单独的一个子进程(redis调用fork()),而父子进程对数据修改,对方看不到
快照、副本
# 手动调用——阻塞的,一般关机维护的时候用,启动的时候不用
save
# 手动调用——后台的 该命令会fork,创建子进程
bgsave
# 也可以在配置文件中配置规则(/etc/redis/6379.conf),配置文件中使用save(写save,其实调用的是bgsave)。在配合文件的一下位置:
################# SNAPSHOTTING ################
# save
# 可写多条
# 900秒操作了1,触发bgsave
save 900 1
# 300秒操作了10,触发bgsave
save 300 1
# 60秒操作了10000,触发bgsave
save 60 10000
# 配置文件中,rdb的文件名
dbfilename dump.rdb
# 存放的位置
dir /var/lib/redis/6379
弊端:
不支持日期拉链,只有一个dump.rdb,新的会覆盖旧的
会丢失数据
优点:类似java中的序列化。恢复的速度相对快
rdb创建子进程速度和使用内存的问题(fork、cow)
(2)AOF
append only file
- 会把redis的写操作都写到文件中,丢失数据少。
- redis中可以同时开启RDB、AOF:如果开启了AOF,只会恢复AOF。
- 4.0以后,AOF中包含RDB全量,增加新的写操作。
弊端:如果redis使用了10年,aof的日志文件将会很大。
解决方案:
- 4.0以前:重写——删除抵消的命令,合并重复的指令;最终也是一个纯指令的日志文件
- 4.0以后:将老的数据RDB到AOF中,将增量的以指令的方式append到AOF中;AOF是一个混合体利用率RDB的快,利用了日志的全量
redis是内存数据库,如果这时候用了AOF,那么写操作会触发IO,就会拖慢redis的速度。这时候可以调三个级别
- no:redis不调用flush,什么时候kernel的缓存满了,什么时候写入到磁盘中。可能会丢失一个buffer大小的数据(buffer大小可调,大概4k左右)
- always:每个操作都调用flush,基本不会丢失数据,最多丢一条
- everysec(默认):每秒调一次flush,速度的丢失的数据都介于上面两个之间

配置文件:
################# APPEND ONLY MODE ################
# 开启
appendonly yes
#文件名称;目录复用上面的rdb的目录
appendfilename "appendonly.aof"
#设置级别
# appendfsync always
appendfsync everysec
# appendfsync no
# bgrewriteaof机制的子进程在进行大量写操作的时候,主进程的aof不进行写操作,而进行阻塞。设置成yes的话,写入缓冲区,不进行阻塞,但有可能丢失数据。
no-appendfsync-on-rewrite no
# 重写的时候,先把rdb的文件加入aof中,可以减少重写的计算
aof-use-rdb-preamble yes
#触发重写:aof文件到达64mb的100%则触发重写,它是有记忆的,下一次就是到达128mb触发重写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
AOF文件查看:*2表示这个命令有两个词;$6表示这个词有6个字符
[root@iZwz91n56f8y4m7ta0i7xoZ 6379]# more appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$2
k1
$1
2
*3
$3
set
$2
k2
$1
2
*3
$3
set
$2
k3
$4
lucy
#重写
bgrewriteaof
重写后再查看aof文件:
REDIS0009ú redis-ver^E6.0.6ú
redis-bitsÀ@ú^EctimeÂáþìaú^Hused-memÂÀ<85>^M^@ú^Laof-preambleÀ^Aþ^@û^C^@^@^Bk3^Dlucy^@^Bk2À^B^@^Bk1À^Bÿ¾¢WFc/<8f>·
再次set k2 后:
REDIS0009ú redis-ver^E6.0.6ú
redis-bitsÀ@ú^EctimeÂáþìaú^Hused-memÂÀ<85>^M^@ú^Laof-preambleÀ^Aþ^@û^C^@^@^Bk3^Dlucy^@^Bk2À^B^@^Bk1À^Bÿ¾¢WFc/<8f>·*2^M
$6^M
SELECT^M
$1^M
0^M
*3^M
$3^M
set^M
$2^M
k2^M
$1^M
9^M
rdb后又变成了纯rdb:bgsave
7、主从复制
单机缺陷:
- 单点故障
- 容量有限
- 压力
AKF:
X-全量、镜像
Y-业务、功能(按业务使用不同的redis)
Z-优先级、逻辑再拆分
机器变多后出现的问题:
- 分区容忍性:两次获取的数据可能不一样,对数据的容忍度
- 数据一致性:
- 强一致性:所有节点阻塞知道所有数据全部一致,破坏可用性,redis用的第二种
- 弱一致性:可能会丢失数据(redis使用的)
- 最终一直性
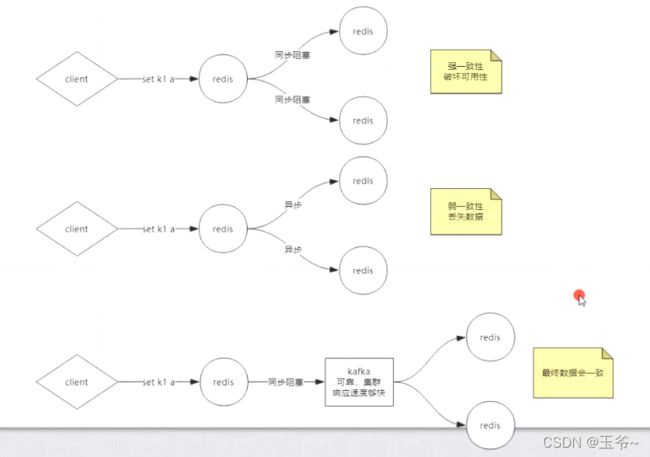
主从复制,投票数:n/2 + 1
一般使用奇数台
# 开启主从——5.0以前的命令
help slaveof
# 5.0以后的命令 执行成功后,从节点会删除所有的数据,并默认不许写入
replicaof 127.0.0.1 6379
# 不追随master
replicaof no one
实验:
- 使用utils/install_server.sh创建两个服务,并关闭服务
- 把配置文件复制一份,修改复制文件:后台启动关闭,注释配置文件,关闭AOF(方便实验观看日志)
- 重新启动,使用修改好的配置文件
- 删除RDB的数据
- 从节点执行replicaof,并查看日志(主节点使用子进程生产RDB文件,并发给从节点(也可以配置成字节网络发送,不先生产rdb文件);从节点flush DB,并从RDB加载数据,并且dump.rdb文件中记录了追随过的机器的id——repl-id)
- 成功后,在主节点插入数据,在从节点查看
- 从节点尝试插入数据,失败
问题:
如果从节点挂了,这时候再启动,那么它会重新拉去master的数据(如果有几个G),还是用老的
这时候启动可以加参数:redis-server ./6381.conf --replicaof 127.0.0.1 6379
答:没有重新从master
如果加上appendongly yes的参数的话,会flush DB:redis-server ./6381.conf --replicaof 127.0.0.1 6379 --appendonly yes。这时候会读rdb文件的数据到内存,并rewrite到aof文件。
相关配置:
# 配置文件 把后台运行关闭,并注释输出的日志文件,会把日志打印到控制台
# daemonize no
# logfile /var/log/redis_6379.log
# 从节点重主节点复制数据的过程,提不提供数据访问
replica-serve-stale-data yes
# 从节点只读
relica-read-only yes
# 主从——增量数据大小队列大小,超过会出发全量同步
repl-backing-seize 1mb
#redis提供了可以让master停止写入的方式,如果配置了min-replicas-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。设置为0是关闭该功能
# min-replicas-to-write 3
# 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave
# min-replicas-max-lag 10
8、哨兵机制
官方文档
目的:当主节点挂了后,不需要手动设置主节点,使用机器选择
实验:
- 开启3个redis,两个追随其中一个
- 创建3个sentinel.conf,并开启三个sentinel
- 查看sentinel.conf:哨兵会修改配置文件
- 开启redis-cli,执行PSUBSCRIBE *(加一个P可以后面接正则,查询通道) :从节点只配置主节点,就可以知道所有的从节点,原因是主节点开起来发布订阅
- 关闭一个redis,观察其他sentinel的日志
启动(两种方式):
- redis-sentinel setinel.conf (其实是redis-server的软链接)
- redis-server sentinel-6379.conf --sentinel
配置文件setinel.conf:开启后sentinel会修改配置文件
port 26379
sentinel monitor mymaster 127.0.0.1 6379 2
配置文件:在解压的源码下 sentinel.conf
9、sharing分片
数据分治方案:
- client写逻辑代码使用不同的redis,比如购物车的用一天redis、商品的用另一个redis
- 或者client控制a开头key的使用一个redis,b开头的使用另一个redis
数据分治产生的问题:
- 聚合操作没法实现
- 事务也无法实现
数据分治四种方式:


一致性hash算法:把数据和node节点都进过hash计算
虚拟节点解决数据倾斜问题
映射算法:
- hash
- crc16
- crc32
- fnv
- md5
(1)redis代理
- twemproxy
- predixy
- cluster
- codis(修改了redis源码)
问题:每个客户端都连接每个redis,导致连接数过多

解决方法:使用代理

(2)cluster
官方文档学习
- 每个redis节点都有其他所有节点的mapping关系数据。
- redis是无主模型
- 当client请求过来,当前redis节点对key进行hash计算后发现不在自己节点,这时候会告诉client数据在哪个节点,client再重新请求。
- set {oo}k1,添加标签,添加了标签会打到同一节点,这些key可以进行事务操作
- 启动的两种方法:
- 使用utils/create-cluster/create-cluster下的脚本启动(看官方文档、该目录下的readme)
- 使用redis-cli cluster help启动(看官方文档)

(3)twemproxy
按照readme.md的build下载编译
#进入scripts目录,复制nutcracker.init文件
cd scripts
cp nutcracker.init /etc/init.d/twemproxy
cd /etc/init.d
#添加执行权限
chmod +x twemproxy
#查看该文件,发现需要/etc/nutcracker/nutcracker.yml文件
cat twemproxy
mkdir /etc/nutcracker
#把配置文件复制到该目录,配置文件在下载的源码的conf下
cp ./* /etc/nutcracker/
# twemproxy脚本中还有:prog="nutcracker" 表明要执行的程序,所有把编译后src下nutcracker执行文件复制到/usr/bin下(放到改目录下的程序,在任何位置都可以执行)
cp nutcracker /usr/bin
# 修改/etc/nutcracker/nutcracker.yml配置文件
#先拷贝一份
cp nutcracker.yml nutcracker.yml.bak
# 配置介绍看github的configuration
vi nutcracker.yml
# 启动两个service后,启动服务
service twemproxy start
#连接代理,添加key,然后分别连接另外两台redis查看数据(或者在另外两台redis添加数据,在当前连接查看)
redis-cli -p 22121
# 连接代理不能执行该命令(watch、事务也不支持)
127.0.0.1:22121> keys *
Error: Server closed the connection
#停止服务
service twemproxy stop
nutcracker.yml文件:
IP和端口后面的数字是权重
alpha:
listen: 127.0.0.1:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 127.0.0.1:6379:1
- 127.0.0.1:6380:1
(4)predixy
官方文档
- 下载编译好的配置文件,解压
- 进入conf,修改主配置文件predixy.conf,设置导入的配置文件为sentinel.conf
- 修改sentinel.conf配置文件:
- Sentinels是哨兵的端口地址
- Group 后面的名称是哨兵配置文件里master的逻辑名称(可配置多套主从)
- 修改哨兵3个配置文件,启动3个哨兵(每个哨兵监控两个master 36379,46379)
- 启动两套主从redis(端口分别为36379,46379,36380,46380)
- 根据配置文件启动predixy
- 连接代理进行测试(如上twemproxy)
sentinel.conf:
sentinel.conf:
SentinelServerPool {
Databases 16
Hash crc16
HashTag "{}"
Distribution modula
MasterReadPriority 60
StaticSlaveReadPriority 50
DynamicSlaveReadPriority 50
RefreshInterval 1
ServerTimeout 1
ServerFailureLimit 10
ServerRetryTimeout 1
KeepAlive 120
Sentinels {
+ 127.0.0.1:26379
+ 127.0.0.1:26380
+ 127.0.0.1:26381
}
Group shard001 {
}
Group shard002 {
}
}
哨兵配置文件:(3个,port分别是26379,26380,26381)
port 26379
sentinel monitor shard001 127.0.0.1 36379 2
sentinel monitor shard002 127.0.0.1 46379 2
# 启动哨兵
redis-server sentinel-26379.conf --sentinel
redis-server sentinel-26380.conf --sentinel
redis-server sentinel-26381.conf --sentinel
# 启动redis
redis-server --port 3679
redis-server --port 36380 --replicaof 127.0.0.1 36379
redis-server --port 4679
redis-server --port 46380 --replicaof 127.0.0.1 36379
# 根据配置文件启动predixy
./predixy ../conf/predixy.conf
# 连接代理进行测试(事务只支持单group,多个group依旧不能支持事务:测试——只配置一个group)
redis-cli -p 7617
#添加标签,会存到同一套主从中
set {oo}k1 aaa
set {oo}k2 bbb
六、几个概念及API
1、击穿

2、穿透
布隆过滤器:缺点不能删除,可以使用布谷鸟

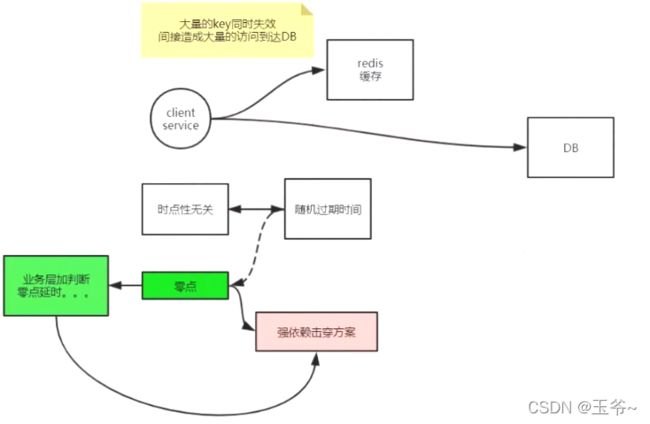
3、雪崩
场景——零点
4、分布式锁
- setnx
- 过期时间
- 多线程延长过期时间(redisson有现成的)
- 另外,zookeeper做分布式锁更方便
5、API
- jedis
- lettuce
- spring:low/hight level
- springboot
- springboot-data-redis
- lettuce
使用api调用前,关闭redis的安全模式,默认开启的,不允许远程连接
# 可以修改配置文件,也可以使用命令修改(临时更改)
# 查询所有配置
config get *
# 修改,临时更改
config set protected-mode no
# 修改配置文件:
# 注释掉 #bin 127.0.0.1
hash序列化
扁平化映射
基本api测试