湖南大学操作系统导论课程作业
第四章
使用的是run-process.py,这个脚本的参数如下
Usage: process-run.py [options]
Options:
-h, --help 查看帮助信息
-s SEED, --seed=SEED 随机种子
-l PROCESS_LIST, --processlist=PROCESS_LIST
以逗号分隔的要运行的进程列表,格式为X1:Y1,X2:Y2,...,其中X是该进程应运行的指令数,Y是该指令将运行的概率(从0到100),指令包括使用CPU或进行IO
-L IO_LENGTH, --iolength=IO_LENGTH
IO花费时间
-S PROCESS_SWITCH_BEHAVIOR, --switch=PROCESS_SWITCH_BEHAVIOR
当进程发出IO时,系统的反应:
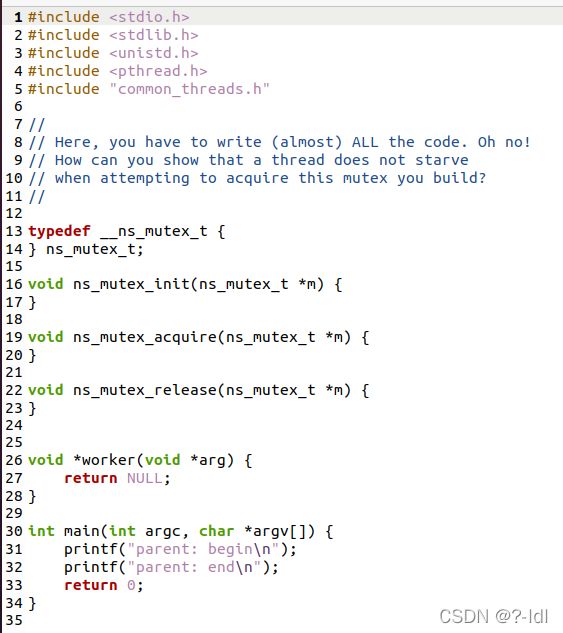
- SWITCH_ON_IO
- SWITCH_ON_END
-I IO_DONE_BEHAVIOR, --iodone=IO_DONE_BEHAVIOR
IO结束时的行为类型: IO_RUN_LATER/IO_RUN_IMMEDIATE
- IO_RUN_IMMEDIATE: 立即切换到这个进程
- IO_RUN_LATER: 自然切换到这个进程(例如:取决于进程切换行为)
-c 计算结果
-p, --printstats 打印统计数据; 仅与-c参数一起使用是有效
io的时间如果不设置则为5个时钟周期。
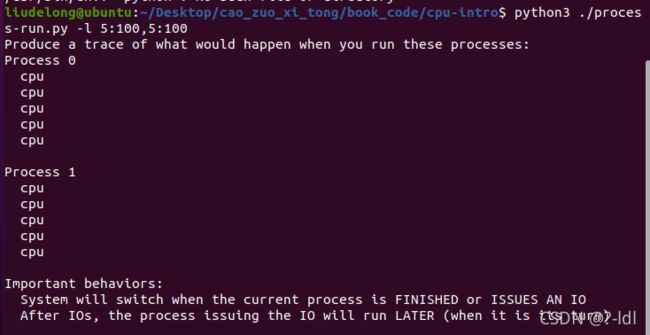
4.1 用以下标志运行程序:./process-run.py -l 5:100,5:100。CPU 利用率(CPU 使用时间的百分比)应该是多少?为什么你知道这一点?利用 -c 标记查看你的答案是否正确。
答:这个题目要求执行两个进程。这两个进程都包含5条cpu指令。由于他们全部在CPU上运行,没有发起IO,所以CPU利用率为100%。
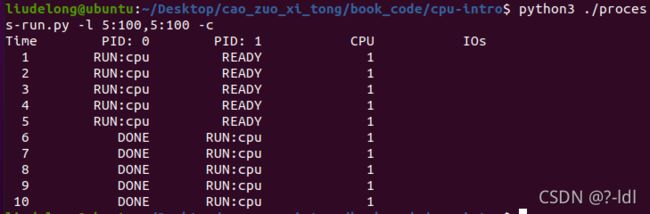
可以看到,CPU占用率确实为100%
4.2 现在用这些标志运行: ./process-run.py -l 4:100,1:0 这些标志指定了一个包含 4 条指令的进程(都要使用 CPU),并且只是简单地发出 IO 并等待它完成。完成这两个进程需要多长时间?利用 c 检查你的答案是否正确。
答:这个指令要求完成两个进程,第一个进程执行4个纯cpu指令,第二个进程指令1个io指令。
完成这两个进程需要10个时钟周期。(io指令默认是5个时钟周期)
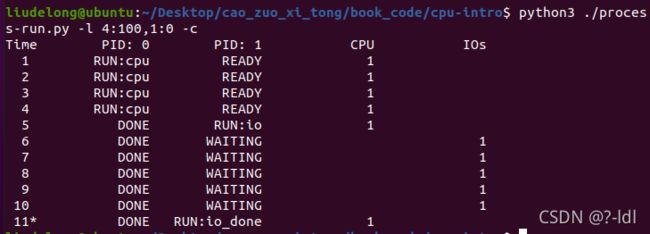
4.3 现在交换进程的顺序: ./process-run.py -l 1:0,4:100 现在发生了什么?交换顺序是否重要?为什么?同样,用 -c 看看你的答案是否正确。
答:进程1等待io的时候,进程2会使用cpu。交换顺序重要,因为它可以减少cpu的等待,提高cpu的利用率。
时钟周期变为了6。
4.4 现在探索另一些标志。一个重要的标志是 -S,它决定了当进程发出 IO 时系统如何反应。将标志设置为 SWITCH_ON_END,在进程进行 I/O 操作时,系统将不会切换到另一个进程,而是等待进程完成。当你运行以下两个进程时,会发生什么情况?一个执行 I/O,另一个执行 CPU 工作。(-l 1:0,4:100 -c -S SWITCH_ON_END)
答:进程1发起io后,cpu进入空闲状态,持续5个周期,然后cpu执行4条cpu指令。

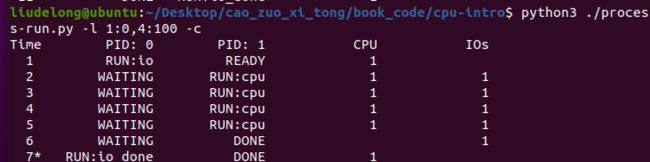
4.5 现在,运行相同的进程,但切换行为设置,在等待 IO 时切换到另一个进程(-l 1:0,4:100 c-S- SWITCH_ON_IO)现在会发生什么?利用 -c 来确认你的答案是否正确。
答:情况会和3相同进程1等待io的时候,进程2会使用cpu。提高cpu的利用率。
第五章
5.1 编写一个调用 fork()的程序。在调用之前,让主进程访问一个变量(例如 x)并将其值设置为某个值(例如 100)。子进程中的变量有什么值?当子进程和父进程都改变 x 的值时,变量会发生什么?

答:子程序的变量为100。当子进程和父进程都改变 x 的值时,他们独立改变。不会影响到别的进程。我写的程序中,子进程最终打印0,父进程最终打印1。
5.2 编写一个打开文件的程序(使用 open 系统调用),然后调用 fork 创建一个新进程。子进程和父进程都可以访问 open()返回的文件描述符吗?当它们并发(即同时)写入文件时,会发生什么?
编写代码如下:
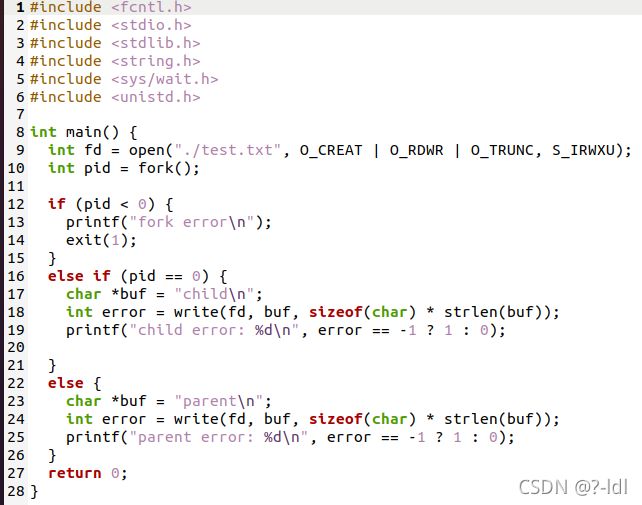
运行结果如下:


答:父子进程都可以使用open返回的文件描述符。关于写,都是可以写成功的。查阅资料得知。write函数不是原子操作。写时可能会出现问题。比如父进程写aaaaa,子现场写bbbbb。最后的结果可能是aaabbbaabb。如果使用pwrite,就不会出现问题,但无法保证顺序。pwrite写文件操作是原子的。
5.4 编写一个调用 fork()的程序,然后调用某种形式的 exec()来运行程序"/bin/ls"看看是否可以尝试 exec 的所有变体,包括 execl()、 execle()、 execlp()、 execv()、 execvp()和 execve(),为什么同样的基本调用会有这么多变种?

exec所有变种都可以使用,这些变种有不同的参数形式。有这么多变种其实是因为c语言没有重载特性。
- l: 希望接收以逗号分隔的参数列表,列表以 NULL 指针作为结束标志
- v: 希望接收一个以 NULL 结尾字符串数组的指针
- p: 是一个以 NULL 结尾的字符串数组指针,函数可以利用 DOS 的 PATH 变量查找自程序文件
- e 函数传递指定采纳数 envp(环境变量),允许改变子进程环境,无后缀 e 是,子进程使用当前程序环境
第七章
7.1 使用 SJF 和 FIFO 调度程序运行长度为 200 的 3 个作业时,计算响应时间和周转时间。
SJF:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 200 |
| 1 | 200 | 400 |
| 2 | 400 | 600 |
FIFO:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 200 |
| 1 | 200 | 400 |
| 2 | 400 | 600 |
| 调度策略 | 平均响应时间 | 平均周转时间 |
|---|---|---|
| SJF | 200 | 400 |
| FIFO | 200 | 400 |
7.2 现在做同样的事情,但有不同长度的作业,即 100、200 和 300
SJF:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 100 |
| 1 | 100 | 300 |
| 2 | 300 | 600 |
FIFO:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 100 |
| 1 | 100 | 300 |
| 2 | 300 | 600 |
| 调度策略 | 平均响应时间 | 平均周转时间 |
|---|---|---|
| SJF | 133.33 | 333.33 |
| FIFO | 133.33 | 333.33 |
7.3 现在做同样的事情,但采用 RR 调度程序,时间片为 1,长度为 200:
RR:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 598 |
| 1 | 1 | 599 |
| 2 | 2 | 600 |
| 平均相应时间 | 平均周转周转时间 |
|---|---|
| 1 | 599 |
长度为 100, 200, 300:
RR:
| 作业 id | 响应时间 | 周转时间 |
|---|---|---|
| 0 | 0 | 298 |
| 1 | 1 | 499 |
| 2 | 2 | 600 |
| 平均相应时间 | 平均周转周转时间 |
|---|---|
| 1 | 456.67 |
7.4 对于什么类型的工作负载,SJF 提供与 FIFO 相同的周转时间?
- 任务达到时间满足下面要求:不会使得任务需要等待执行。
- 有任务需要等待执行时,也就是FIFO中有任务。等待执行的任务在队列中按执行时间递增。
7.5 对于什么类型的工作负载和量子长度(时间片长度),SJF 与 RR 提供相同的响应时间?
运行时间 <= 时间片
7.6 随着工作长度的增加,SJF 的响应时间会怎样?你能使用模拟程序来展示趋势吗?
响应时间越来越长。
7.7 随着量子长度(时间片长度)的增加,RR 的响应时间会怎样?你能写出一个方程,计算给定 N 个工作时,最坏情况的响应时间吗?
响应时间会变长。
设T为时间片长度。
当执行时间最短的任务的执行时间>T时,有最坏情况。
公式为
ans=(0+T+2T+3T+……+(n-1)T)/n=(n-1)*T/2
第八章
本章作业使用mlfq程序。它的参数如下
Usage: mlfq.py [options]
Options:
-h, --help 显示此帮助信息并退出
-s SEED, --seed=SEED 指定随机种子
-n NUMQUEUES, --numQueues=NUMQUEUES
MLFQ中的队列数(如果没有使用-Q)
-q QUANTUM, --quantum=QUANTUM
时间片长度(如果没有使用-Q参数)
-Q QUANTUMLIST, --quantumList=QUANTUMLIST
指定为x,y,z,...为每个队列级别的时间片长度,
其中x是优先级最高的队列的时间片长度,y是第二高的队列的时间片长度,依此类推
-j NUMJOBS, --numJobs=NUMJOBS
系统中的作业数
-m MAXLEN, --maxlen=MAXLEN
作业的最大运行时间(如果是随机的)
-M MAXIO, --maxio=MAXIO
作业的最大I/O频率(如果是随机的)
-B BOOST, --boost=BOOST
将所有作业的优先级提高到高优先级的频率(0表示从不)
-i IOTIME, --iotime=IOTIME
I/O 持续时间(固定常数)
-S, --stay 发出I/O时重置并保持相同的优先级
-l JLIST, --jlist=JLIST
以逗号分隔的要运行的作业列表,格式为x1,y1,z1:x2,y2,z2:...。
其中x是开始时间,y是运行时间,z是作业I/O的频率
-c 计算答案
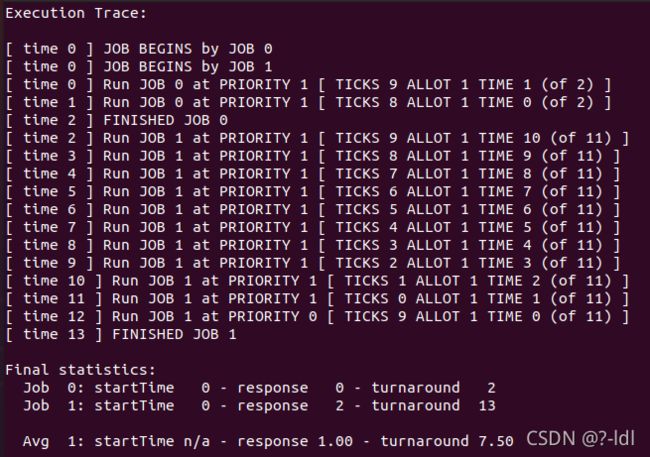
8.1 只用两个工作和两个队列运行几个随机生成的问题。针对每个工作计算 MLFQ 的执行记录。限制每项作业的长度并关闭 I/O,让你的生活更轻松。
seed 1:python3 mlfq.py -j 2 -n 2 -M 0 -m 15 -l 0,2,0:0,11,0

mlfq中第一队列和第二队列时间片都为10
| 时刻 | 事件 |
|---|---|
| 0 | 任务1和任务2到达,都进入第一队列。然后任务1开始运行 |
| 1 | 任务1运行 |
| 2 | 任务1完成,任务2运行 |
| 3~11 | 任务2运行 |
| 12 | 任务2进入队列2,继续运行 |
| 13 | 任务2运行完成 |
程序运行答案:
8.3 将如何配置调度程序参数,像轮转调度程序那样工作?
答:队列数设为 1
python3 mlfq.py -n 1
8.5 给定一个系统,其最高队列中的时间片长度为 10ms,你需要如何频繁地将工作推回到最高优先级级别(带有-B 标志),以保证一个长时间运行(并可能饥饿)的工作得到至少 5%的 CPU?
对于一个任务,它一开始在最高优先队列运行10ms后,优先级下降,要得到5%,那么需要每190ms把它重新放入最高优先级。
所以要设置 -B 190
第九章
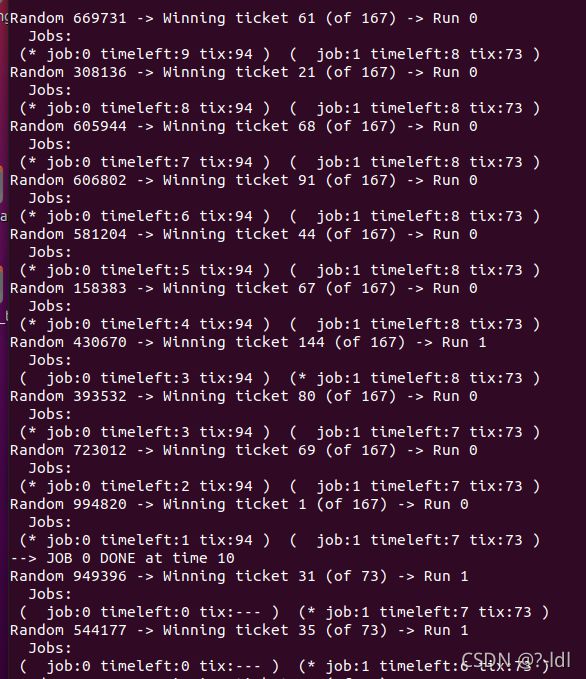
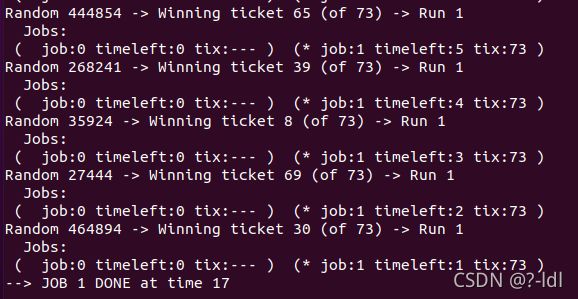
1.计算 3 个工作在随机种子为 1、2 和 3 时的模拟解。
seed 1

获胜票=随机数%彩票总数
| 抽签轮数 | 随机数 | 彩票总数 | 获胜票 | 被 执行的任务 |
|---|---|---|---|---|
| 1 | 495435 | 109 | 30 | 1 |
| 2 | 449491 | 25 | 16 | 0 |
| 3 | 651593 | 25 | 18 | 0 |
| 4 | 788724 | 25 | 24 | 0 |
| 5 | 93859 | 25 | 9 | 0 |
| 6 | 28347 | 25 | 22 | 0 |
| 7 | 835785 | 25 | 15 | 0 |
| 8 | 432767 | 25 | 17 | 0 |
seed 2

seed 3
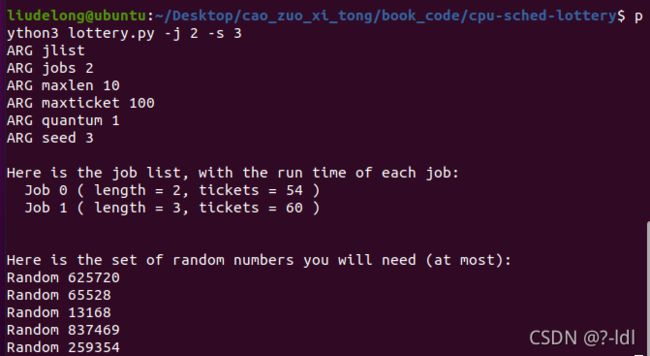
| 抽签轮数 | 随机数 | 彩票总数 | 获胜票 | 被 执行的任务 |
|---|---|---|---|---|
| 1 | 625720 | 114 | 88 | 1 |
| 2 | 65528 | 114 | 92 | 1 |
| 3 | 13168 | 114 | 58 | 1 |
| 4 | 837469 | 54 | 37 | 0 |
| 5 | 259354 | 54 | 46 | 0 |
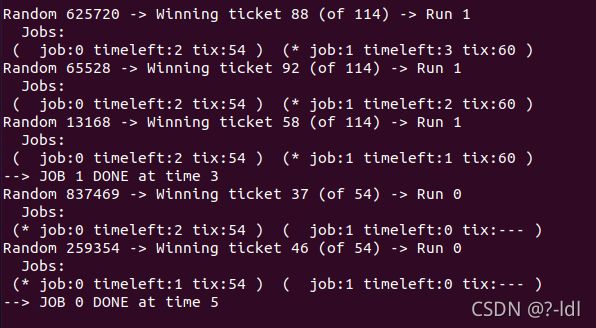
9.2 现在运行两个具体的工作:每个长度为 10,但是一个(工作 0)只有一张彩票,另一个(工作 1)有 100 张(-l 10:1,10:100).彩票数量如此不平衡时会发生什么?在工作 1 完成之前,工作 0 是否会运行?多久? 一般来说,这种彩票不平衡对彩票调度的行为有什么影响?
答:
- 彩票数量如此不平衡导致作业 0 响应时间与周转时间可能非常长。
- 作业 1 完成前,作业 0 会会很小的概率运行。
- 彩票不平衡的调度导致彩票数少的作业响应时间与周转时间变得很长。
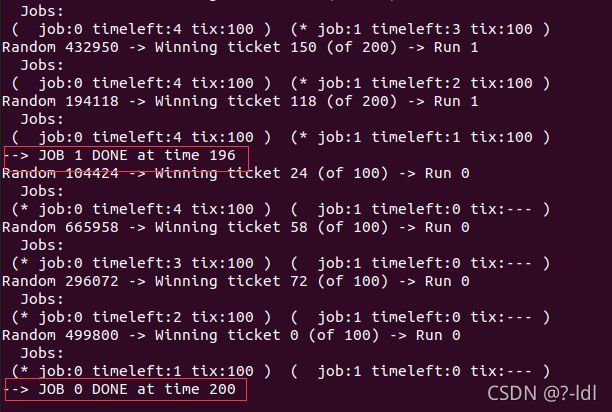
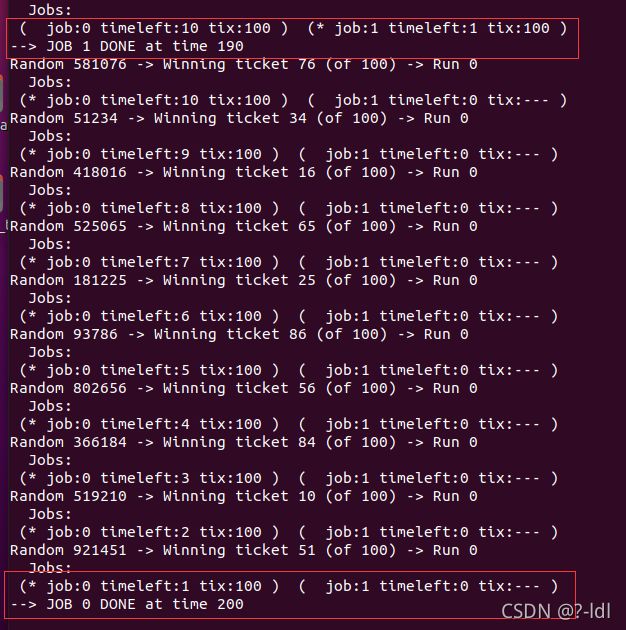
9.3 如果运行两个长度为 100 的工作,都有 100 张彩票(-l 100:100,100:100),调度程序有多不公平?运行一些不同的随机种子来确定(概率上的)答案。不公平性取决于一项工作比另一项工作早完成多少。
seed 1
seed 2
seed 20

seed 50
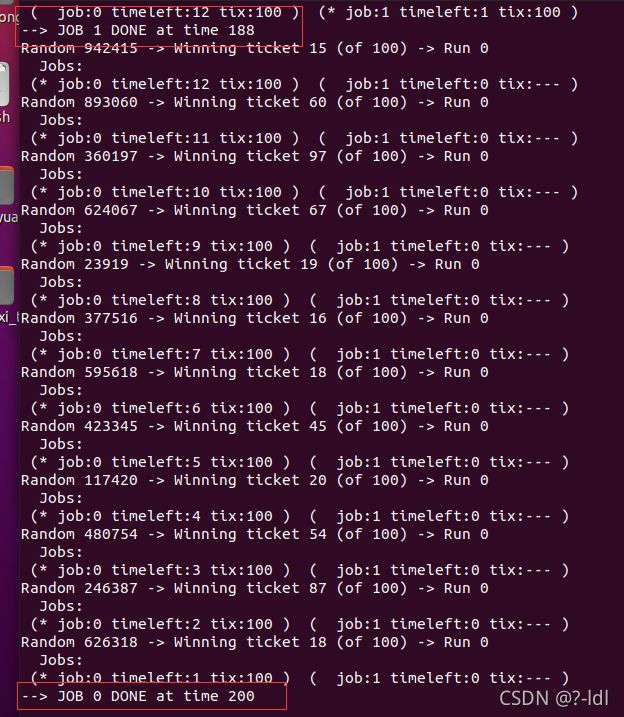
| seed | job 0 | job 1 |
|---|---|---|
| 1 | 200 | 196 |
| 2 | 200 | 190 |
| 20 | 200 | 196 |
| 50 | 200 | 188 |
最公平的情况应该是199 和200 ,已经比较接近这个线,我认为是比较公平的。
第26章
26.1
开始,我们来看一个简单的程序,“loop.s”。首先,阅读这个程序,看看你是否能理解它:
cat loop.s。然后,用这些参数运行它:
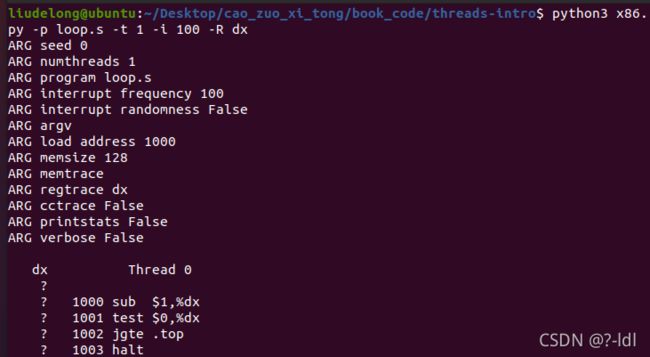
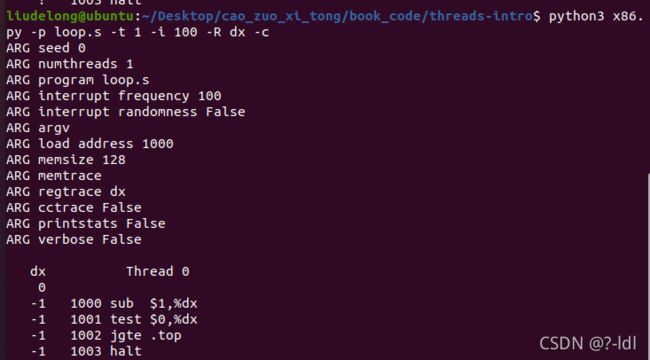
./x86.py -p loop.s -t 1 -i 100 -R dx
这指定了一个单线程,每 100 条指令产生一个中断,并且追踪寄存器 %d。你能弄清楚 %dx 在运行过程中的值吗?
你有答案之后,运行上面的代码并使用 -c 标志来检查你的答案。注意答案的左边显示了右侧指令运行后寄存器的值(或内存的值)
答:
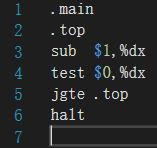
loop.s 代码如下
这个代码是循环地让%edx的值减1,直到%edx的值小于0。
%dx初始值为0,第一条指令%dx变为-1,然后3条指令没有对%dx进行修改。任然为-1。
26.2
现在运行相同的代码,但使用这些标志:
-/x86.py -p loop.s -t 2 -i 100 -a dx=3,dx=3 -R dx
这指定了两个线程,并将每个%dx 寄存器初始化为 3. %dx 会看到什么值?使用-c 标志运行以查看答案。多个线程的存在是否会影响计算?这段代码有竞态条件吗?
运行代码获取问题描述
%dx 的值变化如下:3->2->2->2->1->1->1->0->0->0->-1->-1->-1->-1->3->2->2->2->1->1->1->0->0->0->-1->-1->-1->1
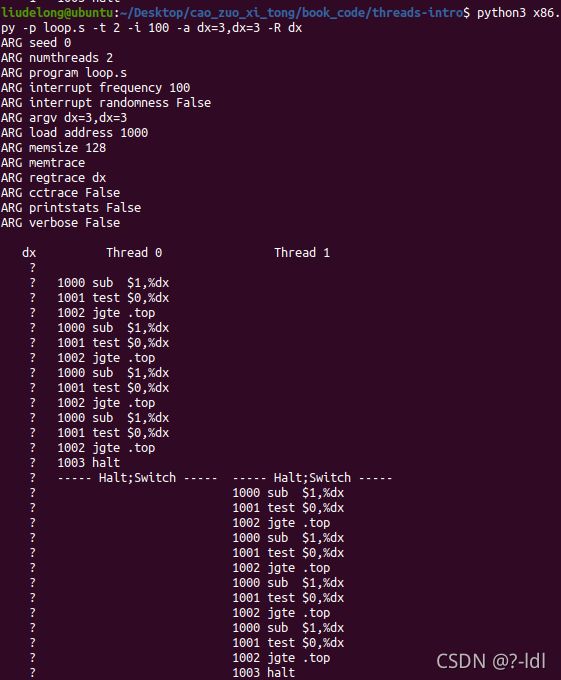

多线程的计算在本例中并没有影响计算。因为本例中的计算都是寄存器计算,没有对内存的读写。而每个线程的寄存器都是独立的。
这段代码没有竞态条件(计算的正确性取决于多个线程的交替执行时序/ 程序运行顺序的改变会影响最终结果)。因为 -i 参数为100,就是每执行100条指令才中断一次。而线程0和线程1运行完毕所执行的指令条数少于100,不论哪个线程先运行,在运行完之前都不会被打断,不会影响最终结果,所以没有竞态条件。
26.3
现在运行以下命令:
./x86.py -p loop.s -t 2 -i 3 -r -a dx=3,dx=3 -R dx
这使得中断间隔非常小且随机。使用不同的种子(-s) 来查看不同的交替。中断频率是否会改变这个程序的行为?
-s 1
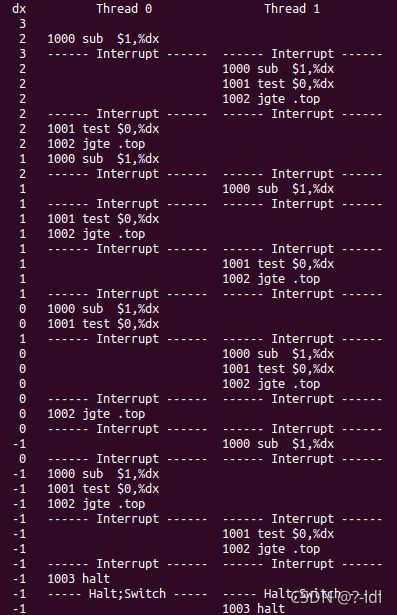
-s 2
-s 3
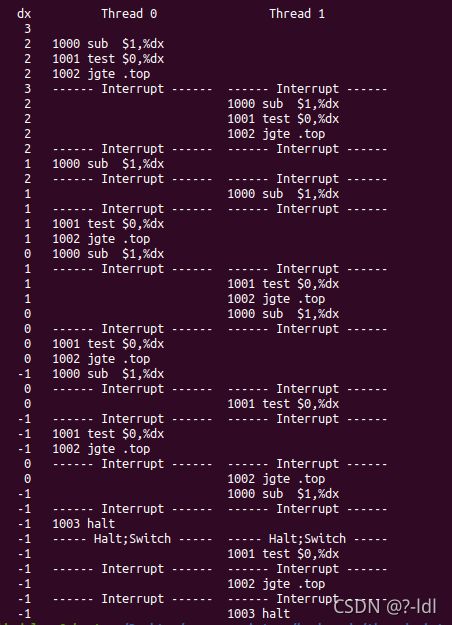

可以看到,同样的中断频率,对于不同的seed,程序运行的顺序有所不同,所以中断频率是会影响程序的行为的。但对于每个线程。它寄存器的值变化都是3->2->2->2->1->1->1->0->0->0->-1->-1->-1->-1,在本例中,中断频率没有影响程序的结果。
26.4
接下来我们将研究一个不同的程序(looping-race-nolock.s)。该程序访问位于内存地址 2000 的共享变量。简单起见,我们称这个变量为 x。使用单线程运行它,并确保你了解它的功能,如下所示:
./x86.py -p looping-race-nolock.s -t 1 -M 2000
在整个运行过程中,x(即内存地址为 2000)的值是多少?使用-c来检查你的答案。
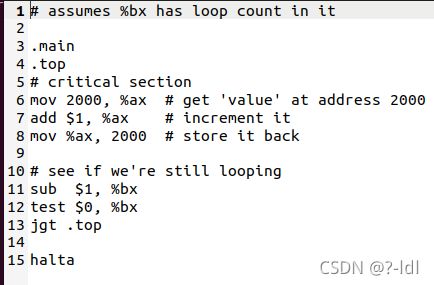
此程序是将地址2000内的值自加1后再存回地址2000处,之后将寄存器bx的值减1并和0作比较,如果大于0,就跳转到.top(循环),否则执行halt线程结束运行。
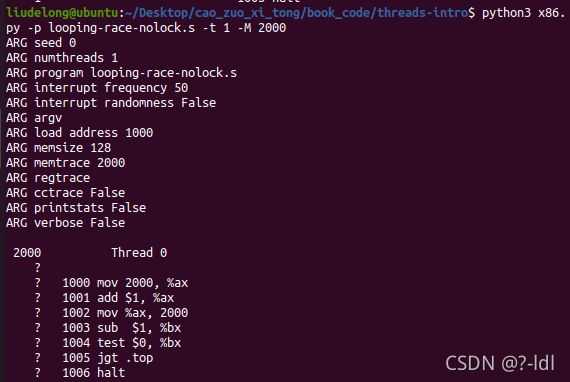
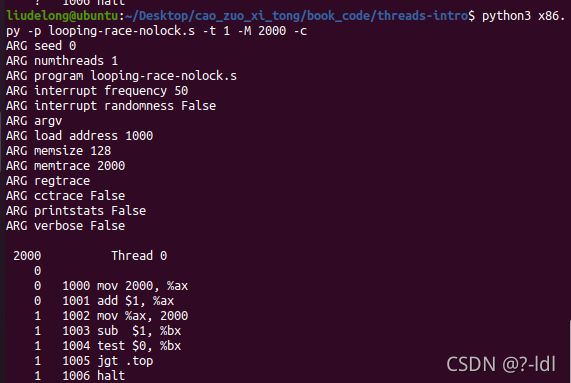
- 地址2000处初值为0,执行完第一条指令后,寄存器ax值为为0;
- 执行add指令,寄存器ax值自加1,变为1;
- 执行mov指令,将寄存器ax值存回地址2000,所以执行完这条指令后,地址2000处的值为1;
- 寄存器bx初值为0,执行完sub指令,寄存器bx值自减1,变为-1;
- 执行test指令,将寄存器bx值与0作比较;
- -1<0,不满足跳转条件大于0,所以不会跳转到.top处;
执行halt指令,线程结束运行。

第28章
28.1 首先用标志 flag.s运行 x86.py。该代码通过一个内存标志“实现”锁。你能理解汇编代码试图做什么吗?
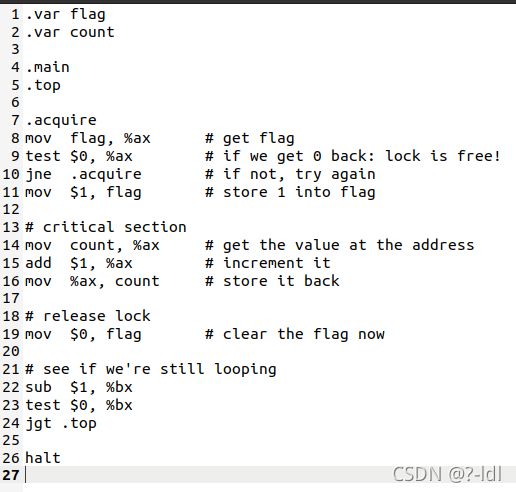
该汇编代码的c语言描述就是课本上的简单锁

循环检查flag,直到flag为0。然后设置flag为1。
28.2 使用默认值运行时, flag.s是否按预期工作?它会产生正确的结果吗?使用-M 和-R 标志跟踪变量和寄存器(并使用-c 查看它们的值)。你能预测代码运行时 flag 最终会变成什么值吗?
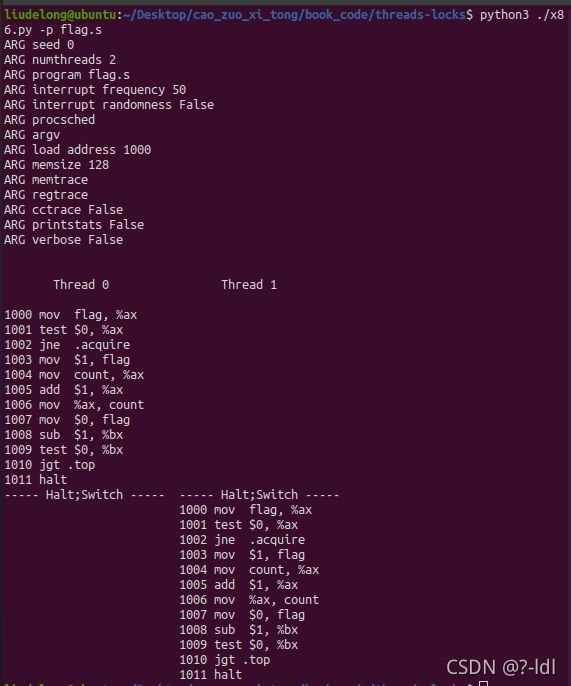
flag.s会按预期工作,线程0先运行,并且进程上下文切换前运行完成。之后线程1才开始运行,没有出现多个线程同时访问临界区的情况,所以预测其会产生正确的结果。
count:线程0和线程1分别进行了一次+1操作。
flag最终会被线程1在1007处设置为0。
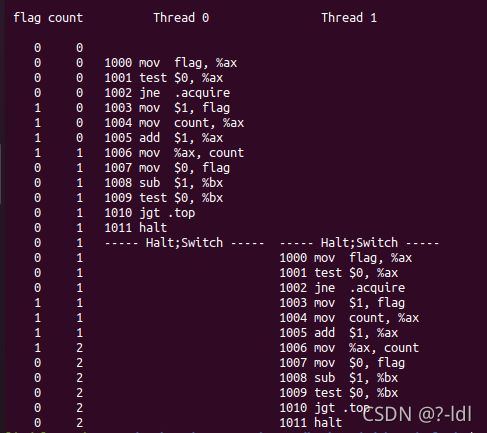
28.3 使用-a标志更改寄存器%bx的值(例如,如果只运行两个线程,就用-a bx=2,bx=2)。代码是做什么的?对这段代码重复上面的问题,答案是什么?

代码让临界区的代码循环执行了更多次。
-a标志使得寄存器bx的初值由默认的0变为了2。将bx初值改为2后,每个线程访问临界区的次数由之前的一次变为两次,即每个线程都对count执行了两次自加1的操作。
对于count:线程0对count执行了两次加1操作,线程1也对count执行了两次加1操作,所以结束时count的值为4。
对于flag:结束是flag为0
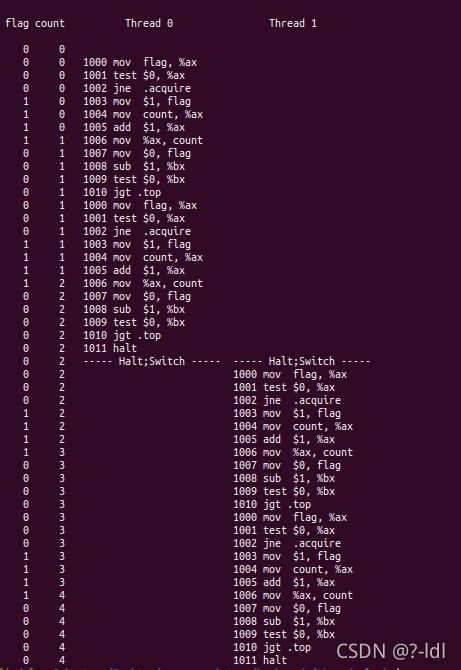
28.4 对每个线程将bx设置为高值,然后使用-i标志生成不同的中断频率。什么值导致不好结果的产生?什么值导致良好结果的产生?
当-i较小时,会有不好的结果产生;当-i较大、比较小时,会产生好的结果。概括地说,如果线程上下文切换发生在内存值的加载与回写中间。就会导致不好的结果。
线程1检查flag当前为0。正准备把flag修改为1,这时候切换线程。线程2也检查到flag为0,并把flag修改为1。然后上下文切换。线程1把flag修改为1。这时候两个进程进入临界区。执行下面代码。
count当前为20,线程0访问临界区,执行完add $1, %ax但还没有来得及将新值写入count时,发生了线程切换。线程1将count加1后重新写入count,此时count为21。当又切换回线程0时,由于已经执行过add指令,所以线程0直接向count写入21。于是不期望的事情发生了:add $1, %ax执行了两次,但实际count只增加了一次。这样就会导致结束时count的值不是两个线程bx初值之和。
这种情况,在-i比较小时发生频率会大。
28.5 现在让我们看看程序test-and-set.s。首先,尝试理解使用xchg指令构建简单锁原语的代码。获取锁怎么写?释放锁怎么写?
.var mutex
.var count
.main
.top
.acquire
mov $1, %ax
xchg %ax, mutex # 原子操作:交换ax寄存器与内存mutex空间的值(mutex设为1)
test $0, %ax #
jne .acquire # 如果(%ax)!=0则自旋等待,即原mutex值不为0
# critical section
mov count, %ax #
add $1, %ax #
mov %ax, count # count地址的值+1
# release lock
mov $0, mutex # mutex设为0(释放锁)
# see if we're still looping
sub $1, %bx
test $0, %bx # 多次循环,直到bx值小于等于0
jgt .top
halt
xchg 完成了两件事,1.把mutex变为1(set) 2.获取mutex变成1之前的值(test)。这两件事,在之前是分开的,现在要么保证两件事一起完成,要么两件事都不做。这样之前因为分开做而出现的问题就解决了。
获取锁:
mov $1, %ax
xchg %ax, mutex
test $0, %ax
jne .acquire
释放锁:
mov $0, mutex
28.6 现在运行代码,再次更改中断间隔(-i)的值,并确保循环多次。代码是否总能按预期工作?有时会导致CPU使用率不高吗?如何量化呢?
经过测试,运行下面代码,都能得到正确的结果
python3 x86.py -p test-and-set.s -a bx=10000,bx=10000 -M count -c -i 1
python3 x86.py -p test-and-set.s -a bx=10000,bx=10000 -M count -c -i 2
python3 x86.py -p test-and-set.s -a bx=10000,bx=10000 -M count -c -i 5
在test-and-set.s的实现当中,当一个线程持有锁并且在临界区发出io时,另一个线程不断自旋等待,且占用整个时间片,而这个时间片内只有前面部分cpu是被占用的,后面都是空闲。使得CPU使用率不高。
量化:计算 当一个线程持有锁进入临界区时被抢占,抢占线程的自旋时间长与总时间长百分比即可
28.7 使用-P 标志生成锁相关代码的特定测试。例如,执行一个测试计划,在第一个线程中获取锁,但随后尝试在第二个线程中获取锁。正确的事情发生了吗?你还应该测试什么?
-P lets you specify exactly which threads run when;
e.g., 11000 would run thread 1 for 2 instructions, then thread 0 for 3, then repeat
python3 x86.py -p test-and-set.s -M mutex,count -R ax,bx -c -a bx=5,bx=5 -P 0011111
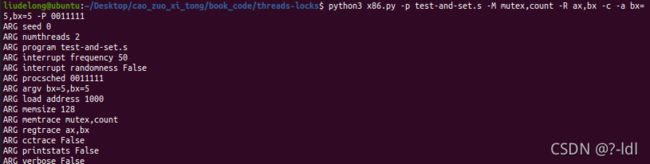
结果
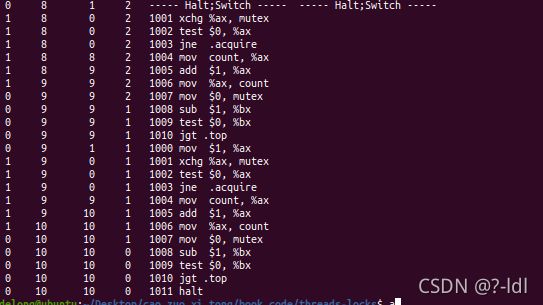
代码可以正确工作。
此外,还应该测试公平性(是否每个线程都保证在一轮中能够执行)和性能。
第三十章
参数设置
-l 每个生产者生产的数量 -m 生产者/消费者共享的缓冲区大小 -p 生产者数量 -c 消费者数量 -P sleep string: how producer should sleep at various points -C sleep string: how consumer should sleep at various points -v [verbose flag: 追踪发生了什么并打印] -t [timing flag: 打印执行总时间]
30.1 我们的第一个问题集中在 main-two-cvs-while.c(有效的解决方案)上。 首先,研究代码。 你认为你了解当你运行程序时会发生什么吗?
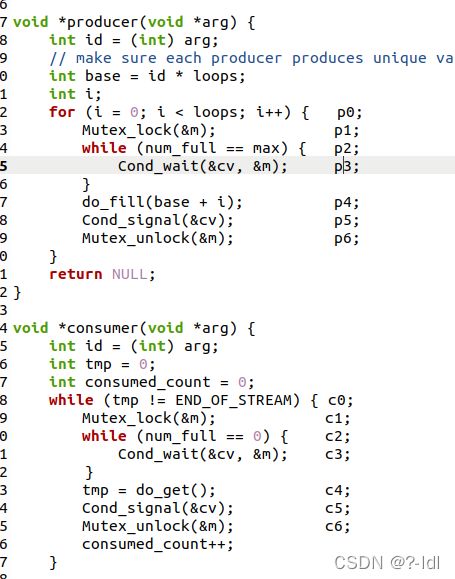
代码的核心部分如图:
这里,生产者生产loop个数据。生成过程如下:首先获取一把锁,然后如果缓冲区已满,则等待消费者发出的消费信号再往下执行。否则,就往缓冲区中放置生产的数据。然后发出一个信号,通知消费者消费。最后解锁。
消费者消费若干个数据。消费过程如下:首先获取一把锁,然后如果缓冲区中没有数据,则等待一个数据信号。否则,取出缓冲区中的数据。并发出一个信号。然后释放锁,并让自己的消费计数器+1。

这个代码目的是让生产者生产数据到缓冲区中(如果缓冲区未满),消费者从缓冲区中取数据。程序运行时,希望生产者会在仓库满时等待,并且一旦仓库有空间,则立即解除等待放置数据。消费者会在仓库为空的时候等待,并且仓库一旦有数据,则立刻解除等待消费数据。
30.2 指定一个生产者和一个消费者运行,并让生产者产生一些元素。 缓gf冲区大小从 1 开始,然后增加。随着缓冲区大小增加,程序运行结果如何改变?当使用不同的缓冲区大小(例如 -m 10),生产者生产不同的产品数量(例如 -l 100),修改消费者的睡眠字符串(例如 -C 0,0,0,0,0,0,1),full_num 的值如何变化?
下面的结果中,NF表示num_full,缓冲区中数据的数据量。中间是仓库的情况。
---表示该仓库位没有数据。后面P0列表示生成者0执行到哪一行代码。对应上图中每一行代码后面的注释。
m=1
m=2
m=3
m=4
程序的运行结果基本不变,m的增加,只是让生成者和消费者每次放置数据的位置和消费数据的有所改变。但消费者还是能够在仓库为空时等待,一旦不为空则开始消费。生成者放置数据没有异常,消费者消费数据也没有异常。最终消费者成功地消费了3个数据。NF(full_num,缓冲区数据的数量)的值也是0,1,0,1的胶体
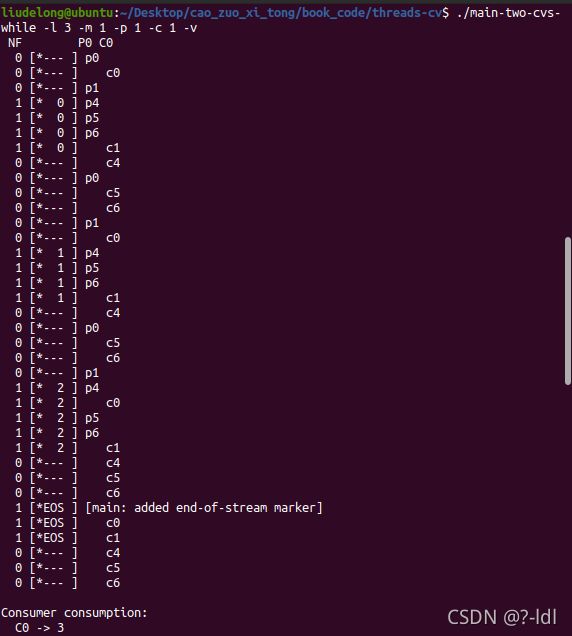

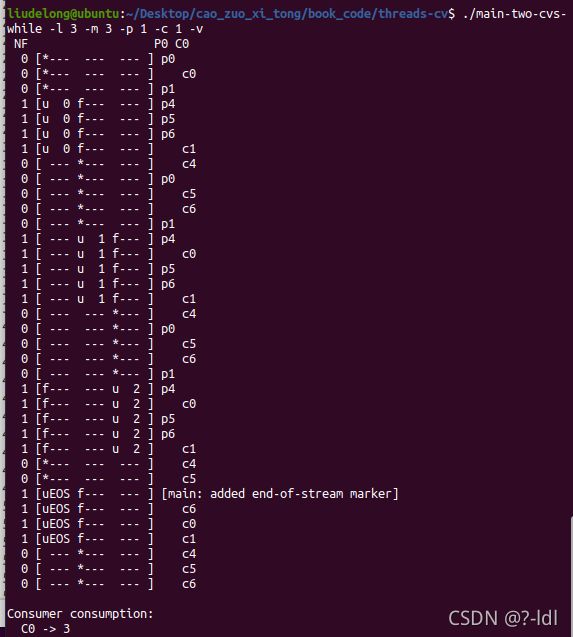
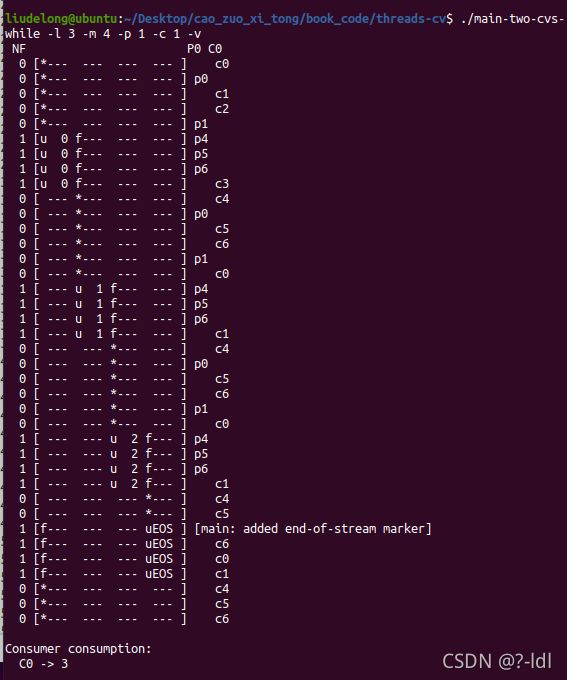
./main-two-cvs-while -l 100 -m 10 -p 1 -c 1 -v -C 0,0,0,0,0,0,1
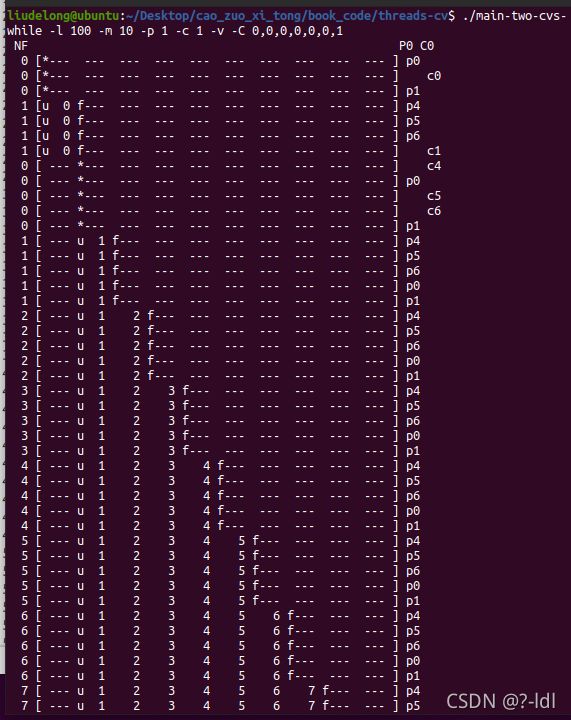

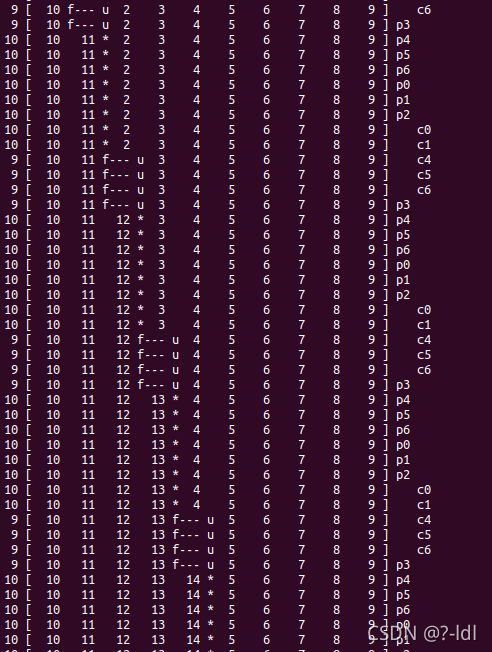

可以看到,在这个设置下,消费者会等待仓库满的时候才开始消费。一旦消费一个,生产者就会立刻生成一个让仓库重新变成满。直到最后生成者不生产了,消费者才开始把仓库清空。
30.4 我们来看一些 timings。 对于一个生产者,三个消费者,大小为 1 的共享缓冲区以及每个消费者在 c3 点暂停一秒,您认需要执行多长时间?(./main-two-cvs-while -p 1 -c 3 -m 1 -C 0,0,0,1,0,0,0:0,0,0,1,0,0,0:0,0,0,1,0,0,0 -l 10 -v -t)
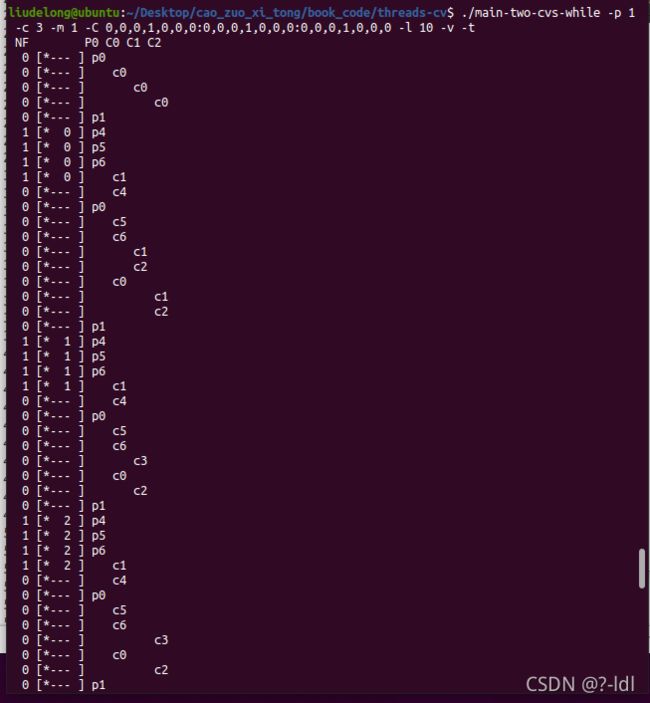

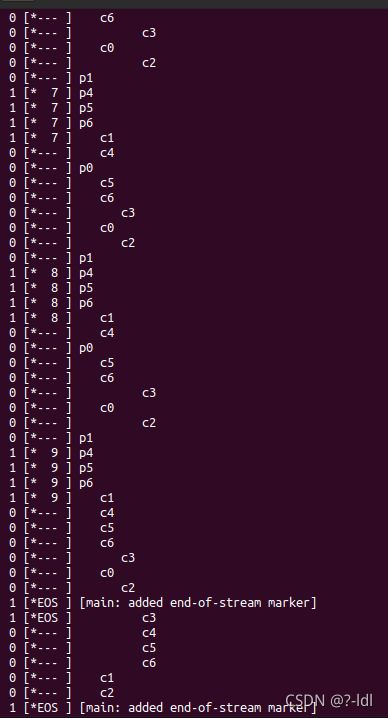

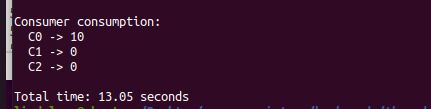
不同次运行同样的命令,每次的运行时间不一致。但至少10s,因为消费者会取出10个数据。每取一个都会有1s的休眠。
30.8 现在让我们看一下 main-one-cv-while.c。您是否可以假设只有一个生产者,一个消费者和一个大小为 1 的缓冲区,配置一个睡眠字符串,让代码运行出现问题
一个生产者和一个消费者不会出现问题。
30.9 现在将消费者数量更改为两个。 为生产者消费者配置睡眠字符串,从而使代码运行出现问题。
./main-one-cv-while -p 1 -c 2 -m 1 -C 0,0,0,3:0,0,0,3 -P 1 -l 2 -v -t
即使不配置睡眠字符串,也可能出现如下情况:
生产者生产后,缓冲区满了,唤醒了两个正在睡眠的消费者中的一个,然后进入睡眠(Mutex_lock)
消费者消费后,唤醒另一个消费者,进入睡眠(Mutex_lock),
新的消费者线程被唤醒,发现缓冲区为空,进入睡眠(Cond_wait),此时三个线程都进入睡眠
无法配置睡眠字符串,使得代码运行必定出现问题,取决与操作系统的线程调度
我尝试通过休眠字符干预程序的线程调度,想法是这样的,模拟课本引发问题的顺序:
生产者线程先运行,在p0处强制睡眠,让消费者先执行。让两个消费者都一直运行到c3处后强行睡眠,使得生产者可以在p5唤醒一个消费者后继续执行,而不是切换到消费者线程。生产者一直运行直到运行到第二次p3。然后c1运行,消费,消费完后唤醒c2,c2起来消费,发现为空。睡眠。这时候3个对象都进入睡眠。
但在实践中发现是这个样子的:

消费者运行到c2后就不再运行了,无论怎么配置睡眠因子,都不能使得一个消费者一口气执行完c0~c3。无论如何都会在c2处穿插运行一个生产者。
而且有一点非常奇怪就是红色方框下面那个c3,它执行完后立刻就变c4了。而代码逻辑是:

c3无论如何都得经过一个c2才能到c4。
所以得到两个问题使得我怀疑程序的正确性:
- 无法通过睡眠因子控制调度。(理论上是可以的,只需要在不希望某个线程执行的时候加个睡眠因子使他无法被调度而被迫执行其他线程)
- 加入睡眠因子后,程序的逻辑竟然不合理了,c3竟然可以不经过c2直接执行c4。
但我认为我的配置是正确的,也就是:
./main-one-cv-while -p 1 -c 2 -m 1 -C 0,0,0,3:0,0,0,3 -P 1 -l 2 -v -t
只是程序有问题(我有较大把握认为程序有问题),导致我运行不出想要的结果
后来经过讨论,发现课本的方案确实不好实现,跳出课本的限制。想另一种方案。
经过与同学讨论,得到了一个可以让所有线程都休眠的配置方案:
./main-one-cv-while -p 1 -c 2 -m 1 -P 0,0,0,0,0,0,1 -l 2 -v -t
最后会卡住,达到效果。其原理和课本的不同。
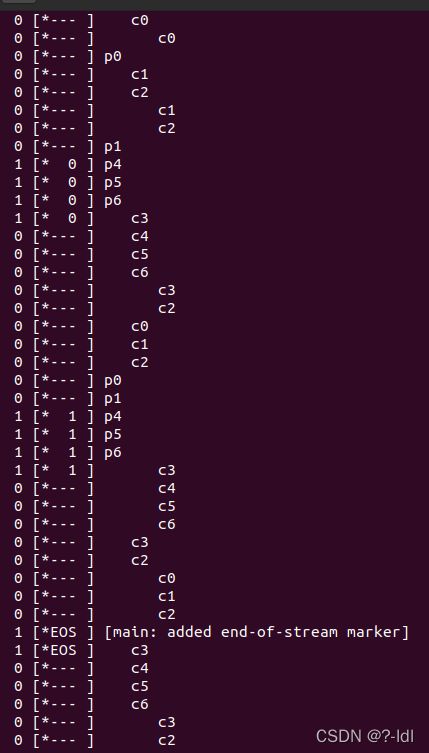
课本是让生产者和消费者1睡,消费者2起导致异常。具体顺序为:生产者睡->消费者1"消费完”"睡之前"唤醒消费者2(按照逻辑它应该唤醒生产者才不会错)。这里对调度干预非常严格,严格在"消费完”,“睡之前”这个两个动作必须是原子操作。可以看到:
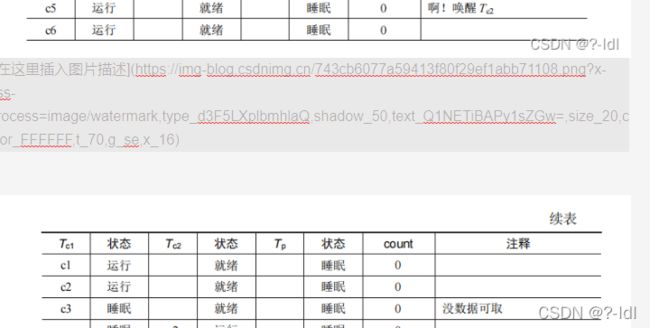
c6(消费完)之后要马上执行c1c2c3(睡之前),这个要求是没办法确定的。这个程序的调度算法并没有让c6(消费完)执行后马上执行c1(睡之前)的机制。因此课本的方案无法复现。
同学这个方案能成功的原理是让生产者和消费者1死,消费者1死之前唤醒消费者2。此时只有消费者2,但消费者2的动作是:睡。它一旦睡了,由于生产者和消费者已经死了,不会有人再叫醒2了,2会一直睡下去。
这里,第4行,生产者生产完一个结束位后线程死亡。消费者1消费完这个结束位后线程死亡,死之前还叫醒了消费者2。

30.10 现在查看 main-two-cvs-if.c。 您是否可以配置一些参数让代码运行出现问题?
再次考虑只有一个消费者的情况,然后再考虑有一个以上消费者的情况。
一个消费者一个生产者不会出现问题
一个生产者,两个消费者在下面情况会出现问题
生产者生产完成时,消费者 1 还停在c0,消费者 c2 在 Cond_wait (c3)处强制休眠。
生产者唤醒一个消费者2,但消费者1抢先执行,执行完后缓冲区为空,c2 开始执行,发现缓冲区为空,执行发生错误!
./main-two-cvs-if -m 1 -c 2 -p 1 -l 10 -C 2:0,0,0,3 -P 1

30.11 最后查看 main-cvs-while-extra-unlock.c。在向缓冲区添加或取出元素时释放锁时会出现什么问题? 给定睡眠字符串来引起这类问题的发生? 会造成什么不好的结果?
do_get 和 do_fill 在锁外面,这锁等于没加
第三十一章(1,2,4,5,6)
31.1第一个问题就是实现和测试 fork/join 问题的解决方案,如本文所述。 即使在文本中描述了此解决方案,重新自己实现一遍也是值得的。 even Bach would rewrite Vivaldi,allowing one soon-to-be master to learn from an existing one。有关详细信息,请参见 fork-join.c。 将添加 sleep(1) 到 child 函数内以确保其正常工作。
这个问题是让我们补全fork-join.c
fork-join.c如下:

要求按顺序打印:
parent:begin
child
parent:end
补全如下:
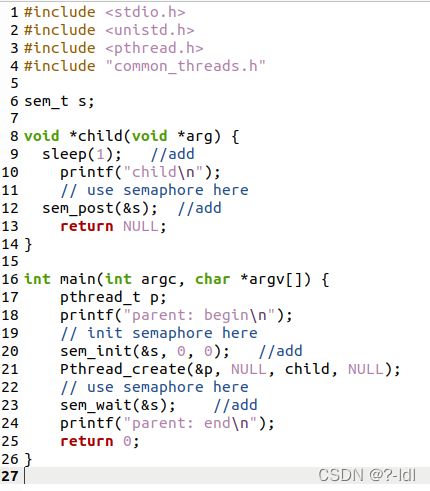
运行:

31.2 现在,我们通过研究集合点问题 rendezvous problem 来对此进行概括。 问题如下:您有两个线程,每个线程将要在代码中进入集合点。 任何一方都不应在另一方进入之前退出代码的这一部分。 该任务使用两个信号量,有关详细信息,请参见 rendezvous.c。
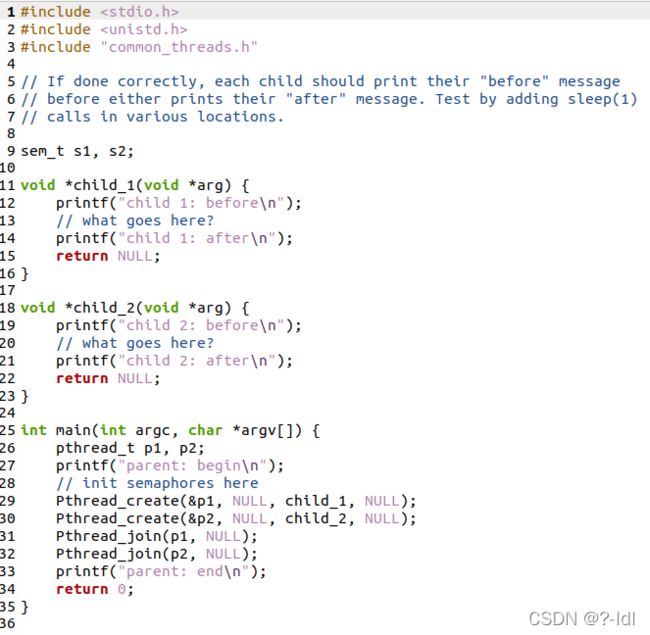
要求先打印两个before,再打印两个after
补全如下:
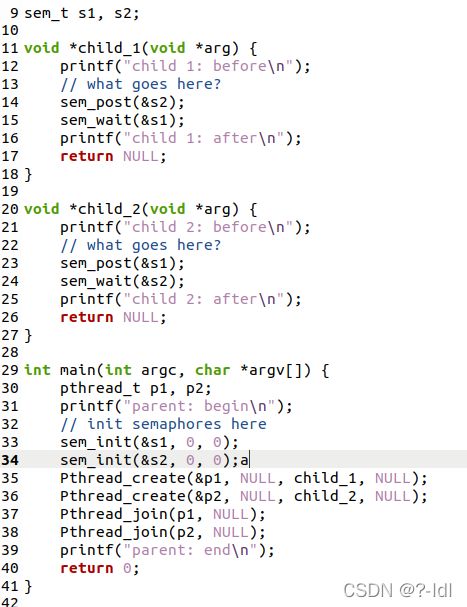
执行如下:
31.4 现在按照文本中所述,解决读者写者问题。 首先,不用考虑进程饥饿。 有关详细信息,请参见 reader-writer.c 中的代码。 将 sleep()调用添加到您的代码中,以证明它可以按预期工作****。 你能证明饥饿问题的存在吗?

这是让我们完成读写锁的实现

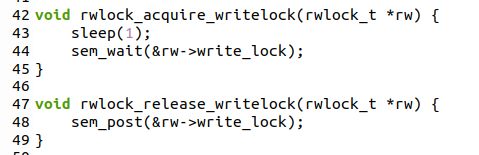
./reader-writer 5 5 10
程序三个参数分别为读者数,写者数,每个读者、写者进行的读写操作数
当读者数量远大于写者时,写者可能饿死,读者不需要锁就能进入临界区,只要有一个读者获得锁,
其他读者线程就能运行,读者数量可能一直大于0,而写者始终无法获取锁
运行结果
liudelong@ubuntu:~/Desktop/cao_zuo_xi_tong/book_code/threads-sema$ gcc -o reader-writer reader-writer.c -Wall -pthread
liudelong@ubuntu:~/Desktop/cao_zuo_xi_tong/book_code/threads-sema$ ./reader-writer
reader-writer: reader-writer.c:82: main: Assertion `argc == 4' failed.
Aborted (core dumped)
liudelong@ubuntu:~/Desktop/cao_zuo_xi_tong/book_code/threads-sema$ ./reader-writer 5 5 10
begin
read 0
read 0
read 0
read 0
write 1
write 2
write 3
write 4
write 5
read 5
read 5
read 5
read 5
read 5
write 6
write 7
write 8
write 9
write 10
read 10
read 10
read 10
read 10
read 10
write 11
write 12
write 13
write 14
write 15
read 15
read 15
read 15
read 15
write 16
write 17
read 17
write 18
write 19
write 20
read 20
read 20
read 20
write 21
read 21
write 22
read 22
write 23
write 24
write 25
read 25
read 25
write 26
read 26
write 27
read 27
read 27
write 28
write 29
write 30
read 30
write 31
read 31
write 32
read 32
read 32
read 32
write 33
write 34
write 35
read 35
read 35
write 36
read 36
read 36
read 36
write 37
write 38
write 39
write 40
read 40
write 41
read 41
read 41
read 41
write 42
write 43
write 44
read 44
write 45
read 45
read 45
read 45
read 45
write 46
write 47
write 48
read 48
write 49
write 50
read 50
end: value 50
31.5 让我们再次看一下读者写者问题,但这一次需要考虑进程饥饿。 您如何确保所有读者和写者运行? 有关详细信息,请参见 reader-writer-nostarve.c。

新增 write_waiting 锁,写者读者都需要竞争这个锁。新增读者要持有这把锁,写者进行写也要持有这把锁,一旦写者抢到了这把锁,就不能增加新读者,直到写者完成写(写者要等当前所有读者离开才能写)


编译运行:
liudelong@ubuntu:~/Desktop/cao_zuo_xi_tong/book_code/threads-sema$ ./reader-writer-nostarve
reader-writer-nostarve: reader-writer-nostarve.c:87: main: Assertion `argc == 4' failed.
Aborted (core dumped)
liudelong@ubuntu:~/Desktop/cao_zuo_xi_tong/book_code/threads-sema$ ./reader-writer-nostarve 5 5 10
begin
read 0
read 0
read 0
read 0
read 0
write 1
write 2
write 3
write 4
write 5
read 5
read 5
read 5
read 5
read 5
write 6
write 7
write 8
write 9
write 10
read 10
read 10
read 10
read 10
read 10
write 11
write 12
write 13
write 14
write 15
read 15
read 15
read 15
read 15
read 15
write 16
write 17
write 18
write 19
write 20
read 20
read 20
read 20
read 20
read 20
write 21
write 22
write 23
write 24
write 25
read 25
read 25
read 25
read 25
read 25
write 26
write 27
write 28
write 29
write 30
read 30
read 30
read 30
read 30
write 31
write 32
read 32
write 33
write 34
write 35
read 35
read 35
read 35
read 35
write 36
write 37
read 37
write 38
write 39
write 40
read 40
read 40
read 40
write 41
read 41
write 42
read 42
write 43
write 44
write 45
read 45
read 45
write 46
read 46
write 47
read 47
write 48
write 49
read 49
write 50
end: value 50
31.6 使用信号量构建一个没有饥饿的互斥量,其中任何试图获取该互斥量的线程都将最终获得它。 有关更多信息,请参见 mutex-nostarve.c 中的代码。
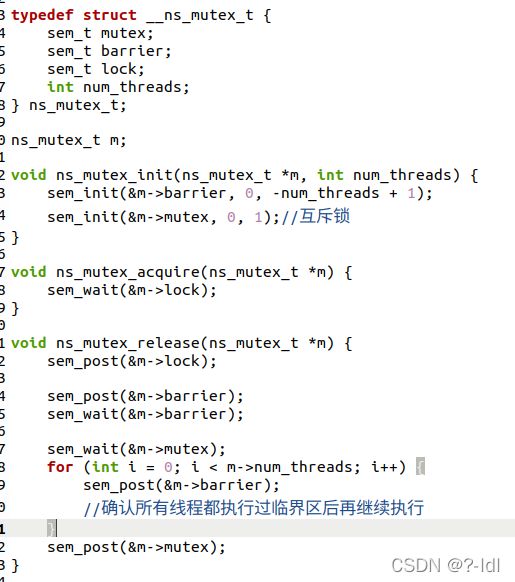
释放临界区锁后,确认所有线程都执行过临界区后再继续执行