一篇文章梳理清楚 Python 多线程与多进程

在学习Python的过程中,有接触到多线程编程相关的知识点,先前一直都没有彻底的搞明白。今天准备花一些时间,把里面的细节尽可能的梳理清楚。
线程与进程的区别
进程(process)和线程(thread)是操作系统的基本概念,但是它们比较抽象,不容易掌握。关于多进程和多线程,教科书上最经典的一句话是“ 进程是资源分配的最小单位,线程是CPU调度的最小单位 ”。线程是程序中一个单一的顺序控制流程。进程内一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位指运行中的程序的调度单位。在单个程序中同时运行多个线程完成不同的工作,称为多线程。

进程和线程区别
进程是资源分配的基本单位。所有与该进程有关的资源,都被记录在进程控制块PCB中。以表示该进程拥有这些资源或正在使用它们。另外,进程也是抢占处理机的调度单位,它拥有一个完整的虚拟地址空间。当进程发生调度时,不同的进程拥有不同的虚拟地址空间,而同一进程内的不同线程共享同一地址空间。
与进程相对应,线程与资源分配无关,它属于某一个进程,并与进程内的其他线程一起共享进程的资源。线程只由相关堆栈(系统栈或用户栈)寄存器和线程控制表TCB组成。寄存器可被用来存储线程内的局部变量,但不能存储其他线程的相关变量。
通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源。在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。
由于线程比进程更小,基本上不拥有系统资源,故对它的调度所付出的开销就会小得多,能更高效的提高系统内多个程序间并发执行的程度,从而显著提高系统资源的利用率和吞吐量。
因而近年来推出的通用操作系统都引入了线程,以便进一步提高系统的并发性,并把它视为现代操作系统的一个重要指标。

线程与进程的区别可以归纳为以下4点:
-
地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
-
通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
-
调度和切换:线程上下文切换比进程上下文切换要快得多。
-
在多线程OS中,进程不是一个可执行的实体。
多进程和多线程的比较
| 对比维度 | 多进程 | 多线程 | 总结 |
|---|---|---|---|
| 数据共享、同步 | 数据共享复杂,同步简单 | 数据共享简单,同步复杂 | 各有优劣 |
| 内存、CPU | 占用内存多,切换复杂,CPU利用率低 | 占用内存少,切换简单,CPU利用率高 | 线程占优 |
| 创建、销毁、切换 | 复杂,速度慢 | 简单,速度快 | 线程占优 |
| 编程、调试 | 编程简单,调试简单 | 编程复杂,调试复杂 | 进程占优 |
| 可靠性 | 进程间不会互相影响 | 一个线程挂掉将导致整个进程挂掉 | 进程占优 |
| 分布式 | 适用于多核、多机,扩展到多台机器简单 | 适合于多核 | 进程占优 |
总结,进程和线程还可以类比为火车和车厢:
-
线程在进程下行进(单纯的车厢无法运行)
-
一个进程可以包含多个线程(一辆火车可以有多个车厢)
-
不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
-
同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
-
进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
-
进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到该趟火车的所有车厢)
-
进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
-
进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-”互斥锁(mutex)”
-
进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量(semaphore)”
Python全局解释器锁GIL
全局解释器锁(英语:Global Interpreter Lock,缩写GIL),并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。由于CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。那么CPython实现中的GIL又是什么呢?来看看官方的解释:
The mechanism used by the CPython interpreter to assure that only one thread executes Python bytecode at a time. This simplifies the CPython implementation by making the object model (including critical built-in types such as dict) implicitly safe against concurrent access. Locking the entire interpreter makes it easier for the interpreter to be multi-threaded, at the expense of much of the parallelism afforded by multi-processor machines.
Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
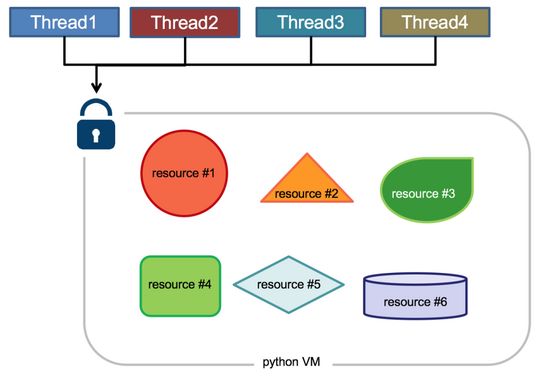
GIL 有什么好处?简单来说,它在单线程的情况更快,并且在和 C 库结合时更方便,而且不用考虑线程安全问题,这也是早期 Python 最常见的应用场景和优势。另外,GIL的设计简化了CPython的实现,使得对象模型,包括关键的内建类型如字典,都是隐含可以并发访问的。锁住全局解释器使得比较容易的实现对多线程的支持,但也损失了多处理器主机的并行计算能力。
在多线程环境中,Python 虚拟机按以下方式执行:
-
设置GIL
-
切换到一个线程去运行
-
运行直至指定数量的字节码指令,或者线程主动让出控制(可以调用sleep(0))
-
把线程设置为睡眠状态
-
解锁GIL
-
再次重复以上所有步骤

Python3.2前,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100(ticks可以看作是python自身的一个计数器,专门做用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整),进行释放。因为计算密集型线程在释放GIL之后又会立即去申请GIL,并且通常在其它线程还没有调度完之前它就已经重新获取到了GIL,就会导致一旦计算密集型线程获得了GIL,那么它在很长一段时间内都将占据GIL,甚至一直到该线程执行结束。
Python 3.2开始使用新的GIL。新的GIL实现中用一个固定的超时时间来指示当前的线程放弃全局锁。在当前线程保持这个锁,且其他线程请求这个锁时,当前线程就会在5毫秒后被强制释放该锁。该改进在单核的情况下,对于单个线程长期占用GIL的情况有所好转。
在单核CPU上,数百次的间隔检查才会导致一次线程切换。在多核CPU上,存在严重的线程颠簸(thrashing)。而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。单核下多线程,每次释放GIL,唤醒的那个线程都能获取到GIL锁,所以能够无缝执行,但多核下,CPU0释放GIL后,其他CPU上的线程都会进行竞争,但GIL可能会马上又被CPU0拿到,导致其他几个CPU上被唤醒后的线程会醒着等待到切换时间后又进入待调度状态,这样会造成线程颠簸(thrashing),导致效率更低。
另外,从上面的实现机制可以推导出,Python的多线程对IO密集型代码要比CPU密集型代码更加友好。
针对GIL的应对措施:
-
使用更高版本Python(对GIL机制进行了优化)
-
使用多进程替换多线程(多进程之间没有GIL,但是进程本身的资源消耗较多)
-
指定cpu运行线程(使用affinity模块)
-
使用Jython、IronPython等无GIL解释器
-
全IO密集型任务时才使用多线程
-
使用协程(高效的单线程模式,也称微线程;通常与多进程配合使用)
-
将关键组件用C/C++编写为Python扩展,通过ctypes使Python程序直接调用C语言编译的动态链接库的导出函数。(with nogil调出GIL限制)
Python的多进程包multiprocessing
Python的threading包主要运用多线程的开发,但由于GIL的存在,Python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,大部分情况需要使用多进程。在Python 2.6版本的时候引入了multiprocessing包,它完整的复制了一套threading所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。
借助这个multiprocessing,你可以轻松完成从单进程到并发执行的转换。multiprocessing支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
Multiprocessing产生的背景
除了应对Python的GIL以外,产生multiprocessing的另外一个原因时Windows操作系统与Linux/Unix系统的不一致。
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(父进程)复制了一份(子进程),然后,分别在父进程和子进程内返回。子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getpid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os
print('Process (%s) start...'