前端工程师怎么写后端?试试 koa.js + Apache APISIX 吧~
前言
两年前,我还是一个小白开发者。当时为了上线我开发的一个网站购买了一个学生服务器,并且安装了 linux 服务器的小白之友 宝塔面板 ,相信现在还有很多朋友买到服务器了第一件事就是装个宝塔。在宝塔面板中,我使用了内置的脚本快速的安装了 nginx + mysql + phpAdmin 全家桶。虽然很快就安装上去了,但是当时的我对于 nginx 一窍不通,在部署服务端功能的时候随便遇到一个小问题都能卡我一天,导致我最后折腾了快一周才把项目部署上去。
作为一个前端开发,我有很多自己写的小项目都是通过 node.js 实现服务端的,对于前端开发来说,node.js 上手非常友好,前端后端都可以 js 一把梭 ,但是一旦遇到服务器上的问题就非常容易卡壳,尤其是对于 linux 的命令不了解的朋友们更是致命。
最近我尝试了一下使用 Apache APISIX 替代 Nginx 进行一个简单的后端开发部署,在不需要配置 nginx.conf 文件的情况下通过可视化的面板配置我的 api ,我发现这样的方式会对不懂 nginx 的小伙伴非常友好。
Apache APISIX 介绍
node.js 相信大家都很熟悉了,但是估计对于前端开发来说可能 Apache APISIX 了解的并不多,下面是官方的介绍:
Apache APISIX 是一个动态、实时、高性能的 API 网关,提供负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功能。作为 API 网关,Apache APISIX 不仅拥有众多实用的插件,而且支持插件动态变更、热插拔和开发自定义插件。
简单来说就是 Apache APISIX 和 nginx 一样是一个 API 网关,但是它额外集成了很多插件之类的功能,而且还有一个可视化的控制台来配置我们的路由和插件。
那么为什么我们可以用 Apache APISIX 来替代 nginx 嘞,主要有两点原因:
- 可视化的控制面板,对于小白来说就不需要手动修改 nginx 的配置了。
- 大量插件可以使用,我们可以将很多以前在后端写的功能直接配置插件,可以省去很多业务代码。
官方文档及仓库如下:
Apache APISIX 官方文档
Apache APISIX github 仓库
开发环境搭建
以下操作均基于 centos7 系统进行开发
Node.js 安装
既然我们是使用 node.js 作为服务端,那么 node.js 的环境肯定是少不了的,在 centos 中安装 node.js 也很方便,执行以下命令安装:
sudo yum -y install nodejs
Apache APISIX 安装
Apache APISIX 使用源码安装的话比较麻烦,所以我推荐使用 docker compose 进行安装,所以我们得安装 docker 和 docker compose ,安装方式可以参考菜鸟教程的这两篇文章:
#CentOS Docker 安装
# Docker Compose
在 docker 和 docker compose 都安装完成后,我们可以开始进行 Apache APISIX 的安装,执行以下命令就可以将 Apache APISIX 相关的容器启动,启动的具体容器可以参考这个文件 apisix-docker github仓库,其中是包括了 apisix 和 apisix dashboard 这两个服务容器的。
git clone https://github.com/apache/apisix-docker
cd apisixdocker/example
docker-compose -p docker-apisix up -d
启动后执行 docker ps ,可以看到打印出来很多个容器,如下图:

apisix 的服务是默认运行在 9080 端口的,而可视化面板 apisix dashboard 则是在 9000 端口。如果你是跑在云服务器上可以使用 服务器外网ip:9000 访问 apisix dashboard ,如果你是通过 vscode ssh remote 在服务器上开发,也可以通过 vscode 的端口映射更加方便的访问,操作方式如下:
首先找到 vscode 底部的一个信号塔小按钮,位置如下图:

点击以下按钮会弹出这个窗口,点一下 Forward a Port。

输入 9000 端口后,映射就设置好了。

设置完成后,直接打开浏览器,访问 localhost:9000 就可以进入 apisix dashboard 的页面了。效果如下图:
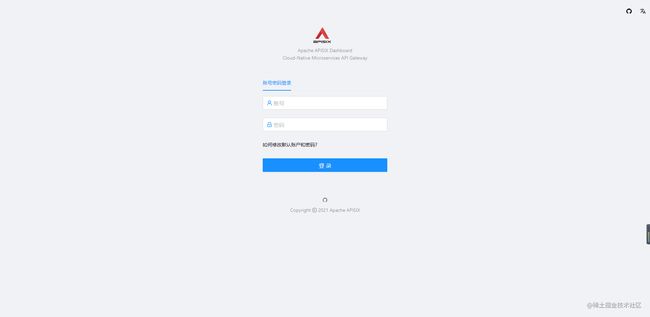
默认的账号密码都是 admin ,输入后即可进入。这个网站使用的组件库是 ant design ,左侧是一个菜单,对应的一些概念可以看上面的官方文档。

最小化服务搭建
在以上操作后,基础的环境都已经搭建好了,接下来我们就模拟一下咱们正常的后端开发过程,看看在这个过程中如何将 Node.js 和 Apache APISIX 搭配使用。
搭建基本后端服务
后端我将使用 koa.js 这个框架来构建服务,首先我们创建一下项目目录:
mkdir server
cd server
touch app.js
接下来初始化一下 package.json , 执行 npm init , 然后一路回车即可。目录结构如下图:
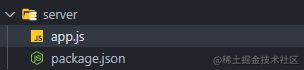
然后我们执行 npm i koa 安装 koa ,并在 app.js 中写入以下代码:
const Koa = require('koa');
const app = new Koa();
app.use(async ctx => {
ctx.body = 'Hello World';
});
app.listen(3100);
执行 node app.js 我们就将一个最小化的服务启动在了 3100 端口,启动后我们执行 curl localhost:3100 ,如果打印了 Hello World 说明服务已经启动成功了。
创建 Apisix 路由
在服务启动成功后,我们当然不能直接通过 3100 端口访问服务,而是需要让 Apisix 代理我们访问服务,就像 nginx 那样。添加路由有很多种方式,我们可以使用命令行或者可视化的网页,当然门槛最低最直观的还是可视化的形式去配置啦。
所以接下来我们在浏览器中访问刚刚启动的 apisix dashboard ,点击进入路由菜单,点击右上角的添加按钮,我们需要添加一个新的路由。

添加路由一共有四个步骤,如下图:

-
首先设置路由信息,我们填写路由名称为
koa-server, 路径我们填写/koa,其他非必选的都不填。
-
接下来设置上游服务信息,上游其实就是咱们启动在
3100的那个 koa 的服务,所以只填写目标节点的主机名,其他非必选都不填。

注意点:这里使用的主机名并非
localhost而是172.17.0.1,这是因为 docker 中的容器是没办法直>接访问到宿主机端口的,需要通过 bridge docker0 作为对外的网桥,而在 linux 中一般 docker0 的 ip 为 >172.17.0.1,在 windows 中为host.docker.internal,在 macOS 中为 >docker.for.mac.host.internal.。如果以上 ip 都不能访问到上游服务,你可以使用
ip addr show docker0命令查询
-
进入下一步我们可以看到有很多的插件,左侧是插件分类,我们可以自由编排或者配置插件,这些插件可以替代很多我们过去在后端服务中需要实现的功能,这里我们先不配置,直接进入下一步。

-
最后一步就是预览前面的所有配置信息,点击右小角提交,我们就完成了一个路由的创建。返回路由列表后就可以看到我们创建的路由。

创建路由后,我们要测试一下路由可不可以代理到我们的 koa 服务上,使用 curl -i localhost:9080/koa 看看打印出来的结果,下图中我们可以看到请求头中的 server 字段已经是 apisix 的版本号了,请求体也正常返回,说明我们这个路由就配置完成啦 ~

功能开发
以下介绍一些常用的后端与 api 网关相互搭配的功能,即使对于个人开发者也非常实用噢。
反向代理解决跨域
首先是在前端项目部署上线一定会遇到的一个问题——跨域,由于现在大部分项目都是前后端分离的,而前端站点由于同源策略没办法直接通过后端的域名或者 ip 来访问服务,解决跨域又很多种方式,其中反向代理应该是应用比较广泛的一种方式,因此我们可以通过网关来配置反向代理。
反向代理的原理大致为:既然前端没法跨域访问其他域名,那就让前端直接访问 前端的域名/一个特殊的路径 ,然后网关匹配到这个特殊的路径就会去代理前端访问后端的url,并将后端的返回结果再给到前端。
一般我们在 nginx 中是通过修改 nginx.conf 文件实现的:
location /api {
rewrite ^.+api/?(.*)$ /$1 break;
include uwsgi_params;
proxy_pass http://localhost:3000/;
}
通过在 server 中匹配一个特殊路径 /api,再通过 proxy_pass 配置代理发送的 url ,就可以将我们的请求转发到这个 url 上了。
而在 Apache APISIX 中,其实我们在上面创建路由的过程中就是配置了一个反向代理了,我们将 ip:9080/koa 的请求代理到了 ip:3100 这个服务上,如果我们想要代理到其他服务器,直接在路由中修改配置即可~

如果你不想要 apisix 跑在 9080,而是想要直接用 80 端口方便浏览器访问的话,如果你是使用 docker-compose 启动服务,那么你得修改一下 /example/docker-compose.yml 中 apisix 服务映射的端口。

如果你是通过源码启动的服务,可以在 /conf/config-default.yaml 文件中修改 node_listen 修改 apisix 服务的端口。

jwt-auth 实现用户鉴权
在前端向后端发送请求时,为了确认请求是合法的,在用户登陆后后端会返回一个 token 给前端,在之后的请求中前端会将 token 放置在请求头中,一般 token 是由用户信息、时间戳和由hash算法加密的签名构成的,当后端判断 token 错误或者过期就要求用户重新登陆获取 token。
在 node.js 中实现这个功能我们可以使用 jsonwebtoken 这个库,下面是基于这个库实现的 生成 token 和 检验 token 的方法。
const jwt = require("jsonwebtoken")
const auth = {
createToken(userId) {
// 根据userId生成token
const payload = {
userId,
time: new Date().getTime(),
timeout: 1000 * 60 * 60 * 48,
}
const token = jwt.sign(payload, config.tokenSecret)
return token
},
verifyToken(allowUrl) {
return async (ctx, next) => {
// 检验token是否有效,若无效则返回false
if (
allowUrl.indexOf(ctx.request.url) === -1
) {
if (!ctx.request.header.token) {
ctx.body = { code: 110, msg: "token无效" }
return
}
try {
const token = ctx.request.header.token
const payload = jwt.verify(
token,
config.tokenSecret
)
if (
payload.time + payload.timeout <
new Date().getTime()
) {
ctx.body = { code: 111, msg: "token过期" }
return
}
ctx.request.header.userId = payload.userId
await next()
} catch (err) {
ctx.body = {
code: 110,
msg: "token无效",
err: err.toString(),
}
return
}
} else {
await next()
}
}
},
}
module.exports = auth
在上面的方法中,我们可以通过 createToken 方法传入 userId 生成 token,通过 verifyToken 方法进行
对 token 的判断,参数 allowUrl 可以传入一个数组,设置一个白名单,例如登陆接口之类的请求就可以跳过判断了。
整体是实现了一个 koa 的中间件,使用的时候也非常简单,在项目的入口文件中引入并通过 use 方法使用即可。
// token验证
const { verifyToken } = require("./server/middleware/auth")
app.use(verifyToken(["/admin/login", "/user/login"]))
当然我这里只是简单的实现,实际项目中会有很多特殊情况,例如一些静态资源的访问之类的判断,还得根据实际需求出发~
下面讲讲在 Apache APISIX 中如何实现这个功能, Apache APISIX 有一个插件 jwt-auth 可以非常便捷的实现这个功能。
- 先增加一个消费者(Consumer):

- 然后启用一下 jwt-auth 插件,填写一下
key值:


- 最后在我们前面创建的路由
/koa也启用 jwt-auth 插件。

通过以上操作我们就开启了 jwt-auth 这个插件,接着我们测试一下,首先是创建 token,当我们开启插件后, Apache APISIX 会插件会增加 /apisix/plugin/jwt/sign 这个接口,通过 /apisix/plugin/jwt/sign 就可以创建 token ,我们需要将刚刚消费者的 key 传入这个 api,同时我们也可以额外附加一些数据在 payload 中,例如用户 id 等。
curl -G --data-urlencode 'payload={"uid":10000,"uname":"test"}' http://127.0.0.1:9080/apisix/plugin/jwt/sign?key=oiloil -i
响应的结果如下,请求体中那一串就是 token 的值:
HTTP/1.1 200 OK
Date: Thu, 10 Mar 2022 10:07:43 GMT
Content-Type: text/plain; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Server: APISIX/2.12.1
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1bmFtZSI6InRlc3QiLCJ1aWQiOjEwMDAwLCJleHAiOjE2NDY5OTMyNjMsImtleSI6Im9pbG9pbCJ9.VIRZ7Sxkm3gfUsvripE3FaqdweilrdljE-GuJjvsBoA
创建 token 后,我们再试一下鉴权功能,我们先不传 token 发个请求测试一下:
curl http://127.0.0.1:9080/koa -i
HTTP/1.1 401 Unauthorized...
{"message":"Missing JWT token in request"}
可以看到返回了状态码 401 和一个错误提示,接下来再在请求头 Authorization 字段带上 token 发个请求测试一下:
curl localhost:9080/koa -i -H 'Authorization:eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1bmFtZSI6InRlc3QiLCJ1aWQiOjEwMDAwLCJleHAiOjE2NDY5OTMyNjMsImtleSI6Im9pbG9pbCJ9.VIRZ7Sxkm3gfUsvripE3FaqdweilrdljE-GuJjvsBoA'
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Content-Length: 11
Connection: keep-alive
Date: Thu, 10 Mar 2022 10:18:49 GMT
Server: APISIX/2.12.1
Hello World
可以看到正确的返回了我们需要的数据,但是 Apache APISIX 的 jwt-auth 插件其实还有很多功能,而且安全性相比我们自己写的鉴权方法更加可靠一些,而且也不需要自己去实现了。
下面是官方文档中提供的一些可以传入的参数,从这些参数中咱们也可以了解到这个插件大概有啥功能。
| 名称 | 类型 | 必选项 | 默认值 | 有效值 | 描述 |
|---|---|---|---|---|---|
| key | string | 必须 | 不同的 consumer 对象应有不同的值,它应当是唯一的。不同 consumer 使用了相同的 key ,将会出现请求匹配异常。 |
||
| secret | string | 可选 | 加密秘钥。如果您未指定,后台将会自动帮您生成。 | ||
| public_key | string | 可选 | RSA 公钥, algorithm 属性选择 RS256 算法时必填 |
||
| private_key | string | 可选 | RSA 私钥, algorithm 属性选择 RS256 算法时必填 |
||
| algorithm | string | 可选 | “HS256” | [“HS256”, “HS512”, “RS256”] | 加密算法 |
| exp | integer | 可选 | 86400 | [1,…] | token 的超时时间 |
| base64_secret | boolean | 可选 | false | 密钥是否为 base64 编码 |
更多 Apache APISIX 功能
Apache APISIX 中还有很多插件适用性很广,例如请求 限流限速,rbac 鉴权 ,日志打印拓展 等等功能,都可以通过可视化的方式去配置,算是给了不了解 nginx 的同学一个更加直观的管理 api 的方式啦。
事实上以上这些应用场景都是比较简单的单体服务开发时使用 Apache APISIX 的好处,在微服务架构或者高负载应用场景下 Apache APISIX 更加能体现出它的优势。
koa 使用技巧
除了介绍 Apache APISIX 外,这里我还讲讲一些过去我使用 kao.js 这个框架进行服务端开发的一点小心得和一些很好用的库。
sequelize orm 框架
sequelize 是 node.js 的一个 orm 框架,所谓 orm 框架就是将关系型数据库中的数据关系映射为咱们程序中的对象里,简单来说就是 orm 可以把数据库中的每个表转换成 js 里的对象,对象里提供了增删查改相关的 api。而且还有一个好处就是表格的结构我们可以直接在代码里维护,不需要使用 sql 语句或者 navicat 这类工具单独进行操作了。
注意点: 只支持 mysql 5.7 以上版本使用噢。
安装
下面讲讲具体如何使用,我之前写的一个项目是使用 sequelize 连接 mysql 使用的,首先安装一下 sequelize:
npm i sequelize
初始化
然后我们新建一个 database.js 文件,写入以下代码:
const { Sequelize } = require("sequelize")
const db = new Sequelize(
config.db.database, // 数据库名
config.db.username, // 数据库用户名
config.db.password, // 数据库密码
{
host: config.db.host, // 数据库 host
dialect: "mysql",
dialectOptions: {
charset: 'utf8mb4',
dateStrings: true,
typeCast: (field, next) => { // for reading from database
if (field.type === 'DATETIME') {
return field.string()
}
return next()
},
},
timezone: "+08:00", // 中国时区
define: {
paranoid: true, // 假删除,删除数据后会为数据新增 deletedAt 字段并且不会被查询
freezeTableName: true, //Model名与表名相同
},
logging: false, // 打印执行过程日志
}
)
module.exports = db;
上面的操作就是初始化了一下 sequelize 并导出了一个 db 对象,其中的一些定义和操作,接下来我们需要定义一下表格的结构,这里以用户表举个例子:
// User.js
const { DataTypes } = require("sequelize")
const db = require("../database")
const User = db.define("user", {
id: {
type: DataTypes.INTEGER,
primaryKey: true,
notNull: true,
autoIncrement: true,
},
name: {
type: DataTypes.STRING,
notNull: true,
},
tel: {
type: DataTypes.STRING,
notNull: true,
},
intro: {
type: DataTypes.STRING,
notNull: true
}
})
module.exports = User
上面的代码还是非常直观的,我们引入前面初始化好的 db ,通过 db.define 将用户表的数据结构给定义好,并将 User 对象给暴露出来。之后我们就可以通过 User 对象来对 User 表进行操作啦,下面举个例子:
const userModel = require('../../model/User')
router.post("/login", async (ctx) => {
const [err, user] = await to(userModel.findOne({
where: { tel: params.tel }
}))
if (err) {
ctx.err('登录失败,请重试')
return
}
if (!user) {
ctx.suc('首次登录')
return
}
const { createToken } = require("../../middleware/auth")
const token = createToken(user.id)
ctx.suc('登录成功', { user, token })
})
这里是一个简单的登陆接口实现,我们根据传入的参数 tel 查询用户是否存在,将前面定义的 User 对象引入为 userModel,使用 userModel 的 findOne 方法进行查询,最后将结果返回,其他的数据表大致也是如此,直接使用对象中的 api 就可以操作或查询数据表啦。
联表操作
在关系型数据库中一般会存在大量的联表关系,例如一对多,一对一等,而在 sequelize 中如果使用需要使用联表查询这类操作,必须先声明好数据表之间的关系,因此我们可以创建一个新的文件用于维护表格间的关系。
// association.js
const User = require("./model/User")
const Experiment = require("./model/Experiment")
const db = require('./database')
const association = async () => {
try {
UserModel.hasMany(Experiment)
//... more association
} catch (error) {
console.log(error)
}
await db.sync({ alter: true}); // 同步到数据库中
}
上面的代码中我们将 User 和 Experiment 通过 hasMany api 设置了一对多的关系,也就是一个 User 拥有多个 Experiment 。我们可以将所有的数据表对象引入到这个文件中统一设置联表关系,然后再将表对象和表关系同步到数据库中,更多的联表 api 还得参考文档。
最后要记得将 association.js 在入口文件中调用一下.
// app.js
const Koa = require("koa")
const app = new Koa()
// 设置联表关系
const association = require("./server/association")
association()
app.listen(config.port)
当我们需要联表查询某些数据的时候可以使用 include 这个 api 进行联表查询,如下例:
router.get("/getExpDetail", async (ctx) => {
if (ctx.empty(['expId'])) {
return
}
const params = ctx.query
const [err, exp] = await to(expModel.findByPk(params.expId, {
include: [
{ model: require('../../model/User'), attributes: ['name'] },
]
}))
if (err) {
ctx.err('获取失败,请重试', err)
return
}
ctx.suc('获取成功', exp)
})
sequelize 还有很多的 api ,而且不同的项目使用方式也有很大不同,可以根据自己的业务决定使用方式。
异步编程
大家知道 koa 是一个提倡 async await 语法进行异步编程的框架。在上面的代码示例中,我经常使用 to 这个方法,比如:
const [err, user] = await to(userModel.findOne({
where: { tel: params.tel }
}))
这个方法是 await-to-js github链接 这个仓库的一个异步请求的包装器,可以用于处理异步请求的错误。
它的代码也很简单,就是使用 Promise.catch 帮我们把错误获取后将错误与结果拼接在数组中返回:
function to(promise, errorExt) {
return promise
.then(function (data) { return [null, data]; })
.catch(function (err) {
if (errorExt) {
Object.assign(err, errorExt);
}
return [err, undefined];
});
}
这样我们在异步编程的时候遇到错误就可以非常轻松的中止这个方法执行其他逻辑啦~
全局方法
像 to 方法这种几乎每个文件都会使用到的方法,如果手动引入的话可能会比较麻烦,咱们也可以通过 node.js 的全局变量 global 来挂载一些方法,这样我们在整个项目中都无需引入就可以直接使用了。
// app.js
const to = require('await-to-js')
global.to = to
如果你有很多方法都需要挂在你可以单独维护一个目录,如下图:

其中 index.js 是一个入口文件, 在这里读取同目录里所有的方法并统一挂载到 global 上:
// utils/index.js 全局方法入口
const fs = require('fs');
const utils = fs.readdirSync(__dirname);
utils.splice(utils.indexOf('index.js'), 1)
const importGlobal = () => {
for (let item of utils) {
let libName = item.replace('.js', '')
global[libName] = require('./' + item)
}
}
module.exports = importGlobal
然后在 app.js 中引入并执行:
// 引入全局配置
const importGlobal = require("./utils")
importGlobal()
当然这么做虽然方便,但是在团队人数较多的时候并不是一个好的选择,因为大家很难直观的看到这个全局变量或方法是如何引入的,所以尽量保证这个方法使用的地方特别多以及提供一定的注释以确保项目的可读性。
中间件
由于 koa 采用的是洋葱圈模型,上下文会一层一层的去处理,因此对于固定的上下文处理我们可以通过中间件来实现,例如我们想每个路由都 判断参数的有无,固定响应成功和响应失败的状态码 和 响应格式,我们可以像下面的代码实现一个中间件:
// 返回值中间件
const response = () => {
return async (ctx, next) => {
ctx.empty = (arr) => {
var isnull = []
const req =
ctx.request.method == "POST"
? ctx.request.body
: ctx.query
for (let item of arr) {
if (!req[item]) {
isnull.push(item)
}
}
if (isnull.length) {
ctx.body = {
code: -1,
msg: "缺少参数" + isnull.join("、"),
}
return true
}
return false
}
ctx.suc = (msg, data) => {
ctx.body = { code: 1, msg, data }
}
ctx.err = (msg, err) => {
ctx.body = {
code: -1,
msg,
err: err ? err.toString() : "",
}
}
await next()
}
}
module.exports = response
我们在 ctx 上挂载了三个方法 empty,suc,err,然后将中间件在入口文件中引入并使用:
const Koa = require("koa")
const app = new Koa()
// 配置请求返回
const response = require("./server/middleware/response")
app.use(response())
这样当我们在处理请求的时候就可以直接使用 ctx 上的这三个方法了,如下例子:
router.get("/getChapterDetail", async (ctx) => {
if (ctx.empty(['chapterId'])) {
return
}
const params = ctx.query
var [err, chapter] = await to(chapterModel.findByPk(params.chapterId))
if (err) {
ctx.err('获取失败,请重试', err)
return
}
ctx.suc('获取成功', { chapter })
})
更多
其实还有很多的开发实践的心得想要分享,如整体的项目结构组织,日志库的选择,路由的配置,项目的部署等等,但篇幅有限,我将在之后的文章中更加全面的介绍更多关于 node.js 的开发心得,欢迎点赞催更~
总结
随着前端技术的不断发展,node.js 使得 js 走向了更加广阔的舞台, 前端开发者可以只靠 js 独立完成一个完整的前后端 web 项目,如果再搭配一些优秀的库更是能为项目的整体的稳定和性能锦上添花。node.js 也成为了前端开发者必备的技能之一。
但后端与前端之间即使是使用相同的语言去开发,其中的思想也是有很大的区别的,但能够抹平语言的不同去探索一个新的领域就已经令人非常兴奋了,未来的技术一定会以更低的门槛吸引更多人参与到有趣的编程中!