Linux友人帐之Shell编程
一、bash简介
1.1shell概述
Shell是指操作系统提供给用户的一种交互式命令行接口,可以用来执行操作系统命令、任务和脚本等。操作系统中有很多种Shell,如Bash、Zsh、Fish等。Shell通常可以使用命令行参数、通配符、管道等特性来简化和优化命令行操作。此外,Shell还可以编写脚本,通过Shell脚本实现复杂的任务和流程控制。Shell在操作系统和开发中都有广泛的应用。
1.2Shell功能
- 操作系统其实是一组软件:管理整个硬件的功能;
- 用户需要操作系统:应用程序;
- 通过应用程序控制核心,让核心实现所需的硬件任务;
- 应用程序在最外面,像一个外壳(Shell)
- Shell的功能:提供用户操作系统的接口,可以调用其它软件。

1.3shell优点
- 不用distribution使用的bask都是相同的;
- 远程管理:速度快;
- 更好的管理主机。


这些是Linux和Unix操作系统上的shell解释器的路径。
/bin/sh和/usr/bin/sh都是指Bourne shell,是最早的Unix shell。
/bin/bash和/usr/bin/bash都是指Bash shell,是Bourne shell的一种替代品,也是Linux上最常用的shell解释器之一。
1.4bash shell
命令编辑功能;
- 命令与文件补全功能(tab);
- 命令别名的配置(alias);
- 工作控制、前台后台控制;
- shell scripts;
- 通配符(wildcard)。
1.5type命令

type命令用于查找指定命令或程序的位置和类型。其语法如下:
type [option] [name]常用选项包括:
- -a:显示命令的所有别名和命令路径。
- -t:仅显示命令类型,而不显示别名和路径。
- -p:仅显示命令路径,而不显示别名和类型。例如,查找ls命令的类型和路径,可以执行以下命令:
type -a ls输出可能类似于:
ls is aliased to 'ls --color=auto' ls is /usr/bin/ls ls is /bin/ls其中可以看到ls命令的别名以及两个路径,分别位于/usr/bin和/bin目录下。如果只想查看路径,可以执行:
type -p ls输出可能类似于:
/usr/bin/ls
二、基础入门
2.1shell变量
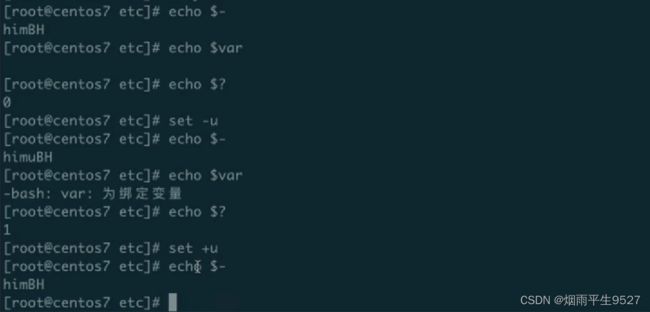
Linux Shell变量是用来存储值的容器。在Shell编程中,变量被用来存储数据,这些数据可以是字符串、数字或其他类型的数据。Shell变量可以包含任何数据类型,而且变量的命名可以是任何字母、数字或下划线的组合,但是变量名称不能以数字开头。注意:Linux是区分大小写的操作系统。
常见变量
1. 用户自定义变量:
name="John Doe"
age=302. 环境变量:
echo $HOME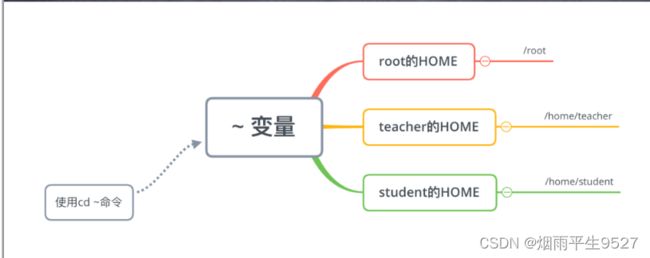
影响bash环境的变量
- 成功登录,使用shell;
- 获得bash运行程序;
- 系统通过一些变量来提供数据的存取,或一些环境的配置参数值;
- 将环境变量读入系统;
- PATH、HOME、HOSTNAME、SHELL;
- 环境变量通常大写。
3. 位置参数变量:
echo $0 $1 $24. 特殊变量:
echo $?
echo $$变量的显示

- 查看当前所有变量:可以使用
printenv或者env命令来查看当前系统中所有的环境变量。printenv- 查看单个变量:可以使用
echo命令来查看单个变量。echo $PATH
配置变量的规则
1.变量与变量内容以⼀个等号”=”进⾏连接:
myname=teacher
2.等号两边不能有空格符,错误示例:
myname = teacher
3.变量名称只能是英⽂字⺟与数字,但是开始的字符不能是数字,错误示例:
2myname=teacher4.变量内容中如果有空格符,可以使⽤双引号”或者单引号’,将变量内容结合起来,但两者存在区别:
- 双引号内的特殊字符,如$等,可以保持原有的特性:
var="lang is $LANG”; echo $var
lang is zh_CN.UTF-8
- 单引号内的特殊字符
var='lang is $LANG'; echo $var
lang is $LANG5.可⽤斜杠”\”,将特殊符号(如$、空格符、’等)变成⼀般字符:
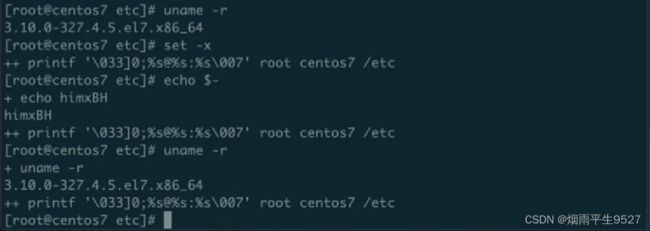
6.其他命令的返回值作为变量值的情况,可以使⽤`cmd`或$(cmd),如:
version=$(uname -r); echo $version
3.10.0-327.4.5.el7.x86_64
7.如果需要增加变量的内容,则可以使⽤$var或${var}累加内容,如:
PATH=“$PATH”:/home/bin8.如果该变量需要运⾏与其他⼦程序,则需要以export来使变量成为环境变量:
export PATH
9.通常⼤写字符为系统默认变量,⾃⾏配置的变量尽量使⽤⼩写字符,⽅便判断,⾮强制;
10.取消变量使⽤unset,unset var,如:
unset myname
2.2别名与历史命令
别名
别名的意义:
1.简化比较长的惯用命令;
2.限制导致严重后果命令的执行;
3.支持用户使用习惯。
alias 命令
在 Linux 操作系统中,alias 命令用于为长命令或一些常用命令设置短别名,以便更快速地输入命令,提高工作效率。alias 命令的常见用法如下:
1. 列出已经定义的别名:
alias2. 设置别名:
alias 别名='原命令'例如:
alias ls='ls --color=auto'这样我们每次输入 ls 命令时,实际执行的是带有彩色输出的 ls 命令。
3. 取消别名:
unalias 别名例如:
unalias ls这样就取消了之前设置的 ls 别名。
4. 将别名永久保存:
要使别名永久保存,需要将 alias 命令写入到 shell 配置文件中,例如:
vim ~/.bashrc在文件末尾添加需要设置的别名,保存后执行 source 命令使其生效:
source ~/.bashrc这样每次打开终端时,别名就会自动加载。
历史命令:history


2.3Bash Shell的操作环境
路径与命令搜索顺序
在 Linux 系统中,当用户输入命令或路径时,系统会按照以下顺序搜索:
1. 当前目录:系统会先在当前目录下查找是否存在该命令或路径。
2. 环境变量 PATH 中的目录:环境变量 PATH 存储了一组用冒号分隔的目录路径,系统会按照 PATH 中定义的目录顺序依次查找是否存在该命令或路径。
3. /sbin 目录:/sbin 目录存放的是系统管理员使用的命令或工具。
4. /usr/sbin 目录:/usr/sbin 目录存放的是系统管理员使用的非必须命令或工具。
5. /usr/local/bin 目录:/usr/local/bin 目录存放的是用户自行安装的软件,一般不会被系统升级替换。
如果系统无法在以上搜索路径中找到该命令或路径,则会提示“command not found”的错误信息。
bash的进站与欢迎信息:/etc/issue,/etc/motd
Linux Bash 的进站信息是在登录前显示的信息,而欢迎信息是在登录后显示的信息。
Linux系统中,进站信息通常存储在 /etc/issue 文件中,而欢迎信息通常存储在 /etc/motd 文件中。
/etc/issue 文件是在用户登录前显示的欢迎信息,通常包括操作系统版本、主机名、IP地址和其他系统信息。该文件可以通过编辑 /etc/issue 文件来更改欢迎信息。
/etc/motd 文件是在用户登录后显示的欢迎信息,通常包括操作系统版本、系统更新信息和其他系统信息。该文件可以通过编辑 /etc/motd 文件来更改欢迎信息。
这些文件都是纯文本文件,可以使用vi、nano或其他文本编辑器进行编辑。
环境配置文件

Linux Login Shell文件是一种特殊类型的脚本文件,用于在用户登录到Linux系统时执行特定的操作。该文件通常称为“登录脚本”。
登录脚本文件可以包含各种命令和脚本语句,例如设置环境变量、显示欢迎信息、运行特定的应用程序、配置别名等。当用户登录到系统时,登录脚本文件会自动在用户的登录 Shell 中执行。
在Linux系统中,有两种主要类型的登录 Shell 文件:系统级别的登录 Shell 文件和用户级别的登录 Shell 文件。
系统级别的登录 Shell 文件位于/etc目录下,系统级别的登录 Shell 文件对所有用户都起作用,而用户级别的登录 Shell 文件则位于用户主目录下的特定文件中,只对该用户有效。
在Linux系统中,常见的系统级别的登录 Shell文件包括:
- /etc/profile
- /etc/bashrc
- /etc/csh.login
- /etc/profile.d/而常见的用户级别的登录 Shell文件包括:
- ~/.bash_profile
- ~/.bash_login
- ~/.profile
- ~/.cshrc
- ~/.tcshrc以上是常见的Linux登录Shell文件,不同的Linux发行版可能会有一些不同。
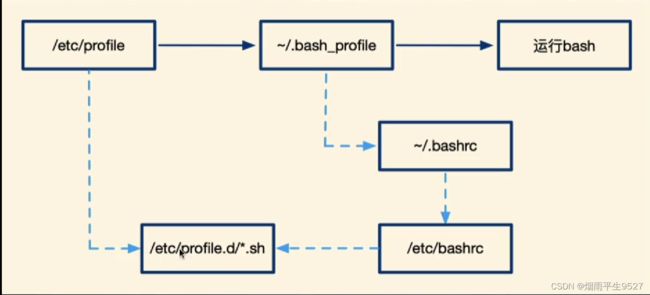
Linux的非登录shell文件是指用户已经登录之后在命令行中运行的shell文件,也称为交互式shell或终端shell。这些文件通常是以用户的身份运行的,而不是以root用户的身份运行的。常见的非登录shell文件包括以下:
1. .bashrc: 这是Bash shell的配置文件,它包含了用户环境变量、别名、命令提示符以及其他自定义设置。
2. .zshrc: 这是Zsh shell的配置文件,与.bashrc类似,它也包含了用户环境变量、别名、命令提示符以及其他自定义设置。
3. .profile: 这是在用户登录时第一个读取的文件。它包含了一些设置,例如环境变量以及用户的启动应用程序。
4. .bash_history: 这个文件记录了用户在Bash shell中执行的所有命令。
5. .zsh_history: 这个文件记录了用户在Zsh shell中执行的所有命令。
这些shell文件通常位于用户的主目录下。用户可以编辑这些文件,以自定义他们的Shell环境和命令行工具。
终端环境配置:stty,set
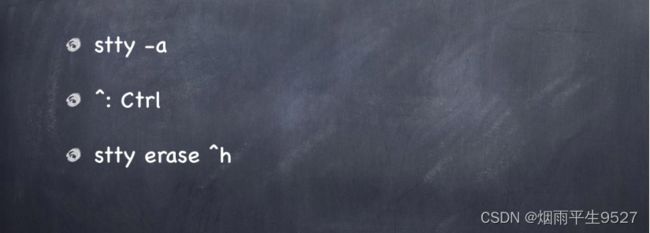
linux stty命令是一个用于设置或显示终端参数的命令。它可以用于设置终端控制台的模式和状态,包括回显、编辑、信号处理和流控制等。
常见的stty命令选项包括:
- -a:显示当前终端设备的全部设置。
- -echo:关闭回显功能,即输入的字符不会在终端上显示。
- echo:打开回显功能,即输入的字符会在终端上显示。
- -icanon:将终端设置为非标准模式,即关闭行缓冲和回车符处理。
- icanon:将终端设置为标准模式,即开启行缓冲和回车符处理。
- -inlcr:将输入的换行符转换为回车符。
- inlcr:将输入的回车符转换为换行符。
- -isig:关闭信号处理。
- isig:打开信号处理。例如,将终端设置为非标准模式并关闭回显功能,可以使用以下命令:
stty -icanon -echo要恢复默认设置,可以使用以下命令:
stty sane
stty命令

该命令用于显示当前终端设备的所有设置。其中包括以下内容:
1. 通信速率为38400 baud。
2. 终端窗口行数为41,列数为187。
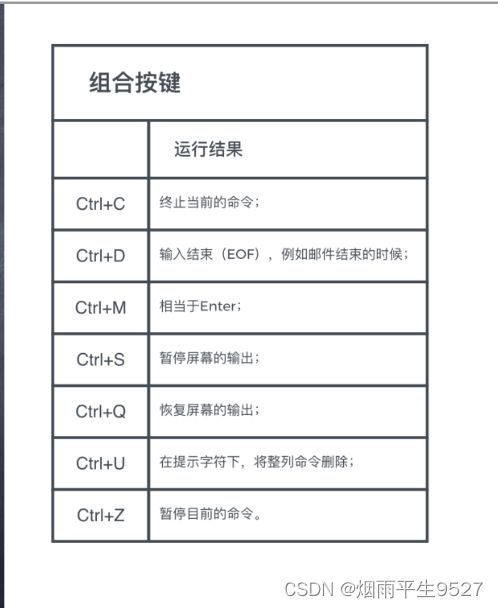
3. 按下CTRL+C可触发中断,CTRL+\可触发退出,CTRL+?可执行删除,CTRL+U可执行删除当前行,CTRL+D可执行结束输入。
4. swtch(切换)未定义。
5. start为CTRL+Q,stop为CTRL+S,susp为CTRL+Z(任务挂起),rprnt为CTRL+R,werase为CTRL+W,lnext为CTRL+V,flush为CTRL+O。
6. min为1,time为0,表示字符读取时最小等待时间为1个字符,没有最大等待时间。
7. 其他设置包括:不使用奇偶校验位,终端为8位字符组成,没有控制终端的挂起信号(hang up),没有使用两个停止位,启用接收器,忽略BREAK信号,中断处理程序中断(BRKINT),忽略奇偶校验错误,标记奇偶校验错误(使用PARMRK),输入字符不进行校验(INPCK),不剥离输入字符的第8个比特(ISTRIP),将输入中的回车符转换成换行符(ICRNL),启用输出流控制(IXON),禁用输入流控制(IXOFF),启用输入字符映射(IUCLC),禁用追加字符(IMAXBEL),启用UTF-8编码(IUTF8),启用输出处理(OPOST),不使用本地字符(OLCUC),将输出中的回车符转换成换行符(OCRNL),将输出中没有回车符的行末添加回车符(ONLCR),不执行回车符后的删除(ONOCR),输出后定位到下一行的开头(ONLRET),输出时不插入空字符(OFILL),不删除当前输出字符(OFDEL)。
8. 启用信号处理程序(ISIG),启用规范模式(ICANON),启用扩展输入字符(IEXTEN),启用回显(ECHO),启用ERASE字符处理(ECHOE),启用ERASE命令的可见提示(ECHOK),禁用NL即换行符的回显(ECHONL),在进程切换后,进程不会刷新输出缓冲区(NOFLSH),开启大写转换(XCASE),在进程被挂起时停止输出(TOSTOP),可见回显终端驱动程序检测到CTRL+V时打印"^V"(ECHOPRT),启用输入字符控制(ECHOCTL),启用接收字符控制序列(ECHOKE)。
`jobs` 命令
`jobs` 命令用于列出当前终端会话中在后台运行的作业列表。可以使用 `jobs` 命令来检查哪些作业正在运行、哪些在后台暂停、它们的状态、PID 等信息。
命令语法:
jobs [-lnprs] [jobspec ...]常用选项与参数:
- `-l` : 显示完整的作业信息(包括PID)
- `-n` : 列出最近启动的N个作业
- `-p` : 只显示作业PID,而不显示作业状态和命令
- `-r` : 只列出正在运行的作业
- `-s` : 只列出已停止的作业`jobspec` 参数是作业的标识符,它包括作业号或者作业进程组的 ID。如果不指定 `jobspec` 参数,则会列出所有作业。
示例:
1. 列出当前终端所有作业信息:
$ jobs2. 列出当前终端最近启动的3个作业信息:
$ jobs -n 33. 列出当前终端所有正在运行的作业:
$ jobs -r4. 列出当前终端所有已停止的作业:
$ jobs -s
`fg` 命令
`fg` 命令用于将一个在后台运行的进程切换到前台。
用法:
fg [job_spec]其中,`job_spec` 是指作业的标识号,可以是前面带有 `%` 的作业编号,也可以是后台进程的进程 ID。
如果没有指定 `job_spec`,则将切换到当前作业的前台。
例如:`fg %1` 将把第一个作业切换到前台。
set命令

常见组合按键
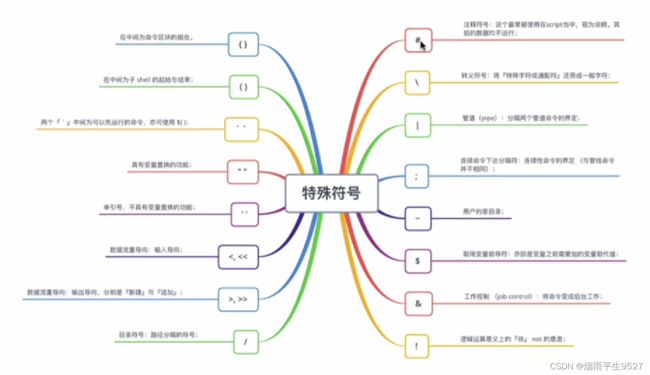
通配符与特殊符号
通配符

特殊符号
2.4数据流的重定向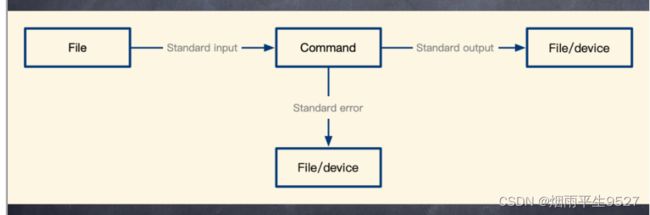
不管正确或错误的数据都是默认输出到屏幕上的,乱。
是否存在一个机制将两种数据分开?
传送所用的特殊字符

注意:>会覆盖,>>则是追加

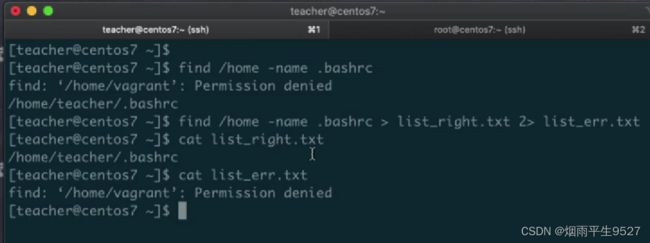
/dev/null垃圾桶黑洞设备与特殊写法
在 Linux 系统中,/dev/null 被称为“黑洞设备”,它是一个特殊的文件,用于接收所有发送到它的数据,但不会将数据写入到任何地方。换句话说,它是一个永远不会满的垃圾桶,所有写入到它的数据都会直接被丢弃。
使用 /dev/null 的好处是可以轻松地将程序中的输出或错误信息丢弃掉,而不会产生任何影响。例如,如果你想运行一个程序但不希望输出文件,可以将输出送到 /dev/null:
$ command > /dev/null此外,可以使用一些特殊的写法来将标准输出或错误重定向到 /dev/null:
$ command > /dev/null 2>&1这个命令将标准输出和标准错误一起重定向到 /dev/null,这意味着命令的所有输出都会被忽略。
总的来说,/dev/null 是一个非常有用的工具,它可以帮助我们有效地处理程序输出和错误信息,以及其他不需要的数据。
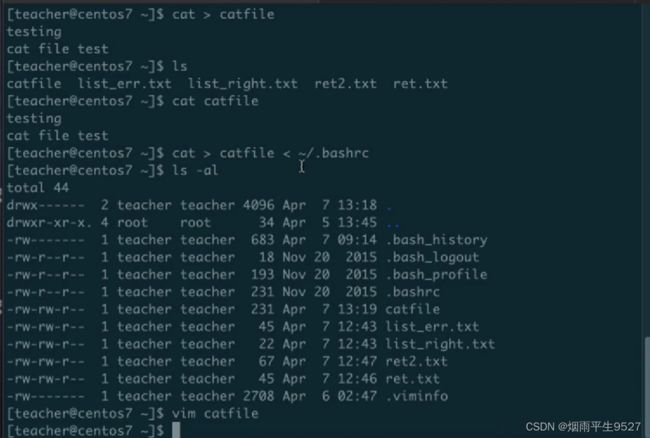
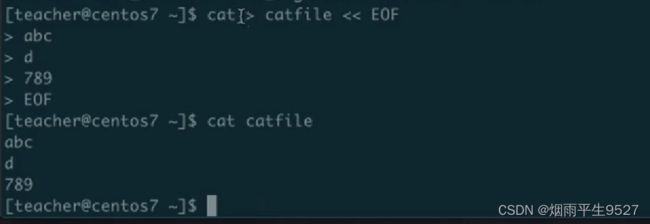
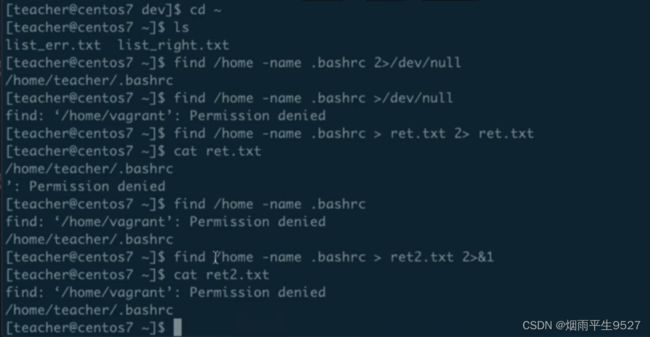 standard inpul:<和<<
standard inpul:<和<<
输入重定向:將原本需要由键盘输入的数据,改由文件内容取代;
 命令运行的判断依据:;,&&,‖
命令运行的判断依据:;,&&,‖
在Linux中,命令运行的判断依据主要有三个符号:分号(;)、逻辑与(&&)和逻辑或(||)。
分号(;)用于分隔命令,表示在命令行中按照顺序执行多个命令。无论前面的命令是否成功,都会继续执行后面的命令。
逻辑与(&&)用于连接两个命令,表示只有前面的命令执行成功,才会继续执行后面的命令。如果前面的命令执行失败,则后面的命令不会执行。
逻辑或(||)也用于连接两个命令,表示只有前面的命令执行失败,才会继续执行后面的命令。如果前面的命令执行成功,则后面的命令不会执行。
例如,以下命令:
command1 ; command2 ; command3表示按照顺序执行command1、command2和command3三个命令。
以下命令:
command1 && command2表示当command1执行成功后,才会执行command2命令。
以下命令:
command1 || command2表示当command1执行失败后,才会执行command2命令。

$?是一个特殊的变量,它会显示上一个命令的返回值。在Linux中,命令返回值代表着命令执行的结果。命令执行成功会返回0,否则会返回一个非零值。例如,如果上一个命令执行成功,$?将会返回0。如果上一个命令执行失败,$?将会返回非零值。通过检查$?的值可以判断命令的执行结果,从而进行后续的操作。
三、管道命令
在 Linux 中,管道是将一个命令的输出作为另一个命令的输入。管道使用垂直线(|)表示。
注意
- 管道命令仅会处理stdout,对于stderr会给予忽略;
- 管道命令必须能够接受来自前一个命令的数据作为stdin继续处理才行。

3.1撷取命令:cut,grep
撷取命令:将数据进行处理后,取出感兴趣的部分;或者,经由分析关键词,取得所想要的行。
一般来说,撷取信息通常是针对“行”来分析的。
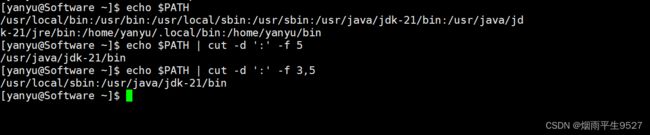
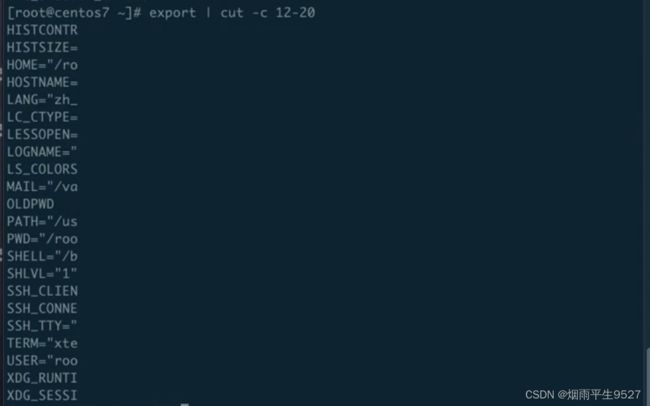
cut命令
Linux cut命令是用来剪切文本文件中的列的命令,它常用于提取文本中的某些字段。
基本语法:
cut [选项] ... [文件名]常用选项:
- `-f`:指定要剪切的列数,多个列数之间用逗号隔开,例如:`-f 1,3` 表示剪切第1列和第3列。
- `-d`:指定列分隔符,默认为制表符。
- `-c`:指定要剪切的字符范围,例如:`-c 1-3` 表示剪切第1个到第3个字符。示例:
# 提取passwd文件中的用户名和用户ID,以冒号为分隔符 cut -d ":" -f 1,3 /etc/passwd # 提取access.log文件中的第一列和第四列 cut -f 1,4 access.log # 提取文本文件中每行的前10个字符 cut -c 1-10 text.txt

cut的主要用途:将同一行内的数据进行分解。
处理多个空格相连的数据时,存在困难。
grep命令
grep命令是Linux中非常重要的文本搜索工具,常用于在文件中查找特定字符串或模式。其语法格式为:
grep [options] pattern [files]其中,options为可选参数,pattern为要查找的模式,files为要查找的文件名或文件列表。常用的选项包括:
- -i:忽略大小写
- -r:递归搜索子目录
- -n:显示匹配行的行号
- -c:显示匹配的行数
- -v:显示不匹配的行举个例子,如果我们要在文件file.txt中查找包含字符串"hello"的行,可以使用以下命令:
grep "hello" file.txt如果要忽略大小写,可以加上-i选项:
grep -i "hello" file.txt如果要显示匹配行的行号,可以加上-n选项:
grep -n "hello" file.txt如果要查找多个文件,可以将文件名列在files参数中,例如:
grep "hello" file1.txt file2.txt如果需要递归搜索子目录,可以加上-r选项,例如:
grep -r "hello" /path/to/directory

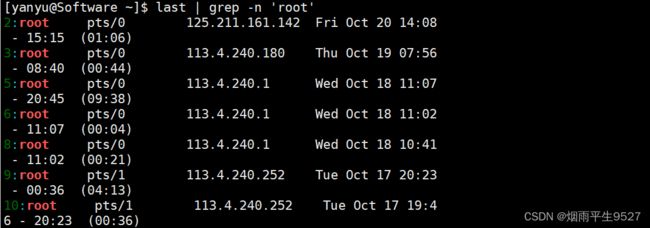

命令中包含"yanyu"的进程。具体解释如下:
- ps:命令行中的进程查看命令。
- aux:选项,用于显示所有进程的详细信息。
- |:管道符号,用于将一个命令的输出作为另一个命令的输入。
- grep -v grep:用于过滤输出结果,去除含有"grep"字符串的行。
- grep yanyu:用于过滤输出结果,只显示含有"yanyu"字符串的行。整个命令的作用是查找运行中的进程中,命令行中含有"yanyu"的进程,并输出这些进程的详细信息。
3.2排序命令
sort命令
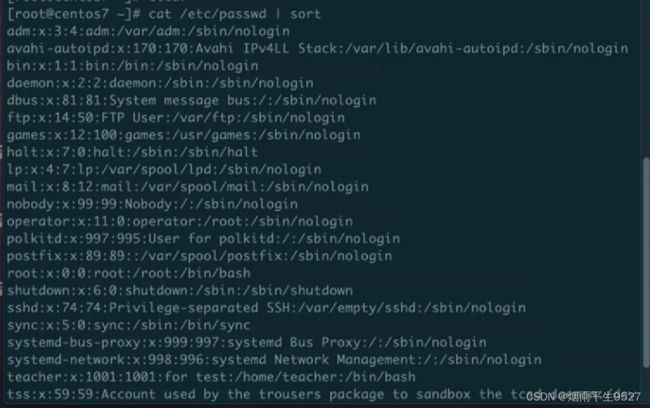
Linux sort命令是一个用于排序文件内容的命令。sort命令默认按照字典序对行进行排序,也可以通过选项调整排序方式。
使用语法:
sort [选项] [文件名]
常用选项:
- -r:按照逆序排序。
- -n:按照数值大小排序。
- -k:按照指定的列排序。
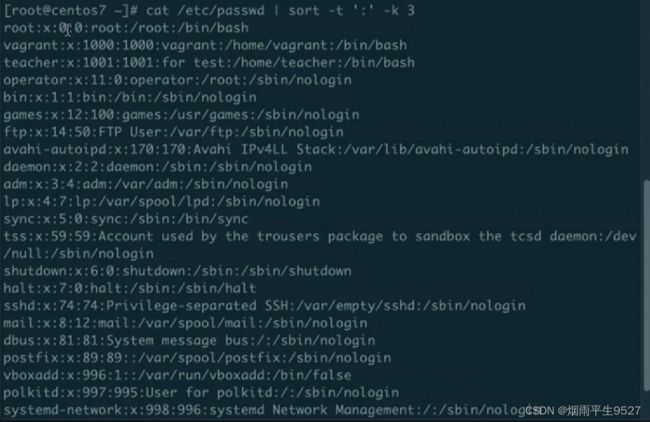
- -t:指定列分隔符,默认为制表符。例子:
1. 对文件进行排序:
sort file.txt
2. 按照逆序排序:
sort -r file.txt
3. 按照数值大小排序:
sort -n file.txt
4. 按照指定列排序:
sort -k 3 file.txt
5. 按照指定列和分隔符排序:
sort -t ',' -k 2 file.txt
uniq命令

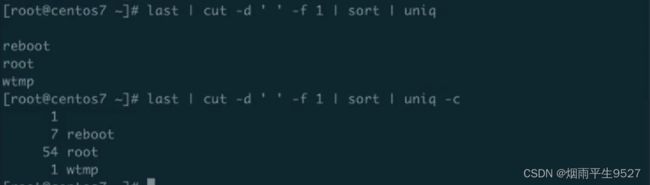
Linux中的uniq命令用于过滤和删除文本文件中的重复行。它可以从文件或标准输入读取数据,并将输出写入到标准输出。
uniq的基本语法如下:
uniq [OPTION]... [INPUT [OUTPUT]]常用选项包括:
- -c:在每行前面显示该行在文件中出现的次数。
- -d:仅显示重复的行。
- -i:不区分大小写。
- -u:仅显示不重复的行。示例:
1. 从文件中删除重复的行:
uniq file.txt2. 显示文件中重复的行及其出现次数:
uniq -c file.txt3. 仅显示重复的行:
uniq -d file.txt4. 忽略大小写并显示不重复的行:
uniq -i -u file.txt
wc命令

wc命令可以用于统计文件中的行数、单词数和字节数。其使用方法如下:
wc [选项] [文件名]常用选项如下:
- `-l`:仅统计行数
- `-w`:仅统计单词数
- `-c`:仅统计字节数
- `-m`:仅统计字符数
- `-L`:输出最长行的长度示例:
- 统计文件中的行数、单词数和字节数:
wc filename.txt- 仅统计文件中的行数:
wc -l filename.txt- 输出文件中最长行的长度:
wc -L filename.txt
3.3双向重定向:tee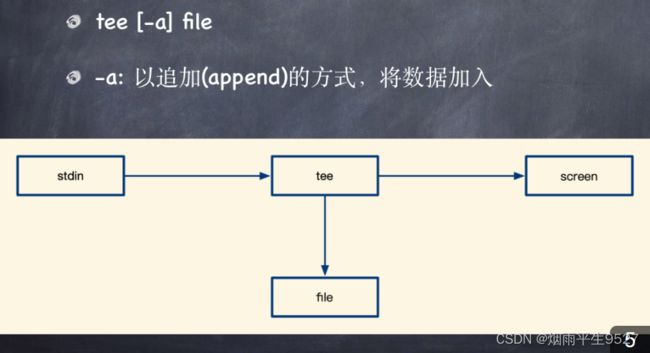
Linux tee命令是用于从标准输入读取数据,将其写入标准输出和一个或多个文件的命令。它可以在命令行中用管道符连接多个命令和文件。
语法:
tee [OPTIONS] [FILE...]参数说明:
- `-a`:附加到文件而不是覆盖文件。
- `-i`:忽略中断信号(SIGINT)。
- `-p`:使用输出的原始数据,而不是进行缓冲处理。
- `-q`:静默模式,不输出到标准输出。
- `-s`:忽略破损的管道。
- `-v`:详细模式,输出写入到文件的字节数。使用示例:
1. 从标准输入读取数据并将其写入文件
echo "hello world" | tee file.txt2. 从标准输入读取数据并将其写入多个文件
echo "hello world" | tee file1.txt file2.txt file3.txt3. 读取文件并将其输出到标准输出及另一个文件
cat file.txt | tee newfile.txt4. 附加数据到文件而不是覆盖
echo "new data" | tee -a file.txt5. 输出详细信息并忽略破损的管道
echo "hello world" | tee -vs file.txt
3.4字符转换命令

unix2dos工具
unix2dos是一个在Unix和Linux下的命令行工具,它用于将UNIX格式的文本文件转换成Windows/DOS格式的文本文件。UNIX文本文件的行末以“\n”字符表示,而Windows/DOS文本文件的行末以“\r\n”字符表示。因此,当在Windows/DOS系统上打开UNIX文本文件时,可能会出现换行错误或显示不正确的问题。
使用unix2dos可以很容易地解决这个问题,只需要执行以下命令即可将UNIX格式的文本文件转换为Windows/DOS格式:
unix2dos filename其中,filename是要转换的UNIX格式文本文件的名称。
除了单个文件之外,unix2dos也可以处理多个文件,只需要将文件名作为参数传递给命令即可:
unix2dos file1 file2 file3 ...在执行unix2dos命令时,可以使用一些选项来定制转换的行为:
- -n或--no-conversion:不进行转换,仅显示哪些行需要转换。
- -c或--safe:安全模式,不修改原始文件并将输出写入新文件。
- -k或--keepdate:保留文件的最后修改时间。例如,若要在安全模式下转换文件filename并保留文件的最后修改时间,可以使用以下命令:
unix2dos -c -k filename总之,unix2dos是一个非常有用的工具,可以轻松地解决UNIX和Windows/DOS之间文本文件格式不兼容的问题。
tr命令
tr命令是Linux操作系统中用于转换或删除字符的命令。它的语法如下:
tr [options] SET1 [SET2]其中,SET1是源字符集,SET2是目标字符集。tr命令会将输入流中SET1集合的字符转换为SET2集合的字符并输出。如果未指定SET2,则tr命令会将SET1集合的字符删除。
常用的选项包括:
- -d:删除SET1中指定的字符。
- -s:将输入中连续出现的SET1中字符压缩成一个字符输出。
- -c:将输入中不属于SET1集合的字符输出。例如,将所有大写字母转换为小写字母:
echo "HELLO WORLD" | tr 'A-Z' 'a-z'

col命令

Linux中的col命令是一个文本过滤器,用于将输入文本转换为列格式。
语法:
col [选项] [文件]
常用选项:
- -b:忽略后退(backspace)字符。
- -f:不将前导和尾随空格合并为单个空格。
- -x:使用单空格作为单元分隔符。示例:
1. 将file.txt的内容按照列格式显示:
cat file.txt | col2. 忽略后退字符并将file.txt的内容按照列格式显示:
cat file.txt | col -b3. 将file.txt的内容按照列格式显示,并使用单空格作为单元分隔符:
cat file.txt | col -x

join命令

Linux join命令用于根据两个文件中指定的字段连接两个文件。
下面是Join命令的语法:
join [options] file1 file2常用选项:
- `-a FILENUM`:输出未匹配到的行。FILENUM为1或2,分别表示输出第一个文件或第二个文件中未匹配的行。
- `-t CHAR`:指定分隔符。默认是制表符。
- `-i` :不区分大小写。
- `-1 FIELD`:指定第一个文件中参与连接的字段。默认是第一个字段。
- `-2 FIELD`:指定第二个文件中参与连接的字段。默认是第一个字段。示例:
1.将两个文件按照第一列进行连接:
join file1.txt file2.txt2.将两个文件按照指定的列进行连接:
join -1 2 -2 3 file1.txt file2.txt3.将两个文件按照指定的列进行连接,并输出未匹配的行:
join -a 1 -1 2 -2 3 file1.txt file2.txt4.将两个文件按照指定的列进行连接,并指定分隔符:
join -t , -1 2 -2 3 file1.txt file2.txt

paste命令

在Linux中,paste命令用于将两个或多个文本文件的行连接起来,并将结果输出到标准输出或指定的输出文件。它的语法如下:
paste [OPTION]... [FILE]...其中,`OPTION`参数用于控制paste命令的行为,可以省略;`FILE`参数指定要连接的文本文件,可以指定多个。以下是一些常用的选项:
- `-d DELIM`:使用指定的分隔符`DELIM`来连接行,默认使用制表符。
- `-s`:串联每个文件的行,而不是并排连接行。例如,假设有两个文本文件`file1.txt`和`file2.txt`,内容如下:
file1.txt:
apple orange bananafile2.txt:
red orange yellow通过以下命令可以连接这两个文件的行并输出到标准输出:
paste file1.txt file2.txt输出结果如下:
apple red orange orange banana yellow如果想使用逗号来连接行,可以使用如下命令:
paste -d ',' file1.txt file2.txt输出结果如下:
apple,red orange,orange banana,yellow

expand命令

Linux的expand命令用于将指定文件中的制表符转换为空格。该命令可用于将包含制表符的文本文件转换为纯文本格式的文件。
命令基本语法:
expand [option] [file]常用选项包括:
- `-t`:指定转换制表符的宽度。
- `-i`:指定覆盖原文件。
- `-o`:指定输出文件。例如,将文件example.txt中的制表符转换为空格,并覆盖原文件,命令如下:
expand -i example.txt
3.5分割命令:split

在 Linux 操作系统中,split 命令可以根据指定的大小将文件分割成多个小文件。该命令的基本语法如下:
split [OPTION] [INPUT [PREFIX]]其中,[OPTION] 为可选参数;[INPUT] 为要分割的文件名;[PREFIX] 为生成的分割文件的前缀。
常用的选项包括:
- -b:指定每个输出文件的大小。例如,使用 -b 10M 表示将输入文件分成每个大小为 10MB 的小文件。
- -d:使用数字作为输出文件的后缀。例如,第一个分割文件为 file01,第二个为 file02,以此类推。
- -a:指定输出文件名后缀的长度。例如,使用 -a 3 表示输出文件名后缀为三个字符,即 file001、file002、file003 等。以下是几个示例:
1. 将文件 file.txt 按照每个文件大小为 10MB 进行分割,分割后的文件名为 file.part:
split -b 10M file.txt file.part2. 将文件 file.txt 按照行数进行分割,每个文件包含 100 行,输出文件名后缀为三个字符:
split -l 100 -a 3 file.txt file_以上命令将会把 file.txt 按照每 100 行分为一个文件,并以 file_001、file_002、file_003 等命名输出文件。

3.6参数替换:xargs

xargs命令是一个非常实用的Linux命令,它可以将标准输入转换为命令行参数并执行指定的命令,从而帮助用户批量执行特定的命令。
xargs命令的基本语法格式如下:
command | xargs [options] [command]其中,command表示要执行的命令,通过管道符“|”将其与xargs命令连接起来;options表示xargs命令的选项,可以根据需要添加不同的选项来实现想要的功能。
xargs常用选项说明如下:
- -a file:从文件中读取参数列表;
- -d delim:指定分隔符,默认为换行符;
- -I replstr:替换符号,用于替换命令中的参数;
- -n num:指定每次执行命令使用的最大参数个数;
- -P maxprocs:指定同时执行命令的最大进程数;
- -t:打印出实际执行的命令。xargs命令的使用示例:
1. 删除多个文件:
ls *.txt | xargs rm2. 根据输入文件中的各行数据,批量创建新目录:
cat dir_list.txt | xargs mkdir3. 用find命令找到所有以.txt结尾的文件,并使用xargs命令将它们拷贝到新目录中:
find . -name "*.txt" | xargs -I {} cp {} /home/user/documents/new_folder/以上是xargs命令的基本用法和示例。该命令在批量处理文件、目录和参数时非常有用。
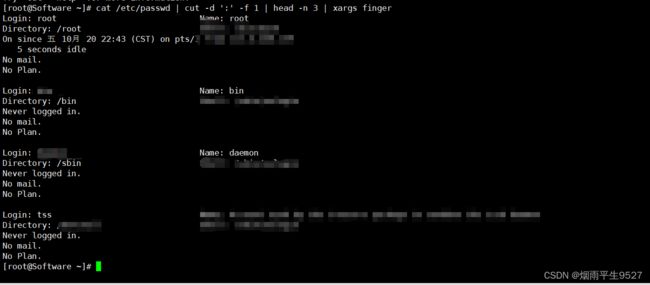
这个命令将先打开 /etc/passwd 文件,并使用 cut 命令将每行的文本根据 ':' 进行分割,并选择第一列。然后使用 head 命令选择前三行。最后使用 xargs 把这三个用户名作为 finger 命令的参数,以显示这些用户的信息。
简单来说,这个命令的作用是显示前三个用户的详细信息。
finger命令
finger是一个命令,可以查询指定用户在Linux系统下的信息,包括用户名、用户ID、登录时间、登录位置以及用户状态等
在CentOS或Fedora系统上:
sudo yum install finger
3.7关于减号-的用途

四、文件格式化与相关处理
4.1正则表达式

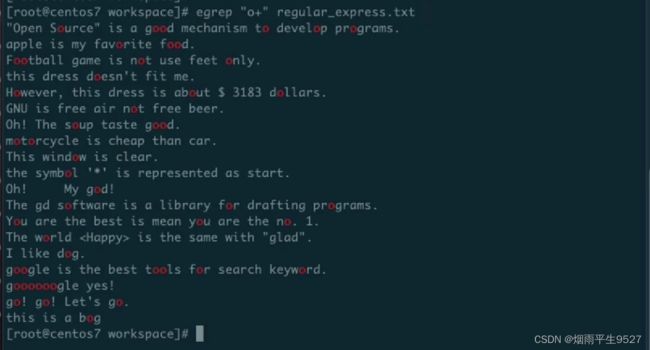
egrep是Linux命令中的一种,也称为Extended grep。它是grep命令的升级版,可以支持正则表达式的语法。egrep命令的基本使用语法如下:
egrep [选项] 正则表达式 文件名其中,选项可以是:
- `-i`:忽略大小写
- `-v`:反向匹配,只匹配不包含的文本行
- `-c`:只显示匹配行的数量
- `-n`:显示匹配行的行号
- `-w`:仅匹配整个词,不匹配子串
4.2printf命令

printf命令是Linux中的一个命令行工具,用于将格式化字符串输出到标准输出(stdout)或者文件中。printf 命令的语法:
printf format-string [arguments...]其中,format-string是格式化字符串,用来定义要输出的文本格式。arguments是可选参数,是要输出的变量或值。format-string可以包含各种格式化参数,如下表所示:
输出字符串:
printf "Hello, World!\n"输出变量:
var="This is a test" printf "%s\n" "$var"使用格式化参数输出:
printf "The value of pi is approximately %f\n" 3.141592653589793以上例子将输出:
Hello, World! This is a test The value of pi is approximately 3.141593

4.3sed命令

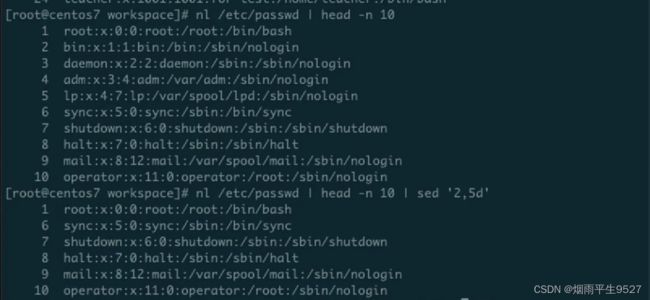
sed(Stream Editor)是一个用于处理文本的工具,它可以对文本进行替换、删除、插入、打印等操作。在Linux系统中,sed是一个非常强大的命令行文本编辑器,可以方便地进行批量处理和编辑文本文件。
sed命令的基本语法如下:
sed [选项] 'sed命令' 文件名常用的sed选项包括:
- `-n`:只显示经过sed编辑的内容;
- `-e`:支持多个编辑器命令;
- `-i`:直接修改原始文件,而不是在屏幕上输出结果。常用的sed命令:
- `s`:替换命令,用于在文本中查找并替换指定的字符串;
- `d`:删除命令,用于删除匹配的行或范围内的行;
- `p`:打印命令,用于打印匹配的行或范围内的行;
- `g`:全局替换命令,用于替换所有匹配的字符串;
- `i`:插入命令,用于在指定行之前插入一行或多行文本;
- `a`:追加命令,用于在指定行之后附加一行或多行文本。例如,将文件中所有的"a"替换为"b",可以使用如下命令:
sed 's/a/b/g' 文件名将文件中的第一行删除,可以使用如下命令:
sed '1d' 文件名将文件中的所有行都打印出来,并且在每一行前加上行号,可以使用如下命令:
sed -n -e '1,${=;p;}' 文件名
4.3awk命令

AWK是一种文本处理工具,能够对文本进行各种形式的处理。它是一种命令行工具,也是一种编程语言。它的主要特点是能够对文本进行分割、过滤、格式化等操作。
在Linux中,awk命令可以使用以下语法:
awk [options] 'pattern {action}' file其中,pattern是用来匹配文本的模式,action是在匹配到相应文本时执行的操作。文件名可以是一个或多个,用空格隔开。如果文件名为空,则从标准输入读取文本。
以下是一些常用的选项:
- -F:指定文本的分隔符,默认为制表符。
- -v:定义一个变量。
- -f:从脚本文件中读取命令。以下是一些常用的模式:
- /pattern/:匹配包含特定模式的行。
- $n:匹配第n个字段。
- BEGIN:在读取第一行之前执行的操作。
- END:在读取所有行之后执行的操作。以下是一些常用的操作:
- print:打印匹配到的文本。
- printf:打印格式化文本。
- getline:读取下一行,并将其存储到指定变量中。
- if-else语句:用于条件判断。
- for循环:用于循环处理文本。例如,以下命令可以在file.txt文件中查找包含“example”字符串的行,然后打印出这些行:
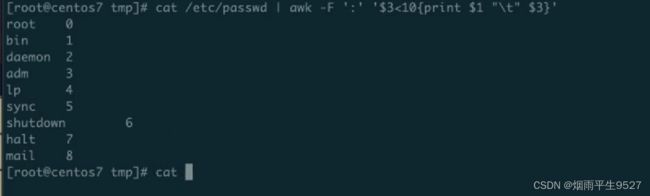
awk '/example/ {print}' file.txt再例如,以下命令可以计算file.txt文件中每行的字段数,并将其打印出来:
awk '{print NF}' file.txt
4.4diff命令

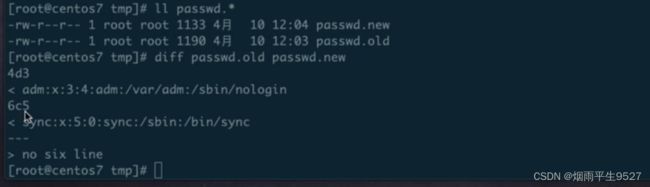
`diff` 命令用于比较两个文件的差异。它可以指定要比较的文件,并生成关于两个文件之间差异的详细报告。
语法:
diff [OPTION]... FILE1 FILE2常用选项:
- `-u`:以 Unified diff 格式输出差异。
- `-c`:以 context diff 格式输出差异。
- `-r`:递归地比较指定的目录。
- `-q`:只输出文件是否有差异,不显示具体内容。
- `-i`:忽略大小写差异。
- `-B`:忽略空格差异。
- `-w`:忽略所有空格差异。示例:
比较两个文件的差异:
diff file1.txt file2.txt以 Unified diff 格式输出差异:
diff -u file1.txt file2.txt递归地比较两个目录下的所有文件:
diff -r dir1 dir2
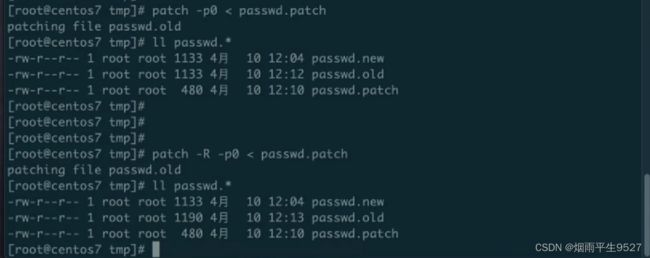
4.5patch命令

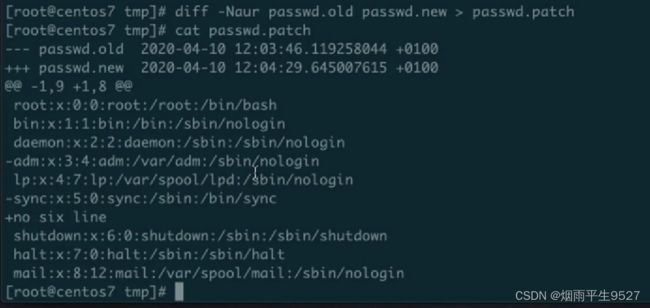
"patch"是Linux中的一个命令,用于将差异文件(即补丁文件)应用到原始文件中,从而更新或修改原始文件。
使用patch命令需要准备两个文件:原始文件(被修改的文件)和差异文件(包含修改内容的文件)。
用法示例:
$ patch < diff_file # 将差异文件应用到原始文件中 $ patch -p1 < diff_file # 适用于差异文件中路径有相对路径的情况 $ patch -R < diff_file # 恢复(回退)修改常用参数:
- `-p[num]`: 忽略差异文件中路径的前[num]层目录
- `-R`: 恢复(回退)修改补丁文件可以由开发人员生成,也可以由第三方提供。它们通常以.diff或.patch作为文件扩展名
五、shell编程
5.1相关概念
什么是shell
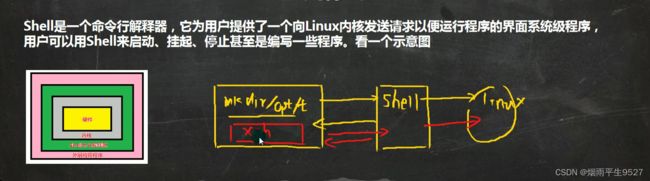
什么是Shell Script?

Shell Script是一种编程语言,能够通过一个Shell解释器来执行。它可以用于编写自动化任务和脚本,例如批量处理文件、系统管理和自动化部署等。 Shell脚本通常以.sh文件扩展名结尾。 Shell Script是Unix和Linux系统的标准工具之一。


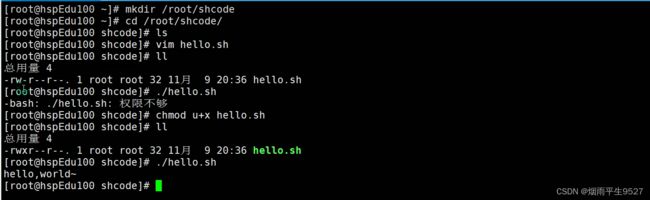


sh命令
sh是一种Unix shell,用于解释运行shell脚本或命令。以下是sh命令的一些常见用法:
1. sh script.sh:运行shell脚本
2. sh -c "command":运行单个命令
3. sh -n script.sh:检查shell脚本语法错误
4. sh -x script.sh:在脚本运行过程中显示执行的命令
5. sh -v script.sh:在脚本运行过程中显示每个命令和它的参数
6. sh -e script.sh:在脚本运行过程中一旦出现错误就停止
7. sh -u script.sh:在脚本中引用未定义的变量会报错
8. sh -l:启动一个登录shell
9. sh --version:显示sh版本号
10. sh --help:显示sh命令的帮助信息
 source命令
source命令
Linux的source命令用于执行指定的Shell脚本,并将其内容加载到当前Shell进程中运行。它的常见使用方式是用于加载环境变量配置文件,如.bashrc或.profile。
语法:
source filename或
. filename其中filename是要执行的Shell脚本文件。
使用source命令执行脚本的优点是,它可以在当前Shell进程中立即生效,并且可以修改当前Shell的环境变量和定义的函数。如果不使用source命令而是直接执行脚本文件,那么它将在一个新的子Shell进程中运行,不会影响当前Shell进程的环境变量和函数定义。

补充
1.对话式脚本;
2.创建随日期变化的文件脚本;
3.数值运算.
对话式脚本;

创建随日期变化的文件脚本;

数值运算.

5.2shell变量


定义变量的规则
1.变量名称可以由字母、数字和下划线组成,但是不能以数字开头。5A=200(×)
2.等号两侧不能有空格
3.变量名称一般习惯为大写
将命令的返回值赋给变量
I.A=`date‘反引号,运行里面的命令,并把结果返回给变量A
2.A=$(date)等价于反号
位置参数变量

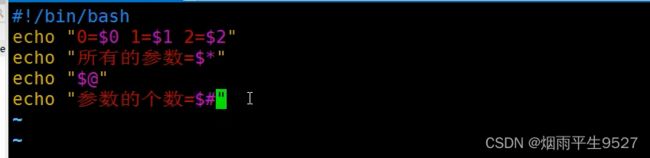
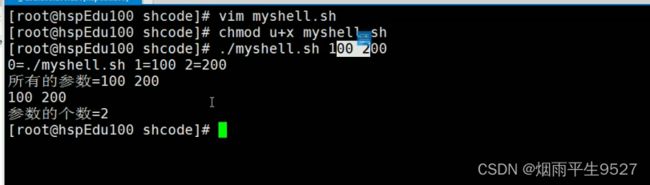 预定义变量
预定义变量

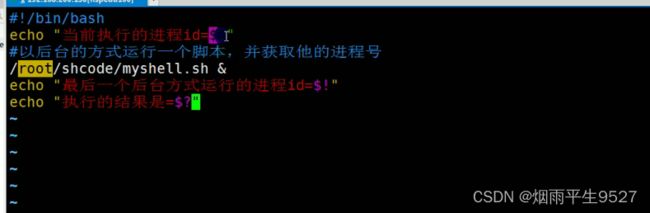
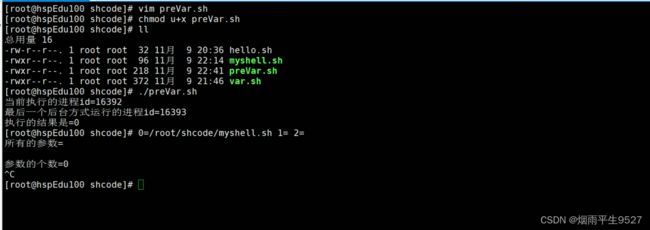
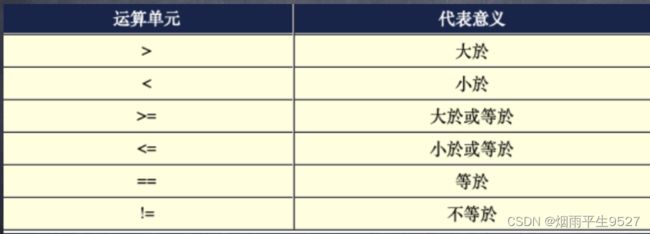
5.3运算符


补充:SeLL的判断式

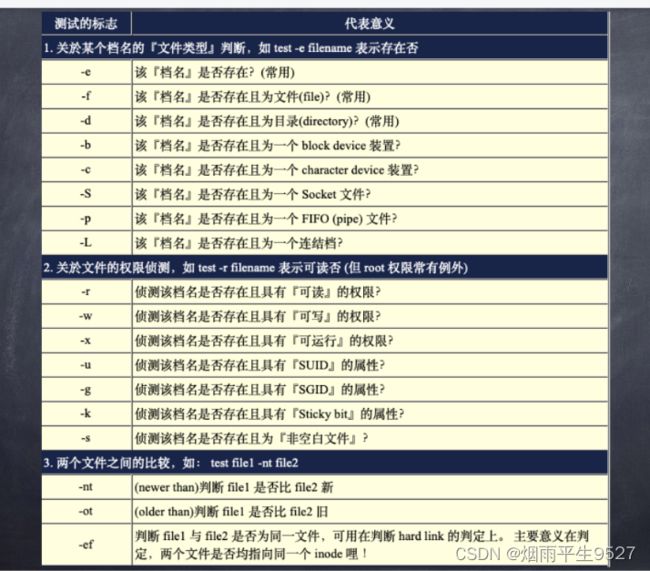
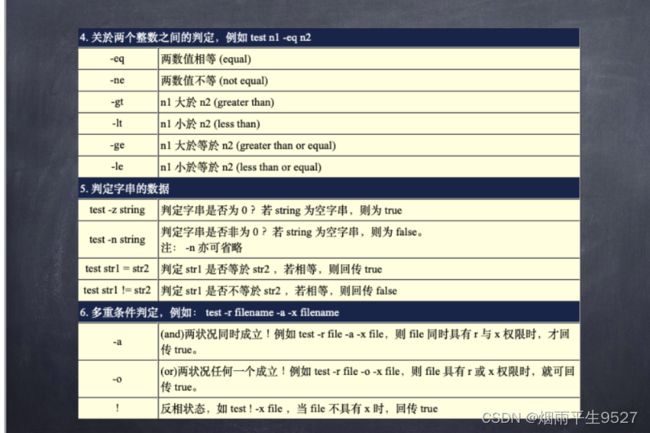
利用命令:test
通过$?、&&,||显示结果.
test命令用于检查文件属性、比较值和其他一些操作,它也被称为[命令。test命令的常用语法如下:test EXPRESSION或者
[ EXPRESSION ]其中,
EXPRESSION为测试表达式,它支持多种测试选项。以下是一些常见的测试选项:
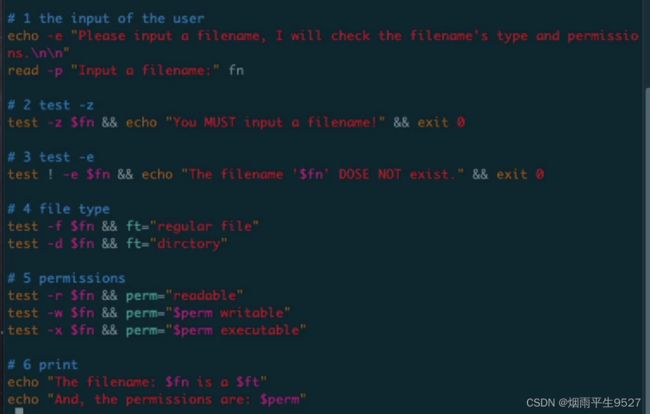
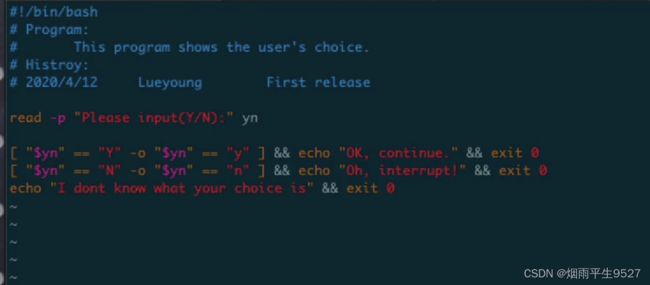
利用符号:[]
5.4条件判断语句


if分支
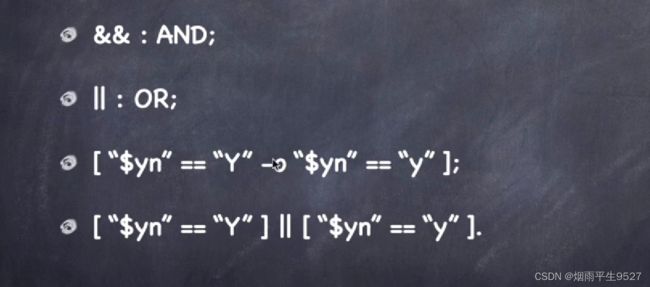
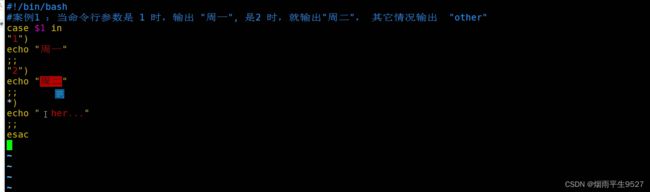
switch分支

 5.5循环语句
5.5循环语句
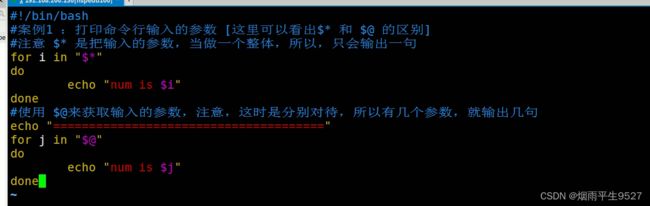
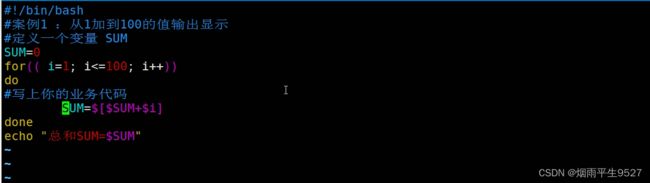
for循环

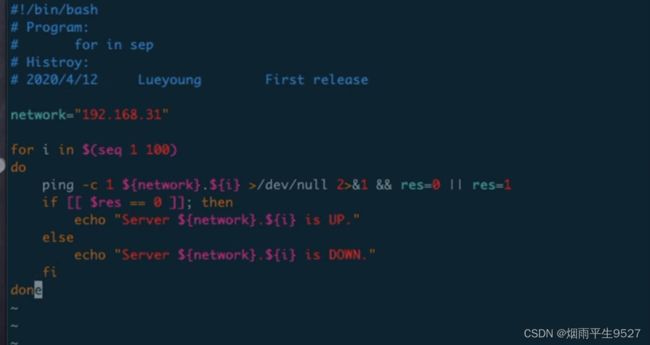 while循环
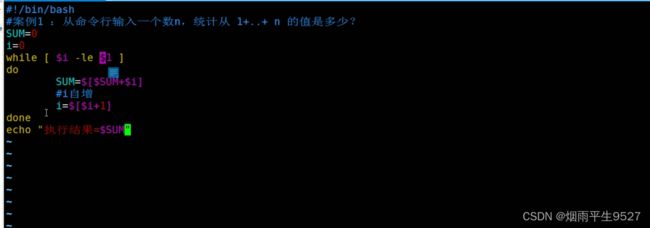
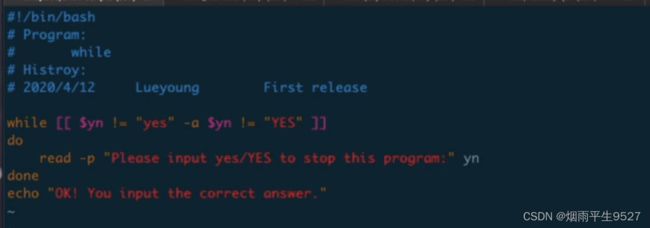
while循环

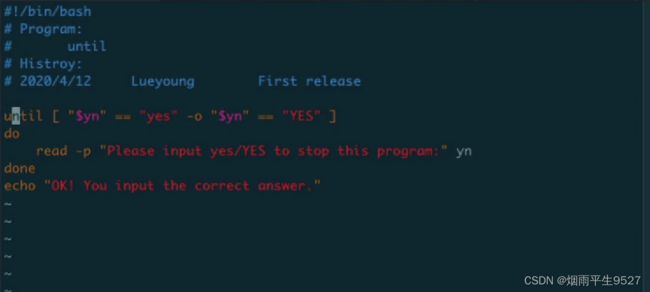
 until循环
until循环

 5.6输入输出
5.6输入输出

自动换行
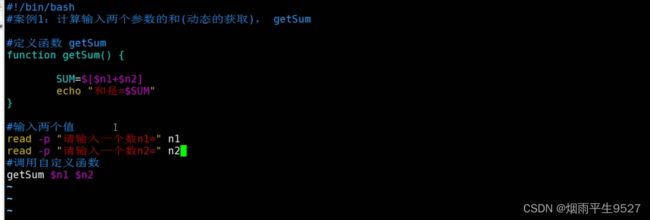
5.7函数
系统函数

`basename`是一个Linux/Unix命令,用于在文件路径中提取文件名或目录名。
使用方法:
basename [OPTIONS] FILENAME其中,`OPTIONS`是可选参数,`FILENAME`是文件路径。
常见的选项包括:
- `-a`:显示所有匹配结果,而不仅仅是第一个。
- `-s`:指定需要删除的后缀。
- `-z`:表示以空字符作为分隔符。示例:
$ basename /usr/local/bin/bash bash $ basename /usr/local/bin/ bin $ basename /usr/local/bin/bash .bash bash $ basename /usr/local/bin/bash | tr '[:lower:]' '[:upper:]' BASH以上命令分别输出:
- `/usr/local/bin/bash`的文件名为`bash`。
- `/usr/local/bin/`的文件名为`bin`。
- `/usr/local/bin/bash`去掉后缀`.bash`的文件名为`bash`。
- `/usr/local/bin/bash`的文件名转换为大写为`BASH`。

`dirname` 命令用于获取一个给定路径的目录部分。该命令会截取掉路径最后一个斜线(`/`)及其后面的部分,只返回目录部分。如果路径已经是目录,该命令会返回它的父目录。
例如:
$ dirname /usr/local/bin /usr/local
在上面的示例中,`/usr/local/bin` 是一个文件路径,执行 `dirname` 命令后只返回了 `/usr/local` 目录部分。命令常用的选项:
- `-z`:按照空串终止而非newline终止;
- `-z`:忽略多余的字符串,处理所有参数;
- `--help`:显示命令帮助信息;
- `--version`:显示命令版本信息。