使用概率编程和Pyro进行金融预测
原文链接:
https://medium.com/@alexrachnog/financial-forecasting-with-probabilistic-programming-and-pyro-db68ab1a1dba
图片来源 https://jmhl.org/research/
大家好,我回来了!去年我发表了几篇利用神经网络做金融预测的教程,其中一些结果是有趣的,我觉得值得应用于真实交易应用中。如果你读过那些文章,你可能注意到,当你用某些机器学习模型拟合“随机”数据,并试图找到其中隐含模式时,通常会陷于过拟合。我们用了不同的正则化技术以及额外的数据试图解决这一问题,但这很费时且需要盲目搜索。
今天我会用略微不同的方法拟合之前的算法。从概率角度进行处理,通过数据本身进行正则化,估计预测的确定性,使用较少的数据,将概率依赖引入到模型中。这里主要讲概况,我会更注重于应用问题,而不会特别深入的讲解贝叶斯模型或变分推断技术或数学细节问题。你可以在这里找到代码。
同时我也推荐你读一下此前写的利用神经网络做金融预测的教程:
-
Simple time series forecasting (and mistakes done)
-
Correct 1D time series forecasting + backtesting
-
Multivariate time series forecasting
-
Volatility forecasting and custom losses
-
Multitask and multimodal learning
-
Hyperparameters optimization
-
Enhancing classical strategies with neural nets
-
Probabilistic programming and Pyro forecasts
-
Backtesting in Pandas
如需要进一步了解概率编程、贝叶斯模型及其应用,推荐阅读以下资源:
-
Pattern recognition and machine learning
-
Bayesian methods for hackers
可以看以下以下Python库及相关文档:
-
PyMC3
-
Edward
-
Pyro
概率编程
这里的概率指什么,为什么称之为编程? 首先我们回忆一下“正常的”神经网络及其输出。神经网络带有参数(权重),这些是以矩阵形式表示的,神经网络的输出通常是一些标量值或向量(例如做分类时)。当模型训练完成后,比如说使用SGD进行训练,得到一些固定的权重矩阵,网络对于相同的样本会输出相同的结果。没错!那么如果把参数和输出看做相互依赖的分布会怎么样呢?神经网络里每个权重可以看做某个分布的样本,同样输出可以看做全网络作为分布的一个样本,这个分布依赖于网络中所有参数。这告诉我们什么?
我们从最基本的开始说。如果把网络看做一组相互依赖的分布,它首先是一个联合分布 p(y, z|x), 这里y是输出、z是模型“内部的”潜变量,依赖于输入 x (常规神经网络都可以这样看)。有趣的是这样的神经网络分布,可以看做从 y ~ p(y|x) 采样,然后把输出作为其分布(其中输出通常是该分布的样本期望,其标准差 — —作为不确定性的估计 — —分布的尾部越大——输出的置信度越低)。
有了这样的设定就后面理解略微清晰了点,我们只需要记得,从现在开始模型中所有的参数、输入和输出都是分布。当我们训练模型时,需要拟合这些分布的参数,在实际任务中获得更高的精度。这里我们还需要知道,参数分布的形态是由我们来设定的 (开始时所有权重都初始化为 w ~ Normal(0, 1)分布,此后通过训练获得正确的均值和方差)。最初的分布是先验分布,经过训练以后的分布是后验分布。我们用后者去采样获得输出。
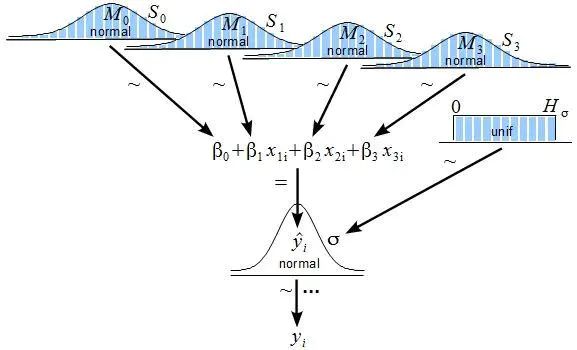
图片来源http://www.indiana.edu/~kruschke/BMLR/
模型拟合是怎么做的? 通用框架叫做变分推断。如果不看细节我们可以假定,需要找到一个模型最大化对数似然 p_w(z|x), 这里w是模型参数 (分布的参数), z 是潜变量 (隐神经元的输出, 采样自参数w的分布) ,x是输入样本数据。我们的模型就是这样的。在Pyro可引入这样一个实体作为该模型的guide,其中包含所有潜变量的分布q_ф(z), 此处 ф 称为变分参数。这个分布必须近似“实际”模型参数的分布,也就是最好的拟合输入数据。
训练目标是最小化[log(p_w(z|x)) — log(q_ф(z))] 关于输入数据和guide样本的期望。这里不会过多介绍训练的细节,因为可能涉及好几门大学课程,现在把这个看做黑盒优化就好。
好的 那为什么称为编程? 通常这样的统计模型(神经网络)被描述为从一个变量到另一个变量的有向图, 这样直接显示变量的依赖:
图片来源 http://kentonmurray.com/
最初概率编程语言被用于定义诸如这样的模型并以此进行推断。
使用概率编程的原因
从数据中学习它作为额外的潜变量,而不是传统的在模型中使用dropouts或L1正则化。考虑到所有权重都是分布,可以从那里采样N次并得到输出的分布,这里可以看一下标准差估计一下模型输出结果的置信度。这种方法的好处是,我们只需要较少的训练数据并可灵活的在变量间增加依赖。
不使用概率编程的原因
我在贝叶斯模型使用尚没有积累大量的经验,不过在使用Pyro和PyMC3的过程中我发现,训练过程很长且难以确定先验概率。另外处理生产环境的样本分布可能导致误解和模棱两可的情况。
数据准备
我从网上获取每日以太币的牌价等数据,其中包括OHLCV (开盘、最高、最低、收盘、成交量) ,另外还获取了每天涉及以太币的推特数量。这里选取7天价格、成交量和推特数的换算为变动%,预测下一个交易日的变动。
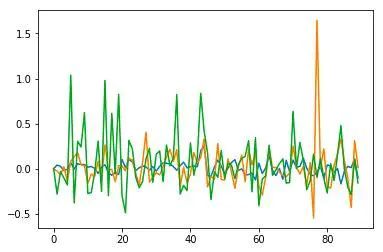
价格 推特数和成交量变动
上图为采样的数据 —蓝色表示价格变动, 黄色表示推特数变动,绿色是成交量变动。这些变量之间存在一些正相关(大概0.1–0.2之间), 所以我们可利用数据中的模式来训练我们的模型。
贝叶斯线性回归
首先我想看一下简单线性回归效果如何(直接从Pyro教程复制结果). 下面定义PyTorch模型 (官方教程里有各个详细的说明):
class RegressionModel(nn.Module):
def __init__(self, p):
super(RegressionModel, self).__init__()
self.linear = nn.Linear(p, 1)
def forward(self, x):
# x * w + b
return self.linear(x)
这是一个简单的确定性模型和之前一样, 不过这就是在Pyro中定义概率模型的方式:
def model(data):
# Create unit normal priors over the parameters
mu = Variable(torch.zeros(1, p)).type_as(data)
sigma = Variable(torch.ones(1, p)).type_as(data)
bias_mu = Variable(torch.zeros(1)).type_as(data)
bias_sigma = Variable(torch.ones(1)).type_as(data)
w_prior, b_prior = Normal(mu, sigma), Normal(bias_mu, bias_sigma)
priors = {'linear.weight': w_prior, 'linear.bias': b_prior}
lifted_module = pyro.random_module("module", regression_model, priors)
lifted_reg_model = lifted_module()
with pyro.iarange("map", N, subsample=data):
x_data = data[:, :-1]
y_data = data[:, -1]
# run the regressor forward conditioned on inputs
prediction_mean = lifted_reg_model(x_data).squeeze()
pyro.sample("obs",
Normal(prediction_mean, Variable(torch.ones(data.size(0))).type_as(data)),
obs=y_data.squeeze())
在上面的代码中我们看到, 用W和b作为广义线性回归模型分布的参数,它们服从~Normal(0, 1)分布,这里命名为prior。构造Pyro随机函数(PyTorch里用RegressionModel), 赋值prior ({‘linear.weight’: w_prior, ‘linear.bias’: b_prior}) 基于输入数据x从 p(y|x) 采样。
模型的guide函数定义如下:
def guide(data):
w_mu = Variable(torch.randn(1, p).type_as(data.data), requires_grad=True)
w_log_sig = Variable(0.1 * torch.ones(1, p).type_as(data.data), requires_grad=True)
b_mu = Variable(torch.randn(1).type_as(data.data), requires_grad=True)
b_log_sig = Variable(0.1 * torch.ones(1).type_as(data.data), requires_grad=True)
mw_param = pyro.param("guide_mean_weight", w_mu)
sw_param = softplus(pyro.param("guide_log_sigma_weight", w_log_sig))
mb_param = pyro.param("guide_mean_bias", b_mu)
sb_param = softplus(pyro.param("guide_log_sigma_bias", b_log_sig))
w_dist = Normal(mw_param, sw_param)
b_dist = Normal(mb_param, sb_param)
dists = {'linear.weight': w_dist, 'linear.bias': b_dist}
lifted_module = pyro.random_module("module", regression_model, dists)
return lifted_module()
接下来为需要训练的分布定义变分分布。可以看到,定义的W和b分布的形状是一致的。为了更符合现实 (根据我们的假定),在本例中将分布收窄一些 (~Normal(0, 0.1))。
接下来训练模型:
for j in range(3000):
epoch_loss = 0.0
perm = torch.randperm(N)
# shuffle data
data = data[perm]
# get indices of each batch
all_batches = get_batch_indices(N, 64)
for ix, batch_start in enumerate(all_batches[:-1]):
batch_end = all_batches[ix + 1]
batch_data = data[batch_start: batch_end]
epoch_loss += svi.step(batch_data)
拟合后从模型中采样y,重复100次,检查预测的均值和标准差 (标准差越高, 本次预测的置信度越低).
preds = []
for i in range(100):
sampled_reg_model = guide(X_test)
pred = sampled_reg_model(X_test).data.numpy().flatten()
preds.append(pred)
在金融场景中预测中经典的指标是MSE, MAE 或 MAPE,这里麻烦 — — 相对误差率较小并不等于模型效果就好,还需要检查那些样本以外的数据在模型中的效果并绘制成图:
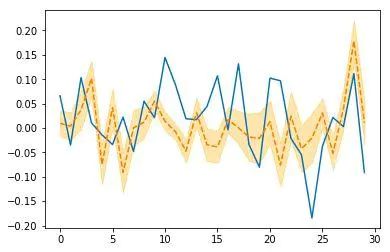
image
贝叶斯模型30天预测
看起来不太理想,不过最后那跳的形状还不错,我们继续!
普通神经网络
这里尝试用以下这个简单神经网络得到一些有趣的特性,首先我们构造一个MLP,隐层含有25神经元后面跟着线性激活函数:
def get_model(input_size):
main_input = Input(shape=(input_size, ), name='main_input')
x = Dense(25, activation='linear')(main_input)
output = Dense(1, activation = "linear", name = "out")(x)
final_model = Model(inputs=[main_input], outputs=[output])
final_model.compile(optimizer='adam', loss='mse')
return final_model
训练100个epoch:
model = get_model(len(X_train[0]))
history = model.fit(X_train, Y_train,
epochs = 100,
batch_size = 64,
verbose=1,
validation_data=(X_test, Y_test),
callbacks=[reduce_lr, checkpointer],
shuffle=True)
以下是训练结果:
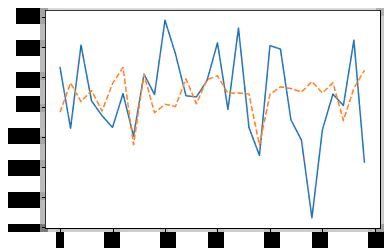
image
Keras 神经网络预测30天预测
结果不如简单贝叶斯回归,此外模型给不出确定性估计,更重要的是模型也不是正则化的。
贝叶斯神经网络
现在把刚才用Keras定义的神经网络用PyTorch框架改写一下:
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.predict = torch.nn.Linear(n_hidden, 1) # output layer
def forward(self, x):
x = self.hidden(x)
x = self.predict(x)
return x
对比贝叶斯回归模型,现在有2组参数 (输入到隐层以及隐层到输出),这里我们稍微修改一下模型先验:
priors = {'hidden.weight': w_prior,
'hidden.bias': b_prior,
'predict.weight': w_prior2,
'predict.bias': b_prior2}
以及分布:
dists = {'hidden.weight': w_dist,
'hidden.bias': b_dist,
'predict.weight': w_dist2,
'predict.bias': b_dist2}
需要给模型中所有分布设定不同的名字,因为此处不能有模棱两可或重复! 代码中可以看到更多细节。我们看一下模型拟合后采样的最终结果:
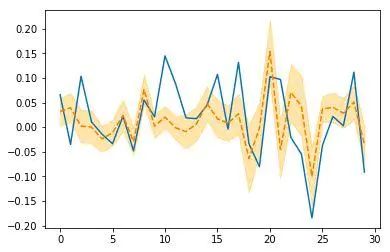
image
Pyro神经网络30天预测
看起来比之前所有的结果都要好一些!
关于正则化或者说贝叶斯模型得到的权重比之普通模型,要看一下权重的统计值。可以这样检查Pyro模型的参数:
for name in pyro.get_param_store().get_all_param_names():
print name, pyro.param(name).data.numpy()
在Keras 模型中是这么查看的:
import tensorflow as tf
sess = tf.Sessiom()
with sess.sa_default():
tf.global_variables_initializer().run()
dense_weights, out_weights = None, None
with sess.as_default():
for layer in model.layers:
if len(layer.weights) > 0:
weights = layer.get_weights()
if 'dense' in layer.name:
dense_weights = layer.weights[0].eval()
if 'out' in layer.name:
out_weights = layer.weights[0].eval()
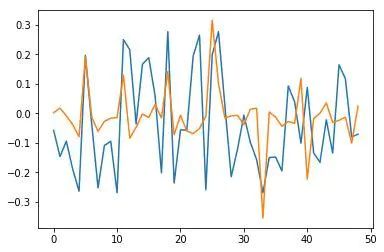
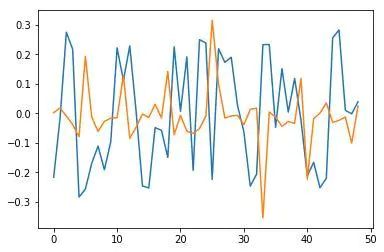
比如Keras模型最后一层权重的均值和方差分别为 -0.0025901748, 0.30395043,Pyro模型的均值和方差分别为0.0005974418, 0.0005974418。小了很多,这挺好! 这是很多正则化手段例如L2或Dropout处理的,将参数逼近至0,可以用变分推断实现! 隐层的情景就更有趣了。我们看一下权重向量图, 蓝色表示Keras权重, 橙色表示Pyro权重:
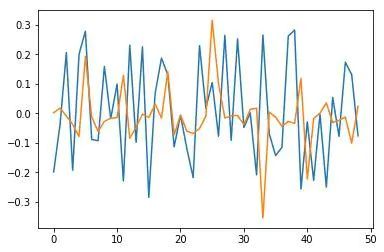
image
image
输入和隐层之间部分权重
事实上有趣的是,均值方差变小了,权重也变得稀疏。令人惊奇的是,最终学习得到一个稀疏表示第一组类似L1正则化,第二组类似L2正则化。可以跑一下代码 !
结论
我们使用新的方法训练神经网络,通过更新权重的分布(而不是依次更新静态权重),得到了有趣的并有前景的结果。我想强调贝叶斯方法可以帮助我们在不手工添加正则化器的情况下正则化神经网络,帮助理解模型的不确定性,并通过较少数据得到较好的训练结果。敬请关注! :)
点击使用概率编程和Pyro进行金融预测即可访问:
社长今日推荐:2019 最新斯坦福 CS224nNLP 课程
自然语言处理(NLP)是信息时代最重要的技术之一,也是人工智能的关键部分。NLP的应用无处不在,因为人们几乎用语言进行交流:网络搜索,广告,电子邮件,客户服务,语言翻译,医学报告等。近年来,深度学习方法在许多不同的NLP任务中获得了非常高的性能,使用单个端到端神经模型,不需要传统的,任务特定的特征工程。在本课程中,学生将深入了解NLP深度学习的前沿研究。
课程链接:https://ai.yanxishe.com/page/groupDetail/59