图解java.util.concurrent并发包源码系列——深入理解ConcurrentHashMap并发容器,看完薪水涨一千
图解java.util.concurrent并发包源码系列——深入理解ConcurrentHashMap并发容器
- HashMap简单介绍
- HashMap在并发场景下的问题
- HashMap在并发场景下的替代方案
- ConcurrentHashMap如何在线程安全的前提下提升并发度
-
- 1.7
- 1.8
- JDK1.7的ConcurrentHashMap源码
- JDK1.8的ConcurrentHashMap源码
HashMap简单介绍
ConcurrentHashMap是java.util.concurrent提供的一个并发安全的容器,可以实现高并发场景下读写的并发安全的同时兼顾了性能。它是HashMap的加强版,是并发安全的HashMap。
ConcurrentHashMap是基于HashMap的扩展,所以可以先简单回顾一下HashMap。
HashMap是一个存储键值对(key-value)的容器,往容器中放入元素要指定对应的key,往容器中获取元素前,通过指定key来获取对应的value。
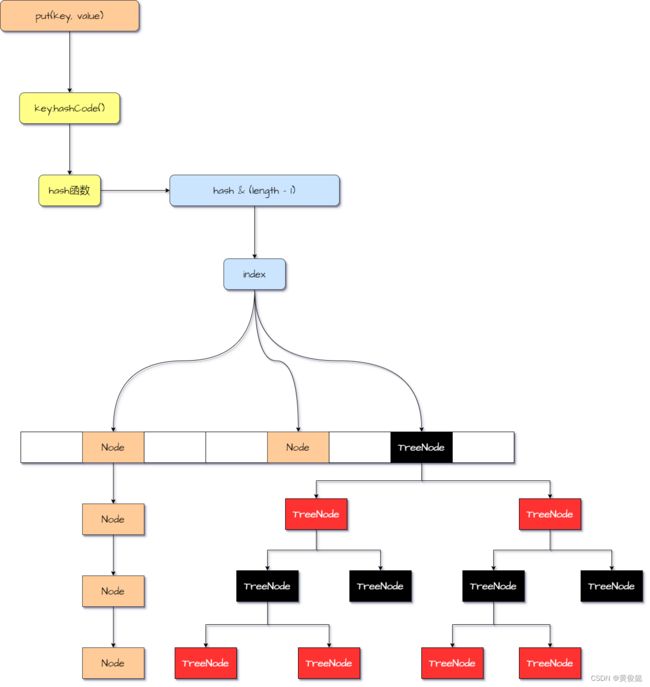
HashMap里面使用一个数组去存放放入进来的键值对,在JDK1.7这个数组的类型是 Entry,而JDK1.8这个数组的类型变为Node。
当一对key-value要放入进来时,会计算当前要放入的数组下标。计算方式是取得key的hashcode,然后对hashcode使用hash函数进行运算,得到一个hash值,然后 hash & (数组长度 - 1) 计算出数组下标。然后把key-value封装为对应的实体类(Entry或Node),放入到数组中对应数组下标的位置上。
如果不同的元素放入数组是出现了hash碰撞,会采用链表的方式解决,在JDK1.8后,当链表长度大于等于8并且数组长度大于等于64,链表会转为红黑树。
HashMap内部记录了扩容阈值,当数组中元素的个数达到扩容阈值后,数组会进行扩容,并把元素重新散列到新数组中取。
HashMap的读取和写入都是简单以计算一个hash值,然后根据hash值计算数组下标,直接定位,所以时间复杂度都是O(1)。
HashMap在并发场景下的问题
HashMap是非删除安全的集合容器,在高并发场景下,会发生更新丢失的问题。比如当某个数组下标index对应的位置是空,此时两个线程同时调用put方法往HashMap中插入元素,而且正好都是插入到这个位置,它们如果同时判断当前位置是空,其中一个线程插入的元素就会被覆盖。

HashMap在并发场景下的替代方案
在ConcurrentHashMap出来以前,要解决并发场景下HashMap线程不安全的问题,可以使用Hashtable替代,Hashtable在所有方法上都加了synchronized关键字。

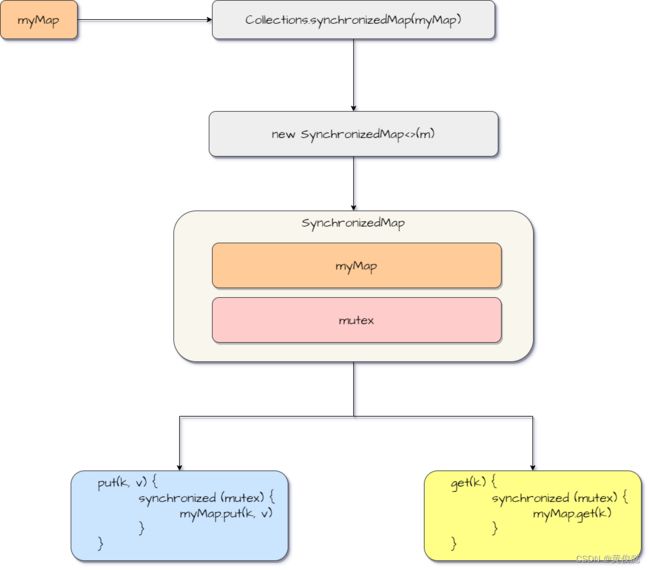
除了Hashtable以外,我们还可以使用Collections.synchronizedMap(hashMap)方法获得一个线程安全的Map容器。
java.util.Collections#synchronizedMap
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
java.util.Collections.SynchronizedMap#SynchronizedMap(java.util.Map
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap是Collections的内部类,保存了一个mutex作为锁对象,这个锁对象是this,也就是SynchronizedMap对象自己。而this.m保存的就是我们传递给Collections的Map。
java.util.Collections.SynchronizedMap#get
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
java.util.Collections.SynchronizedMap#put
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
SynchronizedMap的的方法都是先通过synchronized代码块保证并发安全,在操作我们的map之前,先获取mutex对象锁,然后在调我们的map的对应方法,是一种代理模式的实现。
这两种方式都是通过synchronized锁住一整个对象,虽然保证了线程安全,但是效率不高。所以JDK在1.5的版本推出了一个新的线程安全的并发Map集合ConcurrentHashMap。
ConcurrentHashMap如何在线程安全的前提下提升并发度
ConcurrentHashMap由于有1.7之前和1.8两个版本,所以要讨论ConcurrentHashMap如何在线程安全的前提下提升并发度,还要分开两个版本进行讨论。
1.7
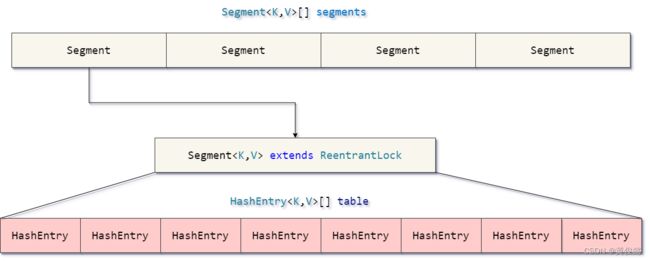
JDK1.7的ConcurrentHashMap通过分段锁的机制提升并发度。
ConcurrentHashMap把原来HashMap的数组切分成一段一段,每一个段用一个Segment对象保存。当要往ConcurrentHashMap放入元素时,需要先定位元素在哪一个Segment中,然后定位到对应的Segment后,要获取ReentrantLock锁,加锁成功,才能往Segment里面的数组中插入元素。从ConcurrentHashMap中获取元素则不需要加锁,只需定位到对应的Segment,然后从Segment的数组中获取对应的元素。
ConcurrentHashMap结构:
写操作流程:
![]()
读操作流程:
![]()
1.8
JDK1.8的ConcurrentHashMap放弃了分段锁的思想,改用了synchronized加CAS实现。
ConcurrentHashMap的结构与HashMap一样,是一个Node数组。每次往Node数组写入数据前,先判断数组是否已经初始化,未初始化要先初始化,初始化要获取CAS自旋锁。数组已初始化,通过hash函数和下标计算定位写入的位置,判断该位置是否为null。如果为null,则通过CAS写入一个新的Node到该位置,如果CAS失败则自旋。如果对应的位置不是null,那么需要对当前位置的第一个Node加synchronized对象锁,加锁成功后才能遍历链表进行修改或新增操作(链表尾部)。由于JDK1.8的HashMap和ConcurrentHashMap都是尾插法,所以一旦一个数组位置中不为null,那么头节点是永远固定的。而从ConcurrentHashMap中读取某个元素时,是不需要加锁的,而且由于没有分段,所以不需要像1.7那样两次定位,所以读操作的流程与HashMap是基本一样的。
ConcurrentHashMap结构:

写操作流程:

JDK1.7的ConcurrentHashMap源码
ConcurrentHashMap内部有一个Segment的数组。
final Segment<K,V>[] segments;
每个Segment内部又有一个HashEntry数组。
transient volatile HashEntry<K,V>[] table;
Segment继承了ReentrantLock锁,可以通过Segment加锁。
static final class Segment<K,V> extends ReentrantLock implements Serializable {...}
ConcurrentHashMap#put:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 通过hash函数计算出hash值
int hash = hash(key.hashCode());
// 定位Segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
// 调用Segment的put方法
return s.put(key, hash, value, false);
}
- 通过hash函数计算出hash值
- 定位Segment
- 调用Segment的put方法

Segment#put:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 获取ReentrantLock锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 定位数组下标
int index = (tab.length - 1) & hash;
// 数组下标对应的位置的第一个节点
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
// 遍历链表
if (e != null) {
K k;
// 找到匹配的key,修改value值
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 遍历到最后,没有发现匹配的key
if (node != null)
// 头插法
node.setNext(first);
else
// 目标位置为null,new一个HashEntry
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果元素个数大于扩容阈值,进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// 插入到数组中
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 释放锁
unlock();
}
return oldValue;
}
- 获取ReentrantLock锁
- 定位数组下标 (tab.length - 1) & hash
- 获取数组下标对应的位置的第一个元素,遍历链表
- 找到匹配的key,修改value值
- 遍历到最后,没有发现匹配的key
- 5.1 目标位置是null,new一个HashEntry
- 5.2 目标位置不是null,头插法
- 5.3 如果元素个数大于扩容阈值,进行扩容
- 释放锁

ConcurrentHashMap#get:
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
// 通过hash函数获取hash值
int h = hash(key.hashCode());
// 定位Segment
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 通过UNSAFE.getObjectVolatile方法取得Segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// (tab.length - 1) & h 定位数组位置,遍历链表
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
// 找到匹配key的HashEntry,返回value
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
- 通过一个hash函数,取得一个hash值h
- 用h进行位运算取得Segment数组中的目标位置u
- 通过UNSAFE.getObjectVolatile(segments, u)取得目标Segment
- 通过 (tab.length - 1) & h 计算得到HashEntry数组中的目标位置
- 遍历链表,找到匹配key的HashEntry,返回value

JDK1.8的ConcurrentHashMap源码
java.util.concurrent.ConcurrentHashMap#put:
public V put(K key, V value) {
return putVal(key, value, false);
}
java.util.concurrent.ConcurrentHashMap#putVal:
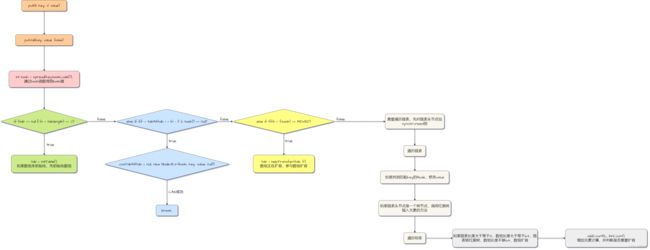
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 通过hash函数得到hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 如果数组未初始化,先初始化数组
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 数组目标位置为null,CAS插入
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// 数组正在扩容,参与数组扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 需要遍历链表,先对链表头节点加synchronized锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果找到匹配key的Node,修改value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 遍历到链表尾部,插入新节点到尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 链表头节点是一个树节点,调用红黑树插入元素的方法
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果链表长度大于等于8,数组长度大于等于64,链表转红黑树,数组长度不够64,数组扩容
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 增加元素计算,并判断是否需要扩容
addCount(1L, binCount);
return null;
}
- 通过hash函数得到hash值
- 如果数组未初始化,先初始化数组
- 数组目标位置为null,尝试CAS插入新节点到目标位置
- 如果数组正在扩容,参与数组扩容
- 如果需要遍历链表,先对链表头节点加synchronized锁
- 遍历链表
- 6.1 如果找到匹配key的Node,修改value
- 6.2 遍历到链表尾部,插入新节点到尾部
- 如果链表长度大于等于8,数组长度大于等于64,链表转红黑树,数组长度不够64,数组扩容
- 增加元素计算,并判断是否需要扩容
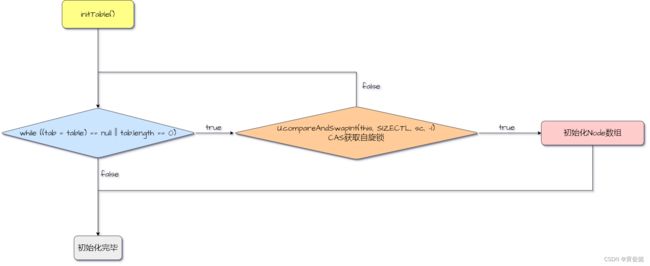
java.util.concurrent.ConcurrentHashMap#initTable
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield();
// CAS获取自旋锁
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 初始化Node数组
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
initTable方法进行Node数组的初始化,初始化前先通过CAS获取自旋锁,获取到了才能进行Node数组的初始化。
java.util.concurrent.ConcurrentHashMap#casTabAt:
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
casTabAt是当数组中对应位置元素为null时调用的,尝试CAS初始化对应位置的元素,调用的是Unsafe的compareAndSwapObject方法。

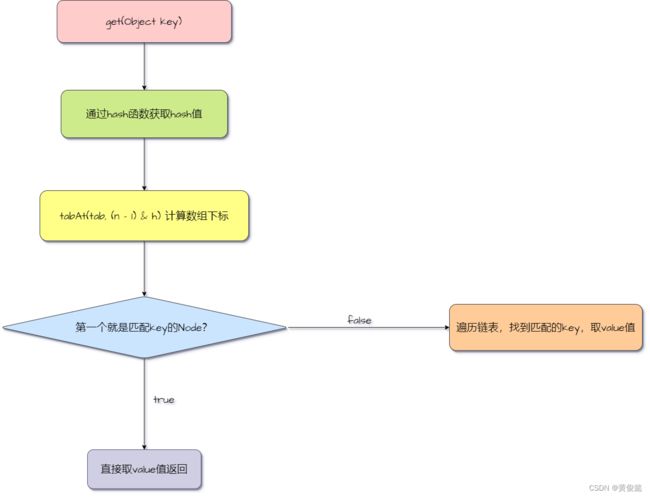
java.util.concurrent.ConcurrentHashMap#get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 通过hash函数获取hash值
int h = spread(key.hashCode());
// tabAt(tab, (n - 1) & h) 计算数组下标
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 第一个就是匹配key的Node,直接取value值
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 数组在扩容的时候,有可能会进这个分支,如果进了这个分支,代表当前位置的元素已经全被挪到新数组中去了,到新数组中去找
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍历链表,找到匹配的key,取value值
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
- 通过hash函数获取hash值
- tabAt(tab, (n - 1) & h) 计算数组下标
- 如果第一个就是匹配key的Node,直接取value值
- 遍历链表,找到匹配的key,取value值