深度学习——目标检测(R-CNN、Fast R-CNN、Faster R-CNN)
目录
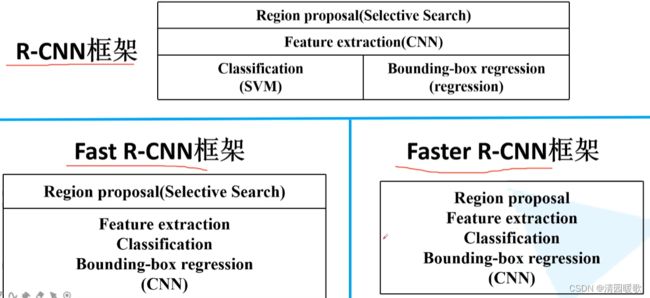
一、RCNN
二、Fast R-CNN
三、Faster R-CNN
四、FPN(Feature Pyramid Networks)
一、RCNN

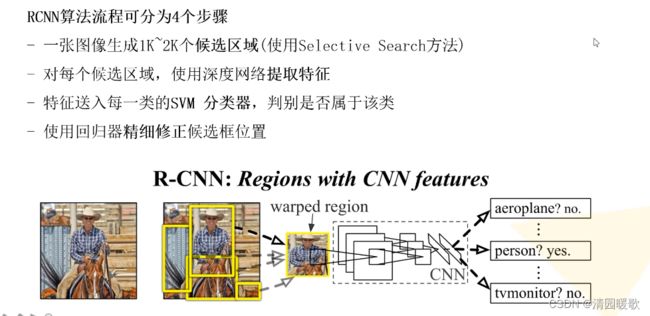

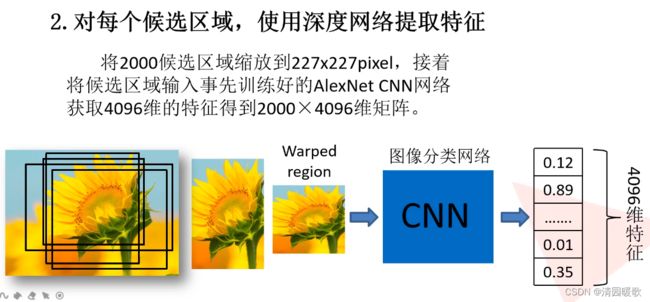
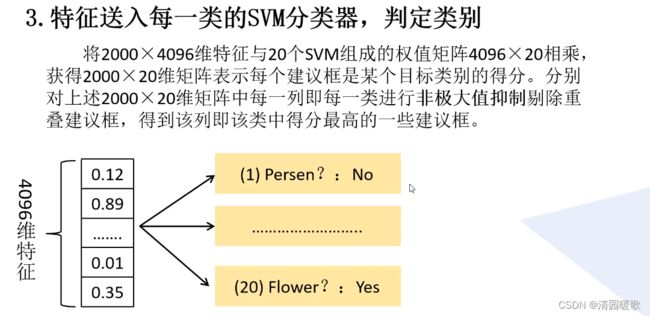
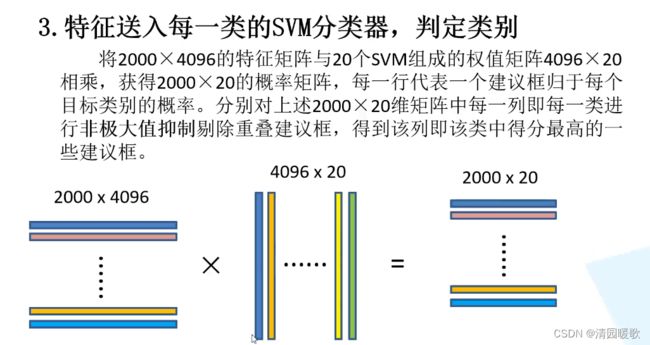
2000个框,每个框都得到4096个特征,把得到的输入svm,得出20个分类的结果
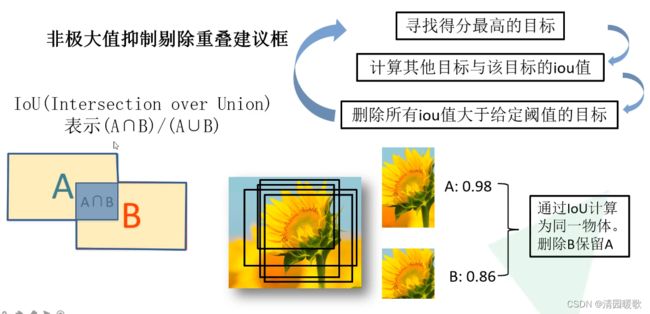
A svm分类后概率为 0.98,B 概率为 0.86,通过对边界框进行IOU计算,大于我们设定的阈值说明是同一个目标,就把概率低的删掉

回归那里,因变量就是高度、宽度、长度比例、宽度比例,一个四维的数据


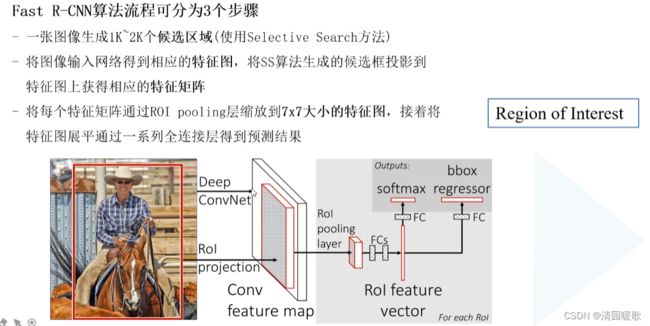
二、Fast R-CNN

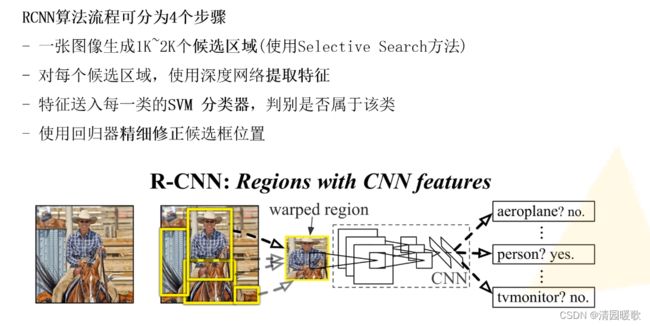
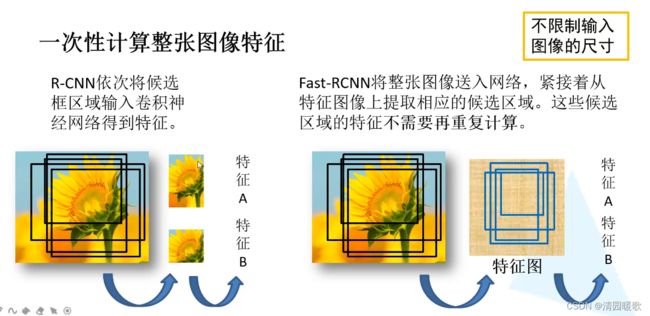
RCNN是将候选区域输入网络,Fast R-CNN是将整个图像输入网络

目标检测architecture通常可以分为两个阶段:
(1)region proposal:给定一张输入image找出objects可能存在的所有位置。这一阶段的输出应该是一系列object可能位置的bounding box。这些通常称之为region proposals或者 regions of interest(ROI),在这一过程中用到的方法是基于滑窗的方式和selective search。
(2)final classification:确定上一阶段的每个region proposal是否属于目标一类或者背景。
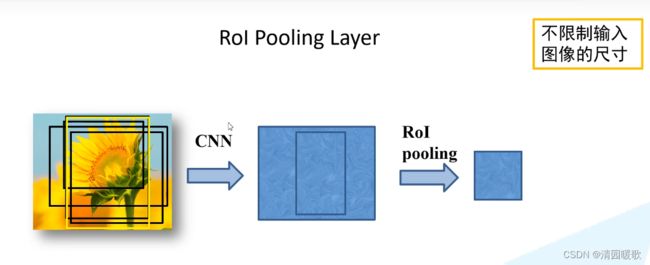
ROI pooling具体操作如下:
- 根据输入image,将ROI映射到feature map对应位置;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
- 对每个sections进行max pooling操作;

从 2000 个候选框,采集64个候选区域,一部分是正样本,一部分是负样本
只要 IOU 大于0.5就是正样本,0.1 到 0.5是负样本


最后并联两个全连接层,一个用来 分类概率的预测,另一个用来 边界框参数的预测
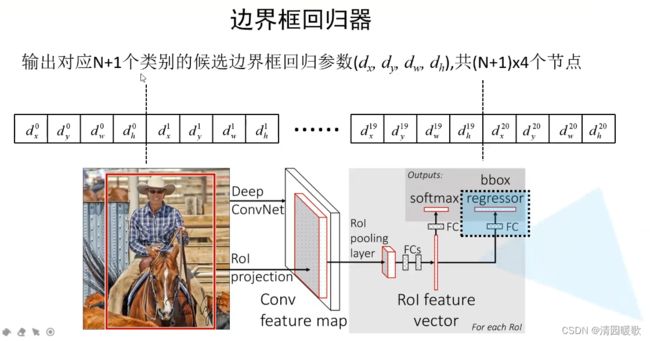
每个类别都有4个参数


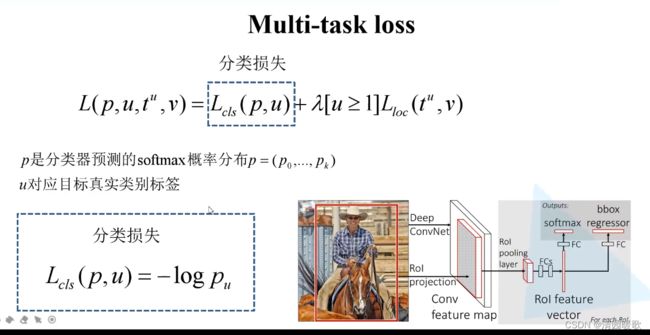
这里的分类损失其实就是交叉熵损失


[u≥1] 的意思是:当 u 满足 ≥1时,这一项 = 1,当u不满足≥1时,就是对应背景时,这一项 =0
真实框参数 v ,如 Vy = (Gy - Py)/ Ph

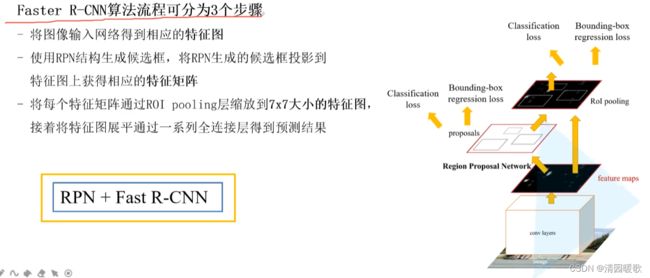
三、Faster R-CNN

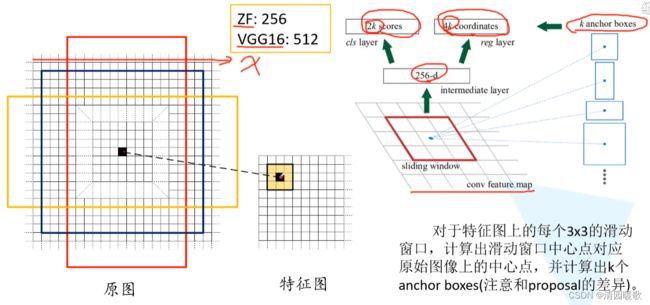
投影方法:找到候选框ROI在原始图像上的位置,然后等比例缩放到特征图的相同位置上

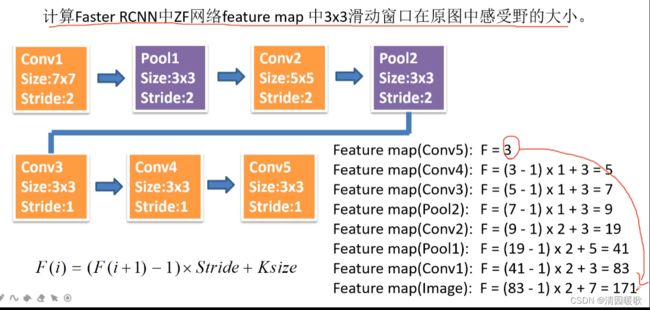
深度学习之 RPN(RegionProposal Network)- 区域候选网络_奔跑的大西吉的博客-CSDN博客
2k个概率:背景和前景
4k个边界框回归参数
backbone 就是你用于特征提取的主干网络结构
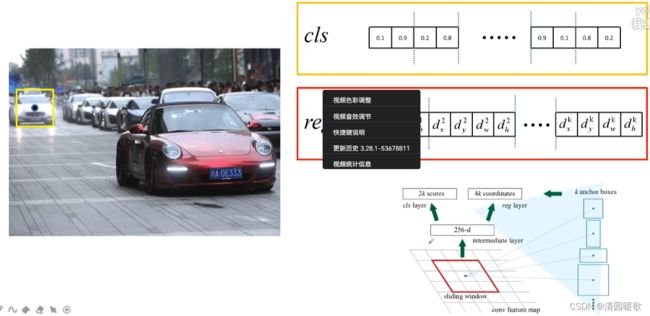
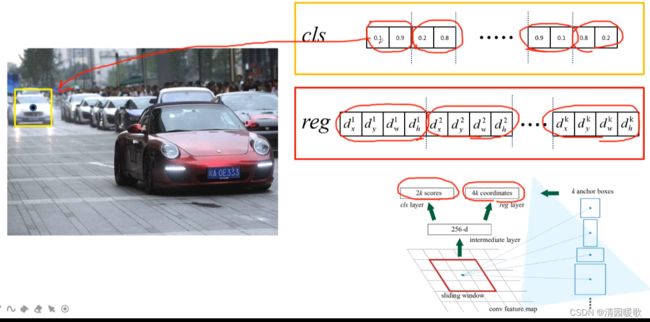
这是只是预测它是背景还是前景,没有对其进行分类
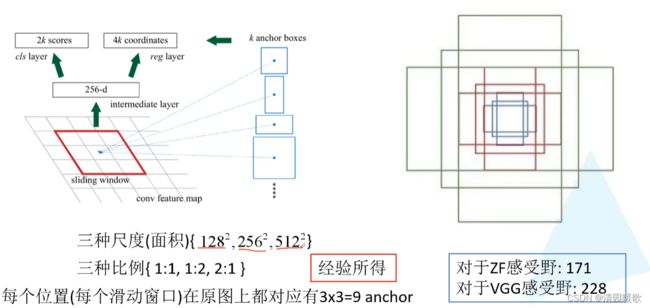

小感受野也能预测大范围的
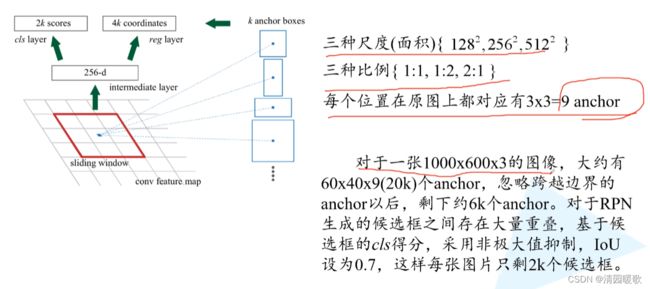

对于每张图片,从上万个anchor中采样256个anchor,这256大概是由1:1的正负样本组成,如果正样本个数不足128就用负样本进行填充
正样本:(1)与真实框IOU大于0.7
(2)和真实框想交的框中最大的IOU的(IOU都小于0.7时)
负样本:与真实框IOU小于0.3
其他全部丢弃
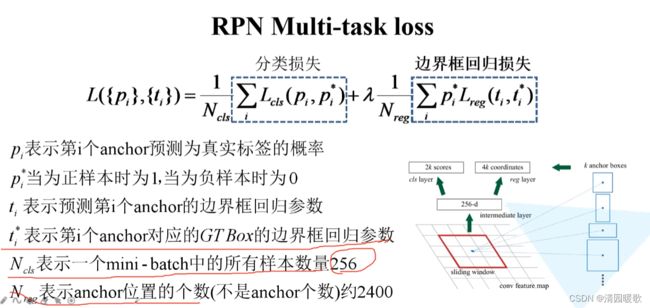
λ*1/Nreg 有时直接用 1/Ncls替代,因为λ=10时,Nreg=2400,实际差不太多
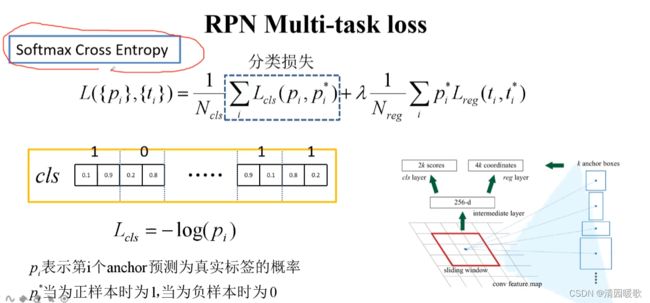
这是就是k个binary cross entropy损失,不是softmax cross entropy。这是细节
这里预测的就是是否是背景

这里应该就是二值交叉熵损失,如果是softmax,对于是前景的概率应该也是更大的概率,而不是0.1这种,pi就是目标的概率




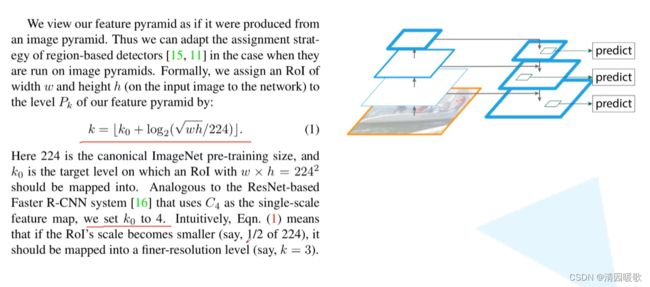
四、FPN(Feature Pyramid Networks)
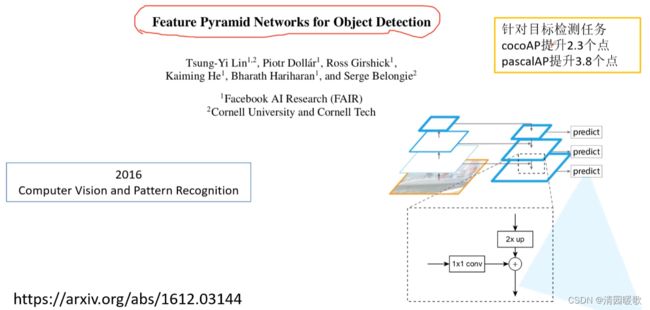
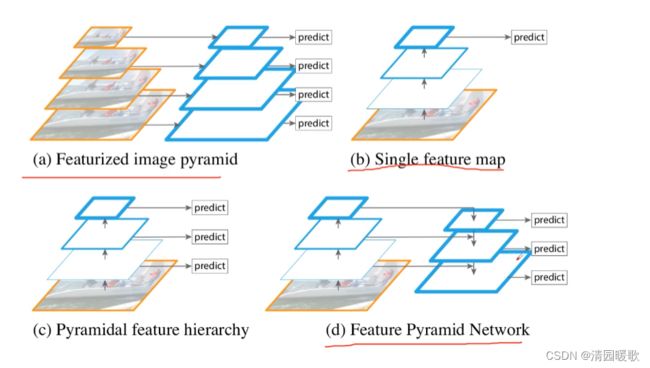
特征融合预测
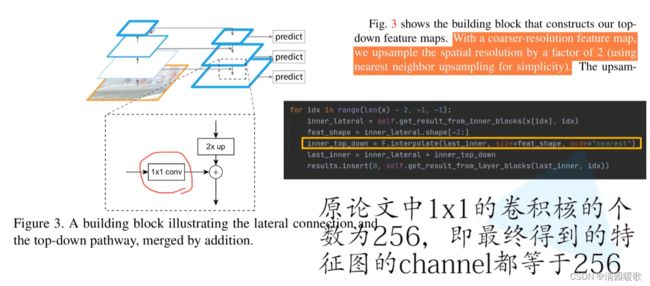
小特征图融合大的时,进行上采样
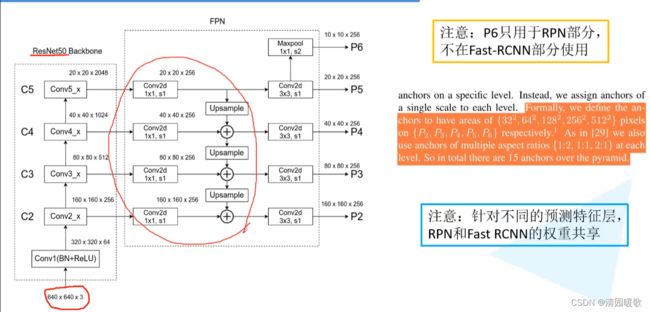
在P2到P65个特征图上对生成proposal进行预测
将生成的proposal用于P2到P5的4个特征图上进行Fast RCNN预测
可以在不同的特征层上针对不同尺度的目标进行预测,如P2是相对较底层的特征层,他会保留更多的底层细节信息,所有更适合预测小型目标,所以32²比例{1:2, 1:1, 2:1}的anchor在P2上生成
在不同的特征层上用不同的RPN和Fast RCNN和用相同的最后效果其实没什么差异,所以可以共享参数
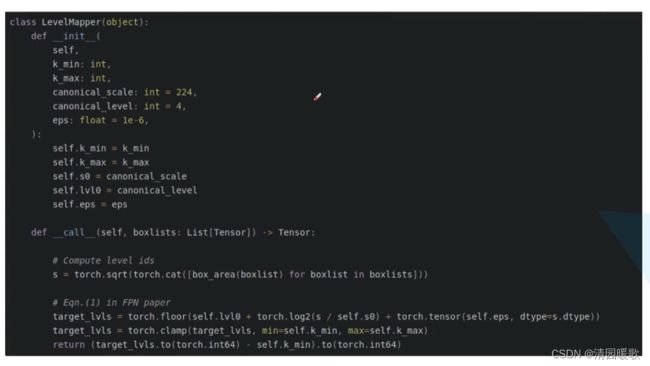
用公式,把proposal映射到特征层上