数据分箱方法 woe编码
Feature engineering is the most important aspect of a data science model development. There are several categories of features in a raw dataset. Features can be text, date/time, categorical, and continuous variables. For a machine learning model, the dataset needs to be processed in the form of numerical vectors to train it using an ML algorithm.
功能 工程是数据科学模型开发中最重要的方面。 原始数据集中有几类要素。 功能可以是文本,日期/时间,类别和连续变量。 对于机器学习模型,需要以数值向量的形式处理数据集,以使用ML算法对其进行训练。
The objective of this article is to demonstrate feature engineering techniques to transform a categorical feature into a continuous feature and vice-versa.
本文的目的是演示特征工程技术,以将分类特征转换为连续特征,反之亦然。
Feature Binning: Conversion of a continuous variable to categorical.
特征分级:将连续变量转换为分类变量。
Feature Encoding: Conversion of a categorical variable to numerical features.
特征编码:将分类变量转换为数字特征。
功能分级: (Feature Binning:)
Binning or discretization is used for the transformation of a continuous or numerical variable into a categorical feature. Binning of continuous variable introduces non-linearity and tends to improve the performance of the model. It can be also used to identify missing values or outliers.
合并或离散化用于将连续变量或数值变量转换为分类特征。 连续变量的分箱引入了非线性,并趋于改善模型的性能。 它也可以用来识别缺失值或离群值。
There are two types of binning:
分箱有两种类型:
Unsupervised Binning: Equal width binning, Equal frequency binning
无监督合并:等宽合并,等频率合并
Supervised Binning: Entropy-based binning
监督分级:基于熵的分级
无监督分箱: (Unsupervised Binning:)
Unsupervised binning is a category of binning that transforms a numerical or continuous variable into categorical bins without considering the target class label into account. Unsupervised binning are of two categories:
无监督分箱是一种分箱,将数字或连续变量转换为分类箱, 而无需考虑目标类标签 。 无监督分箱分为两类:
1.等宽合并: (1. Equal Width Binning:)
This algorithm divides the continuous variable into several categories having bins or range of the same width.
该算法将连续变量分为具有相同宽度的区间或范围的几个类别。

Notations,
x = number of categories
w = width of a category
max, min = Maximum and Minimun of the list
2.等频率合并: (2. Equal frequency binning:)
This algorithm divides the data into various categories having approximately the same number of values. The values of data are distributed equally into the formed categories.
该算法将数据分为具有大致相同数量的值的各种类别。 数据值平均分配到形成的类别中。
Notations,
x = number of categories
freq = frequency of a category
n = number of values in data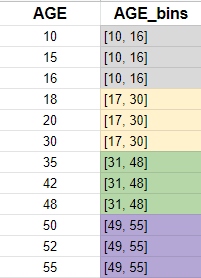
有监督的分箱: (Supervised Binning:)
Supervised binning is a type of binning that transforms a numerical or continuous variable into a categorical variable considering the target class label into account. It refers to the target class label when selecting discretization cut points. Entropy-based binning is a type of supervised binning.
监督合并是一种合并,将考虑目标类标签的数值或连续变量转换为分类变量。 选择离散化切点时,它指向目标类别标签。 基于熵的装箱是一种有监督的装箱。
1.基于熵的分箱: (1. Entropy-based Binning:)
The entropy-based binning algorithm categorizes the continuous or numerical variable majority of values in a bin or category belong to the same class label. It calculates entropy for target class labels, and it categorizes the split based on maximum information gain.
基于熵的装箱算法将属于同一类别标签的箱或类别中的大多数连续或数值变量分类。 它计算目标类别标签的熵,并根据最大信息增益对拆分进行分类。
功能编码: (Feature Encoding:)
Feature Encoding is used for the transformation of a categorical feature into a numerical variable. Most of the ML algorithms cannot handle categorical variables and hence it is important to do feature encoding. There are many encoding techniques used for feature engineering:
特征编码用于将分类特征转换为数值变量。 大多数ML算法无法处理分类变量,因此进行特征编码非常重要。 特征工程使用许多编码技术:
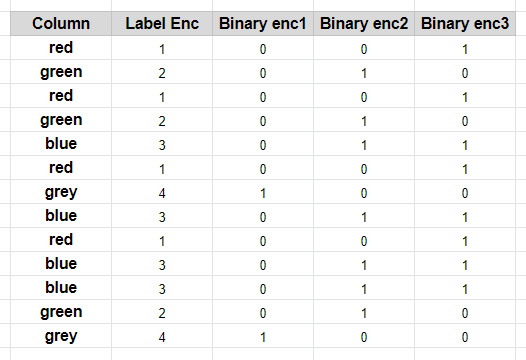
1.标签编码: (1. Label Encoding:)
Label encoding is an encoding technique to transform categorical variables into numerical variables by assigning a numerical value to each of the categories. Label encoding can be used for Ordinal variables.
标签编码是一种通过为每个类别分配数值来将类别变量转换为数值变量的编码技术。 标签编码可用于序数变量 。
2.顺序编码: (2. Ordinal encoding:)
Ordinal encoding is an encoding technique to transform an original categorical variable to a numerical variable by ensuring the ordinal nature of the variables is sustained.
序数编码是一种编码技术,可通过确保变量的序数性质得以维持 ,将原始类别变量转换为数值变量。

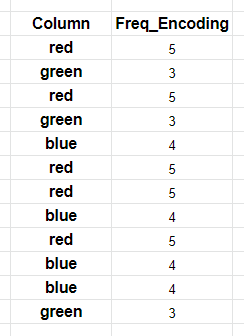
3.频率编码: (3. Frequency encoding:)
Frequency encoding is an encoding technique to transform an original categorical variable to a numerical variable by considering the frequency distribution of the data. It can be useful for nominal features.
频率编码是一种编码技术,通过考虑数据的频率分布将原始类别变量转换为数值变量。 它对于名义特征很有用。
4.二进制编码: (4. Binary encoding:)
Binary encoding is an encoding technique to transform an original categorical variable to a numerical variable by encoding the categories as Integer and then converted into binary code. This method is preferable for variables having a large number of categories.
二进制编码是一种通过将类别编码为Integer然后将其转换为二进制代码,从而将原始类别变量转换为数值变量的编码技术。 对于具有大量类别的变量,此方法更可取。
For a 100 category variable, Label Encoding creating 100 labels each corresponding to a category, but instead binary encoding creating only 7 categories.
对于100个类别变量,Label Encoding创建100个标签,每个标签对应一个类别,但是二进制编码仅创建7个类别。
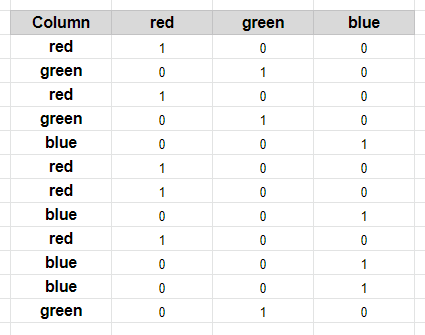
5.一种热编码: (5. One hot encoding:)
One hot encoding technique splits the category each to a column. It creates k different columns each for a category and replaces one column with 1 rest of the columns is 0.
一种热编码技术将类别分别划分为一列。 它为一个类别分别创建k个不同的列,并用1个其余列替换一个列为0。
6.目标均值编码: (6. Target Mean encoding:)
Mean encoding is one of the best techniques to transform categorical variables into numerical variables as it takes the target class label into account. The basic idea is to replace the categorical variable with the mean of its corresponding target variable.
均值编码是将分类变量转换为数值变量的最佳技术之一,因为它考虑了目标类标签。 基本思想是将分类变量替换为其相应目标变量的平均值。
Here the categorical variable that needs to be encoded is the independent variable (IV) and the target class label is the dependent variable (DV).
这里需要编码的分类变量是自变量(IV),目标类别标签是因变量(DV)。
Steps for mean encoding:
均值编码的步骤:
- Select a category 选择一个类别
- Group by the category and obtain aggregated sum (= a) 按类别分组并获得汇总总和(= a)
- Group by the category and obtain aggregated total count (= b) 按类别分组并获得汇总总数(= b)
- Numerical value for that category = a/b 该类别的数值= a / b
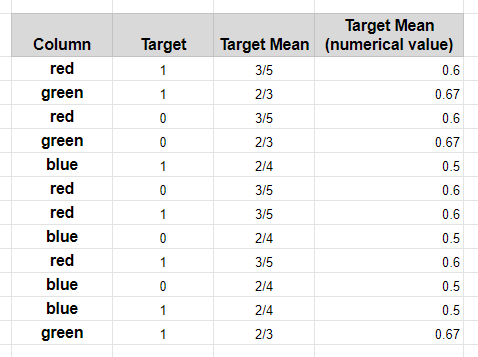
实现方式: (Implementation:)
(Code by Author), Python implementation of Encoders (作者编写的代码),编码器的Python实现结论: (Conclusion:)
Feature engineering is a cycle process, nobody can conclude that this feature engineering technique is the best. There is no thumb rule to pick a particular feature engineering — encoding or binning technique during data processing. So one needs to try focusing on feature engineering as per business requirement, try every process several times and pick the best out of it.
特征工程是一个循环过程,没有人能断定该特征工程技术是最好的。 没有经验法则可以选择特定的要素工程-数据处理期间的编码或合并技术。 因此,需要根据业务需求尝试着重于要素工程,尝试每个流程几次,然后从中选出最好的。
Thank You for Reading
谢谢您的阅读
翻译自: https://towardsdatascience.com/feature-engineering-deep-dive-into-encoding-and-binning-techniques-5618d55a6b38
数据分箱方法 woe编码