第1章 实践基础——张量
声明:本内容基于百度提供的paddlepaddle框架,参考复旦大学邱锡鹏老师著作《神经网络与深度学习》(蒲公英书)与《神经网络与深度学习:案例与实践》(nndl)理解完成。(书籍源代码:源代码)
深度学习在很多领域中都有非常出色的表现,例如:图像识别、语音识别、自然语言处理、机器人、广告投放、医学诊断和金融等领域。而目前深度学习的模型还主要是各种各样的神经网络。随着网络越来越复杂,从底层开始一步步实现深度学习系统变得非常低效,其中涉及模型搭建、梯度求解、并行计算、代码实现等多个环节。每一个环节都需要进行精心实现和检查,需要耗费开发人员很多的精力。为此,深度学习框架(也常称为机器学习框架)应运而生,它有助于研发人员聚焦任务和模型设计本身,省去大量而烦琐的代码编写工作,其优势主要表现在如下两个方面:
- 实现简单:深度学习框架屏蔽了底层实现,用户只需关注模型的逻辑结构,同时简化了计算逻辑,降低了深度学习入门门槛。
- 使用高效:深度学习框架具备灵活的移植性,在不同设备(CPU、GPU或移动端)之间无缝迁移,使得深度学习框架会使模型训练以及部署更高效。
作为实践的基础框架,飞桨(paddlepaddle)框架是一套面向深度学习的基础训练和推理框架。飞桨于2016年正式开源,是主流深度学习开源框架中一款完全国产化的产品。目前,飞桨框架已经非常成熟并且易用。
第一节:张量
1.1概念
张量(Tensor):张量是深度学习中表示和存储数据的主要形式。 在实践中,我们通常使用向量或矩阵运算来提高计算效率。比如![]() 的计算可以用
的计算可以用![]() (T表示转置)来代替(其中
(T表示转置)来代替(其中![]() ),这样可以充分利用计算机的并行计算能力,特别是利用GPU来实现高效矩阵运算。
),这样可以充分利用计算机的并行计算能力,特别是利用GPU来实现高效矩阵运算。
在深度学习框架中,数据经常用张量(Tensor)的形式来存储。张量是矩阵的扩展与延伸,可以认为是高阶的矩阵。1阶张量为向量,2阶张量为矩阵。张量是类似于Numpy的多维数组(ndarray)的概念,可以具有任意多的维度。(注意:这里的“维度”是“阶”的概念,和线性代数中向量的“维度”含义不同)
张量的大小可以用形状(shape)来描述。比如一个三维张量的形状是 [2,2,5][2, 2, 5][2,2,5],表示每一维(也称为轴(axis))的元素的数量,即第0轴上元素数量是2,第1轴上元素数量是2,第2轴上的元素数量为5。
图1.5给出了3种纬度的张量可视化表示。
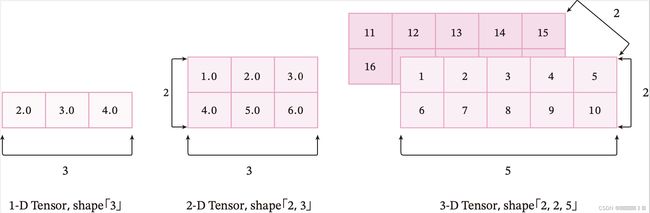
张量中元素的类型可以是布尔型数据、整数、浮点数或者复数,但同一张量中所有元素的数据类型均相同。因此我们可以给张量定义一个数据类型(dtype)来表示其元素的类型。
1.2张量的数据类型
飞桨中可以通过Tensor.dtype来查看张量的数据类型,类型支持bool、float16、float32、float64、uint8、int8、int16、int32、int64和复数类型数据。
1)通过Python元素创建的张量,可以通过dtype来指定数据类型,如果未指定:
- 对于Python整型数据,则会创建int64型张量。
- 对于Python浮点型数据,默认会创建float32型张量。
2)通过Numpy数组创建的张量,则与其原来的数据类型保持相同。通过paddle.to_tensor()函数可以将Numpy数组转化为张量
1.3创建
创建一个一维张量。
Tensor(shape=[3], dtype=float32, place=CPUPlace, stop_gradient=True,
[2., 3., 4.])
# 导入PaddlePaddle
import paddle
# 创建一维Tensor
ndim_1_Tensor = paddle.to_tensor([2.0, 3.0, 4.0])
print(ndim_1_Tensor)创建类似矩阵(matrix)的二维张量
Tensor(shape=[2, 3], dtype=float32, place=CPUPlace, stop_gradient=True,
[[1., 2., 3.],
[4., 5., 6.]])
# 创建二维Tensor
ndim_2_Tensor = paddle.to_tensor([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]],dtype='float32')
print(ndim_2_Tensor)如果要创建一个指定形状、元素数据相同的张量,可以使用paddle.zeros、paddle.ones、paddle.full等API,类似于numpy.zeros(),numpy.ones()等函数,但paddle创建的张量dtype为列表。
m, n = 2, 3
# 使用paddle.zeros创建数据全为0,形状为[m, n]的Tensor
zeros_Tensor = paddle.zeros([m, n])
# 使用paddle.ones创建数据全为1,形状为[m, n]的Tensor
ones_Tensor = paddle.ones([m, n])
# 使用paddle.full创建数据全为指定值,形状为[m, n]的Tensor,这里我们指定数据为10
full_Tensor = paddle.full([m, n], 10)
print('zeros Tensor: ', zeros_Tensor)
print('ones Tensor: ', ones_Tensor)
print('full Tensor: ', full_Tensor)输出:
zeros Tensor: Tensor(shape=[2, 3], dtype=float32, place=CPUPlace, stop_gradient=True,
[[0., 0., 0.],
[0., 0., 0.]])
ones Tensor: Tensor(shape=[2, 3], dtype=float32, place=CPUPlace, stop_gradient=True,
[[1., 1., 1.],
[1., 1., 1.]])
full Tensor: Tensor(shape=[2, 3], dtype=float32, place=CPUPlace, stop_gradient=True,
[[10., 10., 10.],
[10., 10., 10.]])
指定区间创建张量使用paddle.arange、paddle.linspace等API。
# 使用paddle.arange创建以步长step均匀分隔数值区间[start, end)的一维Tensor
arange_Tensor = paddle.arange(start=1, end=5, step=1)
# 使用paddle.linspace创建以元素个数num均匀分隔数值区间[start, stop]的Tensor
linspace_Tensor = paddle.linspace(start=1, stop=5, num=5)
print('arange Tensor: ', arange_Tensor)
print('linspace Tensor: ', linspace_Tensor)输出情况如下:
arange Tensor: Tensor(shape=[4], dtype=int64, place=CPUPlace, stop_gradient=True,
[1, 2, 3, 4])
linspace Tensor: Tensor(shape=[5], dtype=float32, place=CPUPlace, stop_gradient=True,
[1., 2., 3., 4., 5.])
类似的,也可以将张量转换成array数组以节省空间
import numpy as np
t=np.array(arange_Tensor)
t
1.4张量的属性
张量具有如下形状属性:
Tensor.ndim:张量的维度,例如向量的维度为1,矩阵的维度为2。Tensor.shape: 张量每个维度上元素的数量。Tensor.shape[n]:张量第nnn维的大小。第nnn维也称为轴(axis)。Tensor.size:张量中全部元素的个数。
为了更好地理解ndim、shape、axis、size四种属性间的区别,创建一个如图1.6所示的四维张量。
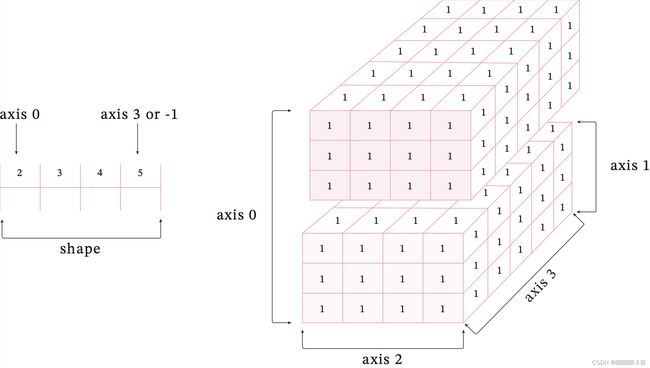
创建四维张量,打印其属性:
ndim_4_Tensor = paddle.ones([2, 3, 4, 5])
print("Number of dimensions:", ndim_4_Tensor.ndim)
print("Shape of Tensor:", ndim_4_Tensor.shape)
print("Elements number along axis 0 of Tensor:", ndim_4_Tensor.shape[0])
print("Elements number along the last axis of Tensor:", ndim_4_Tensor.shape[-1])
print('Number of elements in Tensor: ', ndim_4_Tensor.size)输出如下:
Number of dimensions: 4 Shape of Tensor: [2, 3, 4, 5] Elements number along axis 0 of Tensor: 2 Elements number along the last axis of Tensor: 5 Number of elements in Tensor: 120
1.5张量的相关操作
1.5.1改变形状
使用paddle.reshape改变张量形状:
ndim_3_Tensor = paddle.to_tensor([[[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10]],
[[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]],
[[21, 22, 23, 24, 25],
[26, 27, 28, 29, 30]]])
print("the shape of ndim_3_Tensor:", ndim_3_Tensor.shape)
# paddle.reshape 可以保持在输入数据不变的情况下,改变数据形状。这里我们设置reshape为[2,5,3]
reshape_Tensor = paddle.reshape(ndim_3_Tensor, [2, 5, 3])
print("After reshape:", reshape_Tensor)out:
the shape of ndim_3_Tensor: [3, 2, 5]
After reshape: Tensor(shape=[2, 5, 3], dtype=int64, place=CPUPlace, stop_gradient=True,
[[[1 , 2 , 3 ],
[4 , 5 , 6 ],
[7 , 8 , 9 ],
[10, 11, 12],
[13, 14, 15]],
[[16, 17, 18],
[19, 20, 21],
[22, 23, 24],
[25, 26, 27],
[28, 29, 30]]])
从输出结果看,将张量从[3, 2, 5]的形状reshape为[2, 5, 3]的形状时,张量内的数据不会发生改变,元素顺序也没有发生改变,只有数据形状发生了改变。
使用reshape时存在一些技巧,比如:
- -1表示这个维度的值是从张量的元素总数和剩余维度推断出来的。因此,有且只有一个维度可以被设置为-1。
- 0表示实际的维数是从张量的对应维数中复制出来的,因此shape中0所对应的索引值不能超过张量的总维度。
分别对上文定义的三维张量进行paddle.reshape为[-1]和[0, 5, 2]两种操作,观察新张量的形状:
new_Tensor1 = ndim_3_Tensor.reshape([-1])
print('new Tensor 1 shape: ', new_Tensor1.shape)
new_Tensor2 = ndim_3_Tensor.reshape([0, 5, 2])
print('new Tensor 2 shape: ', new_Tensor2.shape)out:
new Tensor 1 shape: [30] new Tensor 2 shape: [3, 5, 2]
当reshape为[-1]时,整个举行张量被压缩成一个向量,而reshape为[0, 5, 2]则不会改变其形状,而如果是reshape为比该张量更大的张量则会报错。
1.5.2切片与引索
可以通过索引或切片方便地访问或修改张量。飞桨使用标准的Python索引规则与Numpy索引规则,具有以下特点:
- 基于0−n的下标进行索引,与python切片相同
- 通过冒号“:”分隔切片参数start:stop:step来进行切片操作,也就是访问start到stop范围内的部分元素并生成一个新的序列。其中start为切片的起始位置,stop为切片的截止位置,step是切片的步长,这三个参数均可缺省。针对一维张量,对单个轴进行索引和切片。
针对一维张量,可以对单个轴进行索引和切片。
针对二维及以上维度的张量,在多个维度上进行索引或切片。索引或切片的第一个值对应第0维,第二个值对应第1维,以此类推,如果某个维度上未指定索引,则默认为“:”。
# 定义1个二维Tensor
ndim_2_Tensor = paddle.to_tensor([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]])
print("Origin Tensor:", ndim_2_Tensor)
print("First row:", ndim_2_Tensor[0])
print("First row:", ndim_2_Tensor[0, :])
print("First column:", ndim_2_Tensor[:, 0])
print("Last column:", ndim_2_Tensor[:, -1])
print("All element:", ndim_2_Tensor[:])
print("First row and second column:", ndim_2_Tensor[0, 1])out
Origin Tensor: Tensor(shape=[3, 4], dtype=int64, place=CPUPlace, stop_gradient=True,
[[0 , 1 , 2 , 3 ],
[4 , 5 , 6 , 7 ],
[8 , 9 , 10, 11]])
First row: Tensor(shape=[4], dtype=int64, place=CPUPlace, stop_gradient=True,
[0, 1, 2, 3])
First row: Tensor(shape=[4], dtype=int64, place=CPUPlace, stop_gradient=True,
[0, 1, 2, 3])
First column: Tensor(shape=[3], dtype=int64, place=CPUPlace, stop_gradient=True,
[0, 4, 8])
Last column: Tensor(shape=[3], dtype=int64, place=CPUPlace, stop_gradient=True,
[3 , 7 , 11])
All element: Tensor(shape=[3, 4], dtype=int64, place=CPUPlace, stop_gradient=True,
[[0 , 1 , 2 , 3 ],
[4 , 5 , 6 , 7 ],
[8 , 9 , 10, 11]])
First row and second column: Tensor(shape=[1], dtype=int64, place=CPUPlace, stop_gradient=True,
[1])
张量类的基础数学函数如下:
x.abs() # 逐元素取绝对值
x.ceil() # 逐元素向上取整
x.floor() # 逐元素向下取整
x.round() # 逐元素四舍五入
x.exp() # 逐元素计算自然常数为底的指数
x.log() # 逐元素计算x的自然对数
x.reciprocal() # 逐元素求倒数
x.square() # 逐元素计算平方
x.sqrt() # 逐元素计算平方根
x.sin() # 逐元素计算正弦
x.cos() # 逐元素计算余弦
x.add(y) # 逐元素加
x.subtract(y) # 逐元素减
x.multiply(y) # 逐元素乘(积)
x.divide(y) # 逐元素除
x.mod(y) # 逐元素除并取余
x.pow(y) # 逐元素幂
x.max() # 指定维度上元素最大值,默认为全部维度
x.min() # 指定维度上元素最小值,默认为全部维度
x.prod() # 指定维度上元素累乘,默认为全部维度
x.sum() # 指定维度上元素的和,默认为全部维度张量类的逻辑运算函数如下:
x.isfinite() # 判断Tensor中元素是否是有限的数字,即不包括inf与nan
x.equal_all(y) # 判断两个Tensor的全部元素是否相等,并返回形状为[1]的布尔类Tensor
x.equal(y) # 判断两个Tensor的每个元素是否相等,并返回形状相同的布尔类Tensor
x.not_equal(y) # 判断两个Tensor的每个元素是否不相等
x.less_than(y) # 判断Tensor x的元素是否小于Tensor y的对应元素
x.less_equal(y) # 判断Tensor x的元素是否小于或等于Tensor y的对应元素
x.greater_than(y) # 判断Tensor x的元素是否大于Tensor y的对应元素
x.greater_equal(y) # 判断Tensor x的元素是否大于或等于Tensor y的对应元素
x.allclose(y) # 判断两个Tensor的全部元素是否接近矩阵运算
张量类还包含了矩阵运算相关的函数,如矩阵的转置、范数计算和乘法等。
x.t() # 矩阵转置
x.transpose([1, 0]) # 交换第 0 维与第 1 维的顺序
x.norm('fro') # 矩阵的弗罗贝尼乌斯范数
x.dist(y, p=2) # 矩阵(x-y)的2范数
x.matmul(y) # 矩阵乘法
有些矩阵运算中也支持大于两维的张量,比如matmul函数,对最后两个维度进行矩阵乘。比如x是形状为[j,k,n,m]的张量,另一个y是[j,k,m,p]的张量,则x.matmul(y)输出的张量形状为[j,k,n,p]。
1.2.5.4 广播机制
飞桨的一些API在计算时支持广播(Broadcasting)机制,允许在一些运算时使用不同形状的张量。通常来讲,如果有一个形状较小和一个形状较大的张量,会希望多次使用较小的张量来对较大的张量执行某些操作,看起来像是形状较小的张量首先被扩展到和较大的张量形状一致,然后再做运算。
广播机制的条件
飞桨的广播机制主要遵循如下规则(参考Numpy广播机制):
1)每个张量至少为一维张量。
2)从后往前比较张量的形状,当前维度的大小要么相等,要么其中一个等于1,要么其中一个不存在。
# 当两个Tensor的形状一致时,可以广播
x = paddle.ones((2, 3, 4))
y = paddle.ones((2, 3, 4))
z = x + y
print('broadcasting with two same shape tensor: ', z.shape)
x = paddle.ones((2, 3, 1, 5))
y = paddle.ones((3, 4, 1))
# 从后往前依次比较:
# 第一次:y的维度大小是1
# 第二次:x的维度大小是1
# 第三次:x和y的维度大小相等,都为3
# 第四次:y的维度不存在
# 所以x和y是可以广播的
z = x + y
print('broadcasting with two different shape tensor:', z.shape)out
broadcasting with two same shape tensor: [2, 3, 4] broadcasting with two different shape tensor: [2, 3, 4, 5]
错误使用:
x = paddle.ones((2, 3, 4))
y = paddle.ones((2, 3, 6))
z = x + y因为在第一次从后往前的比较中,4和6不相等,不符合广播规则。
广播机制的计算规则
现在我们知道在什么情况下两个张量是可以广播的。两个张量进行广播后的结果张量的形状计算规则如下:
1)如果两个张量shape的长度不一致,那么需要在较小长度的shape前添加1,直到两个张量的形状长度相等。
2) 保证两个张量形状相等之后,每个维度上的结果维度就是当前维度上较大的那个。
以张量x和y进行广播为例,x的shape为[2, 3, 1,5],张量y的shape为[3,4,1]。首先张量y的形状长度较小,因此要将该张量形状补齐为[1, 3, 4, 1],再对两个张量的每一维进行比较。从第一维看,x在一维上的大小为2,y为1,因此,结果张量在第一维的大小为2。以此类推,对每一维进行比较,得到结果张量的形状为[2, 3, 4, 5]。
由于矩阵乘法函数paddle.matmul在深度学习中使用非常多,这里需要特别说明一下它的广播规则:
1)如果两个张量均为一维,则获得点积结果。
2) 如果两个张量都是二维的,则获得矩阵与矩阵的乘积。
3) 如果张量x是一维,y是二维,则将x的shape转换为[1, D],与y进行矩阵相乘后再删除前置尺寸。
4) 如果张量x是二维,y是一维,则获得矩阵与向量的乘积。
5) 如果两个张量都是N维张量(N > 2),则根据广播规则广播非矩阵维度(除最后两个维度外其余维度)。比如:如果输入x是形状为[j,1,n,m]的张量,另一个y是[k,m,p]的张量,则输出张量的形状为[j,k,n,p]。
正确用法:
x = paddle.ones([10, 1, 5, 2])
y = paddle.ones([3, 2, 5])
z = paddle.matmul(x, y)
print('After matmul: ', z.shape)out:
After matmul: [10, 3, 5, 5]
飞桨的API有原位(inplace)操作和非原位操作之分。原位操作即在原张量上保存操作结果,非原位操作则不会修改原张量,而是返回一个新的张量来表示运算结果。
下节内容:算子(Operator):构建神经网络模型的基础组件。每个算子有前向和反向计算过程,前向计算对应一个数学函数,而反向计算对应这个数学函数的梯度计算。有了算子,我们就可以很方便地通过算子来搭建复杂的神经网络模型,而不需要手工计算梯度。
本文章提到的飞桨(paddlepaddle)API详细内容可凭其名称查询API官网