因为最近的多元统计讲到了聚类分析,课上同学也分别同R、SPSS、python展示了简单的聚类。但是问题是,理论不够联系实际,具体说,就是我们没有结合具体的业务背景,甚至连数据清洗的环节也直接略过了,这样不够好。一是理论被证明是否可行还需要实践去检验,基于特定业务背景上的模型的选择、数据的抽取、探索、清洗、建模、模型应用等等每个环节都可能遇到各种问题;同时,对于目前我们的情况来说,试着去结合业务背景把整个流程走一遍有助于更深刻地理解其中的原委,包括模型的适用性、模型的解读;更重要的是,不管多么高级的模型算法最后也一定是会落实到实际的业务中去,同时,目前来说,不仅是数据分析师、搞算法的人也需要懂业务,因此在学习过程中注意考虑实际业务背景,对于锻炼业务理解能力至关重要。还有不得不说,真的不喜欢R的代码样式,因此决定暂时不学习R,涉及到统计分析部分我利用了python+SPSS。虽然据说R的图像比较漂亮,但是web可视化的JavaScript工具和tableau估计能完全替代它。
上一篇《客户细分那点事——理论篇》的博客中,我们已经得知,实际的商业中,聚类分析的方法被广泛应用到客户细分中。因此这篇文章想结合具体案例去加深对客户细分、K均值聚类的理解,其中的案例部分参考自《python数据分析与挖掘实战》一本书。《航空公司客户的价值分析》这一案例,相对于传统的RFM模型(点击打开链接查看MBA智库百科的介绍),提出了航空公司的LRFMC模型,具体模型算法部分,利用了sklean中的KMeans算法进行了分析。数据清洗和标准化部分是利用pandas实现的。
1.1 背景与挖掘目标
信息时代的到来使企业营销焦点从产品中心转变为客户中心,客户关系管理成为企业的核心问题。客户关系管理的关键问题是客户分类;通过客户分类,区分无价值客户、高价值的客户,企业针对不同价值的客户制定优化的个性化服务个案,进而采取不同的营销策略,将有限的资源集中最优分配,实现企业的效益最大化。目前,客户分类越来越成为客户关系管理中亟待解决的问题。
首先介绍我们的航空客户数据:
A:客户基本信息(会员卡号、入会时间、第一次飞行时间、性别、会员卡级别、工作地城市、年龄);
B:乘机信息(观测窗口内飞行次数、观测窗口的截止时间、最后一次乘机距离观测窗口借书的时长、平均折扣率、观测窗口的票级收入、观测窗口的总飞行公里数、末次飞行日期、平均乘机时间间隔、最大的乘机间隔);
C:积分信息等。部分数据如下所示,存放在air_data.csv中。

根据我们的业务目标和经验,我们可以利用这些数据实现以下目标:
1)对客户分类
2)对不同的客户类别进行特征分析,比较不同客户的客户价值。
3)对不同的客户类别提供个性化服务,指定相应的营销策略。
1.2分析方法和过程
识别客户价值应用最广的模型是RFM模型(R:Recencyd代表最近消费的时间间隔、F:Frequency代表消费的频率、M:Monetary代表消费的金额。RFM模型是根据这三个指标对客户进行细分)
在RFM模型中,M代表一段时间内,客户芤脉该企业产品金额的总和。但是,由于航空票价收到座位登记、运输价值等多种因素的影响,因此同样的消费金额的不同旅客的客户价值可能是不一样的。因此单单这一个指标不适合我们的分析目标。我们选取一定时间内累计额的飞行里程M和客户一定时间内乘坐仓位所对应的折扣系数的平均值C两个指标达标消费金额。(注意这个过程相当于PCA的反过程,将"数据中的信息"拆分,使综合起来能很好地表达数据中隐藏的信息。)此外,客户入会时间长短也一定程度能后影响客户价值,所以我们的模型中则增加这个标量L,作为区分客户的另一个指标。
总结一下,我们的选取的指标有客户关系长度L、消费时间间隔R、消费频率F、飞行里程M和折扣系数的平均值C,五个指标来识别客户价值,我们记为LRF(MC)模型。
分析过程:
1)数据抽取/数据获取,比如我们可以从数据库中抽取内部数据,也可以用爬虫自己抓取数据自己做个报告。
注意,如果没有业务背景,因为你没有业务压力,你自己想写一份报告,这个时候第一个步骤即分析目标往往很难确定;分析目标这一步在工作中通常是由你的客户/上级/其他部门同事/合作方提出来的;但是我们自己写报告,在选择目标时应该注意以下几点:
1)选择一个你比较熟悉,或者比较感兴趣的领域/行业;
2)选择一个范围比较小的细分领域/细分行业作为切入点;
3)确定这个领域/行业有公开发表的数据/可以获取的UGC内容(论坛帖子,用户点评等)。
逐一分析上面三个注意点:选择熟悉/感兴趣的领域/行业,是为了保证你在后续的分析过程中能够真正触及事情的本质——这一过程通常称为洞察——而不是就数字论数字;选择细分领域/行业作为切入点,是为了保证你的报告能够有一条清晰的主线,而非单纯堆砌数据;确定公开数据/UGC内容,是为了保证你有数据可以分析,可以做成报告,你说你是个军迷,要分析一下美国在伊拉克的军事行动与基地组织恐怖活动之间的关系……找到了数据麻烦告诉我一声,我叫你一声大神……不管用什么方法,你现在有了一个目标,那么就向下个阶段迈进吧。
我们抽取的数据就是如上边的截图所示,观测开始时间为2012.4.1,截止时间为2014.3.31
2)数据预处理(可能包含以下部分:数据探索、数据清洗、属性规约、数据变换;数据探索一般有两个目的:第一是描述性统计分析,可以作为报告的一部分;另外是检查缺失值和异常值为数据清洗作准备。数据清洗:对上一步发现的异常值和缺失值的处理;属性规约:删除不相关、弱相关或是冗余的属性;数据变换:可以包括分析变量的生产、构造,数据的规范化、连续属性的离散化等)。不管你经历了几步的预处理,每一步你怎么称呼,总之,根本目标就是为分析建模提供合适的数据。【顺便做下标记,python是数据预处理的好工具,比如pandas库中的isnull、notnull、unique函数可以帮助我们做数据清洗;Scipy库总的interpolate函数可以对一维、高维数据进行插值;Scikit-learn库可以提供PCA方法对指标变量进行主成分分析的降维】
先看看我们的数据(“数据探索”):
本案例中的探索分析是对缺失值和异常值的分析,分析出数据的规律和异常值。python的代码如下,我们擦看了每列属性的空值个数、最大值、最小值:
1 #-*- coding: utf-8 -*- 2 #对数据进行基本的探索 3 #返回缺失值个数以及最大最小值 4 5 import pandas as pd 6 7 datafile= '../data/air_data.csv' #航空原始数据,第一行为属性标签 8 resultfile = '../tmp/explore.xls' #数据探索结果表 9 10 data = pd.read_csv(datafile, encoding = 'utf-8') #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码) 11 12 explore = data.describe(percentiles = [], include = 'all').T #包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等);T是转置,转置后更方便查阅 13 explore['null'] = len(data)-explore['count'] #describe()函数自动计算非空值数,需要手动计算空值数 14 15 explore = explore[['null', 'max', 'min']] 16 explore.columns = [u'空值数', u'最大值', u'最小值'] #表头重命名 17 '''这里只选取部分探索结果。 18 describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)''' 19 20 explore.to_excel(resultfile) #导出结果
结果我们保存在了excel中,我们简单查看一下:
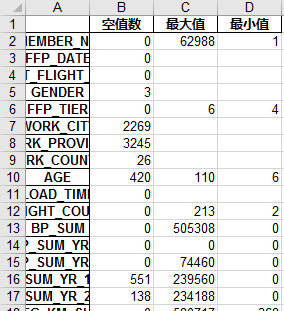
接下来是数据的清洗,代码如下:
1 #-*- coding: utf-8 -*- 2 #数据清洗,过滤掉不符合规则的数据 3 4 import pandas as pd 5 6 datafile= '../data/air_data.csv' #航空原始数据,第一行为属性标签 7 cleanedfile = '../tmp/data_cleaned.csv' #数据清洗后保存的文件 8 9 data = pd.read_csv(datafile,encoding='utf-8') #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码) 10 11 data = data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] #票价非空值才保留 12 13 #只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。 14 index1 = data['SUM_YR_1'] != 0 15 index2 = data['SUM_YR_2'] != 0 16 index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) #该规则是“与” 17 data = data[index1 | index2 | index3] #该规则是“或” 18 19 data.to_excel(cleanedfile) #导出结果
接下来是数据的变换:因为我们没有表示入会时间的字段L,距离观测窗口结束的月数,所以我们需要增加个计算字段;同时我们发现5个指标的取值范围差异较大,为了消除数量级差异带来的影响,我们需要对数据进行标准化处理,代码如下:
1 #-*- coding: utf-8 -*- 2 #标准差标准化 3 4 import pandas as pd 5 6 datafile = '../data/zscoredata.xls' #需要进行标准化的数据文件; 7 zscoredfile = '../tmp/zscoreddata.xls' #标准差化后的数据存储路径文件; 8 9 #标准化处理 10 data = pd.read_excel(datafile) 11 data = (data - data.mean(axis = 0))/(data.std(axis = 0)) #简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。 12 data.columns=['Z'+i for i in data.columns] #表头重命名。 13 14 data.to_excel(zscoredfile, index = False) #数据写入
3)模型的构建
模型的构建包括两个部分,第一部分是根据标准号的5个指标数据,对客户进行聚类分群;第二部分是结合业务对每个客户群进行特征分析没分析其客户价值。
先是,客户聚类,这一部分我们分别用SPSS和sklearn-cluster实现:
先是SPSS的结果:
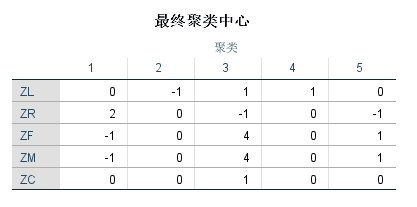
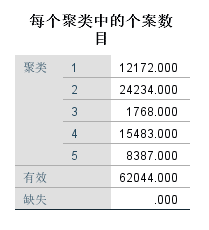
客户价值分析:
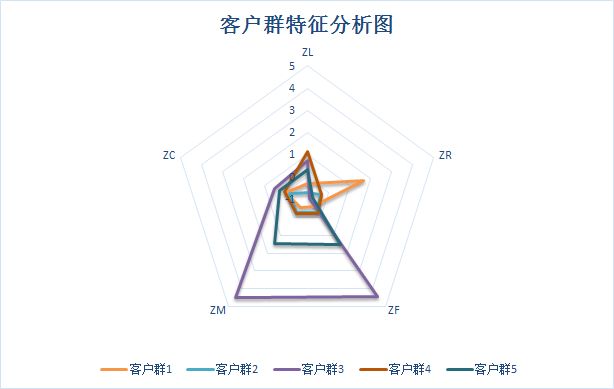
注意:不同重复试验得到的结果可能不同
针对聚类结果进行特征分析,如上图所示。其中,客户群1在R属性上最大,在F、M属性上最小;客户群2在L、C属性上最小;客户群3在F、M属性上最大;客户群4在L属性上最大;客户群5在F、M属性最大,R属性最小,但是和客户群3有区别,客户群3中F、M的优势更明显;

- 重要保持客户:客户群3,这一类客户,相对其他客户群,平均折扣率C是较高的(一般所乘航班的行位等级较高),乘坐的次数F和里程M较大,最近乘坐过本公司的航班R相对自己的其他属性较低。他们是航空公司的高价值客户,是最理想的客户类型,对航空公司的贡献最大,所占比例最低为0.028。航空公司应该优先把资源投放到这类客户上,对他们进行差异化管理和一对一的营销,提高这类客户的忠诚度和满意度,尽可能延长这类客户的高水平消费。
- 重要发展客户:客户群5,这一类客户的平均折扣率C较高,最近乘坐本公司航班R较低,
- 重要挽留客户:客户群4,这类客户入会时间较长,过去所乘航班的平均折扣率、次数、里程数都比较高。但是R很高,即很长时间已经没有乘坐本公司航班了或是乘坐频率降低。他们的客户价值变化的不确定性很高。建议:由于这类客户的衰退的原因各不相同,所以掌握客户的最新信息、维持与客户的互动就显得尤其重要。应该准对客户的最近消费时间、消费次数的变化,推测客户消费的异常状况,并列出客户名单,对其重点联系,采取一定的营销手段,延长客户的生命周期。
- 一般与低价值客户:这类客户所乘坐航班的平均折扣率很低,较长时间么有乘坐,次数和里程数较低,入会时间较短。他们是公司的一般客户与较低价值客户,可能是在航空公司打折促销的时候,才会乘坐。
但是,我用sklearn-cluster做的聚类分析,分析结果和客户去特征分析图如下,和SPSS中的结果还是有点不同的,事实上,sklearn的效果更好,类别分的更开,文后会探讨这种差异的原因:

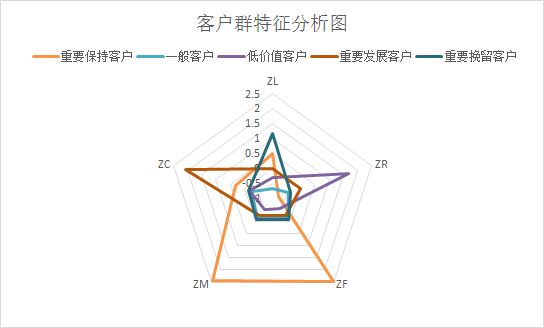
- 重要保持客户:这一类客户,相对其他客户群,平均折扣率C是较高的(一般所乘航班的行位等级较高),乘坐的次数F和里程M较大,最近乘坐过本公司的航班R相对自己的其他属性较低。他们是航空公司的高价值客户,是最理想的客户类型,对航空公司的贡献最大,所占比例最低为0.086。航空公司应该优先把资源投放到这类客户上,对他们进行差异化管理和一对一的营销,提高这类客户的忠诚度和满意度,尽可能延长这类客户的高水平消费。
- 重要发展客户:这一类客户的平均折扣率C较高,最近乘坐本公司航班R较低,但乘坐次数和乘坐里程数较低。这类客户入会时间也不久,他们是航空公司的潜在客户。虽然这类客户的当前价值并不高,但却有很大的发展潜力。航空公司要努力促使这类客户增加本公司的乘机消费和合作伙伴处消费,也就是增加客户的钱包份额。通过客户价值的提升,加强这类客户的满意度,提高他们转向竞争对手的转移成本,使他们逐渐成为公司的忠实客户。
- 重要挽留客户:这类客户入会时间较长,过去所乘航班的平均折扣率、次数、里程数都比较高。但是R很高,即很长时间已经没有乘坐本公司航班了或是乘坐频率降低。他们的客户价值变化的不确定性很高。建议:由于这类客户的衰退的原因各不相同,所以掌握客户的最新信息、维持与客户的互动就显得尤其重要。应该准对客户的最近消费时间、消费次数的变化,推测客户消费的异常状况,并列出客户名单,对其重点联系,采取一定的营销手段,延长客户的生命周期。
- 一般与低价值客户:这类客户所乘坐航班的平均折扣率很低,较长时间么有乘坐,次数和里程数较低,入会时间较短。他们是公司的一般客户与较低价值客户,可能是在航空公司打折促销的时候,才会乘坐。
注意,我们的模型采取的是历史数据,随着客户信息的更新,同时考虑业务的实际情况,建议模型定期运行一次,包括对聚类中心、客户特征进行新的分析;如果情况变化较大,业务部门需要重点关注。
4)模型的应用
根据各个客户群的特征分析,航空公司可以采取以下的营销手段和策略。
(1)会员的升级与保级
(2)首次兑换
(3)交叉销售
附录:
1、关于SPSS和Sklearn—cluster结果差异:
结果差异只能和迭代次数、初始中心的选择算法有关、K值有关;python和SPSS中K值我选的都是5,同时迭代次数也足够多。我试着再SPSS中多次运行,观测初始中心的变化,发现每次初始中心都是一样的,同时通过查资料,了解到SPSS中初始中心的选择某种程度不具有随机性。因此我觉得结果的差异和这个有关系。而sklearn中的聚类算法显然更“高级”的多,以下为kmeans的参数部分。
n_clusters : int, optional, default: 8
The number of clusters to form as well as the number of centroids to generate.
max_iter : int, default: 300
Maximum number of iterations of the k-means algorithm for a single run.
n_init : int, default: 10
Number of time the k-means algorithm will be run with different centroid seeds. The final results will be the best output of n_init consecutive runs in terms of inertia.
init : {‘k-means++’, ‘random’ or an ndarray}
Method for initialization, defaults to ‘k-means++’:
‘k-means++’ : selects initial cluster centers for k-mean clustering in a smart way to speed up convergence. See section Notes in k_init for more details.
‘random’: choose k observations (rows) at random from data for the initial centroids.
If an ndarray is passed, it should be of shape (n_clusters, n_features) and gives the initial centers.
algorithm : “auto”, “full” or “elkan”, default=”auto”
K-means algorithm to use. The classical EM-style algorithm is “full”. The “elkan” variation is more efficient by using the triangle inequality, but currently doesn’t support sparse data. “auto” chooses “elkan” for dense data and “full” for sparse data.
2、kmeans算法初始聚类中心的选择
http://blog.sina.com.cn/s/blog_7103b28a0102w81n.html
http://www.dataguru.cn/thread-449411-1-1.html