ARM架构
一、ARM体系结构
1、ARM相关的概念
1. 机器码:编译器将汇编指令编译生成具有特定功能的机器码(二进制数010101的集合),
执行机器码可以完成某个特定的功能。
2. 汇编指令:执行汇编指令可以完成某个特定的功能(指令是硬件,加法运算器等,由三极管mos管组装而成)。
3. 汇编指令集:很多不同功能的汇编指令的集合。汇编指令的可移植性比较差
4. 架构:汇编指令集的版本的命名
ARM架构 X86-64架构 Mips架构 PowerPC架构 Risc-V架构 loongarch架构
ARM架构的版本:
ARM-v1 ~ ARM-v6 : 目前已经淘汰
ARM-v7:32位的架构,支持32位的ARM指令集
ARM-v8:64位的架构,支持64位的ARM指令集,向下兼容ARM-v7架构
ARM-v9: 2021年发布的新的一代ARM架构,目前ARM高端处理器基本使用的都是
ARM-v9架构
5. ARM内核:ARM公司基于不同的ARM架构,设计出不同性能的ARM内核。
ARM内核的命名方式:
Cortex-A53/A55/A72/A76/A78/A710/A510 : 主要用于高端处理器中
Cortex-x1/x2/x3 : 主要用于高端处理器中
Cortex-M0/M1/M3/M7 : 主要用于单片机中,低端的处理器
cortex-R系列:主要针对于对实时性要求比较高的场合
6. SOC : System On Chip:片上系统
一款处理器,在内核的基础之上,有添加了很多不同的外设资源,
这样的处理器可以统称为SOC.
SOC : 片上系统, 可以是单片机,可以是高端处理器
CPU : 中央处理单元, 可以是单片机,可以是高端处理器
MCU : 微控制单元, 主要指的单片机
MPU : 微处理单元,主要指高端处理器
GPU : Graph Process Unit,图形处理单元
VPU : Video Processing Unit,视频处理单元2、RISC和CISC的区别
2.1RISC指令集
RISC : 精简指令集
ARM架构,RISC-v架构,Mips架构,PowerPC架构,都属于精简指令集的架构
精简指令集特点:指令相对比较简单,比较容易理解
指令的周期和指令的宽度固定。
指令周期:执行一条汇编指令需要的时钟周期的个数。
CPU的主频,CPU的频率的倒数为周期
比如:CPU主频为2GHz,
一个周期的时间为 = 1 / 2G (单位s)
指令宽度:指令被编译生成机器码,1条汇编指令占用代码段的空间,
32位处理器或者64位处理器,指令的宽度为4字节。

2.2 CISC指令集
CISC : 复杂指令集
X86, X86-64, 属于复杂指令集的架构
复杂指令集的特点:复杂指令集更加注重指令的功能性,
指令的周期和指令的宽度不固定。
3、ARM架构数据类型的约定
3.1 ARM-v7架构数据类型的约定
byte ---> 字节 ---> 8bits ---> 1字节
half word ---> 半字 ---> 16bits ---> 2字节
word ---> 字 ---> 32bits ---> 4字节
double word ---> 双字 ---> 64bits ---> 8字节3.2 ARM-v8架构数据类型的约定
byte ---> 字节 ---> 8bits ---> 1字节
half word ---> 半字 ---> 16bits ---> 2字节
word ---> 字 ---> 32bits ---> 4字节
double word ---> 双字 ---> 64bits ---> 8字节
quad word ---> 四字 ---> 128bits ---> 16字节4、ARM内核处理器的工作模式
4.1 Cortex-M核处理器的工作模式
线程模式:执行的用户代码,主要是主函数中的代码
异常模式:执行的是异常处理程序,中断,复位,硬件错误4.2 Cortex-A核处理器的工作模式
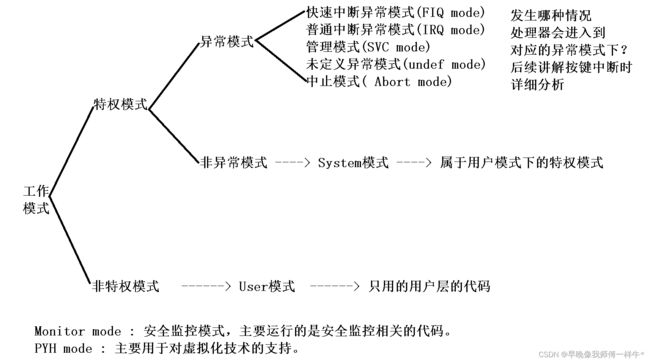
不同的工作模式下,执行不同的代码,最终完成不同的功能。
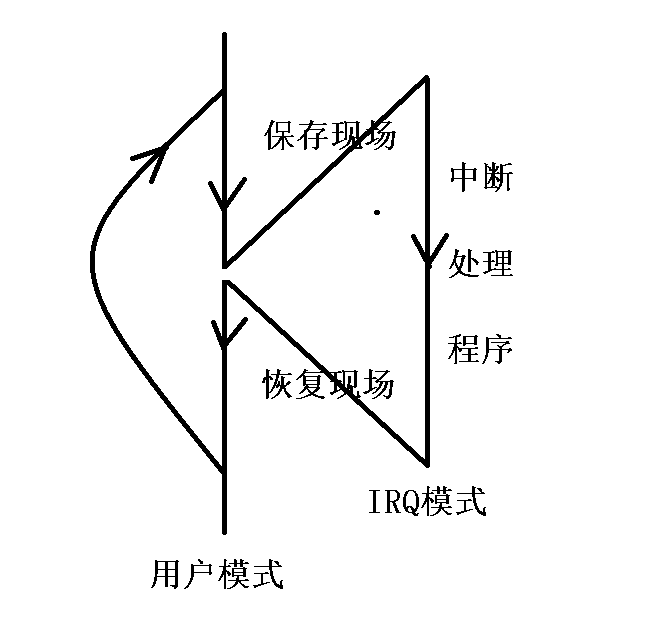
5、ARM寄存器的组织(重点!重点!重点!)
5.1 寄存器的介绍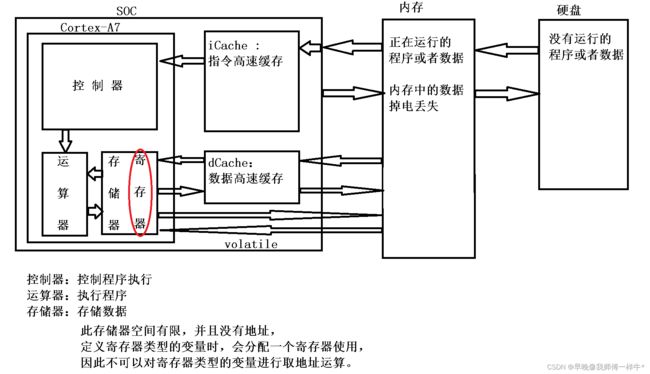

5.2 寄存器组织 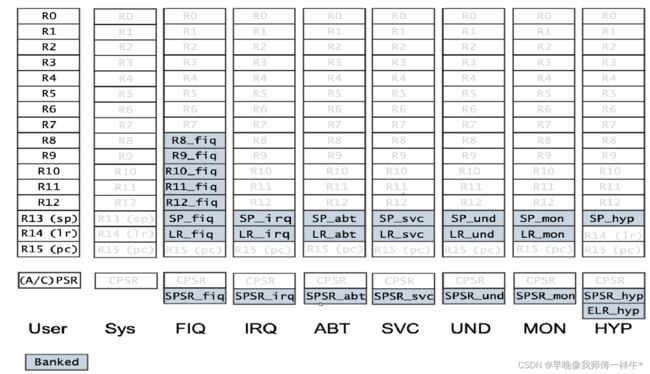
灰色表示不存在
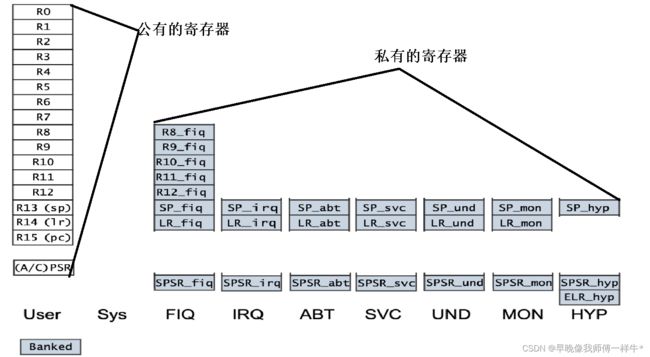
1. 每个小方块是一个寄存器,32位处理器,每个寄存器都是32位的。
2. 寄存器是没有地址的,通过寄存器的编号进行访问,R0-R15,cpsr,spsr
寄存器为什么没有地址?
add r0, r1, r2
|
编译生成32位的机器码
|
32位机器码中需要存储
add的信息,r0,r1,r2(如果用地址的话,地址就占32位,r0,r1,r2每个寄存器都有32个地址,32位的
机器码存不下,溢出了,所以不用地址指向寄存器)
的信息。
add被编译生成4位机器码
r0,r1,r2也会被编译生成4位机器码
3. 每种工作模式下,只能访问自己对应模式下的寄存器,不可以访问其他模式下的
User和Sys模式下,最多可以访问17个寄存器;
FIQ/IRQ/SVC/ABT/UND/MON模式下,最多可以访问18个寄存器;
HYP模式下,最多可以访问19个寄存器。
4. Banked类型的寄存器表示私有的寄存器;
非Banked类型的寄存器表示公有的寄存器。
5. 如果工作模式下自己有的就访问自己的,没有就访问共有的
6. User模式和Sys模式共用同一套寄存器组织。6、特殊的寄存器
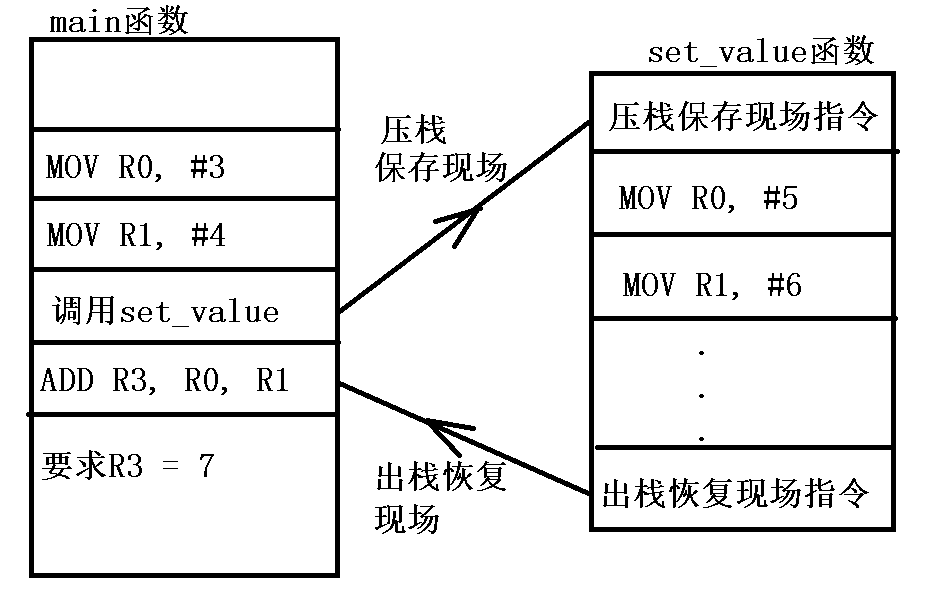
6.1 SP寄存器
R13 ---> 别名:sp ---> the Stack Pointer
作用:SP寄存器中存储的是执行栈空间的地址。
栈空间主要用于压栈保存现场,出栈恢复现场。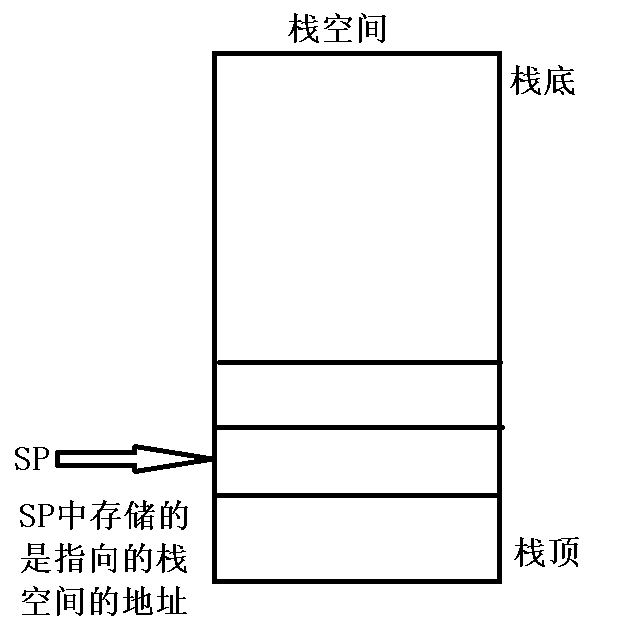
6.2 LR寄存器

6.3 PC寄存器
R15 ---> 别名:PC ---> The Program Counter : 程序计数寄存器
作用:PC寄存器中存储的是当前取指指令的地址,
每完成取指操作之后,PC会自动加4指向下一条指令。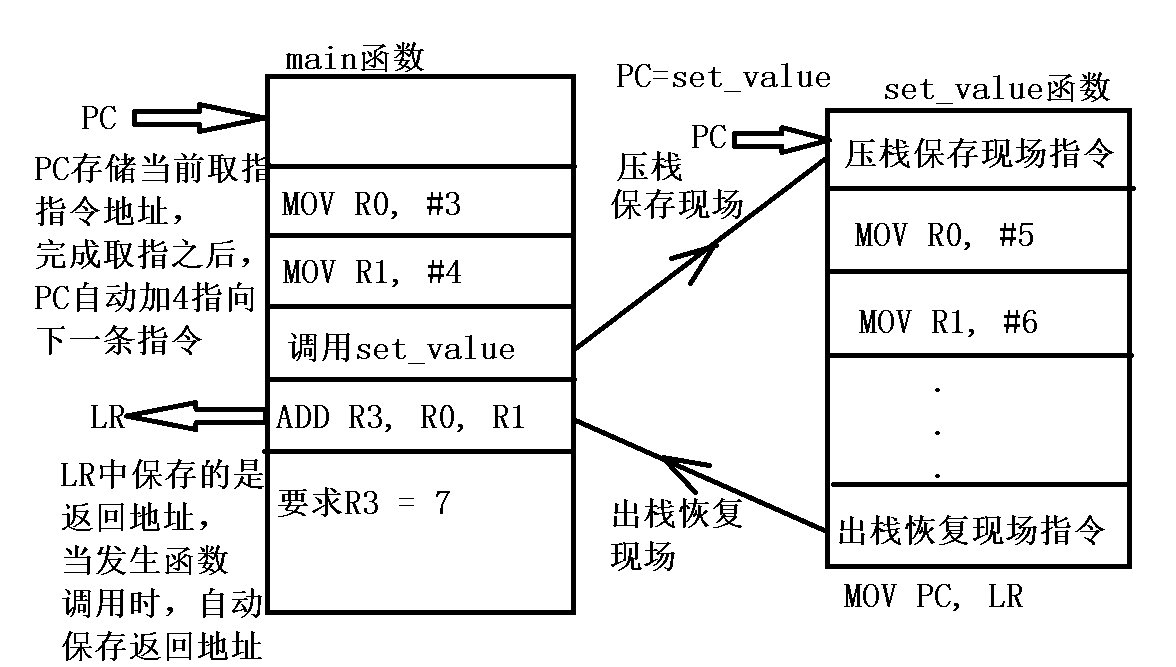
6.4 CPSR 寄存器
CPSR : Current Program Statu Register : 当前程序状态寄存器
CPSR寄存器中存储的是当前处理器的运行的状态,比如:工作模式
所有的工作模式共用一个CPSR寄存器6.5 SPSR 寄存器
SPSR : Save program Statu Register : 保存程序状态寄存器
SPSR寄存器主要用于对CPSR寄存器进行备份的。
每种异常模式下都有一个私有的SPSR寄存器。
7、CPSR寄存器的详解

N[31] : 指令的运算结果为负数时,
N位被自动置1,否则为0.
Z[30] :指令的运算结果为零时,
Z位被自动置1,否则为0.
C[29] :
加法:低32位向高32位进位时,C位被自动置1,否则为0.
32位的处理器的寄存器为32位的,1条汇编指令本身就可以完成
32位以内数据的运算,如果数据超过32位之后,就需要考虑进位。
减法:低32位向高32位借位,C位被自动清0,否则为1.
V[28] :符号位发生变化,V位被自动置1,否则为0.
I[7] :IRQ屏蔽位
I = 1:屏蔽IRQ类型的中断
I = 0:不屏蔽IRQ类型的中断
F[6] :FIQ屏蔽位
F = 1:屏蔽FIQ类型的中断
F = 0:不屏蔽FIQ类型的中断
T[5] :状态位
T = 0 : ARM状态, 执行ARM汇编指令集
一条ARM汇编指令占4字节的代码段的空间
T = 1 : thumb状态,执行Thumb汇编指令集
一条Thumb汇编指令占2字节的代码段的空间。
M[4:0] :模式位
10000 User mode;
10001 FIQ mode;
10011 SVC mode;
10111 Abort mode;
11011 Undfined mode;
11111 System mode;
10110 Monitor mode;
10010 IRQ mode.8、汇编指令流水线
为了提高指令的执行的效率,指令的执行采用流水线的方式。
三级流水线
五级流水线
七级流水线
八级流水线
十三级流水线
重点理解三级流水线:
取指器:根据PC寄存器的指令的地址,从代码段取出指令对应的机器码。
译码器:翻译指令对应的机器码,将指令最终交给对应的执行器。
执行器:执行汇编指令,完成一个特定的功能,并将指令的执行结果写到寄存器中。
以上三个器件都是相互独立的器件,工作互不干扰,都属于单周期的器件。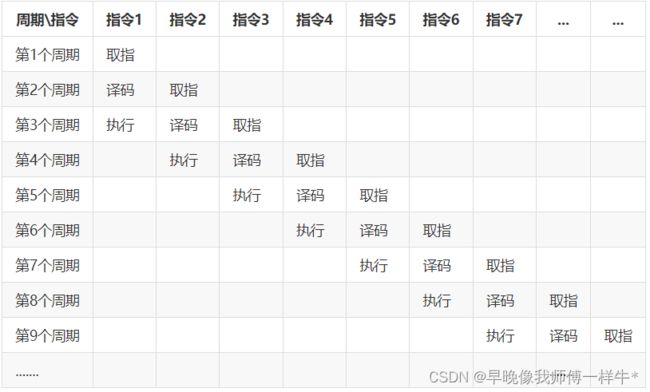
执行1条汇编指令大概需要1个时钟周期:9 / 7 = 1
以上指令的指令是理想状态下的指令的流水线,
函数的调用,异常的处理会打断理想状态下的指令的流水线。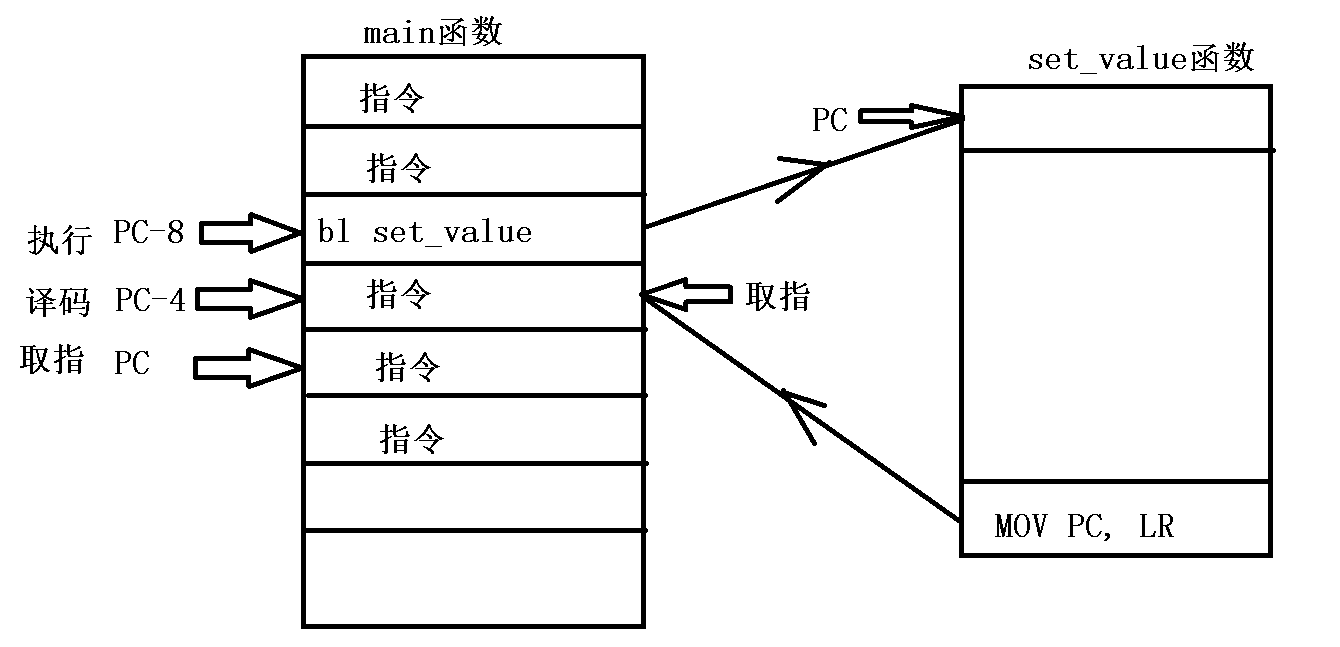
9、汇编指令流水线
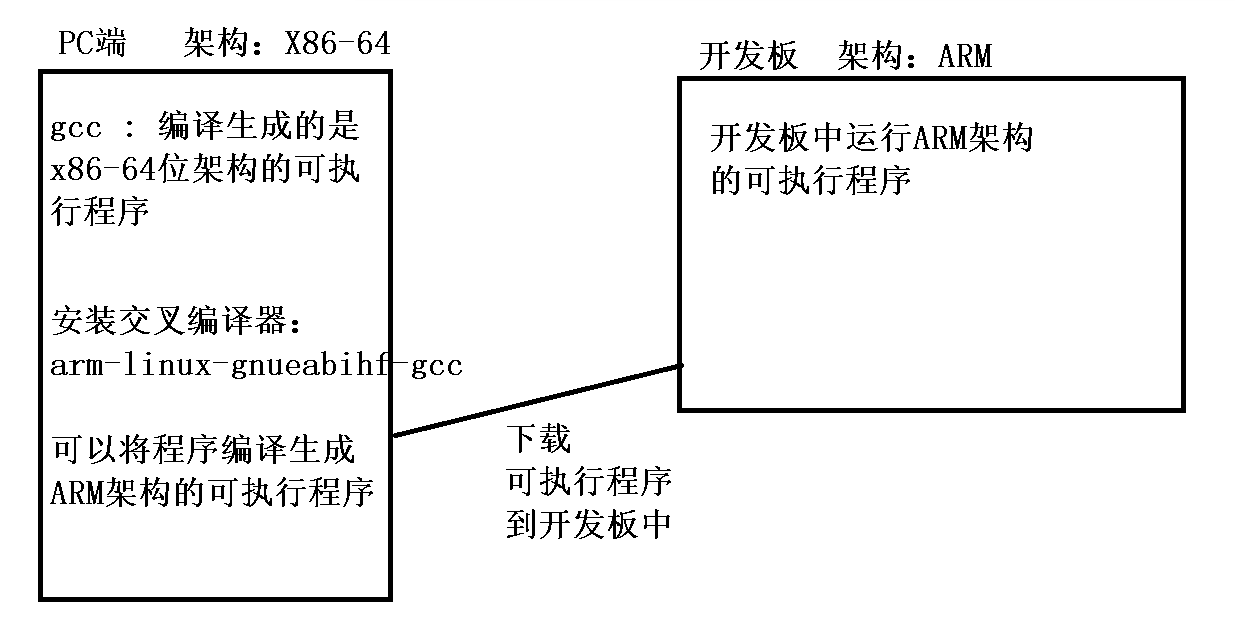
9.1 本地开发和交叉开发
本地开发 : PC端编写代码,PC端编译代码,PC端运行代码
交叉开发 : PC端编写代码,PC端编译代码,目标板运行代码
单片机开发就属于交叉开发:
Keil工具编写代码,编译代码 ---> 烧录到开发板中运行程序
linux驱动开发板属于交叉开发:
ubuntu中编写代码,编译代码 ---> 烧录到开发板中运行程序
PC : X86-64架构 ---> gcc编译器 ---> 编译生成x86-64架构的可执行程序
开发板 :arm架构 ---> 交叉编译器 ---> 编译生成ARM架构的可执行程序
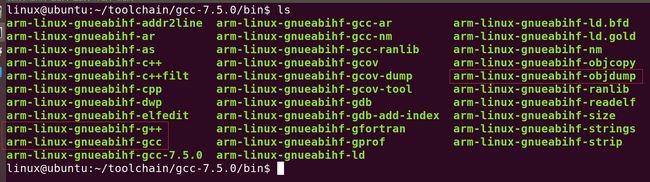
9.2 ubuntu开发环境的搭建-》安装ARM交叉编译器
1> 在ubuntu的家目录下创建一个toolchain目录
cd ~
mkdir toolchain
2> 拷贝交叉编译工具链的压缩包到toolchain目录下

cd ~/toolchains
cp 拷贝交叉编译器到toolchains目录下 ./
3> 对交叉编译器的压缩包进行解压缩
tar -vxf gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf.tar
解压缩成功之后会得到gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf目录
将交叉编译器的目录简化:
mv gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf gcc-7.5.0
交叉编译器在~/toolchain/gcc-7.5.0/bin目录下。
切记:不要在windows下进行解压缩,不支持软链接文件。
4> 配置PATH系统环境变量,将交叉编译器的路径添加到PATH环境变量中
/etc/profile
/etc/environment
/etc/bash.bashrc -----> 对所有的用户有效
~/.bashrc -----> 只对当前用户有效
本次配置使用sudo vi /etc/bash.bashrc文件,打开此文件在最后一行添加以下内容:
export PATH=$PATH:/home/linux/toolchain/gcc-7.5.0/bin
|-----> 修改为自己的交叉编译器所在的路径
5> 使环境变量立即生效
source /etc/bash.bashrc
6> 测试交叉编译器是否安装成功
arm-linux-gnueabihf-gcc -v
arm-l(tab键)
出现以下提示信息表示安装成功:
gcc version 7.5.0 (Linaro GCC 7.5-2019.12)二、ARM汇编指令
1.汇编工程文件的介绍
1.1 start.s文件介绍
.text @ 伪操作,不占用代码段的空间,给编译器使用
@ 告诉编译器,.text后边的内容为代码
.globl _start @ 伪操作 将_start声明为全局的函数
@ 可以被外部的文件使用
_start: @ 标签,类似于C语言的函数名,表示汇编函数的入口
@ 及标签可以表示标签下的第一条汇编指令的地址
mov r0, #0xFF @ 汇编指令 编译器可以将其编译生成32位的机器码
@ 执行汇编指令的机器码可以完成特定的功能
@ mov是一个赋值的汇编指令
@ R0 = 0xFF
stop: @ 标签
b stop @ 跳转指令,跳转到stop标签下的第一条指令
@ 等价于while(1){}死循环
/*
在裸机开发中,必须在主函数中编译一个while(1){}
死循环,否则程序会跑飞,执行的结果不可预知。
在while(1){}死循环中轮询的处理各种事件。
*/
.end @ 伪操作,代码段结束1.2 map.lds文件的介绍
/*
map.lds : 链接脚本文件,给编译器使用,
编译器解析链接脚本文件,最终决定对代码的配置和链接。
*/
/* 输出格式 : ELF格式 32位 小端对齐 ARM架构可执行程序 */
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
/*OUTPUT_FORMAT("elf32-arm", "elf32-arm", "elf32-arm")*/
/* 输出架构 (ARM架构)*/
OUTPUT_ARCH(arm)
/* 程序的入口 */
ENTRY(_start)
SECTIONS /* 段 */
{
. = 0x00000000; /* 代码的入口地址 */
. = ALIGN(4); /* 对齐 */
.text : /* 代码段 */
{
./Objects/start.o(.text) /* start.o文件必须放到代码段最开始的位置,start.s生成start.o*/
*(.text) /* 其他的.o文件 编译器看着排布 */
}
. = ALIGN(4);
.rodata : /* 只读数据段 */
{
*(.rodata) /* 常量 只读数据*/
}
. = ALIGN(4);
.data : /* 数据段 */
{
*(.data) /* 初始化的全局变量,或者使用static修饰的初始化的变量 */
}
. = ALIGN(4);
__bss_start = .;
.bss : /* bss段 */
{
*(.bss) /* 未初始化的全局变量,或者使用static修饰的未初始化的变量 */
}
__bss_end__ = .;
}2.汇编文件中的符号
1. 伪操作:伪操作不占用代码段的空间,给编译器使用,
比如.text .global .globl .end .data .if .else .endif ....
注:编译器不同,汇编文件中的伪操作书写方式不同。
2. 汇编指令:编译器可以将汇编指令编译生成机器码,执行汇编指令可以完成特定的功能。
比如:mov r0, #0xFF ===> r0 = 0xFF
3. 伪指令:伪指令本身不是一条汇编指令,编译器可以将伪指令编译生成多条汇编指令,
共同完成一条伪指令的功能。
4. 注释:
单行注释:@
多行注释:/**/
.if 0/1
.else
.endif
注:编译器不同,汇编文件中的单行注释方式不同。3.汇编指令的分类
1. 数据操作指令
1> 数据搬移指令
2> 移位操作指令
3> 算数运算指令
4> 位运算指令
5> 比较指令
2. 跳转指令
3. Load/Store内存读写指令
1> 单寄存器操作指令
2> 多寄存器操作指令
3> 栈操作指令
4. 特殊功能寄存器操作指令
5. 软中断指令4.汇编指令的基本的语法格式
{cond}{S} Rd, Rn, shifter_oprand
解释:
:指令码(指令名字), 比如:mov,add,sub....
{cond} :条件码, 实现汇编指令的有条件的执行,后续讲解比较指令时详细解释。
{S} :状态位, 加S,指令的执行结果影响CPSR的NZCV位,
不加S,指令的执行结果不影响CPSR的NZCV位。
Rd :目标寄存器,存放指令的执行的结果
Rn :第一个操作寄存器,只能是一个普通的寄存器,
等价于运算符的左操作数
shifter_oprand:第二个操作数, 等价于运算符的右操作数
1> 可以是一个普通的寄存器
2> 可以是一个立即数
3> 可以是一个移位操作的寄存器
{cond}{S}:这三部分书写时,连到一起写即可。
Rd, Rn, shifter_oprand:这三部分书写时,使用英文逗号隔开
和Rd之间使用空格隔开
一条汇编指令单独占一行,汇编文件中不严格区分大小写: 5.数据操作指令
5.1 移位操作指令
5.1.1 指令码
mov : 直接赋值
mvn :按位取反之后再进行赋值操作
5.1.2 指令格式
mov{cond}{S} Rd, shifter_oprand @ Rd = shifter_oprand
mvn{cond}{S} Rd, shifter_oprand @ Rd = ~shifter_oprand
数据搬移指令没有第一个操作寄存器
5.1.3 指令测试代码
/*1. 数据搬移指令 */
@ 第二个操作数为一个立即数,立即数前需要加#
mov r0, #0xFF @ 功能:R0 = 0xFF
@ 第二个操作数为一个普通的寄存器
mov r1, r0 @ 功能:R1 = R0
mvn r2, #0xFF @ 功能:r2 = ~0xFF = 0xFFFFFF00
5.1.4 立即数的概念
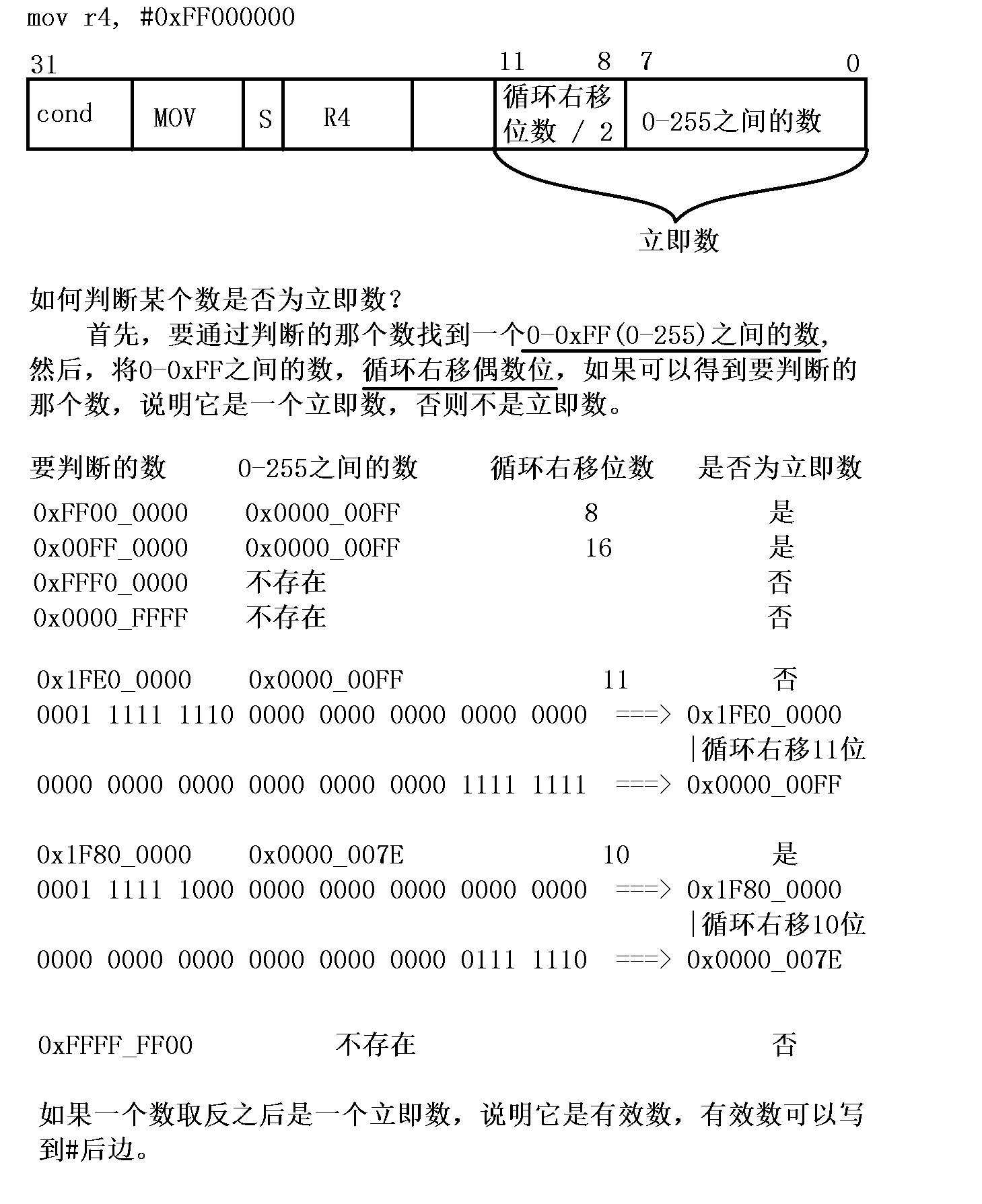
mov r0, #0xFF
@ mov r1, #0xFFF
@ mov r2, #0xFFFF
mov r3, #0x00FFFFFF
mov r4, #0xFF000000
mov r4, #0x00FF0000
mov r5, #0x1F800000
立即数的概念不需要记忆,不同的汇编指令,立即数占用的位数也是不同的。
5.1.5 ldr伪指令
格式:
ldr Rd, =number @ Rd = number
ldr r0, =0x123456785.2 移位操作指令
5.2.1 指令码
lsl : 逻辑左移/无符号数左移
lsr : 逻辑右移/无符号数右移
asr : 算数右移/有符号数右移
ror : 循环右移
5.2.2 指令格式
{cond}{S} Rd, Rn, shifter_oprand
5.2.3 指令测试代码
/* 2. 移位操作指令 */
mov r0, #0xFF
@ 逻辑左移:高位移出,低位补0
lsl r1, r0, #4 @ r1 = r0 << 4 = 0xFF0
@ 逻辑右移:低位移出,高位补0
lsr r2, r0, #4 @ r2 = r0 >> 4 = 0xF
@ 算数右移:低位移出,高位补符号位
asr r3, r0, #4 @ r3 = r0 >> 4 = 0xF
@ 循环右移:低位移出,补到高位
ror r4, r0, #4 @ r4 = r0 >> 4 = 0xF000000F
@
mov r0, #-1 @ r0 = 0xFFFFFFFF
@ 算数右移:低位移出,高位补符号位
asr r5, r0, #4
@ 第二个操作数是一个经过移位的寄存器
mov r0, #0xFF
mov r1, r0, lsl #4 @ r1 = r0 << 4 = 0xFF0
5.3 位运算指令(重要!重要!重要!)
5.3.1 指令码
and : 按位与运算(&)
orr : 按位或运算(|)
eor : 按位异或运算(^)
bic : 按位清除运算
与0清0,与1不变
或1置1,或0不变
异或1取反,异或0不变
| 左操作数 | 运算符 | 右操作数 | 结果 |
|---|---|---|---|
| 0 | & | 0 | 0 |
| 1 | & | 0 | 0 |
| 0 | & | 1 | 0 |
| 1 | & | 1 | 1 |
| 左操作数 | 运算符 | 右操作数 | 结果 |
|---|---|---|---|
| 0 | | | 0 | 0 |
| 1 | | | 0 | 1 |
| 0 | | | 1 | 1 |
| 1 | | | 1 | 1 |
| 左操作数 | 运算符 | 右操作数 | 结果 |
|---|---|---|---|
| 0 | ^ | 0 | 0 |
| 1 | ^ | 0 | 1 |
| 0 | ^ | 1 | 1 |
| 1 | ^ | 1 | 0 |
5.3.2 指令格式
{cond}{S} Rd, Rn, shifter_oprand
5.3.3 指令测试代码
/* 3. 位运算指令 */
@ 假设R0寄存器有一个默认值,对R0寄存器的某些位进行操作
ldr r0, =0x12345678
@31 0
@ **** **** **** **** **** **** **** ****
@ 1> 将R0寄存器中的值的第[3]位清0,保持其他位不变
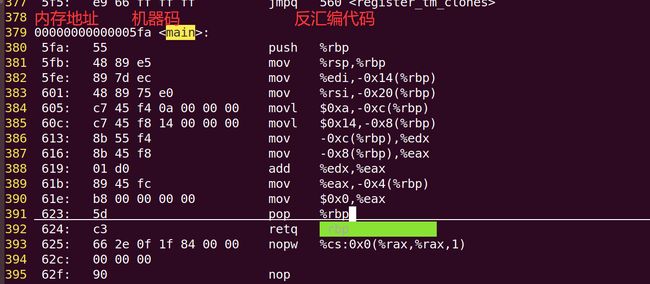
@ r0 = r0 & 0xFFFFFFF7; <===> r0 = r0 & (~(0x1 << 3));
and r0, r0, #0xFFFFFFF7 @ <==> and r0, r0, #(~(0x1 << 3))
@ 2> 将r0寄存器中的值的第[29]位置1,保持其他位不变
orr r0, r0, #(0x1 << 29)
@ 3> 将R0寄存器中的值的第[7:4]位清0,保持其他位不变
and r0, r0, #(~(0xF << 4))
@ 4> 将R0寄存器中的值的第[15:8]位置1,保持其他位不变
orr r0, r0, #(0xFF << 8)
@ 5> 将R0寄存器中的值的第[3:0]位按位取反,保持其他位不变
eor r0, r0, #(0xF << 0)
@ 6> 将R0寄存器中的值的第[11:4]位修改为10101011,保持其他位不变
@ 6.1> 先整体清0
and r0, r0, #(~(0xFF << 4))
@ 6.2> 再将对应的位置1
orr r0, r0, #(0xAB << 4)
@ 6.1> 先整体置1
orr r0, r0, #(0xFF << 4)
@ 6.2> 再将对应的位清0
@ 10101011 ===》 01010100
and r0, r0, #(~(0x54 << 4))
@ bic 指令: 按位清0的指令
@ 第二个操作数的哪位为1,就将第一个操作寄存器中的数据的哪位清0,
@ 然后将结果写回到目标寄存器中
bic r0, r0, #0xFF @ <==> and r0, r0, #(~0xFF)
5.4 算数运算指令
5.4.1 指令码
add :普通的加法指令,不需要考虑进位标志位(C位)
adc :带进位的加法指令, 需要考虑进位标志位(C位)
sub :普通的减法指令,不需要考虑借位标志位(C位)
sbc :带借位的减法指令,需要考虑借位标志位(C位)
mul : 乘法指令
div :除法指令, ARM-v8之后的架构才支持除法指令
5.4.2 指令格式
{cond}{S} Rd, Rn, shifter_oprand
5.4.3 指令测试代码
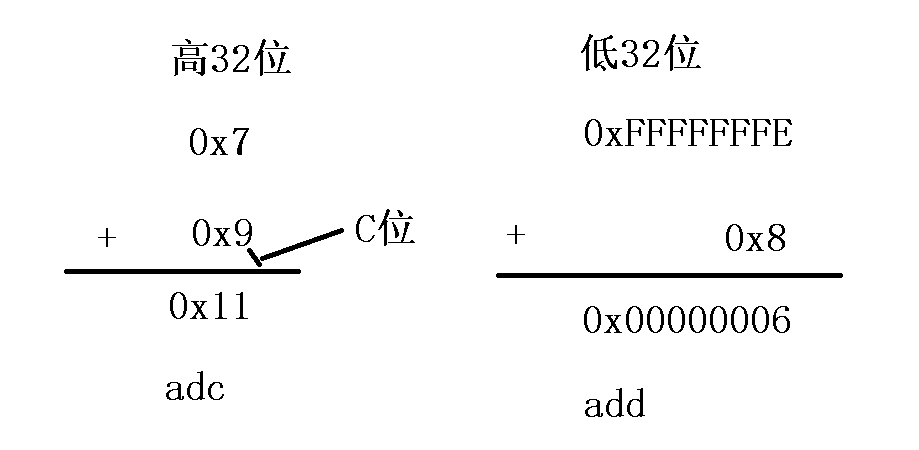
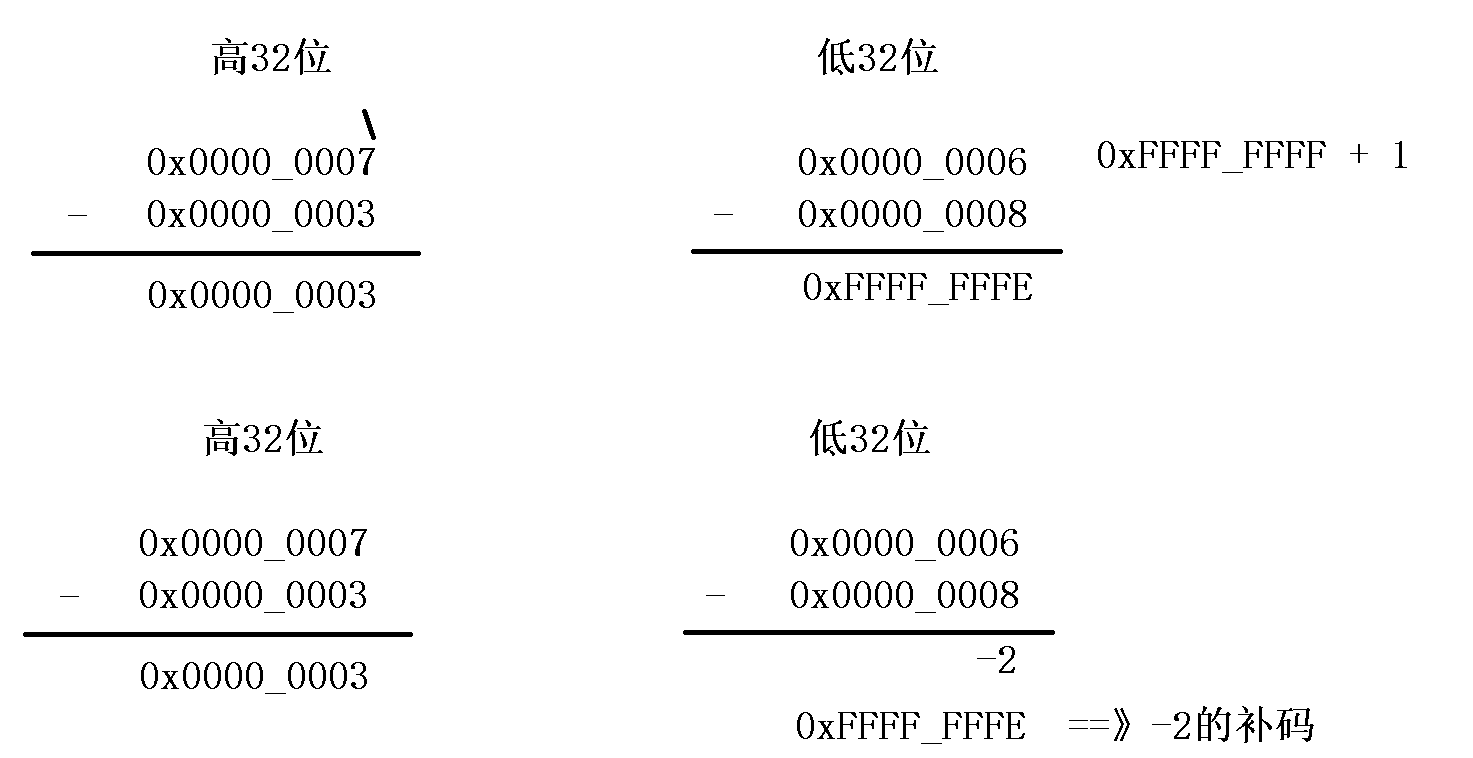
@ 案例1:实现两个64位数相加
@ r0和R1存放第1个64位的数
@ r2和r3存放第2个64位的数
@ r4和r5存放运算的结果
@ 第一步:准备两个64位的整数
mov r0, #0xFFFFFFFE @ 第1个数的低32位
mov r1, #0x7 @ 第1个数的高32位
mov r2, #0x8 @ 第2个数的低32位
mov r3, #0x9 @ 第2个数的高32位
adds r4, r0, r2 @ r4 = r0 + r2 = 0x00000006
adc r5, r1, r3 @ r5 = r1 + r3 + C = 0x11
@ 案例2:实现两个64位数相减
@ r0和R1存放第1个64位的数
@ r2和r3存放第2个64位的数
@ r4和r5存放运算的结果@ 算数运算指令
mov r0, #0x6 @ 第1个数的低32位
mov r1, #0x7 @ 第1个数的高32位
mov r2, #0x8 @ 第2个数的低32位
mov r3, #0x3 @ 第2个数的高32位
subs r4, r0, r2 @ r4 = r0 - r2 = 0xFFFFFFFE
sbc r5, r1, r3 @ r5 = r1 - r3 - !C = 0x3
@ 乘法指令 mul
mov r0, #3
mov r1, #4
mul r2, r0, r1 @ r2 = r0 * r1 = 0xC
@ 乘法指令的第二个操作数只能是一个寄存器
@ mul r3, r2, #2 @ error
5.5 比较指令
5.5.1 指令码
cmp
5.5.2 指令格式
cmp Rn, shifter_oprand
1. cmp指令没有目标寄存器,只有第一个操作寄存器和第二个操作数
2. cmp指令就是用于比较两个数的大小,本质就是进行减法运算。
Rn - shifter_oprand
3. cmp指令的执行结果最终会影响CPSR的NZCV位,并且不需要加S.
4. cmp指令经常和条件码配合使用,实现汇编指令的有条件执行。
5. 条件码可以实现汇编指令的有条件执行

5.5.3 参考案例
/* 5. 比较指令 */
mov r0, #9
mov r1, #15
/*
比较r0和r1寄存器中的值的大小:
如果r0>r1 ,则 r0 = r0 - r1
如果r0r1
subcc r1, r1, r0 @ r0 6、跳转指令
6.1 指令码
b : 不保存返回地址的跳转指令
bl : 保存返回地址的跳转指令
6.2 指令格式
b/bl{cond} Label(函数名)
Label: ---> 标签表示汇编函数的入口地址
函数体
b: 跳转到Label标签下的第一条指令,不保存返回地址到LR中
b跳转指令的使用场合:有去无回就用b跳转指令,
比如:
stop:
.....
b stop
bl: 跳转到Label标签下的第一条指令,同时保存返回地址到LR中
bl跳转指令的使用场合:有去有回就用bl跳转指令
比如:函数的调用
跳转指令的本质就是修改PC值,修改PC所指向的汇编指令。
6.3 指令测试代码
/*6. 跳转指令 */
@ 案例:封装函数,实现交换两个寄存器中的值
mov r0, #9
mov r1, #15
@ 使用bl指令调用函数
@ 自动保存返回地址到LR中
bl swap_func
nop @ 控制器,占位,没有任何的含义
@ LR寄存器中保存的是nop指令的地址
.if 0
b stop @ 不需要保存返回地址,使用b跳转指令
.else
ldr pc, =stop
.endif
swap_func:
eor r0, r0, r1
eor r1, r0, r1
eor r0, r0, r1
mov pc, lr @ 函数的返回
stop:
b stop
6.4 实现跳转的其他的方式
b label
bl label
mov pc, lr @ 一般用于函数的返回
ldr pc, =label @ 等价于b label
mov pc, #label @ 要求:label标签标识的地址必须是一个立即数
@ 此种用法不建议使用
6.5 综合练习题:求两个数的最大公约数

mov r0,#0x9
mov r1,#0x15
AAA:
cmp r0,r1
bEQ stop
subHI r0,r0,r1
subCC r1,r1,r0
b AAA
stop:
b stop7、特殊功能寄存器操作指令
7.1 指令码
msr
mrs
特殊功能寄存器操作指令是对cpsr寄存器进行读写操作的。
7.2 指令格式
msr cpsr, Rn @ 将Rn寄存器中的值赋值给CPSR寄存器
mrs Rd, cpsr @ 将CPSR寄存器中的值赋值给Rd寄存器
7.3 指令测试代码
用切换模式的方式验证这两条指令
/* 系统上电,默认工作在SVC模式下
此时CPSR的M[4:0]位 = 0b10011,
修改CPSR寄存器的M位,从SVC模式切换到用户模式
用户模式CPSR的M[4:0]位 = 0b10000,
操作CPSR寄存器时,只修改M位,其他位保持不变
*/
@ 方式1:直接给CPSR寄存器赋值
.if 0
msr cpsr, #0xD0 @ 0b1101 0000
.elif 0
mov r0, #0xD0
msr cpsr, r0
.endif
@ 方式2:间接修改CPSR的M位
mrs r0, cpsr @ 先读到普通寄存器中
bic r0, r0, #0x1F @ 对普通寄存器清0(只给要改的位清零)
orr r0, r0, #0x10 @ 将对应的位置1
msr cpsr, r0 @ 将结果写回到cpsr中
8、Load/Store内存读写指令
8.1 单寄存器操作指令(重要!重要!重要!)
8.1.1 指令码
ldr ---> 将内存地址中的数据读到寄存器中,读4字节
str ---> 将寄存器中的数据写到内存地址中,写4字节
ldrh ---> 将内存地址中的数据读到寄存器中,读2字节
strh ---> 将寄存器中的数据写到内存地址中,写2字节
ldrb ---> 将内存地址中的数据读到寄存器中,读1字节
strb ---> 将寄存器中的数据写到内存地址中,写1字节
ld : load st:store r:register h : half b : byte
8.1.2 指令格式
ldr/ldrh/ldrb Rd, [Rm]
[Rm] : Rm寄存器中的数据被当成一个地址看待
将Rm指向的地址空间的数据读到Rd寄存器中。
int a = 100;
int *p = &a;
p <==> [Rm]
int b = *p; <==> ldr Rd, [Rm]
str/strh/strb Rn, [Rm]
[Rm] : Rm寄存器中的数据被当成一个地址看待
将Rn寄存器中的数据写到Rm指向的地址空间中
int a = 100;
int b = 200;
int *p = &a;
p <==> [Rm]
*p = b; <==> str Rn, [Rm]
8.1.3 指令测试代码
ldr r0, =0x40000800 @ 准备内存的地址
ldr r1, =0x12345678 @ 准备数据
@ 将r1中的数据写到r0指向的地址空间中
str r1, [r0]
@ 将r0指向的地址空间中的数据读到r2中
ldr r2, [r0]
问题1:为什么使用0x40000800内存地址,可否使用其他地址?
被映射后有可读可写的权限,可以自己映射,但重新启动以后又需要重新映射

问题2:如何查看内存中的数据?
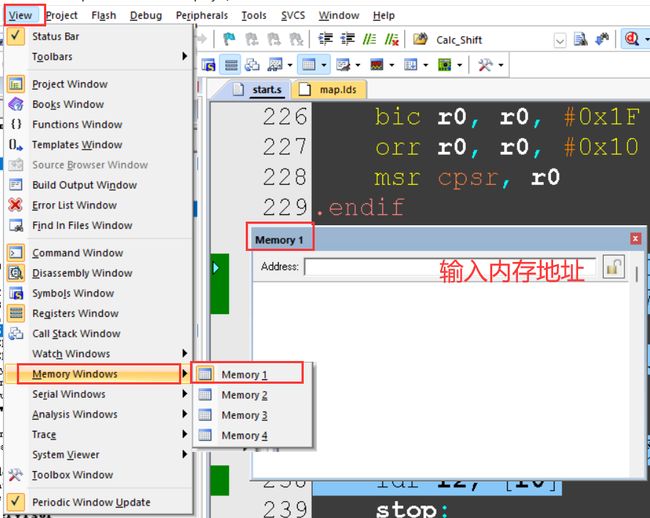
8.1.4 单寄存器操作指令的语法扩展
ldr/ldrh/ldrb Rd, [Rm, #offset]
将Rm+offset指向地址空间中的数据读到Rd寄存器中,
Rm寄存器中存储的地址不变
ldr/ldrh/ldrb Rd, [Rm], #offset
将Rm指向的地址空间中的数据读到Rd寄存器中,
同时,更新Rm指向的地址空间,Rm = Rm + offset
ldr/ldrh/ldrb Rd, [Rm, #offset]!
将Rm+offset指向的地址空间中的数据读到Rd寄存器中,
同时,更新Rm指向的地址空间,Rm = Rm + offset
! : 作用:更新Rm指向的地址空间
str/strh/strb同样支持以上三种不同的用法。
ldr r0, =0x40000800 @ 准备地址
ldr r1, =0x11111111 @ 准备数据
ldr r2, =0x22222222
ldr r3, =0x33333333
@ 将r1中的数据写到r0+4指向的地址空间中,
@ R0寄存器中存储的地址不变
@ [0x40000804] = 0x11111111 R0 = 0x40000800
str r1, [r0, #4]
@ 将r2中的数据写到r0指向的地址空间中,
@ 同时,更新r0中的地址,r0 = r0 + 4
@ [0x40000800] = 0x22222222 R0 = 0x40000804
str r2, [r0], #4
@ 将r3中的数据写到r0+4指向的地址空间中,
@ 同时,更新r0中的地址,r0 = r0 + 4
@ [0x40000808] = 0x33333333 R0 = 0x40000808
str r3, [r0, #4]!
@ 练习题:
ldr r0, =0x40000800 @ 准备地址
ldr r1, =0x12345678 @ 准备数据
str r1, [r0] @ 将r1中的数据写到r0指向的地址空间中
@ 使用ldrb指令按照字节的方式,将每个字节中的数据读到r2-r5寄存器中
ldrb r2, [r0, #0]
ldrb r3, [r0, #1]
ldrb r4, [r0, #2]
ldrb r5, [r0, #3]
ldrb r2, [r0], #1
ldrb r3, [r0], #1
ldrb r4, [r0], #1
ldrb r5, [r0], #1
ldr r0, =0x40000800 @ 更新r0中的地址
ldrb r2, [r0,#0]!
ldrb r3, [r0,#1]!
ldrb r4, [r0,#1]!
ldrb r5, [r0,#1]!
8.2 多寄存器操作指令
8.2.1 指令码
stm
ldm
m :multi
8.2.2 指令格式
stm Rm, {寄存器列表}
Rm寄存器中的数据将被当成内存的地址看待
将寄存器列表中的所有的寄存器中的数据,写到Rm指向的连续的地址空间中
ldm Rm, {寄存器列表}
Rm寄存器中的数据将被当成内存的地址看待
将Rm指向的连续的地址空间的数据,读到寄存器列表的每个寄存器中。
寄存器列表的书写格式:
1> 如果寄存器的编号连续,则使用“-”隔开
比如:r1-r5
2> 如何寄存器的编号不连续,则使用“,”隔开
比如:r1-r4,r7,r9
3> 寄存器列表中的寄存器要求从小到大的编号进行书写
比如:
r1-r4,r7,r9 : Ok, 编译可以通过
r4-r1 : Error, 编译报错
r4,r3,r2,r1 : Ok, 编译会报警告
4> 不管寄存器列表中的寄存器的顺序如何书写,
永远都是小编号的寄存器对应的使低地址,
大编号的寄存器对应的是高地址。
8.2.3 指令测试代码
ldr r0, =0x40000800 @ 准备地址
ldr r1, =0x11111111 @ 准备数据
ldr r2, =0x22222222
ldr r3, =0x33333333
ldr r4, =0x44444444
ldr r5, =0x55555555
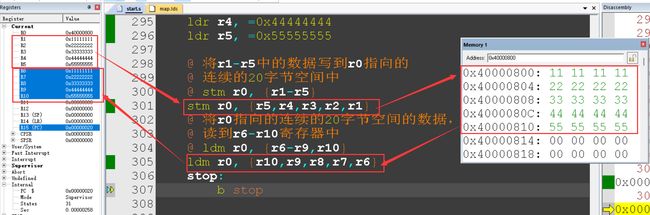
@ 将r1-r5中的数据写到r0指向的
@ 连续的20字节空间中
@ stm r0, {r1-r5}
stm r0, {r5,r4,r3,r2,r1}
@ 将r0指向的连续的20字节空间的数据,
@ 读到r6-r10寄存器中
@ ldm r0, {r6-r9,r10}
ldm r0, {r10,r9,r8,r7,r6}

8.3 栈操作指令
8.3.1 栈的种类
增栈:压栈之后,栈指针向高地址方向移动。
减栈:压栈之后,栈指针向低地址方向移动。
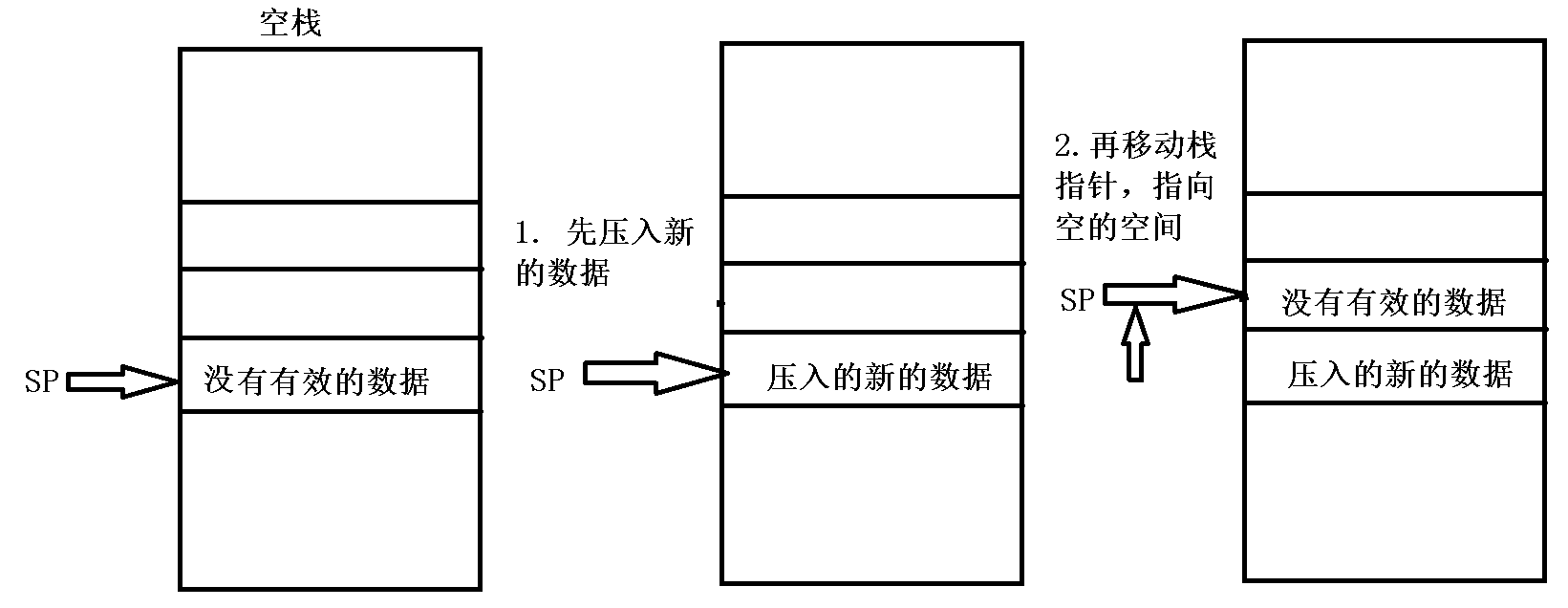
满栈:当前栈指针指向的栈空间有有效的数据,需要先移动栈指针,
指向一个没有有效数据的空间之后,然后再压入新的数据,
此时栈指针指向的空间依然有有效数据,因此再次压入数据时,
依然要先移动栈指针再压入新的数据。
空栈:当前栈指针指向的空间没有有效的数据,可以先压入数据,
然后再移动栈指针指向一个没有有效数据的空间,
因此载入压入数据时,可以先押入数据再移动栈指针。

8.3.2 栈的操作方式
满增栈 :Full Ascending
满减栈 :Full Descending
空增栈 :Empty Ascending
空减栈 :Empty Descending
8.3.3 栈的读写指令
满增栈 :Full Ascending
stmfa/ldmfa
满减栈 :Full Descending
stmfd/ldmfd
空增栈 :Empty Ascending
stmea/ldmea
空减栈 :Empty Descending
stmed/ldmed
ARM处理器规定默认使用的是满减栈。
8.3.4 指令的语法格式
stmfd sp!, {寄存器列表}
将寄存器列表中的所有的寄存器的数据,压栈到SP指向的连续的栈空间中,
! : 同时更新栈指针指向的地址
ldmfd sp!, {寄存器列表}
将栈指针指令的连续的栈空间的数据,出栈到寄存器列表的每个寄存器中,
! : 同时更新栈指针指向的地址
寄存器列表的书写格式:
1> 如果寄存器的编号连续,则使用“-”隔开
比如:r1-r5
2> 如何寄存器的编号不连续,则使用“,”隔开
比如:r1-r4,r7,r9
3> 寄存器列表中的寄存器要求从小到大的编号进行书写
比如:
r1-r4,r7,r9 : Ok, 编译可以通过
r4-r1 : Error, 编译报错
r4,r3,r2,r1 : Ok, 编译会报警告
4> 不管寄存器列表中的寄存器的顺序如何书写,
永远都是小编号的寄存器对应的使低地址,
大编号的寄存器对应的是高地址。
8.3.5 指令的测试代码
@ 初始化栈指针
ldr sp, =0x40000820
mov r0, #3
mov r1, #4
bl set_Value
add r2, r0, r1 @ r2 = r0 + r1 = 0x7
b stop
set_Value:
stmfd sp!, {r0-r1,LR} @ 压栈保存现场
mov r0, #5
mov r1, #6
bl add_func
ldmfd sp!, {r0-r1,PC} @ 出栈恢复现场
@ mov pc, lr
add_func:
stmfd sp!, {r0-r1} @ 压栈保存现场
mov r0, #7
mov r1, #8
add r3, r0, r1
ldmfd sp!, {r0-r1} @ 出栈恢复现场
mov pc, lr
8.3 栈操作指令
8.3.1 栈的种类
增栈:压栈之后,栈指针向高地址方向移动。
减栈:压栈之后,栈指针向低地址方向移动。
满栈:当前栈指针指向的栈空间有有效的数据,需要先移动栈指针,
指向一个没有有效数据的空间之后,然后再压入新的数据,
此时栈指针指向的空间依然有有效数据,因此再次压入数据时,
依然要先移动栈指针再压入新的数据。
空栈:当前栈指针指向的空间没有有效的数据,可以先压入数据,
然后再移动栈指针指向一个没有有效数据的空间,
因此载入压入数据时,可以先押入数据再移动栈指针。
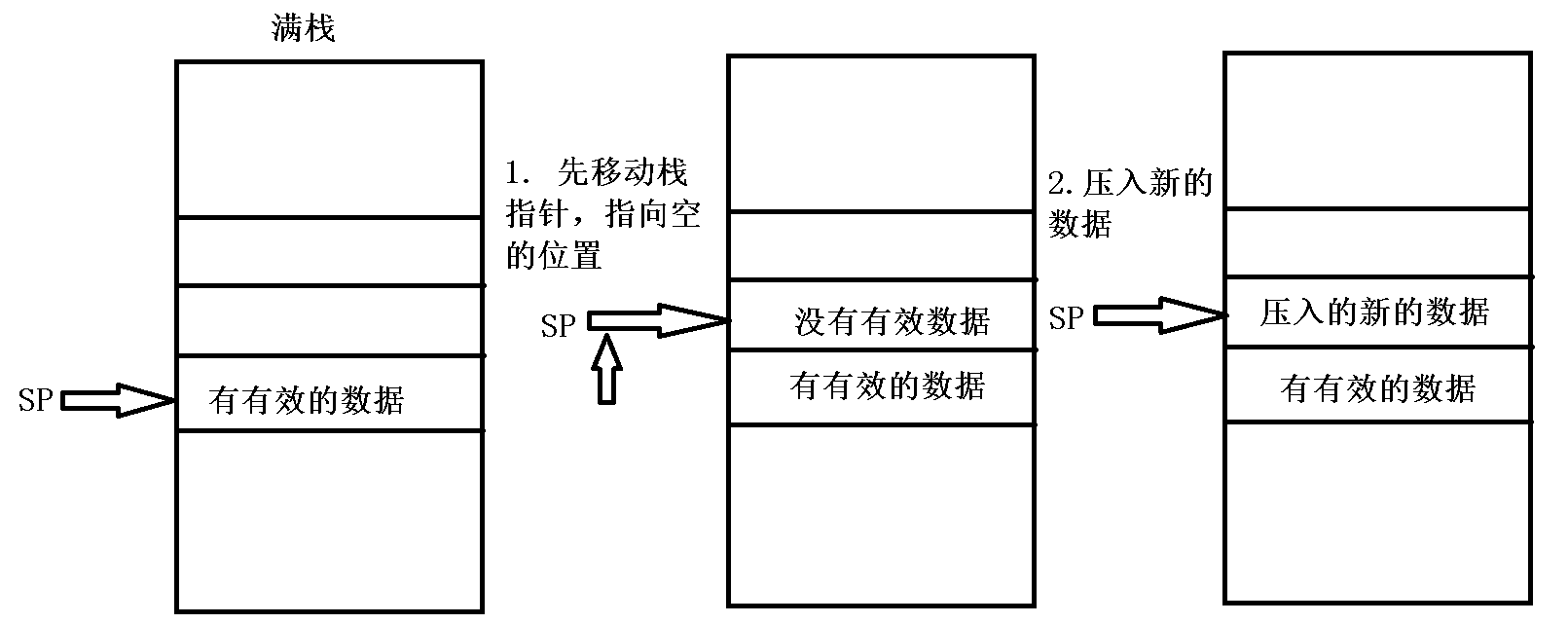

8.3.2 栈的操作方式
满增栈 :Full Ascending
满减栈 :Full Descending
空增栈 :Empty Ascending
空减栈 :Empty Descending
8.3.3 栈的读写指令
满增栈 :Full Ascending
stmfa/ldmfa
满减栈 :Full Descending
stmfd/ldmfd
空增栈 :Empty Ascending
stmea/ldmea
空减栈 :Empty Descending
stmed/ldmed
ARM处理器规定默认使用的是满减栈。
8.3.4 指令的语法格式
stmfd sp!, {寄存器列表}
将寄存器列表中的所有的寄存器的数据,压栈到SP指向的连续的栈空间中,
! : 同时更新栈指针指向的地址
ldmfd sp!, {寄存器列表}
将栈指针指令的连续的栈空间的数据,出栈到寄存器列表的每个寄存器中,
! : 同时更新栈指针指向的地址
寄存器列表的书写格式:
1> 如果寄存器的编号连续,则使用“-”隔开
比如:r1-r5
2> 如何寄存器的编号不连续,则使用“,”隔开
比如:r1-r4,r7,r9
3> 寄存器列表中的寄存器要求从小到大的编号进行书写
比如:
r1-r4,r7,r9 : Ok, 编译可以通过
r4-r1 : Error, 编译报错
r4,r3,r2,r1 : Ok, 编译会报警告
4> 不管寄存器列表中的寄存器的顺序如何书写,
永远都是小编号的寄存器对应的使低地址,
大编号的寄存器对应的是高地址。
8.3.5 指令的测试代码
@ 初始化栈指针
ldr sp, =0x40000820
mov r0, #3
mov r1, #4
bl set_Value
add r2, r0, r1 @ r2 = r0 + r1 = 0x7
b stop
set_Value:
stmfd sp!, {r0-r1,LR} @ 压栈保存现场
mov r0, #5
mov r1, #6
bl add_func
ldmfd sp!, {r0-r1,PC} @ 出栈恢复现场
@ mov pc, lr
add_func:
stmfd sp!, {r0-r1} @ 压栈保存现场
mov r0, #7
mov r1, #8
add r3, r0, r1
ldmfd sp!, {r0-r1} @ 出栈恢复现场
mov pc, lr9、软中断指令
9.1 指令码
swi
9.2 指令格式
swi{cond} 软中断号
软中断号的范围为:0 ~ 2^24-1
后续讲解异常处理过程时,讲解软中断指令实验一、点亮LED
流程:
使能时钟