PaddleOCR在ubuntu18.0上finetune中文模型遇到的各种坑
第一次写文章,主要是遇见的坑太多,怕以后记不住
配置:ubuntu18.0 cuda11.2 cudnn8.1 paddle2.2-gpu
下载官方paddle:https://www.paddlepaddle.org.cn/
然后下载OCR:https://github.com/PaddlePaddle/PaddleOCR
数据集制作参考:https://blog.csdn.net/Andrwin/article/details/120162193
【1】这里遇到了第一个bug,是读不出来汉字,原因是编码解码的问题
加一个编码格式就好了

with open("F:/10w/special.txt",encoding='utf-8-sig') as f:
【2】最后的部分为了导出成paddleocr的格式,需要做一些代码修改,不过都很简单,根据你生成的数量,调整一下zfill补0的值就好了
word,fontPath,save_dir,words_lenth,img_count = config()
line_words_list = generate_words(word,img_count,words_lenth)
filename='word_'
t=1
for line in line_words_list:
length = len(line)
font_size = 33 if np.random.randint(0,2)==0 else 20
file_name = filename+str(t).zfill(6)+".jpg"
t+=1
if(font_size==33):
size = (42,math.ceil(length*34.4))
draw_to_image(size,fontPath,font_size,line,save_dir,file_name)
else:
size = (29,math.ceil(length*20.8))
draw_to_image(size,fontPath,font_size,line,save_dir,file_name)
with open("d:/label.txt","a",encoding='utf-8') as f:
f.write("train_data/rec/train/"+file_name+"\t"+line+"\n")
数据集制作好以后,开始准备训练
参考:https://blog.csdn.net/Andrwin/article/details/120173126?ops_request_misc=&request_id=&biz_id=102&utm_term=paddleocr%E7%9A%84finetune&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-4-120173126.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
【3】这里首先遇见的bug就是,原代码里生成的数据集TXT编码,并不是UTF-8,所以解码出错,上面已经进行了修改。
【4】之后是cuda和cudnn的问题,因为最开始用了cpu,后来想用GPU训练的时候,发现各种问题,又更改cuda的链接和cudnn的库之类的,然后又和GCC版本不兼容啊,驱动不兼容啊之类的问题,不过如果一开始就安装好版本,应该就没这么多事了
【5】搞定环境之后,根据自己的GPU降低了batch_size的大小,最后又出现out_memory这一类的bug,上网找了好多,都说是batch_size太大,或者是cuda啊cudnn版本不对啊之类的,最后发现都不是,无奈的又再次看了一下最开始就查看过的显存,nvidia-smi查看发现,确实没有进程占用GPU,但是神奇的是显存就是6500/7973这样,所以就关机重启了,再查看,果然就175/7973,然后就完美运行了。
【6】训练过程中一直出现找不到train和text里的word_000001.jpg的图片,相对路径和绝对路径都试过了,完全没用,就只好听之任之了,好在loss和acc都是在变化的。
![]()
【7】我的训练集是2w张,设置是32的batch_size,预先设置是500epoch,不过在14轮就已经loss到峰值了,再之后就又回升了

停止训练之后,预测图片,发现自己的model并不存在,原来少了一步转换,官方文档里有写:
-c 后面设置训练算法的yml配置文件
-o 配置可选参数
Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./ch_lite/ch_ppocr_mobile_v2.0_rec_train/best_accuracy Global.save_inference_dir=./inference/rec_crnn/
【8】再次测试,依旧读不出东西,官方文档里有写:如果训练时修改了文本的字典,在使用inference模型预测时,需要通过–rec_char_dict_path指定使用的字典路径,并且设置 rec_char_type=ch
然而设置指明了文档以后,仍然不好用,现在怀疑是不是字典除了问题,因为最开始没发现是显存问题的时候,第一个warn就是model【5283】not match 【6623】这种,发现应该是预训练的模型是中文字典,现在是指向了自己的字典,字数不同不匹配,于是我就加了一些常用字进去,凑够了字数,现在在想是不是这一步出现了问题,但是常用字测不出来正常,但总不至于自己数据集的图片都识别不出来啊,所以下一步准备更换字典,或者重新训练,看看not match会不会影响训练,亦或者是终止
------------------------------------------------这是后续测试部分--------------------------------------------
【9】用test可以识别自己的数据,单单用识别模块,也可以识别,但是加上定位以后就识别不出来,够奇怪的
![]()
![]()
【10】考虑是不是图片过小,定位不够精准,所以把图片放在了word里截图了个大的,结果可以识别了!那基本就到这里结束了,下一步采用混合字典,看看可不可以训练。起码现在,单纯的在识别时调用混合字典,是识别不出来的,因为会跟其他的字更靠近。


【测试1】混合字典可以进行训练,但是15个epoch之后,loss基本没降多少,不收敛,考虑是不是训练集不够的原因,从2w扩展到了10w,准备再进行一次训练
【结果】是epoch训练不够,多跑跑就好了
【测试2】在第88个epoch的时候,在test上的acc达到了100,但是测试其他图片的时候,原来的字并不能识别出来,而且给定一个字甚至识别出了7个字…继续探索为什么会出现这种情况
【结果】通过对比发现原来是字典的问题,可以用自己字典跑,但是只能在给定的字典的后面加文字,因为预训练模型的字典是ppocr_keys,所以新训练的字要加在字典后面,索引和字是一一对应的,通过新字典训练,一开始的准确率就已经有了93左右,当然这也是因为训练集中有些是原字典当中的字,如果是纯新的数据,预计准确率也应该很快就可以上升,原来的acc之所以一直为0,很可能是因为识别出了字,但是字典不匹配,所以acc为0,而后来训练的字的权重越来越大,索引也就更偏向于新字,所以识别原有简单字识别不出来,因为没有对应的索引了啊,新人小白真是遇到了不少坑。希望这一次可以OK。
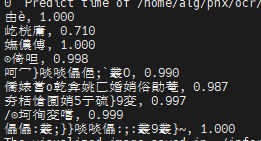
【测试3】又双叒叕出现问题了,新加的字可以识别出来了,不过原来的字又不行了,看起来原来的字也要加入训练集里试试看了。

【结果】这一次是自己的问题,训练好之后才发现字典没有更换,按理说那起码字典中有的字可以识别出来,但是结果是,字典中有的字依旧识别不出来,考虑可能是在训练中出现了字典中没有的字引起来的一系列误差,所以更换字典后再次训练,GPU是单卡的RTX2070,跑了一夜,88个epoch,才发现acc是0.9,但是保存模型的只有0.2,应该是每次输出的是训练集中的图片acc,保存模型时候用的测试集图片造成的,小小识别了一下,识别文字的准确率果然有0.2,而之前训练出来的乱七八糟的,识别出文字只有0.00000几,所以继续跑下去试试看,感觉是有戏的,先把学习率提高到了0.01,看看最终准确率先。
【暂停】训练好了以后依旧不可以,不知道是因为预训练模型是6623,而我更改了字典,最后一层的分类没有更改导致识别不准还是怎样,总结一下:
(1)更换了全生僻字字典和数据集,出来的效果只能识别生僻字
(2)在原字典上新增了一些文字,用的新字数据集,训练出来依旧只能识别新增的字
(3)在原字典上新增文字,用的新老数据集,训练出来效果依旧很神奇
(4)学习率将为0.00001,出来的依旧不知道是什么玩意儿
(5)准备用原字典,针对一些识别不出的字进行finetune,暂时转战text renderer
(6)用原字典进行训练生僻字,一个epoch就已经丢掉了之前的权重,不知道怎么finetune的