【leetcode】46.全排列 (回溯算法详细解析。java实现)
46. 全排列
难度中等825收藏分享切换为英文关注反馈
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]
分析
请读者带着以下问题理解回溯搜索算法的思想。
1、什么是“树形问题”?为什么是在树形问题上使用“深度优先遍历”?不用深度优先遍历我们还可以用什么?
2、什么是“回溯”?为什么需要回溯?
3、不回溯可以吗?
首先介绍“回溯”算法的应用。“回溯”算法也叫“回溯搜索”算法,主要用于在一个庞大的空间里搜索我们所需要的问题的解。我们每天使用的“搜索引擎”就是帮助我们在庞大的互联网上搜索我们需要的信息。“搜索”引擎的“搜索”和“回溯搜索”算法的“搜索”意思是一样的。
“回溯”指的是“状态重置”,可以理解为“回到过去”、“恢复现场”,是在编码的过程中,是为了节约空间而使用的一种技巧。而回溯其实是“深度优先遍历”特有的一种现象。之所以是“深度优先遍历”,是因为我们要解决的问题通常是在一棵树上完成的,在这棵树上搜索需要的答案,一般使用深度优先遍历。
“全排列”就是一个非常经典的“回溯”算法的应用。我们知道,N 个数字的全排列一共有 N! 这么多个。
大家可以尝试一下在纸上写 3 个数字、4 个数字、5 个数字的全排列,相信不难找到这样的方法。
以数组 [1, 2, 3] 的全排列为例。
- 我们先写以 1 开头的全排列,它们是:
[1, 2, 3], [1, 3, 2]; - 再写以 2 开头的全排列,它们是:
[2, 1, 3], [2, 3, 1]; - 最后写以 3 开头的全排列,它们是:
[3, 1, 2], [3, 2, 1]。
我们只需要按顺序枚举每一位可能出现的情况,已经选择的数字在接下来要确定的数字中不能出现。按照这种策略选取就能够做到不重不漏,把可能的全排列都枚举出来。
- 在枚举第一位的时候,有 3 种情况。
- 在枚举第二位的时候,前面已经出现过的数字就不能再被选取了;
- 在枚举第三位的时候,前面 2 个已经选择过的数字就不能再被选取了。
这样的思路,我们可以用一个树形结构表示。看到这里的朋友,建议自己先尝试画一下“全排列”问题的树形结构。
使用编程的方法得到全排列,就是在这样的一个树形结构中进行编程,具体来说,就是执行一次深度优先遍历,从树的根结点到叶子结点形成的路径就是一个全排列。
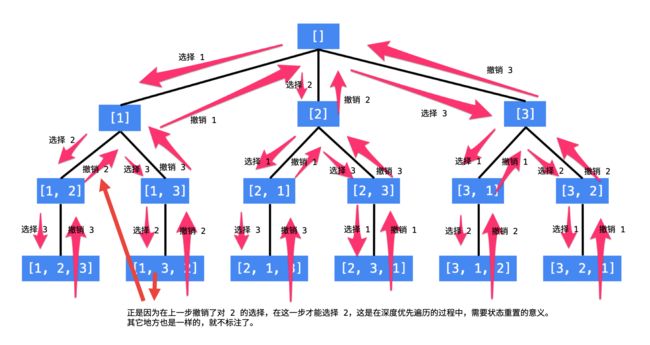
说明:
1、每一个结点表示了“全排列”问题求解的不同阶段,这些阶段通过变量的“不同的值”体现;
2、这些变量的不同的值,也称之为“状态”;
3、使用深度优先遍历有“回头”的过程,在“回头”以后,状态变量需要设置成为和先前一样;
4、因此在回到上一层结点的过程中,需要撤销上一次选择,这个操作也称之为“状态重置”;
5、深度优先遍历,可以直接借助系统栈空间,为我们保存所需要的状态变量,在编码中只需要注意遍历到相应的结点的时候,状态变量的值是正确的,具体的做法是:往下走一层的时候,path 变量在尾部追加,而往回走的时候,需要撤销上一次的选择,也是在尾部操作,因此 path 变量是一个栈。
6、深度优先遍历通过“回溯”操作,实现了全局使用一份状态变量的效果。
下面我们解释如何编码:
1、首先这棵树除了根结点和叶子结点以外,每一个结点做的事情其实是一样的,即在已经选了一些数的前提,我们需要在剩下还没有选择的数中按照顺序依次选择一个数,这显然是一个递归结构;
2、递归的终止条件是,数已经选够了,因此我们需要一个变量来表示当前递归到第几层,我们把这个变量叫做 depth;
3、这些结点实际上表示了搜索(查找)全排列问题的不同阶段,为了区分这些不同阶段,我们就需要一些变量来记录为了得到一个全排列,程序进行到哪一步了,在这里我们需要两个变量:
(1)已经选了哪些数,到叶子结点时候,这些已经选择的数就构成了一个全排列;
(2)一个布尔数组 used,初始化的时候都为 false 表示这些数还没有被选择,当我们选定一个数的时候,就将这个数组的相应位置设置为 true ,这样在考虑下一个位置的时候,就能够以 O(1) 的时间复杂度判断这个数是否被选择过,这是一种“以空间换时间”的思想。
我们把这两个变量称之为“状态变量”,它们表示了我们在求解一个问题的时候所处的阶段。
4、在非叶子结点处,产生不同的分支,这一操作的语义是:在还未选择的数中依次选择一个元素作为下一个位置的元素,这显然得通过一个循环实现。
5、另外,因为是执行深度优先遍历,从较深层的结点返回到较浅层结点的时候,需要做“状态重置”,即“回到过去”、“恢复现场”,我们举一个例子。
从 [1, 2, 3] 到 [1, 3, 2] ,深度优先遍历是这样做的,从 [1, 2, 3] 回到 [1, 2] 的时候,需要撤销刚刚已经选择的数 3,因为在这一层只有一个数 3 我们已经尝试过了,因此程序回到上一层,需要撤销对 2 的选择,好让后面的程序知道,选择 3 了以后还能够选择 2。
这种在遍历的过程中,从深层结点回到浅层结点的过程中所做的操作就叫“回溯”。
下面来看看代码应该如何编写:
参考代码 1:(注意:这个代码是错误的,希望读者能自己运行一下测试用例自己发现原因,然后再阅读后面的内容)
import java.util.ArrayList;
import java.util.List;
public class Solution {
public List<List<Integer>> permute(int[] nums) {
// 首先是特判
int len = nums.length;
// 使用一个动态数组保存所有可能的全排列
List<List<Integer>> res = new ArrayList<>();
if (len == 0) {
return res;
}
boolean[] used = new boolean[len];
List<Integer> path = new ArrayList<>();
dfs(nums, len, 0, path, used, res);
return res;
}
private void dfs(int[] nums, int len, int depth,
List<Integer> path, boolean[] used,
List<List<Integer>> res) {
if (depth == len) {
res.add(path);
return;
}
for (int i = 0; i < len; i++) {
if (!used[i]) {
path.add(nums[i]);
used[i] = true;
dfs(nums, len, depth + 1, path, used, res);
// 注意:这里是状态重置,是从深层结点回到浅层结点的过程,代码在形式上和递归之前是对称的
used[i] = false;
path.remove(path.size() - 1);
}
}
}
public static void main(String[] args) {
int[] nums = {
1, 2, 3};
Solution solution = new Solution();
List<List<Integer>> lists = solution.permute(nums);
System.out.println(lists);
}
}
这段代码在运行的时候输出如下:
[[], [], [], [], [], []]
原因出现在递归终止条件这里:
if (depth == len) {
res.add(path);
return;
}
path 这个变量所指向的对象在递归的过程中只有一份,深度优先遍历完成以后,因为回到了根结点(因为我们之前说了,从深层结点回到浅层结点的时候,需要撤销之前的选择),因此 path 这个变量回到根结点以后都为空。
在 Java 中,因为都是值传递,对象类型变量在传参的过程中,复制的都是变量的地址。(Python 我不是很清楚 Python 中方法变量的传递机制,所以暂时没有写,欢迎知道的朋友补充,但是从实验的结果上看和 Java 很像。)这些地址被添加到 res 变量,但实际上指向的是同一块内存地址,因此我们会看到 6 个空的列表对象。解决的方法很简单,在 res.add(path); 这里做一次拷贝即可。
修改的部分:
if (depth == len) {
res.add(new ArrayList<>(path));
return;
}
此时再提交到「力扣」上就能得到一个 Accept 了。
复杂度分析:(这部分内容可以不掌握,增加学习负担,并且可能有错误,欢迎指处)。
回溯算法的时间复杂度一般都比较高,有些问题分析起来很复杂,我个人觉得没有必要掌握,而且剪枝剪得好的话,复杂度会降得很低,因此分析的最坏时间复杂度的意义也不是很大,视情况而定。
- 时间复杂度:O(N \times N!)O(N×N!)
(1) 非叶子结点的个数,依次为(按照层数来)
1 + A N 1 + A N 2 + ⋯ + A N