音乐智能推荐 ALS算法
音乐推荐分析
特征的产生:
能让用户产生兴趣的行为,可能包括有:试听音乐、收藏音乐、收藏专辑|歌单、搜索、关注歌手|用户、下载歌曲、分享(比较少)
权重产生:
-
按照用户操作成本
下载+播放 > 喜欢+播放 > 搜索+播放 > 播放 > 下载 > 喜欢
-
权重分析之播放次数加权
因为音乐播放时一个偏好动作,你可能对喜欢的音乐进行重复播放,一次播放和两次三次或者说十次播放,能反应出你对该歌曲的偏好程度不同,假设一次播放我们给与的权重为a,那么重复n次播放,我们赋予权重为a+0.01*n (0.01可相对调整)(如何确定有效播放次数?暂未考虑)
推荐内容:
-
歌曲推荐:推荐的结果应该为uid:array((mid,score))
-
歌单推荐:推荐的结果应该为uid:array((mid,score))
推荐之冷启动:
冷启动:
- 由于新用户没有历史记录,没有数据就不能很好的推荐给用户相关的音乐
- 由于新发布发音乐没有人听过,所有用户对于该音乐的分数相当于0,无法推送
解决方案:
- 最简单的方法就是推荐热度音乐(排行榜)
- 根据用来入口来源,比如说微博,qq,爬取用户动态信息,对用户进行分类,(该方法在后期,根据用户心情推荐有奇效,比如,用户在微博或者qq发表一条动态 ,或者今天发表的动态,对内容进行情感分析,推荐相关音乐或者相反类型音乐)
- 根据手机号码读取手机联系人,匹配相关好友,推荐年龄相符活跃度高的好友歌单或者歌曲
- 4.26更新 经过思考,冷启动 在某种程度上可以用相似度来推荐,比如该用户是首次访问,更具他填写的一些基本信息,更具用户相似度矩阵,计算与该用户的相似度领域,然后意见相关音乐,音乐也是如此,可否实现?(暂为实现)
Spark 2.2.0ml包和mllib包
既然说到2.2.0 不得不说 org.apache.spark.ml org.apache.spark.mllib 这两个包的区别
- 官网里面说 在spark3.x 以后可能会废除mllib
- 在spark2.x以后,mllib不更新 只负责修复bug
- 在ml中 机器学习的对象为dataframe 而ml中为rdd对象
基于Spark2.2.0解决冷启动方案
除上述方案在业务逻辑上可以解决冷启动,在代码层面上 saprk2.2.0 对算法进行了优化
在模型对象model 中有一个方法 setColdStartStrategy() 查找源码可以发现 此方法有两个值 有个为nan 另一个为drop,可以看到nan为默认值,

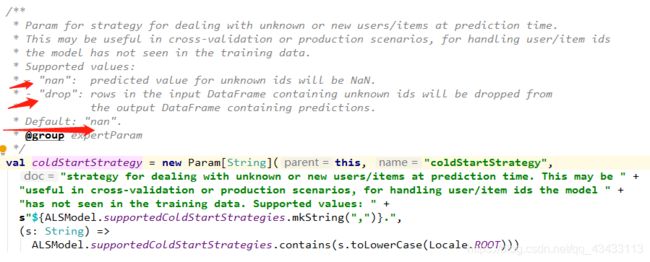
nan参数 是指在模型处理参数是 如果遇到未知的参数 即未出现的userid moiveid (即冷启动)时 ,他推荐的结果为nan,个人觉得这种方式可以用在实时推荐中
drop参数 是指在交叉验证中 处理不了nan值 会删除nan值和任意的行 然后在对剩下的数据进行推荐(离线推荐的时候更管用?看需求,是否需要甄别新用户)
Spark 智能推荐之显隐性特征处理
一般对数据分析过程中,或多或少都具有隐性特征,而我们一般是对数据的显性特征进行转化为分数,隐性特质某些程度上是没有考虑到,


在spark2.2.0中 new ALS对象是 参数setImplicitPrefs(true) 该方法默认为false fasle 为创建显性模型,不考虑隐性因素,但是此方法还可以传入true,传入true为考 虑隐性因素的模型,在隐性因素就多或者占比重较大时,可以创建隐性模型,如果集群性能比较好,建议创建隐性模型,在创建隐性模型后,参数对比显性模型应该相对调整,要不然均方根误差比显性模型的大,以至于没有显性模型准确
Spark 智能推荐之误差分析(暂时写不了)
在Spark 机器学习中 常见的四种误差分析方式:均方根误差(RMSE),均方误差(MSE),拟合优度检验(R2),平均绝对误差(MAE)
RMSE:均方根误差,数学表达式为,n组数据a1…an,取预测值为b1…bn 计算对应的预测值与真实值之间的差值取其平方,累加求和,取平均值 对结果进行开方
意义 :rmse 主要代表 一组数据 预测值和真实值的差异 代表预测数据偏离真实数据的程度
r m s e = ( ( b 1 − a 1 ) 2 + . . . . . + ( b n − a n ) 2 ) / n rmse= \sqrt{((b_1-a_1)^2+.....+(b_n-a_n)^2)/n} rmse=((b1−a1)2+.....+(bn−an)2)/n
MSE: 均方误差,数学表达式为,n组数据a1…an,取预测值为b1…bn 计算对应的预测值与真实值之间的差值取其平方,累加求和,取平均值
意义:MSE 越小 说明预测值与真实值有更好的精确度 说明预测值与一组数据之间的关系
m s e = ( ( b 1 − a 1 ) 2 + . . . . . + ( b n − a n ) 2 ) / n mse={((b_1-a_1)^2+.....+(b_n-a_n)^2)/n} mse=((b1−a1)2+.....+(bn−an)2)/n
推荐之’越推越窄’
Q:由于大多数推荐算法,根据用户的历史行为,会导致推荐的结果越来越窄,越来越单一化,重复化,其实用户听音乐更多是根据用户心情来的,或者根据音乐、歌手的热度来的(比如时下抖音流行音乐?时下流行的歌手?),如何多风格(口味)的推荐用户的音乐?
-
不成熟想法之一:推荐歌曲不在多而在精,根据算法预测出用户的推荐结构,大多数是按照分数进行排序,某种程度上,可以排序完了取出前n个,然后对前n个进行排列组合,不按照分数排序进行推送
-
在对用户推荐的前n个歌曲中,去掉x个分数排名的的,加入其它风格或者类型的歌曲,进行推荐
-
在时下热度时,用户对某个歌手很是关注或者偏爱,或者很多人对此歌手偏爱,即热度排行前三的歌曲的歌手,某种程度上可以推荐该歌手的其他不出名的歌曲
推荐之时间因素(根据业务来定的)
某种程度上来说,时间因素很重要,他可以分析出用户听音乐的时间段,什么时候听,是否在最后推荐的结果中加入时间因素?或者对用户听过的音乐进行时间维度分类,对组和好的推荐的结果进行过滤?(此种方法靠谱!)
4.26 更新: 最近了解了一下决策树,突然有个新的思路 是否可以结合决策树+协同过滤 对车载音乐进行混合推荐,因为公司业务为 特定的时间+特定的场合 推荐不同的音乐,在决策树中,可以在一级分类为时间,二级分类为地点,三级分类…,该套方案可为后期发展方案,某种程度上肯定比只有协调过滤准确
音乐推荐之采集音乐时长分析
在音乐数据采集中,用户收听或者播放的这首歌曲的真实时长x,其实是很重要的,某种程度能强烈反应出用户对该首音乐的喜好程度(通常如果不喜欢该音乐 很快就会跳过,而如果偏爱的话,就会听完大部分或者所有的时长),取音乐真实时长x/音乐时长s得到的百分比r,r可以反映出,用户本次对该首音乐的情况,但是,在数据清洗时,如何判断x的有效性?
1.通常的做法是, 取x与s相比较,0<=x<=s,这种事最常见的处理方式,如果没有采集到x,即将x当0处理
2.但是通常还有其他情况,比如,会有用户在听音乐的时候,遇到高潮部分,会将进度条拉回去(将音乐倒退),此时重复收听高潮部分,导致采集到x>s,此时如何判断x的有效性?
3.是否还存在其他采集情况?
用户行为数据采集方案
在大数据行业,建议所有的一手数据,都应该有大数据部门人员一手采集,切不可拿二手数据来分析,所有数据指标,只能有大数据部门 人员计算而来,前端采集的数据都要通过清洗规则,然后才能入库,不可胡乱入库,切不可直接引用前端采集的数据,一但开始后期数据 出现问题,涉及整个数据方案的修改!
推荐算法之欧几里得距离与余弦相似度
离线推荐
在离线推荐部分设计:
主要应用场景:一般应用在首页推荐,即用户访问时还没有产生行为数据,这其中分为两部分,一部分为老用户,因为老用户有历史数据,可以在他进入应用首页推荐位上,为他展示离线推荐的结果,另外一部分为新用户,由于新用户没有历史数据(冷启动问题),可在推荐位上展示相关热度的排行数据。
实时推荐
实时推荐架构设计:
没有写完就发布了,主要是怕没时间写完或者没有毅力,先发布,给自己一点动力,写的不好请大家指教,谢谢