Velox: Meta 实现的计算引擎底座
0 背景
近期加入了计算引擎领域, 才深刻得体会到低头向前冲的时候抬头跟进一下业界有多么得重要. 计算和存储差异还是非常大的, 本质上是有无状态的差异. 计算方向的技术栈重心在主存及以上 偏向cpu的体系; 存储的重心则在主存及以下的偏向磁盘的体系. 而 CPU 技术体系变革极快, 不论是底层的硬件技术 还是 计算思想 都跟着业界最前沿的计算科技的接近快速变化, 不像存储 磁盘技术的革新是以十年为单位的(从 HDD–> SSD --> NVMe-SSD --> NVM 已经经过了数十年的时间了), 受限于材料学和物理学的发展,只能从距离cpu的距离上找寻性能提升点(NVM)以及容量(remote storage)上下功夫了. 但是计算硬件的发展还在如火如荼, 除了大模型体系衍生的市场需求推进之外还有本身计算硬件和软件结合的多种方式、硬件和主存/cpu-cache 之间的高效数据交互 等等, 都在尝试各种提升效率的方案.
在这样的大背景之下, 对于个人以及公司来说需要持续跟进业界的进展, 搭不上当前这趟车的话就会比其他人/公司 慢不止一步.
Pandas & Apache-Arrow & ibis 等项目的创始人 Wesmckinney 可以说从 Pandas开始遇到各种问题 到 Arrow 如今的如日中天之间的近十年时间一直在计算领域探索和思考. 利用 Arrow 解决了数据分析场景下 数据在不同的文件格式/服务器/磁盘和内存之间的传输效率问题, 用一套统一的内存格式成为了一个通用且高效的数据存储/处理/交互平台. 这个时候 Arrow 项目的作用已经远超 Wes当初提出它要解决的 Pandas等项目的问题范畴, 这给了 Wes 以及 业界巨大的启发.
Arrow 将模块化、互操作性、可组合性做到了极致, 这一些特性为计算软件的发展带来了新的思想. Arrow 利用这一些特性可以节省大量反复造轮子的人力, 大家不需要大家自己的数据管理/存储平台, 只需要调用arrow的各种语言库 调用对应的内存/磁盘 管理的接口, 即可完成数据的 高效 ETL 操作. 这一些设计思想完全可以迁移到为AP 甚至 TP 服务的 计算引擎这里, 因为像是类型系统、表达式求值、物理计划的算子执行 这样的能力是几乎所有计算引擎都需要的能力. 实现一套统一的 但是内部模块化的计算引擎 为上层不同的业务提供计算需求, 让一个全新的业务用最快的时间搭建起不输于业界最先进的分析型系统太多的性能 且 节省了大量的重复造轮子的人力. 如果存在这样的系统,那简直是计算领域的小革新了, 意味着会有很多的资源投入到计算本身的极致优化中,而不是互卷, 长远来看这是造福人类社会的事情.
本文要介绍的 Velox, 以及相关的 Arrow-datafusion 都是在这样的大背景下发展起来的, 且处于高速发展中并且以肉眼可见的速度产生了较大的收益.
1 要解决的问题
Velox 在 Meta中要解决的核心问题如下:
- 公司内部 大量的服务于分析型系统的数十个组件在不断得重复造相同的轮子, 且 不同的组件之间还有大量的数据传递以及统一计算结果的工作 耗费了巨大的人力. 但是分析场景中除了 sql 前端(parser)、优化器、runtime、io调度之外有更多的相同处理场景, 比如 类型系统、表达式计算、物理算子、内存格式 和 执行期间的资源管理体系都是一样的.
- 因为上面的问题, 每一个组件都没有办法极致化数据处理的性能,导致了过量的资源消耗, 毕竟大厂还是需要更为合理的降本增效.
基于以上的核心问题, Velox 通用计算平台(核心实现是 C++ 基础库的形式) 提供的解决方案如下:
- 性能方面: 实现了大量的 runtime 优化, 比如充分利用simd架构、惰性求值、自适应的谓词重拍和谓词下推、公共子表达式消除、代码生成等.
- 一致性方面: 这里一致性指的是对不同平台的数据输入都能保证一致性的计算结果, 毕竟相同的处理体系. 就不需要不同系统之间的数据搬迁、计算 以及 结果同步等耗时耗力的工作了, 只需要该系统快速支持以下 velox 即可.
- 工程效率方面: 所有的功能以及相关优化均是一次开发和维护, 不需要反复造轮子, 极大得提升了工程效率.
目前 Velox 已经集成或正在与 Meta(及其他)的十多个数据系统集成,例如 Presto、Spark、PyTorch、XStream(流处理)、F3(特征工程)、FBETL(数据提取) )、XSQL(分布式事务处理)、Scribe(消息总线基础设施)、Sabre(高 QPS 外部服务) .
比如 Presto 项目, 它是 meta 的 SQL计算引擎, 由coordinator nodes 负责sql的parser、优化、资源管理, worker nodes拿到物理执行计划进行实际的执行. 大多数的执时间都消耗在了 work-nodes 的数据处理中, 因为 Presdo 用的是java实现的, 也会有大量的 java进程, JVM, GC的运行开销. Velox 快速实现了 Prestissimo 项目(核心实现很简单, 也就是让velox能够读懂 coordinator 的plan 以及 和 coordinator 能够通信), 用于取代 work-nodes的功能, 接受 coordinator-nodes的物理计划, 并执行. 内部完全是 velox worker-worker的高效数据交互, 拥有搞笑的处理引擎以及统一的处理方式. 在实际生产环境中, Prestissimo 提供相同的计算能力的情况下能够减少 3倍的 work-nodes 机器资源.
类似的工作也在 spark中用 velox实现的 Spruce 可以将 spark的计算任务 反序列化为 velox能识别的物理plan, 在velox中执行, 也同样在性能层面有直接效果.
还有前面提到的 流处理或者 F3 服务于机器学习的特征处理系统 都能够在较短的时间内产生较大的收益,并且 不同的系统完全可以用 velox 解耦出来的不同能力, 比如只用 类型系统 + 计算函数 就可以达成流处理的需求.
2 实现
2.1 类型系统
做过计算引擎的同学都知道要实现一个完备、准确、易维护且可扩展的类型系统到底有多难, 像 PG这样的跟着标准走的数据库拥有的基础类型就达到了四百多种, 更不用说无穷无尽的 UDT(User defined type). 而且 其中最为复杂的像是 Numeric 中的 decimal 如何在它支持足够高的精度的情况下能够保证正确性. 整个这一套类型系统 想要正确得做出来至少得以数个人年为单位, 而像 Arrow 这样的优雅的类型系统则更是遥遥无期.
所以 Velox 底层的类型系统实现是有 大量的 Arrow影子的, 毕竟 Velox背后除了 meta 开发者之外也是有 Wes等 Arrow核心团队的支持. 上层系统输入的数据能够在 Velox 中被统一编码解码 以及 进行对应类型的转换求值, 是整个计算引擎的计算核心了, 也是抽象度最高的部分.
2.2 向量内存格式
Velox 的内存格式的组织是在 Arrow的内存格式的基础上做了一些扩展. 内存格式是将不同类型的数据(数组、字符串、null-values)以统一高效方式存储在内存中并提供高效的编码、解码的方式. 实现中 Velox的 RowVector 的功能就是 Arrow 中 RecordBatch的功能只不过 Velox 在 其基础上做了一些很有意思的扩展.
LazyVector, 用于实现惰性求值, 在第一次使用的时候才会取实际的value.在部分场景用于减少或者限流 io 操作, 比如 在读取一些稀疏列的时候通过ValueHook回调将很多不需要读取的数据 filter掉.DecodedVector服务于业务的一个需求, 支持将超大多维 vector 展平, 并能够在展平后的数据集合上加索引以及编码. 然后为用户提供统一的访问接口可以进行高效的访问.
同时Velox 在类型细节上相比于 Arrow 也做了一些适合 Meta 需求的一些差异:
1.字符串设计增加了 StringView 的元数据区域. Arrow 的数据存储统一用的是内存buffer + size 表示.
const uint8_t* data_;
int64_t size_;
Arrow 则在 buffer的基础上增加了一个元数据字段:
uint32_t size_;
char prefix_[4];
union {
char inlined[8];
const char* data;
} value_;
其中 prefix_ 字段的四个字节用来表示字符串前缀, 用于加速过滤和排序操作, 更好得利用 simd 高效比较. 其他的 size_ 和 value_ 则是完全内联, 比如针对 trim()和 substr() 这样的操作只需要更新指针就好了.
2.RowVector 内部的数据支持无序更新. 即在 if/switch 这样的分支语句中要更新 RowVector 的字段, 这个时候如果能够支持 无序写入, 就可以由simd 批量更新,而不需要for 循环逐个执行更新. Velox 之所以能够支持这个是因为保证了要更新的某一个列的数据大小是恒定的, 针对变长的数据类型 Velox 也通过支持 size+offset buffers , 无序写入时每一个元素指定要写入的 offset + size 即可.
3.更多编码类型的支持. Velox 支持了 Run-Length Encoding 和 Const Encoding, 前者是能够支持高效的无损压缩能力, 后者则服务于 literal和partition-key 的场景, 即某一个列全部是一样的值, 只需要存储一份编码结果就好了, 极大得节省存储空间.
以上提到的和 arrow 的类型实现细节上的差异部分, velox 也在向 arrow 社区沟通合并中.
2.3 表达式求值
应用场景:
- 可以被 FilterProject 算子使用, 用于过滤和投影操作.
- TableScan和 IO Connects 可以用此评估是否需要执行谓词下推操作.
- 可以被独立使用, 比如机器学习过程中的数据预处理.
对于一个输入的表达式 会用 Expression-Tree来表示,每一个节点可能有如下几种类型的表示(这个其在其他计算引擎中都比较通用,大体实现都差不多, 包括arrow-acero, duckdb, 确实可以抽象):
- 输入列的引用. 比如 在PG 中就是 Var, Arrow中就是 FieldRef
- 常量. Const类型/Literal
- 函数表达式. 比如 PG 中的
T_FuncExpr, 包含函数和其参数表达式 - CAST 表达式. 用于将表达式的输出结果转为指定的类型.
- lambda 函数. 用户自定义的函数类型.
输入的表达式 tree 类似如下
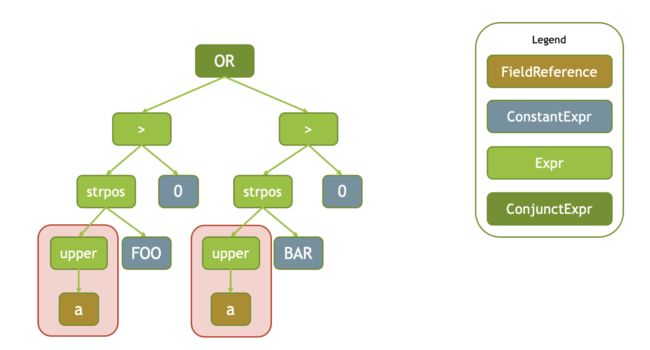
Velox 表达式的求值过程主要是两步:
这个过程的实现在 PG中是利用 JIT来进行优化的, 因为大多数的传统数据的执行器是解释型, Velox 采用编译型执行则更有利用一些 RunTime的优化:
1.编译. 将一个或者多个表达式列表编译为新的可执行的表达式.这个过程可以应用很多的 Runtime优化.
包括:
- 公共子表达式消除. 比如对于输入表达式树
strpos(upper(a), 'FOO') > 0 OR strpos(upper(a), 'BAR') > 0, 被谓词OR分开的两个子表达式中都包含一个公共表达式upper(a), 则这个表达式在编译期间会进行消除, 保证只需要执行一次即可. - 常量折叠. 将输入的确定性表达式替换为 Const/Literal 的过程. 比如对于表达式
upper(a) = upper('Foo')则会被替换为upper(a) = 'Foo' - 自适应的介词重排. Velox 动态跟踪输入的表达式中介词的性能,哪一个介词能够在最短的时间内过滤最多的值,则优先对哪一个介词之后的表达式进行求值;并且会扁平化
OR/ADD介词, 比如表达式AND(AND(AND(a,b),c),d)则会被展平为AND(a,b,c,d).
2.求值.对编译生成的表达式进行求值,计算实际输出的结果. 实际执行的时候会利用 SIMD指令来加速某一些函数/场景的求值过程.
除了以上两个基本步骤,在表达式求值整个过程中 Velox 利用编译器特性支持了代码生成, 这个特性目前还没有上生产. 且应用场景也是类似于 JIT 这种能力, 仅对于 cost比较高的plan效果比较好, 因为代码生成这种能力对性能的提升本质是利用 CPU+内存 来换取执行时间的, 也是完全依赖编译器的优化能力. 毕竟 编译器工程师肯定比 数据库内核工程师更懂 对CPU 友好的代码.
论文中还花了一个完整的小结来介绍 Velox 的函数体系, 这块的基本设计和 arrow::compute 基本一样, 因为需要一套完备的函数管理体系来屏蔽各种数据类型的差异, 并能能够高效准确的执行. 因为要支持的函数很多, 有一些函数又比较通用, 比如 less, equal 这种函数, 能够根据用户的输出类型自动得去进行比较, 且能够利用到 SIMD 的能力.
整个框架的设计基本和 arrow::Expression::Call 一样, 内部的调度深入到arrow::Kernel 之后还是比较复杂,整个体系用 C++的模版元编程构建起来的, 这一部分非常值得深入学习.
2.4 Operator 算子
这一块是物理执行计划的核心部分, 包括基本的 Filter, Project, TableScan, Agg, Join 等基本算子节点. 这一些算子节点在 Velox 可能会被转换为一个或者多个 Operator 用于实际的执行.
比如 Fiter 之后有一个 Project , 这两个节点会被统一转为 FilterProject operator; 而 HashJoin 这一个节点则会被转为 HashBuild 以及 HashProbe 两个 operator节点.
转为 operator 之后的plan调度是可以并行的, 整个plan的执行方式是 Push, 以 Exchange/TableScan 最为起始节点将读取到的数据以 RowVector为粒度作为输入 Push到下游节点:
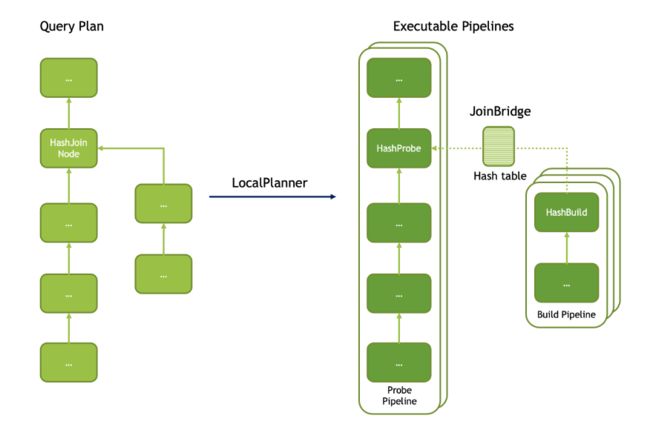
比如上图中 将 HashJoin 的物理计划转为 pipeline 中的多个task 来并发执行, 对于probe端启开启了两个线程, build端开启三个线程来执行.
Build端和Probe端会通过 JoinBridge 进行数据共享, 即probe 读取到的数据可以在 JoinBridge 中找到 build端构建好的 hash 表.
Velox 对于算子的优化也是 利用SIMD, 比如 一般 filter以及project 会和 tablescan 一起用, 列数据 从tablescan 输出前先filter一下, 能够过滤大多数的列. 这个阶段 Filter 可以利用 AVX2 simd 指令集来执行, 一次对多个值进行 filter 检查. 同样的 AVX2优化也可以用在 hashjoin的probe 探测, arrow::Acero 对于hash表的实现采用的是 swisstable, 能够更为高效得利用 simd 指令进行hash匹配. 论文中并没有提 velox 的hash表的实现细节.
2.5 内存管理
这一节主要介绍的是 Velox 本身对内存的管理 以及 IO 上的优化.
内存管理分为两部分:
- plan执行过程中的内存分配和释放. 对于小块的内存会走 C++的new逻辑, 大块内存分配则由自己的 mempool管理. 通过 mmap + madivse 分配大块内存, mempool 也提供了内存分配的追踪, 在plan的执行过程中能够清晰得看到每一个算子的内存资源消耗的情况.
- 算子执行内存不足时的spill 机制. 这也是内存自管理的一个优势, 能够追踪到每一个算子的内存占用情况, 是否需要 走内存溢出的逻辑 或者 内存不足时从其他节点回收内存到当前节点. 内存不足也是服务于超大规模数据分析的场景, 尤其是 sort/join 这样的节点, sort需要对所有的输入数据进行排序, 中间涉及到已经排序的结果无法完全存储到内存中,肯定需要 先临时存储到磁盘,后续使用的时候才重新加载. 基本的数据库都应该支持这样的能力.
IO管理则是说 尽可能得利用 prefetch 从远端存储预取数据来降低 磁盘访问效率和内存访问效率之间的量级差异, 从而保证整个plan operator 的 pipeline 调度不会因为io性能的差异被中断(大家都在等 tablescan 喂数据). 这个过程也会利用 自管理 数据Cache 已经 本地ssd-cache 来缓存远端读取上来的数据, 加速高频数据的访问效率.
3 性能收益
瞅一眼性能收益.
如下数据是 tpch1,6,13,19 这四个query 下的 Prestissimo velox引擎 和 Presto的java引擎对比. 前两个 query 是 cpu密集型的 agg计算 query, 后两个是io密集型的hashjoin+scan query.
测试场景: 80nodes的集群, 每一个节点 64G RAM + 2*2TB-SSD. TPCH 3TB 的 orc格式的数据集.

最终的结果能够看到 Prestissimo 相比于 preso 的java 引擎 整体提升还是非常明显的.
在这个测试场景下 性能瓶颈都不在 velox侧, Q1和Q6 瓶颈在presto的 coordinator 侧, 需要频繁的和多个 worker-nodes 节点交互, 处理元数据. 而 Q13和Q19 瓶颈在数据重分布, 需要有一些数据编码上的优化, 减少 hashjoin 在多个节点之间数据重分布时的数据量传输.
另一个测试则是 启动两个集群,分别是 Prestissimo 和 presto-java, 两个集群压相同的工作负载, 然后慢慢减少 Prestissimo 集群的节点数量. 最后发现 提供相同的工作负载, 基于 velox 的 Prestissimo 能够将服务器数量减少至 presto-java 的 三分之一.
总结
计算引擎的平台化已经成为趋势. Meta/Databricks/Snowflake/Voltron Data/Google 已经都在合作, 诞生了 arrow/duckdb/volex 这样类型的顶级项目,并且是以开源的路线. 就目前看到的收益, 不论是volex 在meta的内部还是datafusion在各个rust 数据库中的应用, 都能在短期内看到明显的收益.
使用这样的项目来构建自己公司的计算平台, 能够以较少的人力和极短的时间构建起来一套性能不差的计算引擎, 这对于初创公司来说简直是好得不能再好的福音. 分析型的市场里 存储这里因为已经有 parquet/orc + arrow 这样完备的存储支撑, 事务在分析场景不是强需求, 可能MVCC就够了, 意味着存储不再是拉开差距的核心. velox 这样的项目又让大家在计算领域(性能)站在同一起跑线…最后 国内分析型数据库/数仓/流/云原生数据库 能够拼市场的还剩下什么呢?
极强的稳定性、极致的用户体验、极多的用户场景(超级数据平台,对接各种系统的数据, 就像velox支持的各种 connectors) 以及 “极强的商务”?