String、StringBuilder、StringBuffer和StringJoiner
String、StringBuilder、StringBuffer和StringJoiner
String详解
-
注意区分对象和对象的引用
首先来看一下我在jdk中找到的String源代码,这里只截取开头的小小一部分
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[]; 从这里可以看出,String类是被final所修饰的,因此String类对象不可变,也不可继承。这里要注意一个误区,字符串对象不可变,但字符串变量所指的值是可变的,即引用地址可变。String变量存储的是对String对象的引用,String对象里存储的才是字符串的值【注意区分对象和对象的引用】。看下面的例子
String str = "abc"; //str是个对象引用
System.out.println(str); //输出abc
str = "abcde"; //不会出错
System.out.println(str); //输出abcde当给str第二次赋值的时候,对象"abc"并没有被销毁,仍存放在常量池中(String自带),只是让str指向了"abcde"的内存地址,而字符串对象"abcde"是新生成的,即str第二次赋值时并不是在原内存地址上修改数据,而是重新指向一个新对象,新地址。记住,对String对象的任何改变都不影响到原对象,相关的任何改变的操作都会生成新的对象。
-
String对象是否真的不可变?!
答案并不是的,那么该如何做呢?那就是使用反射(反射不太懂的可以点击链接学习——反射基础详解)
从上面的源码可知String的成员变量是private final的,也就是初始化之后不可改变。那么在这几个成员中,value比较特殊,因为它是一个引用变量,而不是真正的对象。value是final修饰的,即final不能再指向其他数组对象,那么我想改变value指向的数组时,比如将数组中的某个位置上的字符变为下划线"_"。因为不能直接通过这个引用去修改数组,那么为了访问到至value这个引用,我们可以使用反射来访问私有成员,反射出String对象中的value属性,进而改变value数组的内容。
public static void testReflection() throws Exception {
// 创建字符串"Hello World" 并赋给引用s
String s = "Hello World";
System.out.println("s = " + s); // 打印出Hello World
// 获取String类中的value字段————Field类获取成员变量
Field valueFieldOfString = String.class.getDeclaredField("value");
valueFieldOfString.setAccessible(true); // 改变value属性的访问权限
value[5] = '_'; // 获取s对象上的value属性的值 改变value所引用的数组中的第5个字符
System.out.println("s = " + s); // 打印出Hello_World
}
(此例子参考了博文:https://blog.csdn.net/zhangjg_blog/article/details/18319521)
下面这个例子将引出两个问题
- String str="hello world" 和 String str=new String("hello world") 有什么不同
- 为什么使用 "==" 和 "equals" 会有不同的结果
public static void main(String[] args) {
String str1 = "hello world";
String str2 = new String("hello world");
String str3 = "hello world";
String str4 = new String("hello world");
String str5 = "Hello" + " World";
String str6 = "Hello" + new String(" World");
String str7 = str2.intern();
String ex1 = "Hello";
String ex2 = " World";
String str8 = ex1 + ex2;
System.out.println(str1 == str3); //true
System.out.println(str1 == str2); //false
System.out.println(str2 == str4); //false
System.out.println(str1.equals(str2)); //true
System.out.println(str2.equals(str4)); //true
System.out.println(str1 == str5); //true
System.out.println(str1 == str6); //false
System.out.println(str1 == str7); //true
System.out.println(str1 == str8); //false
}【运行结果】是 true、false、false、true、true、true、false、true、false
先把下面四大点看懂了,我会在最后写出【解析】
-
String的两种赋值方式
※ 区分【String str="HW"】和【String str=new String("HW")】
(1)字面量赋值方式 eg:String str = "Hello";
- 该种直接赋值的方法,JVM会去字符串常量池(String对象不可变)中寻找是否有equals("Hello")的String对象,如果有,就把该对象在字符串常量池中"Hello"的引用复制给字符串变量str,如若没有,就在堆中新建一个对象,同时把引用驻留在字符串常量池中,再把引用赋给字符串变量str。
- 用该方法创建字符串时,无论创建多少次,只要字符串的值(内容)相同,那么它们所指向的都是堆中的同一个对象。
- 该方法直接赋值给变量的字符串存放在常量池里
(2)new关键字创建新对象 eg:String str = new String("Hello");
- 利用new来创建字符串时,无论字符串常量池中是否有与当前值相同的对象引用,都会在堆中新开辟一块内存,创建一个新的对象。
注意:对字符串进行拼接操作,即做"+"运算的时候,分2种情况:
- 表达式右边是纯字符串常量,那么存放在常量池里面。eg:String str = "Hello" + "World";
- 表达式右边如果存在字符串引用,也就是字符串对象的句柄,那么就存放在堆里面。eg:String str = str1 + str2;
总结:常量池是方法区的一部分,而方法区是线程共享的,所以常量池也是线程共享的,且它是线程安全的,它让有相同值的引用指向同一个位置,如果引用值变化了,但是常量池中没有新的值,那么就会新建一个常量结果来交给新的引用,对于同一个对象,new出来的字符串存放在堆中,而直接赋值给变量的字符串存放在常量池里。
-
字符串比较——区分"=="和"equals"
"==":比较引用变量的地址,即两个对象是否引用同一地址的内容,用"=="时会检测是否指向同一个对象
"equals":比较对象的内容,即两个对象内容上是否相同
字符串用这两种比较方式都是可行的,具体看想要比较什么,总体来看,"=="稍微强大些,因为它既要求内容相同,也要求引用对象相同
-
intern() 方法
当使用 intern() 方法时,会先查询字符串常量池是否存在当前字符串,如果存在,则返回常量池中的引用,若不存在,则将字符串添加到字符串常量池中,并返回字符串常量池中的引用。
【代码解析】
str1 == str3——str1与str3指向常量池中同一个对象,引用对象相同,因此用"=="比较时结果为true
str1 == str2——new会创建一个新的对象放在堆中,str1所指对象在常量池,即使str1与str2内容相同,但并不是同一个对象
str2 == str4——new会创建一个新的对象放在堆中,str2与str4指向不同的对象,即使内容相同
str1.equals(str2)——str1于str2各自引用对象不同,但内容相同,因此用"equals"比较时结果为true
str2.equals(str4)——str2于str4各自引用对象不同,但内容相同,因此用"equals"比较时结果为true
str1 == str5——对字符串进行拼接操作("+"运算)时,表达式右边是纯字符串常量,那么存放在常量池里面,若常量池中有该字符串,则返回该引用
str1 == str6——对字符串进行拼接操作("+"运算)时,表达式右边如果存在字符串引用,也就是字符串对象的句柄,那么就存放在堆里面
str1 == str7——intern()方法会去常量池中找是否存在当前字符,存在则返回引用,该对象引用刚好是str1所指向的
str1 == str8——str8由两个变量拼接,编译期不知道它们的具体位置,所以不会做出优化,必须要等到运行时才能确定,因此新对象的地址和前面的不同。
字符串拼接
字符串拼接是我们在Java代码中比较经常要做的事情,就是把多个字符串拼接到一起。
我们都知道,String是Java中一个不可变的类,所以他一旦被实例化就无法被修改。
不可变类的实例一旦创建,其成员变量的值就不能被修改。这样设计有很多好处,比如可以缓存hashcode、使用更加便利以及更加安全等。
但是,既然字符串是不可变的,那么字符串拼接又是怎么回事呢?
字符串不变性与字符串拼接
其实,所有的所谓字符串拼接,都是重新生成了一个新的字符串。下面一段字符串拼接代码:
String s = "abcd";
s = s.concat("ef");
其实最后我们得到的s已经是一个新的字符串了。如下图
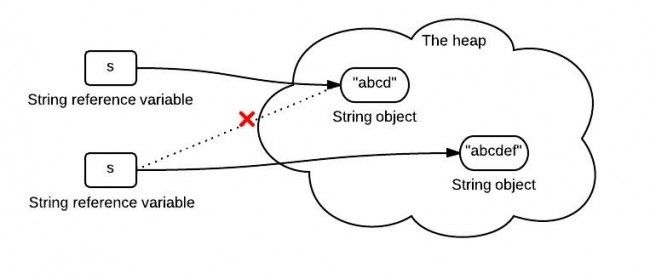 

s中保存的是一个重新创建出来的String对象的引用。
那么,在Java中,到底如何进行字符串拼接呢?字符串拼接有很多种方式,这里简单介绍几种比较常用的。
使用+拼接字符串
在Java中,拼接字符串最简单的方式就是直接使用符号+来拼接。如:
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
String hollis = wechat + "," + introduce;
这里要特别说明一点,有人把Java中使用+拼接字符串的功能理解为运算符重载。其实并不是,Java是不支持运算符重载的。这其实只是Java提供的一个语法糖。后面再详细介绍。
运算符重载:在计算机程序设计中,运算符重载(英语:operator overloading)是多态的一种。运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。
语法糖:语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。
concat
除了使用+拼接字符串之外,还可以使用String类中的方法concat方法来拼接字符串。如:
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
String hollis = wechat.concat(",").concat(introduce);
StringBuffer
关于字符串,Java中除了定义了一个可以用来定义字符串常量的String类以外,还提供了可以用来定义字符串变量的StringBuffer类,它的对象是可以扩充和修改的。
使用StringBuffer可以方便的对字符串进行拼接。如:
StringBuffer wechat = new StringBuffer("Hollis");
String introduce = "每日更新Java相关技术文章";
StringBuffer hollis = wechat.append(",").append(introduce);
StringBuilder
除了StringBuffer以外,还有一个类StringBuilder也可以使用,其用法和StringBuffer类似。如:
StringBuilder wechat = new StringBuilder("Hollis");
String introduce = "每日更新Java相关技术文章";
StringBuilder hollis = wechat.append(",").append(introduce);
StringUtils.join
除了JDK中内置的字符串拼接方法,还可以使用一些开源类库中提供的字符串拼接方法名,如apache.commons中提供的StringUtils类,其中的join方法可以拼接字符串。
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
System.out.println(StringUtils.join(wechat, ",", introduce));
这里简单说一下,StringUtils中提供的join方法,最主要的功能是:将数组或集合以某拼接符拼接到一起形成新的字符串,如:
String []list ={"Hollis","每日更新Java相关技术文章"};
String result= StringUtils.join(list,",");
System.out.println(result);
//结果:Hollis,每日更新Java相关技术文章
并且,Java8中的String类中也提供了一个静态的join方法,用法和StringUtils.join类似。
以上就是比较常用的五种在Java种拼接字符串的方式,那么到底哪种更好用呢?为什么阿里巴巴Java开发手册中不建议在循环体中使用+进行字符串拼接呢?
 

(阿里巴巴Java开发手册中关于字符串拼接的规约)
使用+拼接字符串的实现原理
前面提到过,使用+拼接字符串,其实只是Java提供的一个语法糖, 那么,我们就来解一解这个语法糖,看看他的内部原理到底是如何实现的。
还是这样一段代码。我们把他生成的字节码进行反编译,看看结果。
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
String hollis = wechat + "," + introduce;
反编译后的内容如下,反编译工具为jad。
String wechat = "Hollis";
String introduce = "\u6BCF\u65E5\u66F4\u65B0Java\u76F8\u5173\u6280\u672F\u6587\u7AE0";//每日更新Java相关技术文章
String hollis = (new StringBuilder()).append(wechat).append(",").append(introduce).toString();
通过查看反编译以后的代码,我们可以发现,原来字符串常量在拼接过程中,是将String转成了StringBuilder后,使用其append方法进行处理的。
那么也就是说,Java中的+对字符串的拼接,其实现原理是使用StringBuilder.append。
concat是如何实现的
我们再来看一下concat方法的源代码,看一下这个方法又是如何实现的。
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
这段代码首先创建了一个字符数组,长度是已有字符串和待拼接字符串的长度之和,再把两个字符串的值复制到新的字符数组中,并使用这个字符数组创建一个新的String对象并返回。
通过源码我们也可以看到,经过concat方法,其实是new了一个新的String,这也就呼应到前面我们说的字符串的不变性问题上了。
StringBuffer和StringBuilder
接下来我们看看StringBuffer和StringBuilder的实现原理。
和String类类似,StringBuilder类也封装了一个字符数组,定义如下:
char[] value;
与String不同的是,它并不是final的,所以他是可以修改的。另外,与String不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数,定义如下:
int count;
其append源码如下:
public StringBuilder append(String str) {
super.append(str);
return this;
}
该类继承了AbstractStringBuilder类,看下其append方法:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
StringBuffer和StringBuilder类似,最大的区别就是StringBuffer是线程安全的,看一下StringBuffer的append方法。
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
该方法使用synchronized进行声明,说明是一个线程安全的方法。而StringBuilder则不是线程安全的。
StringUtils.join是如何实现的
通过查看StringUtils.join的源代码,我们可以发现,其实他也是通过StringBuilder来实现的。
public static String join(final Object[] array, String separator, final int startIndex, final int endIndex) {
if (array == null) {
return null;
}
if (separator == null) {
separator = EMPTY;
}
// endIndex - startIndex > 0: Len = NofStrings *(len(firstString) + len(separator))
// (Assuming that all Strings are roughly equally long)
final int noOfItems = endIndex - startIndex;
if (noOfItems <= 0) {
return EMPTY;
}
final StringBuilder buf = new StringBuilder(noOfItems * 16);
for (int i = startIndex; i < endIndex; i++) {
if (i > startIndex) {
buf.append(separator);
}
if (array[i] != null) {
buf.append(array[i]);
}
}
return buf.toString();
}
效率比较
既然有这么多种字符串拼接的方法,那么到底哪一种效率最高呢?我们来简单对比一下。
long t1 = System.currentTimeMillis();
//这里是初始字符串定义
for (int i = 0; i < 50000; i++) {
//这里是字符串拼接代码
}
long t2 = System.currentTimeMillis();
System.out.println("cost:" + (t2 - t1));
我们使用形如以上形式的代码,分别测试下五种字符串拼接代码的运行时间。得到结果如下:
+ cost:5119
StringBuilder cost:3
StringBuffer cost:4
concat cost:3623
StringUtils.join cost:25726
从结果可以看出,用时从短到长的对比是:
StringBuilder<StringBuffer<concat<+<StringUtils.join
StringBuffer在StringBuilder的基础上,做了同步处理,所以在耗时上会相对多一些。
StringUtils.join也是使用了StringBuilder,并且其中还是有很多其他操作,所以耗时较长,这个也容易理解。其实StringUtils.join更擅长处理字符串数组或者列表的拼接。
那么问题来了,前面我们分析过,其实使用+拼接字符串的实现原理也是使用的StringBuilder,那为什么结果相差这么多,高达1000多倍呢?
我们再把以下代码反编译下:
long t1 = System.currentTimeMillis();
String str = "hollis";
for (int i = 0; i < 50000; i++) {
String s = String.valueOf(i);
str += s;
}
long t2 = System.currentTimeMillis();
System.out.println("+ cost:" + (t2 - t1));
反编译后代码如下:
long t1 = System.currentTimeMillis();
String str = "hollis";
for(int i = 0; i < 50000; i++)
{
String s = String.valueOf(i);
str = (new StringBuilder()).append(str).append(s).toString();
}
long t2 = System.currentTimeMillis();
System.out.println((new StringBuilder()).append("+ cost:").append(t2 - t1).toString());
我们可以看到,反编译后的代码,在for循环中,每次都是new了一个StringBuilder,然后再把String转成StringBuilder,再进行append。
而频繁的新建对象当然要耗费很多时间了,不仅仅会耗费时间,频繁的创建对象,还会造成内存资源的浪费。
所以,阿里巴巴Java开发手册建议:循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。而不要使用+。
StringBuilder 和 StringJoiner
要高效拼接字符串,应该使用StringBuilder。
很多时候,我们拼接的字符串像这样:
public class Main {
public static void main(String[] args) {
String[] names = {"Bob", "Alice", "Grace"};
StringBuilder sb = new StringBuilder();
sb.append("Hello ");
for (String name : names) {
sb.append(name).append(", ");
}
// 注意去掉最后的", ":
sb.delete(sb.length() - 2, sb.length());
sb.append("!");
System.out.println(sb.toString());
}
}
输出结果:
Hello Bob, Alice, Grace! 类似用分隔符拼接数组的需求很常见,所以Java标准库还提供了一个StringJoiner来干这个事:
public class Main {
public static void main(String[] args) {
String[] names = {"Bob", "Alice", "Grace"};
StringJoiner sj = new StringJoiner(", ");
for (String name : names) {
sj.add(name);
}
System.out.println(sj.toString());
}
}
输出结果:
Bob, Alice, Grace //注意,和join方法一样,没有前后缀 但是用StringJoiner的结果少了前面的"Hello"和结尾的"!",遇到这种情况,需要给StringJoiner指定“开头”和“结尾”:
public class Main {
public static void main(String[] args) {
String[] names = {"Bob", "Alice", "Grace"}; //第一个为分隔符,第二个参数为字符串前缀,第三个参数为字符串后缀,注意空格
StringJoiner sj = new StringJoiner(", ", "Hello ", "!");
for (String name : names) {
sj.add(name);
}
System.out.println(sj.toString());
}
}
输出结果:
Hello Bob, Alice, Grace! 那么StringJoiner内部是如何拼接字符串的呢?如果查看源码,可以发现,StringJoiner内部实际上就是使用了StringBuilder,所以拼接效率和StringBuilder几乎是一模一样的。
附上源码:


总结
本文介绍了什么是字符串拼接,虽然字符串是不可变的,但是还是可以通过新建字符串的方式来进行字符串的拼接。
常用的字符串拼接方式有五种,分别是使用+、使用concat、使用StringBuilder、使用StringBuffer以及使用StringUtils.join。
由于字符串拼接过程中会创建新的对象,所以如果要在一个循环体中进行字符串拼接,就要考虑内存问题和效率问题。
因此,经过对比,我们发现,直接使用StringBuilder的方式是效率最高的。因为StringBuilder天生就是设计来定义可变字符串和字符串的变化操作的。
但是,还要强调的是:
1、如果不是在循环体中进行字符串拼接的话,直接使用+就好了。
2、如果在并发场景中进行字符串拼接的话,要使用StringBuffer来代替StringBuilder。