c++学习笔记——对象和类()
面向对象编程最重要的特性:
(1)抽象:将问题的本质特征抽象出来,并根据特征来描述解决方案。
(2)封装和数据隐藏
(3)多态
(4)继承
(5)代码的可重用性
c++中的类
概念明确
接口的定义:接口是一个共享框架,供两个系统(例如计算机和打印机或者用户或者计算机程序之间)交互时使用。类,也就是公共接口,公众是使用类的程序,交互系统由类对象组成,而接口由编写类的人提供的方法组成。接口让程序员能够编写与类对象交互的代码,从而让程序能够使用类对象。例如,计算string对象包含多少个字符,无需打开对象,只需要使用string类提供的方法size()。类设计禁止直接公共用户访问类,但是公众可以使用size()。方法size()是用户和string类对象之间的公共接口的组成部分。
c++中一般将接口放在头文件中,并将实现(类方法的代码)放在源代码文件中。
程序10.1
// stock00.h -- Stock class interface
// version 00
#ifndef STOCK00_H_
#define STOCK00_H_
#include
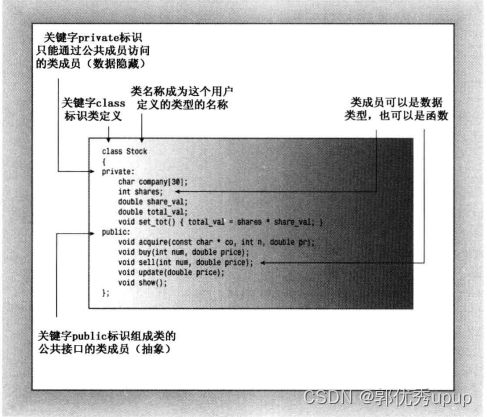
class Stock // class declaration
{
private:
std::string company;
long shares;
double share_val;
double total_val;
void set_tot() { total_val = shares * share_val; }
public://要执行的操作以类函数成员的形式出现,成员函数可以就地定义,也可以用原型表示
//(对于描述接口,函数原型就已经足够了),例如上面的set_tot()
void acquire(const std::string & co, long n, double pr);
void buy(long num, double price);
void sell(long num, double price);
void update(double price);
void show();
}; // note semicolon at the end
#endif 要执行的操作以类函数成员的形式出现,成员函数可以就地定义,也可以用原型表示(对于描述接口,函数原型就已经足够了),例如上面的set_tot()。
访问控制:关键字private和public描述了对类成员的访问控制。使用类对象的程序可以直接访问共有部分,但是只能通过公用成员函数来访问对象的私有成员,公用成员函数是程序和对象的私有成员之间的桥梁,提供了对象和程序之间的接口。无论是类成员是数据成员还是成员函数都可在类共有部分或者私有部分声明它。上面的代码中将函数set_tot()放在了私有部分,不能直接从程序中直接调用它,但共有方法可以使用它。但是由于数据隐藏是oop的主要目标之一,所有我们一般将数据成员放在私有部分,组成接口的成员函数放在公有部分。
由与类对象的默认控制访问控制是private,所以在类声明中关键字private是可选的,可不必显示地声明它。

封装:公有接口表示设计的抽象组件,将实现细节(代码)放在一起,并将它们与抽象分开被称为封装。数据隐藏:将数据放在类的私有部分(关键字private)中,这也是一种封装。将实现的细节隐藏在私有部分中(如上面的set_tot())也是一种封装。
将函数定义和类声明放在不同的文件中也是一种封装。
c++中的专门用来实现oop方法的特性:将数据表示(数据的类型和存储格式)和函数原型放在一个类声明中(注意是一个类中,而不是一个文件中),来使描述成为一个整体。然后让数据表示成为私有(数据隐藏),使得数据只能被授权的函数访问。在上述代码上,如果试图直接访问Stock对象的shares成员就会违反c++语言的规则。原则就是将实现细节(函数定义等)从接口设计中分离出来。如果开发了更好的、实现数据表示或成员函数细节的方法,可以对这些细节进行修改,而无需修改程序接口,这可以使得程序更加方便维护。
实现类成员函数
类的第二部分就是:为在类声明的原型表示的成员函数提供代码。与普通函数的相比它们有两个重要特征:
(1)定义成员函数时,使用作用域解析运算符(::)来标识函数所需的类;
在函数头使用作用域解析运算符来指出函数所需类:例如update()成员函数的函数头可表示如下:
void Stock::update(double price);//其中Stock是类名,update是函数名,这种表示方法可以明确的看出update()函数是Stock的成员,也意味着可以将另一个类中的成员函数命名为update()。
作用域解析运算符确定了方法定义对应的类的身份。标识符update()具有类作用域,Stock的其他成员函数不必使用作用域解析运算符就可以使用update方法。
类方法的完整名称中包括类名。也就是说Stock::update()是函数的限定名,而update()是全名的缩写,它只能在类作用域中使用。
(2)类方法可以访问类的private组件。实例如下:
// stock00.cpp -- implementing the Stock class
// version 00
#include
#include "stock00.h"
void Stock::acquire(const std::string & co, long n, double pr)
{
company = co;
if (n < 0)
{
std::cout << "Number of shares can't be negative; "
<< company << " shares set to 0.\n";
shares = 0;
}
else
shares = n;
share_val = pr;
set_tot();
}
void Stock::buy(long num, double price)
{
if (num < 0)
{
std::cout << "Number of shares purchased can't be negative. "
<< "Transaction is aborted.\n";
}
else
{
shares += num;
share_val = price;
set_tot();
}
}
void Stock::sell(long num, double price)
{
using std::cout;
if (num < 0)
{
cout << "Number of shares sold can't be negative. "
<< "Transaction is aborted.\n";
}
else if (num > shares)
{
cout << "You can't sell more than you have! "
<< "Transaction is aborted.\n";
}
else
{
shares -= num;
share_val = price;
set_tot();
}
}
void Stock::update(double price)
{
share_val = price;
set_tot();
}
void Stock::show()
{
std::cout << "Company: " << company
<< " Shares: " << shares << '\n'
<< " Share Price: $" << share_val
<< " Total Worth: $" << total_val << '\n';
}
程序说明:上面的4个成员函数设置或者重新设置了total_val的值,方法时每次都调用set_tot函数。set_tot()是实现代码的一种方式,不是公有接口的组成部分,所以在这个类中将其声明为私有成员函数,好处是通过使用函数调用,而不是每次都重新输入计算代码,可以确保执行的计算完全相同,另外,如果需要修改代码,只需在一个地方修改。
内联方法:
函数定义位于类声明中的函数都自动为内联函数。如果想让在类声明之外定义其成员函数为内联函数,只需要在类实现部分定义函数时使用inline限定符即可。前面的笔记中有说过内联函数要求每个使用它的文件都对其进行定义,所以一般将内联函数的定义(而不只是原型)放在头文件中。

方法使用那个对象
创建类对象的方法,语法如下:
类名 对象名;
如何使用对象的成员函数,使用成员语运算符(.)例如:
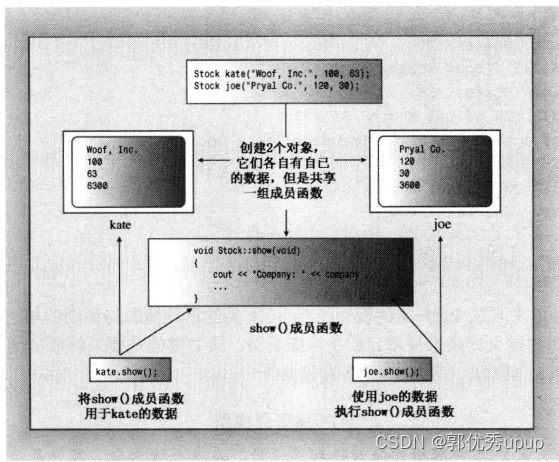
kate.show();//这条语句调用了kate对象的show()成员。这就意味着show()方法将把shares解释为kate.shares,将share_vla解释为kate.share_val。注意:在调用函数时,它将使用被用来调用它的对象的数据成员。
创建的每个对象都有自己的存储空间,用于存储器内部变量和类成员;但是同一个类的所有对象共享同一组方法,也就是说每个方法只有一个副本。例如,kate和joe都是Stock对象,则kate.show()和joe.show()都调用同一个方法,也就是说它们执行同一个代码块,只是将代码块用于不同的数据。但是kate.shares将占据一个代码块,joe.shares占用另一个代码块。
使用类
程序10.3
// usestok0.cpp -- the client program
// compile with stock.cpp
#include
#include "stock00.h"
int main()
{
Stock fluffy_the_cat;
fluffy_the_cat.acquire("NanoSmart", 20, 12.50);
fluffy_the_cat.show();
fluffy_the_cat.buy(15, 18.125);
fluffy_the_cat.show();
fluffy_the_cat.sell(400, 20.00);
fluffy_the_cat.show();
fluffy_the_cat.buy(300000, 40.125);
fluffy_the_cat.show();
fluffy_the_cat.sell(300000, 0.125);
fluffy_the_cat.show();
// std::cin.get();
return 0;
}
客户/服务器模型
客户只能以公用方式定义的接口使用服务器,这就意味着客户(客户程序员)唯一的责任是了解该接口。服务器(服务器设计人员)的责任是确保服务器根据接口可靠并准确地执行。服务器设计人员只能修改类设计的实现细节,而不能修改接口。这样程序员可单独的对客户和服务器进行改进,对服务器的修改不会对客户的行为造成意外的影响。
修改实现
在程序运行过程中,有些地方可能不满意,例如前面的程序数字的格式不一致,现在可以改进实现,但保持接口不变。
例如在可以在使用cout对象时使用其方法setf(),便可避免科学计数法:
std::cout.setf(std::ios_base::fixed, std::ios_base::floatfield);//这行代码设置了cout对象的一个标记,命令cout使用定点表示法。
同样在上面的程序中,可在方法show( )中使用这些工具来控制格式信息,但是还有一点需要考虑,修改方法的实现时,不应影响客户程序的其他部分,修改后将一直有效直到再次修改它,因此它们可能会影响客户程序中的后续输出。因此,使其恢复到自己被调用前的状态。所以可在实现文件中将方法show()的定义修改成下面这样:
void Stock::show()
{
using std::cout;
using std::ios_base;
ios_base::fmtflags orig =
cout.setf(ios_base::fixed, ios_base::floatfield);
std::streamsize prec = cout.precision(3);
cout << "Company: " << company
<< " Shares: " << shares << "\n";
cout << "Total Worth : $ " << total_val << "\n";
cout.setf(orig, ios_base::floatfield);
cout.precision(prec);
}程序解释:fmtflags是在ios_base类中定义的一种类型,而ios_base是在名称空间std中定义的,因此orig的类型名很长。其次,orig存储了所有的标记,而重置语句使用这些信息来重置floatfield。而floatflied包含定点表示法标记和科学计数法标记。具体细节在后面的章节中有具体介绍。
这里的最重要的要点是:将修改限制在实现文件中,以免影响程序的其他部分。
修改后的输入如下:
Company: NanoSmart Shares: 20
Total Worth : $ 250.000
Company: NanoSmart Shares: 35
Total Worth : $ 634.375
You can't sell more than you have! Transaction is aborted.
Company: NanoSmart Shares: 35
Total Worth : $ 634.375
Company: NanoSmart Shares: 300035
Total Worth : $ 12038904.375
Company: NanoSmart Shares: 35
Total Worth : $ 4.375小结:
指定类设计的步骤:
第一步:提供类声明
类声明类似于结构声明,可以包括数据成员和函数成员。声明私有部分,在其中声明的成员只能通过成员函数进行访问。声明还具有公有部分,在其中声明的成员可被使用类对象的程序直接访问。
典型的类声明格式如下:
class MyClass
{
public:
data member declarations;
private:
member function prototypes;
};
其中,公有部分的内容构成了设计的抽象部分——公有接口。
将数据封装到私有部分可以保护数据的完整性,这被称为数据隐藏。
所以,c++通过类使得实现抽象、数据隐藏和封装定等oop特性很容易。
第二步:实现类成员函数
可以在类声明中提供完整的函数定义,而不是函数原型,但是通常的做法是单独提提供函数定义(除非这个函数很小)。
单独提供函数定义时,需要使用作用域运算符来指出成员函数属于那个类。
例如char * Bozo:: Retort();
意为Retort()不仅仅是一个char*类型的函数(返回值是char*类型),而且是一个属于Bozo类的函数。
该函数的全名(或限定名)是Bozo::Retort()。名称Retort是缩写,缩写只能在特定的环境(例如类方法的代码)中使用。 也就说可使用名称Retort的作用域是整个类,在类声明和类方法之前使用时必须使用作用域解析运算符进行限定。
第三步:创建对象(类的实例)
要创建对象,只需将类视为类型名即可,例如:
Bozo bozetta;
第四部:调用类方法
类成员函数(方法)可通过类对象来调用,可以通过类对象使用成员运算符句点:
cout << Bozetta.Rotort();类的构造函数和析构函数
构造函数
为啥要构造函数
需要构造函数的原因:可以是用户定义的类像初始化int或者结构那样来初始化类对象。没有这个函数,像下面这样初始化Stock对象hot会出现汇编错误:
Stock hot = {"Sukie's Autos, Inc.", 200, 50.25};原因是数据部分的访问状态是私有的,这意味着程序不能直接访问数据成员。程序只能通过成员函数来访问数据成员,所以需要设计合适的成员函数,才能像成功地将对象初始化(这里需要注意的一点是如果数据成员成为公有,那而不是私有,就可以按照上面代码行所示的方法初始化,但是它违背的类的一点初衷,那就是数据隐藏)。
声明和定义构造函数
类构造函数定义:专门用于构造新对象、将值赋给它的数据成员。
声明类构造函数:例如上面的Stock类,要创建它的构造函数,需要为构造函数提供3个参数(由于total_val()是根据shares和share_val计算得来的,所以不需要为构造函数提供这个值)。这里只设置了compay成员,把其他的两个成员设置为0(详见第八章,使用默认参数即可)。所以它的原型如下:
Stock(const string & co, long n = 0, double pr = 0.0);这里的Stock()是Stock类的成员函数(充当类的构造函数),第一个参数是字符串的引用,用于初始化成员company。n和pr参数为shares和share_val成员提供值。
注意,没有返回值。原型位于类声明的公有部分。
下面是构造函数的一种可能定义:
Stock::Stock(const string& co, long n, double pr)
{
company = co;
if (n < 0)
{
std::cerr << "Number of shares can't be negative; "
<< company << " shares set to 0.\n ";
shares = 0;
}
else
shares = n;
share_val = pr;
set_tot();
}上面的代码和前面代码中的acquire()基本相同,区别就是程序声明对象时会自动调用构造函数。
注意:不能使用将类成员名称用作构造函数的参数名,例如:
Stock :: Stock(const string & company, long shares, double share_val)
{
……
}上面这样是错误的,构造函数的参数表示的不是类成员,而是赋给类成员的值。所以参数名不能与类成员相同。
为了避免混乱,一种常见的做法是在数据成员名中使用m_前缀。另一种常见的做法是在数据成员中使用后缀_。就像下面这样:
class Stock
{
public:
string m_company;
long m_shares;
……或者:
class Stock
{
public:
string company_;
long shares_;
……这样就可以在公有接口中在参数名中包含company和shares。
使用构造函数
有两种使用构造函数来初始化对象的方法:
第一种:显式地调用构造函数:
Stock food = Stock("World Cabbage", 250, 1.25);//这里就是将food对象的company成员设置成字符串"World Cabbage",将shares成员设置成250,等等
第二种:隐式地调用构造函数
Stock garment("Furry Mason", 50, 2.5);
每次创建类对象(甚至使用new动态分配内存)时,c++都使用类构造函数,例如:
Stock *pstock = new Stock("Electroshock games", 18, 19.0);
//这条语句创建了一个Stock对象,并将其初始化为参数提供的值,并将该对象的地址赋给pstock指针。这种情况下,虽然对象没有名称,但是可以使用指针来管理对象,在后面的指针对象中会进一步讨论。
一般来说使用对象来调用其他类方法,但是无法使用对象来调用构造函数,因为在构造函数构造出对象前,对象时不存在的。
默认构造函数
定义:在未提供显式初始值时,用来创建对象的构造函数。
在上面的程序4.3中语句
Stock fluffy_the_cat;就是这样做的,在程序10.1中函数声明中没有提供构造函数,这条语句的管用之处就是如果没有提供任何构造函数,c++将自动提供默认构造函数。它是默认构造函数的隐式版本,不做任何工作。它只是创建了fluffy_the_cat对象,但是不初始化其成员,和int x这个语句的作用类似。
需要注意一点,只有当没有任何构造函数时,编译器才会提供自动构造函数。
为类定义了构造函数,程序员就必须为它提供默认构造函数。
如果提供了非默认构造函数,但是没有提供默认构造函数,使用下列声明将会出错:
Stock stock1;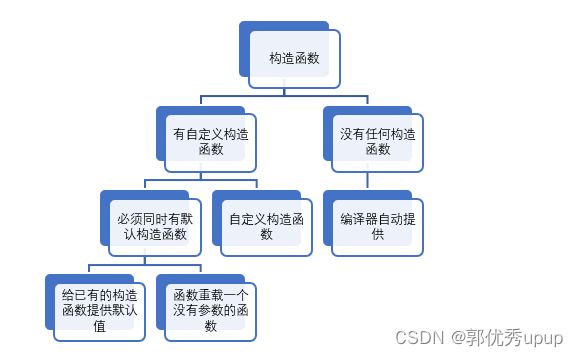
这样做的原因是禁止创建未初始化的对象。想要创建对象,但是不显式的初始化它,就必须定义一个不接受任何参数的默认构造函数。
定义默认构造函数的两种方式:
第一种:给已有的构造函数的所有参数提供默认值,如下:
Stock(const string &co = ""Error", int n = 0; double pr = 0.0); 第二种:通过函数重载来定义另一个构造函数——一个没有参数的构造函数:
Stock(const string &co, int n ; double pr);
Stock();上述代码中第二行通过与第一行的构造函数函数重载定义了一个没有任何参数的构造函数。

上面两种方式,需要注意的是只能有一个默认构造函数,所以不能同时采用两个这两种方式,一般来说,应该初始化所有的对象,以确保所有成员一开始就有合理的值,所以用户定义的默认构造函数通常给所有的成员提供隐式初始值。
使用上述任何一种方式(没有参数或所有参数都有默认值)创建了默认构造函数后,就可以声明对象并且不对其进行显式初始化。


析构函数
作用:构造函数创建完对象后,程序负责跟踪该对象,直到其过期为止,对象过期后,程序将自动调用析构函数。
什么时候创建:当构造函数使用new来分配内存,则析构函数将使用delete来释放这些内存。没有使用new,因此析构函数实际上没有需要完成的任务。这种情况下,只需让编译器生成一个什么都不做的隐式析构函数即可。
析构函数的名称是在类名前加一个~;例如Stock类的析构函数为~Stock(),另外,和构造函数一样,析构函数也可以没有返回值和声明类型。析构函数没有参数,因此Stock析构函数的原型必须是这样的:
~Stock();
由于Stock的析构函数不承担任何工作,所以编写它为不执行任何话操作的函数:
Stock :: ~Stock()
{
}如果想看到析构函数何时被调用,可以想下面这样来编写代码:
Stock::~Stock()
{
cout << "Bye, " <
何时调用析构函数:
调用析构函数的时间是由编译器决定的,一般情况下不在代码中显式地调用它(例外情况是使用new)。
如果创建的是静态存储类型,则其析构函数将在程序结束时自动被调用。
如果创建的是自动存储类对象,则析构函数将在程序执行完成代码块(包含该类对象)时自动被调用。
如果对象时通过new创建的,则它将驻留在栈内存或者自由存储区中,当使用delete来释放内存时,其析构函数将自动被调用。
当类对象过期时析构函数将自动被调用,所以必须得有一个析构函数,当开发人员没有提供析构函数,编译器将隐式地声明一个默认析构函数,并在发现导致对象被删除的代码后,提供析构函数的定义。
基于上面的介绍,可以对Stock类进行改造:
改进Stock
头文件:
// stock10.h —— Stock class declaration with constructors, destructor added
#ifndef STOCK1_H_
#define STOCK1_H_
#include
class Stock
{
private:
std::string company;
long shares;
double share_val;
double total_val;
void set_tot() { total_val = shares * share_val; }
public:
Stock(); // default constructor
Stock(const std::string & co, long n = 0, double pr = 0.0);
~Stock(); // noisy destructor
void buy(long num, double price);
void sell(long num, double price);
void update(double price);
void show();
};
#endif
实现文件:
// stock1.cpp ?Stock class implementation with constructors, destructor added
#include
#include "stock10.h"
// constructors (verbose versions)
Stock::Stock() // default constructor
{
std::cout << "Default constructor called\n";
company = "no name";
shares = 0;
share_val = 0.0;
total_val = 0.0;
}
Stock::Stock(const std::string & co, long n, double pr)
{
std::cout << "Constructor using " << co << " called\n";
company = co;
if (n < 0)
{
std::cout << "Number of shares can't be negative; "
<< company << " shares set to 0.\n";
shares = 0;
}
else
shares = n;
share_val = pr;
set_tot();
}
// class destructor
Stock::~Stock() // verbose class destructor
{
std::cout << "Bye, " << company << "!\n";
}
// other methods
void Stock::buy(long num, double price)
{
if (num < 0)
{
std::cout << "Number of shares purchased can't be negative. "
<< "Transaction is aborted.\n";
}
else
{
shares += num;
share_val = price;
set_tot();
}
}
void Stock::sell(long num, double price)
{
using std::cout;
if (num < 0)
{
cout << "Number of shares sold can't be negative. "
<< "Transaction is aborted.\n";
}
else if (num > shares)
{
cout << "You can't sell more than you have! "
<< "Transaction is aborted.\n";
}
else
{
shares -= num;
share_val = price;
set_tot();
}
}
void Stock::update(double price)
{
share_val = price;
set_tot();
}
void Stock::show()
{
using std::cout;
using std::ios_base;
// set format to #.###
ios_base::fmtflags orig =
cout.setf(ios_base::fixed, ios_base::floatfield);
std::streamsize prec = cout.precision(3);
cout << "Company: " << company
<< " Shares: " << shares << '\n';
cout << " Share Price: $" << share_val;
// set format to #.##
cout.precision(2);
cout << " Total Worth: $" << total_val << '\n';
// restore original format
cout.setf(orig, ios_base::floatfield);
cout.precision(prec);
}
客户文件:
// usestok1.cpp -- using the Stock class
// compile with stock10.cpp
#include
#include "stock10.h"
int main()
{
{
using std::cout;
cout << "Using constructors to create new objects\n";
Stock stock1("NanoSmart", 12, 20.0); // syntax 1
stock1.show();
Stock stock2 = Stock ("Boffo Objects", 2, 2.0); // syntax 2
stock2.show();
cout << "Assigning stock1 to stock2:\n";
stock2 = stock1;
cout << "Listing stock1 and stock2:\n";
stock1.show();
stock2.show();
cout << "Using a constructor to reset an object\n";
stock1 = Stock("Nifty Foods", 10, 50.0); // temp object
cout << "Revised stock1:\n";
stock1.show();
cout << "Done\n";
}
// std::cin.get();
return 0;
}
输出:
Using constructors to create new objects
Constructor using NanoSmart called
Company: NanoSmart Shares: 12
Share Price: $20.000 Total Worth: $240.00
Constructor using Boffo Objects called
Company: Boffo Objects Shares: 2
Share Price: $2.000 Total Worth: $4.00
Assigning stock1 to stock2:
Listing stock1 and stock2:
Company: NanoSmart Shares: 12
Share Price: $20.000 Total Worth: $240.00
Company: NanoSmart Shares: 12
Share Price: $20.000 Total Worth: $240.00
Using a constructor to reset an object
Constructor using Nifty Foods called
Bye, Nifty Foods!
Revised stock1:
Company: Nifty Foods Shares: 10
Share Price: $50.000 Total Worth: $500.00
Done
Bye, NanoSmart!
Bye, Nifty Foods!
程序说明(回顾之前的知识点):
创建对象的两种句法:
第一种: Stock stock1("NanoSmart", 12, 20.0); //隐式地调用构造函数
第二种: Stock stock2 = Stock ("Boffo Objects", 2, 2.0);//显式地调用构造函数,可以理解为程序先创建了一个临时对象(等号右边),然后将临时对象复制到stock2中,并丢弃它。需要注意的是如果使用这种方法,那么编译器也会给临时对象调用析构函数,所以有时它的输出是下面这样的:
Constructor using Boffo Objects called
Bye, Boffo Objects
Company: Boffo Objects Shares: 2
上面的输出代码块中和这里不一样,因为有的编译器可能立即删除对象,但也有可能需要等一会。
stock2 = stock1;
这条语句的表明可以将一个对象赋给同类型的另一个对象。这是stock2原本的内容将会被覆盖。在默认情况下,c++将源对象的每个数据成员的内容复制到目标对象中相应的数据成员中。
stock1 = Stock("Nifty Foods", 10, 50.0);
stock1对象已经存在,所以这条语句不是对stock1进行初始化,而是将新的值赋给它。此时构造函数将会创建一个新的、临时的对象(等号右边的作用),然后将其新的值复制给stock1来实现的。然后程序会调用析构函数来删除这个临时对象,所以它的输出是这样的:
Using a constructor to reset an object
Constructor using Nifty Foods called //临时对象创建
Bye, Nifty Foods! //临时对象删除
Revised stock1:
Company: Nifty Foods Shares: 10 //数据已经别复制到stock1
Share Price: $50.000 Total Worth: $500.00
由于自动变量被放在栈中,栈的规则是“先进后出”,也就是后进来的先被删除,这里由于"NanoSmart"最初位于stock1中,但是随后被传输到stock2中,然后被重置为"Nifty Foods")
也就是说NanoSmart数据最先被创建(被放在栈中),stock1最先和它关联,然后stock2再和它关联,具体参考之前的笔记中的图片。
Done
Bye, NanoSmart!
Bye, Nifty Foods!
c++11列表初始化
在c++11中可以使用列表初始化,,主要提供与参数列表匹配的内容,并用大括号括起来即可。

6.const成员函数
const Stock land = Stock{"Kludgehorn Properties"};
land.show();
上面的代码中编译器会拒绝第二行,是因为show()的代码可能会修改调用对象——调用对象和const一样,不能被修改。

构造函数和析构函数小结:
构造函数时一种特殊的类成员,在创建类对象时被调用。构造函数的名称和类名应该相同。
可以通过函数重载创建多个同名的构造函数,但是前提是每个函数的特征标(也就是参数列表)不同。另外,构造函数没有声明类型(也就是不需要声明返回值类型)。一般来说,构造函数用于初始化类对象的成员,初始化应该与构造函数的参数列表匹配。

如果构造函数只有一个参数,则将对象初始化一个与参数的类型相同的值时,该构造函数将被调用。例如下面是一个构造函数的原型:
cout << trip;
注:接受一个参数的构造函数允许使用赋值语法将对象初始化成一个值。
则可以使用下面的任何一种形式来初始化对象:
 上面的第三种方式 Classname object = value;//是新内容,在第11章会具体介绍,这种特性可能会导致问题,可以关闭这项特性。
上面的第三种方式 Classname object = value;//是新内容,在第11章会具体介绍,这种特性可能会导致问题,可以关闭这项特性。
默认构造函数没有参数,因此如果创建对象时没有显式的初始化,将调用默认构造函数,
如果程序中没有提供任何构造函数,则编译器就会为程序定义一个默认构造函数;
或者自己提供默认构造函数,默认构造函数可以没有任何参数,如果想提供参数,那么就必须给所有参数提供默认值。
Bozo();//以函数重载的方式来定义默认构造函数
Bistro(const char * s = "Chez Zero");//给已有的构造函数提供默认值来构建默认的构造函数
有了默认构造函数。对于未被初始化的对象,程序将使用默认构造函数来创建。
当对象被删除时,程序将调用析构函数,每个类只能有一个析构函数,析构函数没有返回类型(连void都没有),也没有参数。名称的命名规则是在类名称前面加上~。如果构造函数使用了new,就必须提供使用delete的析构函数。
this指针
作用:当一个类的方法(成员函数)涉及到两个对象时,这种情况下就需要使用this指针。
示例:定义一个成员函数,它查看两个Stock对象,并返回股价较高的那个对象的引用。
第一种方式:
是让方法返回一个值,一般使用内联代码:

程序解读:在倒数第三行代码中,函数参数列表(也就是括号)后面的const的意思是:只有类的非静态成员函数后可以加const修饰,表示该类的this指针为const类型,不能改变类的成员变量的值,即成员变量为read only(有例外情况),任何改变成员变量的行为均为非法。此类型的函数可称为只读成员函数,格式为:
returnType functionName(param list) const
就程序访问而言,上面定义实际上是使得total_val为只读。也就是说可以使用方法total()来获取total_val这个值,但是没有提供专门用于重新设置total_val的值的方法。
第二种方式:
定义一个成员函数,它查看两个Stock对象,并返回股价较高的那个对象的引用,这需要使用到this指针。
代码如下:
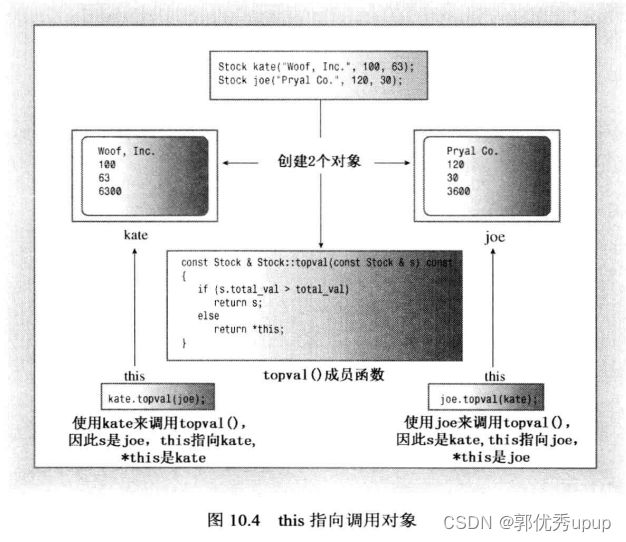
const Stock & Stock::topval(const Stock & s) const
{
if(s.total > total_val)
return s;
else
return *this;
}
程序解释:
将方法命名为topval,函数调用stock1.topal()将访问stock1对象的数据,而stock2.topval()将访问stock2对象的数据。将第二个对象作为参数传递给它,可以按引用来传递参数,这样效率高, 所以方法topval()方法的参数类型时const Stock &。将比较后的答案返回,最直接的方法是让方法返回一个引用,该引用指向股价总值较高的对象。所以函数原型:
const Stock & topval(const Stock & ) const;
该函数隐式的访问一个对象,而显式的访问另一对象,并且返回其中一个对象的引用。括号中的const表明该函数不会修改显式地访问的对象,而括号后面的const表明,该函数不会修改隐式地访问的对象。由于
函数返回了两个const对象之一的引用,所以返回类型应该是const引用。
假设要对Stock的对象stock1和stock2进行比较,并将其中股价总值较高的那一个赋给top变量,则可以使用以下的语句之一:
top = stock1.topval(stock2);//调用函数的对象是stock1
top = stock2.topval(stock1);
第一种就是隐式地访问stock1,而显式地访问stock2;第二个就是隐式地访问stock2,而显式地访问stock1。无论将那一种方式,都是返回股价总值较高的那一个。
关于return *this指针的解释:当s.total_val是作为参数传递的对象(显示调用)的总值,而total_val是用来调用该方法的对象(隐式调用)的总值。当s.total_val大于tota_val,则函数返回指向s的引用,否则就返回用来调用该方法的对象,但是问题就在于这个对象该如何称呼,解决的方案就是使用别称为this的指针,this指针指向用来调用成员函数的对象(this作为被作为隐藏参数传递给方法)。例如,语句stock1.topval(stock2);将this指针设置为stock1对象的地址,使得这个指针可用于topval()方法。
一般来说,所有的类方法都将this指针设置为调用它的对象的地址。所以topval()函数体中的total_val只不过是this->total_val的简写。(关于符号->运算符,通过指针来访问结构成员,同样也适用于类成员)。
注意:每个函数(包括构造函数和析构函数)都有一个this指针。this指针都指向调用对象。
如果方法需要引用整个调用对象,可以使用表达式*this(就像上面语句return *this;)。
在函数的括号后面使用const限定符将this限定为const,这样就不能使用this来修改对象的值。
因为要返回的并不是this,因为this是对象的地址,而是对象本身,即*this(将解除引用运算符*用于指针,将得到指针指向的值)。
对象数组
作用:当用户像创建同一个类的多个对象,可以单独的创建多个对象,也可以创建对象数组。
声明对象数组的方式与声明标准数组的方式相同,例如:
Stock mystuff[4];
上述语句创建了一个包含4个Stock类对象的数组。
每个元素(mystuff[0]、mystuff[1]等)都是Stock对象,可以使用Stock方法,例如:
mystuff[].update();
可以用构造函数来初始化数组元素,在这种情况下,必须为每个元素调用构造函数,例如:
const int STKS = 4;
Stock stocks[STKS] = {
Stock("NansSmart", 12.5, 20),
Stock("Boffo Object", 200, 2.0),
Stock("Monolithic Obelisks", 130, 3.25),
Stock("Fleep Enterprises", 60, 6.5)
};
上面的代码使用标准格式对数组进行初始化:用括号括起的、以逗号分隔的值列表。其中,每次构造函数调用表示一个值。 如果类包含多个构造函数,则可以对不同的元素使用不同的构造函数。就像下面这样:
const int STKS = 10;
Stock stocks[STKS] = {
Stock("NansSmart", 12.5, 20),
Stock(),
Stock("Monolithic Obelisks", 130, 3.25),
};
使用Stock(const string & co, long n, double pr)初始化stock[0]和stock[2],使用构造函数Stock()初始化stock[1]。这里初始化了前三个元素,剩下的7个元素将使用默认构造函数进行初始化。
初始化对象数组的过程是
第一步:先使用默认构造函数创建数组元素
第二步:花括号中的构造函数将创建临时对象
第三步:将临时对象的内容复制到相应的元素。
所以创建对象数组,这个类就必须有默认构造函数。
类作用域
定义:在类中定义的名称(如类数据成员名和类成员函数名)的作用域都为整个类,作用域为整个类的名称只在该类中是已知的在,在类外是不可知的。所以在不同类中使用相同的类成员名是不会引起冲突。同时,类作用域意味着不能从外部直接访问类的成员,公有成员函数也是这样。要调用公有成员函数,就必须通过对象。
class IK
{
private:
int fuss;
public:
IK(int f = 9) { fuss = f; }
void ViewIK() const;
};
void IK::ViewIK() const
{
cout << fuss << endl;
}
……
int main()
{
IK* pik = new IK;
IK ee = IK(8);
ee.ViewIK();
pik->ViewIK();
……
在类声明或者成员函数定义中,可以使用未修饰的成员函数,就像前面的sell()调用set_tot()成员函数时那样。这里函数ViewIK()使用变量fuss。
构造函数名称在被调用时,才能被识别,因为它的名称和类名相同。
在其他情况下,使用类成员名时,必须根据上下文使用直接成员运算符(.)、间接成员运算符(->)或者作用域解析运算符(::)。
这里回顾下前面笔记中的间接成员运算符(->):
由于使用new创建动态结构时,没有名称,只知道它的地址,所以不能将成员运算符句点应用于结构名,应该使用箭头成员运算符(->)。格式就是指针变量->成员名;
这里的语句IK* pik = new IK;这里就是创建了一个未命名的IK类对象,并将其地址赋值给pik指针变量,把足以存储IK类的一块可用内存的地址赋给pik。
语句 pik->ViewIK();就相当于常规情况下的(类对象.类成员函数),这里的间接成员运算符就相当于常规情况下的句点运算符(.)。
//使用new创建动态结构
#include
struct inflatable
{
char name[20];
float volumn;
double price;
};
int main()
{
using namespace std;
//使用new创建动态结分两步,第一步;创建结构时,要同时使用new和结构类型
//这里就是创建了一个未命名的inflatable类型,并将其地址赋值给ps指针变量
inflatable * ps = new inflatable;
//把足以存储inflatable结构的一块可用内存的地址赋给ps
cout << "Enter name of inflatiable item: ";
//由于使用new创建动态结构时,没有名称,只知道它的地址,所以不能将成员运算符句点应用于结构名
//应该使用箭头成员运算符(->),如下
cin.get(ps->name, 20);
//ps指向一个inflatable结构,则ps->name是被指向的结构的成员
//如果结构标识符是结构名,则使用句点运算符,如果标识符是指向指针结构的指针,则使用箭头运算符
cout << "Enter volumn in cubic feetd: ";
//另一种访问结构成员的方法时,ps是指向就结构的指针,则*ps就是被指向的值——结构本身。所以*ps就是一个结构,例如可使用(*ps).volumn
cin >> (*ps).volumn;
cout << "Enter price : $";
cin >> ps->price;
cout << "Name: " << (*ps).name <volumn << " cubic feet\n";
cout << "Price: " << ps->price << endl;
delete ps;
return 0;
}
作用域为类的常量
首先示例错误做法

这样做是错误的,因为类声明只是描述了对象的形式,并没有创建对象,所以在创建对象之前,没有存储值的空间,现在有两种方式可以解决:
第一种方式:利用枚举
在类中声明一个枚举:在类中声明的枚举作用域是整个类。所以可以用枚举为整型常量提供作用域为整个类的符号名称。
class Bakery
{
private:
enum {Months = 12 };
double const{ Months };
……
解读:用这种方式声明枚举并不会创建类数据成员。也就是说,所有对象中都不包含枚举,Months只是一个符号名称(也就是说这里使用枚举的作用只是为了创建一个符号常量,并不打算创建枚举类型的变量,所以不需要提供枚举名),在作用域为整个类的代码中遇到它时,编译器会用12来替代它。
这里回顾下枚举的有关知识:enum是创建符号常量的方式,这种方式可以替代const,如果只打算使用常量,而不创建枚举类型的变量,则可以省略枚举类型的名称,就像上面的enum {Months = 12}
扩展:在很多实现中,ios_base类在其公有部分中完成了类似的工作,例如ios_base::fixed等标识符,其中fixed就是ios_base类中定义的典型的枚举量。将默认情况下,将整数值赋给枚举量(但并非枚举类型就是整型,只是每个每个枚举量都对应一个整数值)。枚举量是整型,可以被提升成整型
第二种方式:使用关键字static
class Bakery
{
private:
static const int Months = 12;
double costs[Months];
……
这里创建了一个名为Months的常量,该常量将与其他静态变量存储在一起,而不是存储在对象中。所以只有一个Months常量,被所有Bakery对象共享。
这里回顾下静态连续性和无链接性的内容:在代码块中使用static时,将局部变量的存储连续性为静态,这就意味着该变量只能在该代码块中使用,但它区别于自动存储的是,它在该代码块不处于活动状态时仍然存在。此外,如果初始化了静态局部变量,则程序只在启动时进行一次初始化。
作用域内枚举
传统的枚举在两个枚举定义中的枚举量可能会发生冲突,例如:

上面egg Small和t_shirt Small位于相同的作用域内,会发生冲突。为了解决这个问题,c++
11中提供了一种新枚举,其枚举量的作用域为类。这种枚举的声明格式如下:
enum class egg {Small, Medium, Large, Jumbo};
enum class t_shirt {Small, Medium, Large, Xlarge};
也可以使用关键词struct代替class,但是无论使用那种形式,使用时都需使用枚举名来限定枚举量。例如:
egg choice = egg::Large;
t_shirt Floyd = t_shirt::Large;
枚举量是作用域是类后,不同枚举定义中的枚举量就不会发生名称冲突。
通常情况下,常规枚举量将自动转换成整型,可以将其赋给int变量或者用于比较表达式,这个前面的笔记中有介绍。但是作用域内的枚举量不能隐式地转换成整型。
但必要时可以进行强制类型转换,例如
int Frodo = int(t_shirt :: Small);//这行代码将Frodo设置为0
enum egg_old {Small, Medium, Large, Jumbo}; //常规枚举
enum class t_shirt {Small, Medium, Large, Xlarge}; //在类作用域中声明的枚举
egg_old one = Medium; //定义一个egg_old类型的常规枚举变量one,并将Medium赋给它,Medium和one可提升为整型2
t_shirt rolf = t_shirt :: Large;//定义一个t_shirt类型的类作用域枚举变量rolf,并将Large赋给它,但Large和rolf不能提升为整型2
int king = one; //常规的枚举变量可以被提升为整型
int ring = rolf;//error,作用域内的枚举变量不能被提升为整型
if (king < Jumbo) //常规枚举量可以被提升成整型,并且将其用于比较表达式
std::cout << "Jumbo converted to int before comparison.\n";
if (king < t_shirt::Medium) //作用域内的 枚举量不可以被提升为整型,并且不能将其用于比较表达式
std::cout << "Not allow : < not defined for scope enum.\n";
虽然经过上面的介绍,在作用域内定义的枚举量不能隐式(自动)转换成整型,但是在c++
11中作用域内枚举的底层类型还是int型。另外还提供一种语法来进行选择:
enum class : short pizza {Small, Medium, Large, XLarge};
其中:short将底层类型指定为short,注意底层必须为整型。在c++中,也可以使用这种语法来指定常规枚举的底层类型,但是如果没有指定,那么编译器选择的底层类型就随实现而异。
小结
面向对象编程强调的是程序如何表示数据。使用OOP方法解决编程问题的第一步时根据它与程序之间接口来描述数据,从而指定如何使用数据。然后设计一个类来实现该接口。类中,私有数据成员存储信息,公有成员函数提供访问数据的唯一途径。类将数据和方法组合成一个单元,其私有性实现数据隐藏。
将类声明分成两部分,两部分分别保存在不同的文件中,类声明应放在头文件中,定义成员函数的源代码放在方法文件中。这样就可以将接口描述和实现细节分开。从理论上讲,只需要知道公有接口就可以使用类(当然可以查看实现细节,但是程序不应该依赖于实现细节)。