Python机器学习12——神经网络
本系列所有的代码和数据都可以从陈强老师的个人主页上下载:Python数据程序
参考书目:陈强.机器学习及Python应用. 北京:高等教育出版社, 2021.
本系列基本不讲数学原理,只从代码角度去让读者们利用最简洁的Python代码实现机器学习方法。
本节开始机器学习中最强大的神经网络方法。神经网络有专门的深度学习领域,也是我之后会开设专门的深度学习领域的代码案例。具体而且,现在主流的神经网络有多层感知机(MLP),卷积神经网络(CNN),循环神经网络(RNN),注意力机制(Transform),当然还有更高级的图卷积网络,生成对抗式网络.......这些都需要专门的深度学习框架去实现代码。本系列作为sklearn库的实现,只能做最基础的MLP网络,虽然基础,但是也很灵活,可以自己搭建不同深度不同神经元个数的神经网络组合,效果比一般机器学习方法也不分仲伯。如果想实现CNN,RNN,LSTM, GRU, Transform等高级网络,建议关注我后面的深度学习系列,基于Keras和pytorch的实现。
神经网络回归的Python案例
还是波士顿房价数据集,导入包数据,划分训练测试集,标准化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
from sklearn.datasets import make_moons
from sklearn.preprocessing import MinMaxScaler
from sklearn.inspection import permutation_importance
from sklearn.inspection import plot_partial_dependence
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.neural_network import MLPRegressor
from mlxtend.plotting import plot_decision_regions
# Feedforward Network with Boston Housing Data
Boston = load_boston()
X = pd.DataFrame(Boston.data, columns=Boston.feature_names)
y = Boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_test_s = scaler.transform(X_test)构建神经网络拟合,构建一个单个隐藏层,只有5个神经元的网络
model = MLPRegressor(solver='lbfgs', hidden_layer_sizes=(5,), random_state=123, max_iter=10000)
model.fit(X_train_s, y_train)
model.score(X_test_s, y_test)
model.intercepts_
model.coefs_
model.n_iter_将系数变为数据框,进行可视化
table = pd.DataFrame(model.coefs_[0], index=Boston.feature_names, columns=[1,2,3,4,5])
sns.heatmap(abs(table), cmap='Blues', annot=True)
plt.xlabel('Neuron')
plt.title('Neural Network Weights (Absolute Values)')
plt.tight_layout()
可以看到,2和4神经元的权重较大。
神经网络可以将变量进行置换得到变量的重要性分布,也可以进行可视化
result = permutation_importance(model, X_test_s, y_test, n_repeats=20, random_state=42)#重复20次
dir(result)
index = result.importances_mean.argsort()
plt.boxplot(result.importances[index].T, vert=False, labels=X_test.columns[index])
plt.title('Permutation Importances')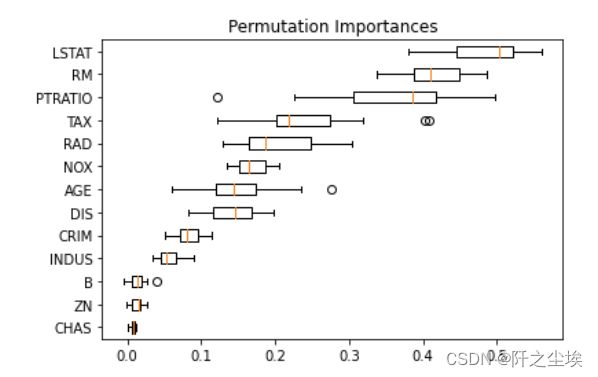 LSTAT最重要
LSTAT最重要
mean_importance = pd.DataFrame(result.importances_mean[index], index=Boston.feature_names[index], columns=['mean_importance'])
mean_importance
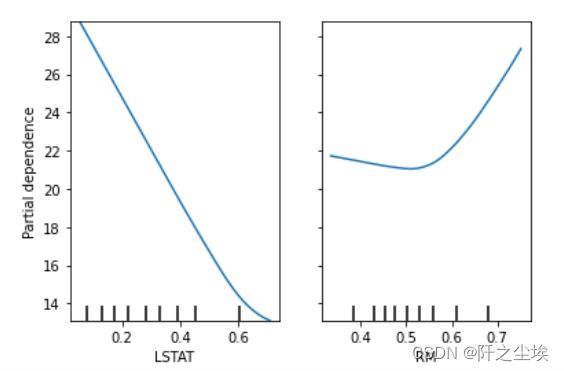
偏依赖图
# Partial Dependence Plot
X_train_s = pd.DataFrame(X_train_s, columns=Boston.feature_names)
plot_partial_dependence(model, X_train_s, ['LSTAT', 'RM'])
手工寻找最优神经元个数
scores = []
for n_neurons in range(1, 41):
model = MLPRegressor(solver='lbfgs', hidden_layer_sizes=(n_neurons,), random_state=123, max_iter=10000)
model.fit(X_train_s, y_train)
score = model.score(X_test_s, y_test)
scores.append(score)
index = np.argmax(scores)
range(1, 41)[index]
plt.plot(range(1, 41), scores, 'o-')
plt.axvline(range(1, 41)[index], linestyle='--', color='k', linewidth=1)
plt.xlabel('Number of Nodes')
plt.ylabel('R2')
plt.title('Test Set R2 vs Number of Nodes')
k折交叉验证搜索最优超参数
#Choose number of nodes by CV
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.model_selection import GridSearchCV
param_grid = {'hidden_layer_sizes':[(5,),(10,),(20,)]}
kfold = KFold(n_splits=10, shuffle=True, random_state=1)
model = GridSearchCV(MLPRegressor(solver='lbfgs', random_state=123, max_iter=100000), param_grid, cv=kfold)
model.fit(X_train_s,y_train)
model.best_params_
model.score(X_test_s,y_test)手工寻找双隐藏层最优神经元个数
best_score = 0
best_sizes = (1, 1)
for i in range(1, 11):
for j in range(1, 11):
model = MLPRegressor(solver='lbfgs', hidden_layer_sizes=(i, j), random_state=123, max_iter=10000)
model.fit(X_train_s, y_train)
score = model.score(X_test_s, y_test)
if best_score < score:
best_score = score
best_sizes = (i, j)
print(best_score)
best_sizes
#最优参数带入
model = MLPRegressor(solver='lbfgs', hidden_layer_sizes=best_sizes, random_state=123, max_iter=10000)
model.fit(X_train_s, y_train)
model.score(X_test_s, y_test)神经网络分类的Python案例
采用垃圾邮件数据集
Spam = pd.read_csv('spam.csv')
Spam.shape
Spam.head()
取出X,y,划分训练测试集,数据标准化
X = Spam.iloc[:, :-1]
y = Spam.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2, random_state=0)
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_test_s = scaler.transform(X_test)进行神经网络拟合
#单隐藏层,100个神经元
model = MLPClassifier(hidden_layer_sizes=(100,), random_state=123, max_iter=10000)
model.fit(X_train_s, y_train)
model.score(X_test_s, y_test)
model.n_iter_
#双隐藏层,神经元都是500个
model = MLPClassifier(hidden_layer_sizes=(500, 500), random_state=123, max_iter=10000)
model.fit(X_train_s, y_train)
model.score(X_test_s, y_test)
model.n_iter_神经网络非常容易过拟合,采用早退或正则化防止过拟合
# Regularization via Early stopping
model = MLPClassifier(hidden_layer_sizes=(500, 500), random_state=123, early_stopping=True, validation_fraction=0.25, max_iter=10000)
model.fit(X_train_s, y_train)
# Regularization via Weight decay
model = MLPClassifier(hidden_layer_sizes=(500,500), random_state=123, alpha=0.1, max_iter=10000)
model.fit(X_train_s, y_train)
model.score(X_test_s, y_test)
model.n_iter_预测,计算混淆矩阵
prob = model.predict_proba(X_test_s)
prob[:3]
pred = model.predict(X_test_s)
pred[:3]
pd.crosstab(y_test, pred, rownames=['Actual'], colnames=['Predicted'])
自制数据集利用神经网络分类
# Data with Noise
X, y = make_moons(n_samples=100, noise=0.3, random_state=0)
data = pd.DataFrame(X, columns=['x1', 'x2'])
sns.scatterplot(x='x1', y='x2', data=data, hue=y, palette=['blue', 'black'])
进行神经网络拟合
# Test Data
X_test, y_test = make_moons(n_samples=1100, noise=0.4, random_state=0)
X_test = X_test[100:, :]
y_test = y_test[100:]
model = MLPClassifier(hidden_layer_sizes=(100, 100), random_state=123, max_iter=10000)
model.fit(X, y)
model.score(X_test, y_test)画其决策边界
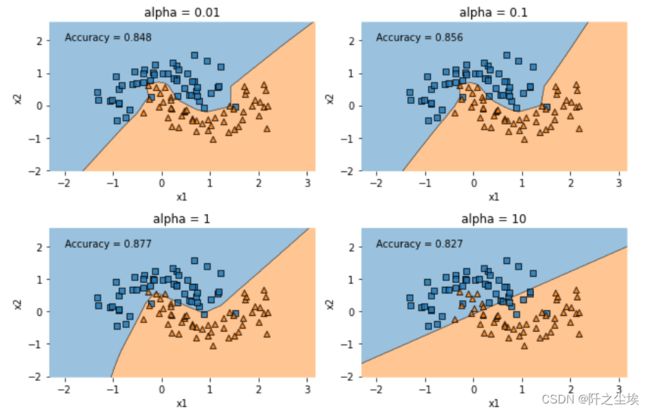
plt.figure(figsize=(9, 6))
for i, alpha in enumerate([0.01, 0.1, 1, 10]):
model = MLPClassifier(hidden_layer_sizes=(100, 100), alpha=alpha, random_state=123, max_iter=10000)
model.fit(X, y)
plt.subplot(2, 2, i + 1)
accuracy = model.score(X_test, y_test)
plot_decision_regions(X, y, model, legend=0)
plt.xlabel('x1')
plt.ylabel('x2')
plt.title(f'alpha = {alpha}')
plt.text(-2, 2, f'Accuracy = {accuracy}')
plt.subplots_adjust(hspace=0.5, wspace=0.3)
plt.tight_layout()