《运维之下》——第九章:网络成长之路
互联网公司的生存根本是服务安全、高效、稳定,这三个条件也是互联网运维从业者的工作基础,而这些基础工作绝大部分都依赖于底层网络服务的健壮性。互联网行业的网络服务与传统行业的网络服务还是有所区别的。
传统行业由于业务单一。增加趋势平稳,所以对于网络只有安全性和健壮性的需求;但互联网行业的特点是服务多元化、业务无规律增加、热点内容等,所以互联网行业的网络服务除了具备安全性、健壮性特点外,还需要支持较高的扩容能力和灵活的按需变化能力。
初期公司创业初期,一方面没有专职的网络运维人员,另一方面对未来网络容量规划缺少可以参考的历史数据(服务器数量、带宽数据等),所以第一阶段的网络建设是在对未来规划毫无数据支撑的情况下进行的。并且这里有个更重要的因素就是在公司产品还没有盈利的情况下,基础建设往往都会处于滞后状态,这应该也是绝大部分创业公司都会面临的问题。
在一穷二白的时候对网络方案的选择更看重以下三个因素。◎ 组网方案的成熟性。◎ 可靠性(主要依赖产品)。◎ 运维便利性。
组网方案和产品选择初期网络产品自身的稳定性决定了整体网络的稳定性,选择一家业界靠谱的网络设备厂商如H3C、Cisco等,是保障初期网络稳定性的必要条件。初期组网拓扑结构图如图9-1所示。

图9-1 初期组网拓扑结构图
第一阶段的网络结构采用了传统分层的Layer 2组网网络,物理上区分了互联网接入层、核心层、接入层设备。自上而下,我们先看互联网接入层。
互联网接入层互联网接入层设备可以选择路由器,也可以选择三层交换机,这里就不展开介绍这两种设备的功能区别了。在某案例中,第一阶段的互联网接入层设备采用的是三层交换机,主要基于两个因素考虑。
(1)端口密度:在流量未形成规模时,同时对互联网接入层设备没有过多功能要求时(初期只运行简单的静态路由),三层交换机的端口密度指标作为优先考虑的条件。
(2)成本问题:同样的成本,端口使用量是路由器的几倍,三层交换机的性价比更高。通常在数据中心接入互联网线路时,线路提供商可以提供如下几种不同的接入方式(不同的互联网供应商可能提供的方式有所区别)。◎ VRRP主备线路◎ ECMP双主线路
在初期网络建设中,互联网接入层设备采用的是双上联接口VRRP主备方式,在互联网流量较小的情况下基本可以满足对业务带宽和冗余的需求。关于互联网接入线路的选择,由于不同数据中心的规模和承建方、人力投入、技术支持、运营能力都不一样,导致数据中心提供的线路也有所区别。
国内比较常见的现象是,一级运营商直接提供数据中心资源,那么数据中心内只能有一级运营商的线路资源。例如,中国联通的数据中心只能提供中国联通的互联网线路。在由二级运营商承建或由不同的一级运营商联合建设的数据中心(此类较少)是可以提供多线或多种单线线路资源的。
线路资源可以分为如下两类。◎ 单运营商线路:中国联通、中国电信、中国移动等国内一级运营商线路。◎ 多运营商BGP线路:双线、四线、六线、八线国内二级运营商提供的线路。
单运营商线路由于是一级运营商直接提供的,所以单线资源在质量、扩容、故障、成本这4个方面要略优于多线资源。但由于中国各运营商自治和网间结算流量费昂贵,导致业务层面需要使用额外技术手段(如DNS调度、全局负载均衡、CDN等)来提升不同区域和不同运营商用户的访问质量。
多运营商BGP线路是由二级运营商和各一级运营商建立的BGP邻居关系,将自有IP地址通过BGP在已建立邻居关系的一级运营商线路内广播。从应用角度来看,可以轻松地实现IP多线路的运行模式,不受骨干网各运营商之间的访问限制,提升了应用访问的速度和品质。
目前国内家用宽带接入运营商以中国电信、中国联通为主,例如,主营客户端游戏的公司通常选择双线(中国电信、中国联通)的线路为主。但随着2008年中国移动和中国铁通的合并和移动互联网的兴起,移动线路和教育网在各数据中心中所占的比重也越来越重要了。各运营商流量占比如图9-2所示。
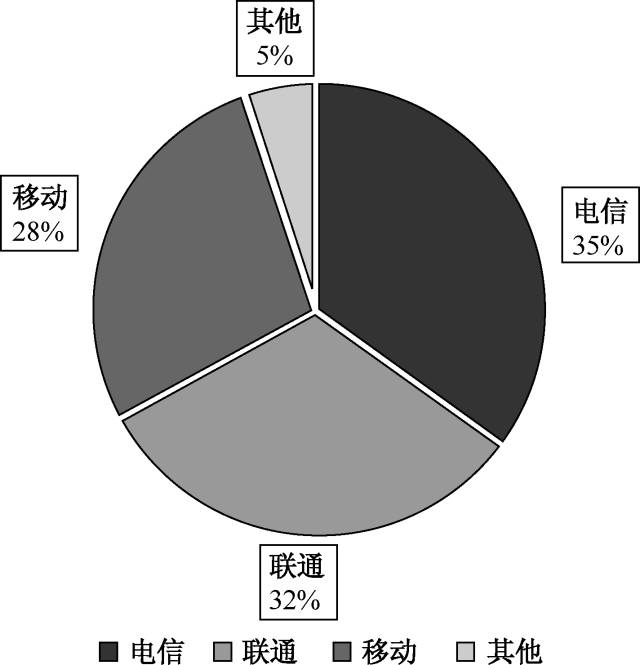
图9-2 各运营商流量占比
在用户至上的时代,显然在初期使用多线BGP线路这种复合型线路资源解决用户的问题是立竿见影的。但随着业务规模的扩张、调度系统的完善,以及对成本方面的考虑,多线BGP线路的弊端也逐步显现出来。
首先就是成本的压力 ,随着用户量的增加,带宽数量也呈现突飞猛进的增长态势,以四线BGP线路和单运营商线路为例,它们的成本差距在5倍左右,在强调“节能环保”的今天,这种成本的差距显然是不可接受的。
其次是故障率和冗余切换能力 ,由于多线BGP线路主要是二级运营商承建的,从网络角度来看,多一跳就意味着多一个故障的隐患。
再者是冗余切换能力 ,多线BGP线路在冗余切换上分为两类,业内称为真BGP多线和伪BGP多线,两者的区别在于真BGP多线实现了各大一级运营商线路路由的互相备份,当多线BGP线路中其中一个运营商线路出现故障时,故障运营商线路上的路由可以通过其他线路进行绕行访问;然而,伪BGP多线则只能实现多线路的用户访问覆盖,无法做到各线路路由的互相备份,当伪BGP多线其中一个运营商线路出现故障时,网络工程师能做的只是等待运营商进行故障修复。
还有就是多线BGP线路定向扩容能力。多线BGP线路的优势在于它具备优秀的线路整合能力,将原本复杂的互联网环境简单化。这种复合型线路资源势必会产生多资源配比的问题,例如,我们购买了1Gbps的四线BGP线路,这是不是代表这4个运营商线路我们单独都能跑到1Gbps呢?
答案肯定不是这样的。通常BGP带宽资源池中的中国电信、中国联通的带宽会比较富裕,但一些相对占比较少运营商的带宽往往会很少。比如某真实案例中,业务移动端流量爆发,导致移动运营商流量突增,从带宽监控图上看带宽Buffer空间仍然有很多富余,但论坛总是能收到用户投诉超时、连接不上服务器等问题。
最后梳理用户投诉发现均为移动用户,协同二级运营商排查后才确定为是由于二级运营商中的移动线路带宽瓶颈导致的。对于这个问题,由于多线BGP线路每家提供商的资源都有所不同,业界也没有一个固定配比原则,所以这部分依然是盲区,不容易规避。
核心接入层和服务器接入层初期在对业务发展毫无概念的情况下,选择一套简单的通用的组网方案和使用相对靠谱的网络设备是保障网络可用性的两个关键条件。
初期核心接入层和服务器接入层采用Layer 2传统二层互联的方式。这种Layer 2传统组网方式,接入交换机后端服务器的默认网关都在核心交换机上运行,核心交换机采用VRRP/HSRP(热备份冗余路由协议)提供一个虚拟地址为服务器默认网关。
核心接入层和服务器接入层运行STP(生成树协议)提供服务器接入层交换机双上联核心交换机冗余性。STP协议需要生成一个无环并且冗余的网络拓扑,基于 STP协议的特性,需要通过算法在核心和接入层之间选择一个接口将其置为Blocking状态,在默认情况下使用Forwarding状态的接口进行数据转发,当Forwarding状态的接口出现故障时,则再次进行STP计算,然后将原Blocking状态的接口置为(默认35秒完成)Forwarding状态后恢复数据传输。
Layer 2传统组网方式提供了便捷的服务器接入能力,服务器只需要接入交换机接口,并将接口归属到指定的VLAN即可完成服务器上线。但如果在此阶段没有良好的IP地址规划,以及在业务爆发期无规律地上线服务器,再加上某些特殊的应用需要在二层环境下才可以工作,如数据集群(Keepalived)、LVS-DR模式等,这样的需求和现状会导致需要频繁的对接口VLAN信息进行变更,工作量巨大。
为了避免此类操作,初期网络采取了比较粗暴的方式进行处理,在核心交换机SVI(Switch Virtual Interface)以辅助地址的形式运行多IP,这样可以解决因服务器上线和接口变更所带来的网络设备的变更问题(不过因此也为后期埋下了祸根)。interface vlan 100ip policy route-map LVS-DR(坑1)ip address 192.168.1.254 255.255.255.0(坑2)ip address 10.0.1.254 255.255.255.0 secondary(坑3)ip address 10.0.2.254 255.255.255.0 secondary大体上来看,这时的网络结构满足了业务需求,并且通过“技术手段”减少了烦琐的服务器上线和其他业务需要的网络设备变更问题,弥补了初期人力不足的短板。但实际上该阶段的网络规划并没有看起来那么美好和健壮。
比如在该案例中,使用了192.168.1.0/24地址给忘了运维带来了困扰。现在做IP地址规划大家一定不会选择B类192.168.0.0/16私有地址作为内网的主要地址。原因不止是B类地址比A类地址可使用的地址数少这么简单。这里面所带来的问题是,如果数据中心存在192.168.1.0/24这个网段的服务器,我们如何通过远程VPN的方式管理这台服务器呢?因为这个地址段默认被D-Link、TP-Link这些家用无线路由器厂商当作初始化的IP地址段。当我们使用PPTP或L2TP远程拨号VPN远程访问目标服务器时,由于本地直连路由比静态路由的优先级更高,所以访问远程目标服务器的数据不会通过VPN发往数据中心目标服务器,数据包会在本地局域网进行二层查询。
上面这个小问题只是让远程办公的同学们有些不爽而已,还没有真正地对生产网络产生影响。下面两个问题对初期网络造成了不可小觑的影响,一个是单SVI多IP工作模式引起的问题,二是LVS-DR工作模式引起的问题。
网络设备对不同的数据处理分别是基于控制层面和转发层面进行的。这部分内容在网络设备厂商官网有大量的介绍,这里就不详细讲解了。简单来说,进入数据控制层面的报文主要靠CPU能力进行处理,转发平面主要靠硬件能力进行处理。控制层面:控制层面就是各种协议工作的层面。
它的作用是控制和管理各种网络协议的运行。控制层面主要处理两类报文,一是抵达设备自身的,如Telnet、SSH、SNMP;二是负责网络选路和拓扑变化所使用的协议,如生成树协议、动态路由协议、组播协议,这些都是由控制层面直接进行处理的。控制层面的处理能力依赖设备自身的CPU性能,所以在网络优化中也需要对控制层面进行特殊的防护,如CoPP(Control Plane Policing,控制层面策略)。 总结:控制层面通过软件(CPU)处理,效率低。
转发平面:转发平面的工作主要是对穿越网络设备的报文进行处理,Layer 2数据包、Layer 3数据包、访问策略、QoS这些都属于转发平面的任务范畴。转发平面主要依赖设备接口芯片的处理能力。总结:转发平面通过硬件(芯片)处理,效率高。
在初期,某案例中,应用时常出现超时和访问失败等问题,排查后确定是由于核心交换机CPU负载高引起的(见图9-3),那么到底是什么原因引起的CPU负载高呢?

图9-3 核心交换机CPU负载高
原因一:
交换机在进行三层转发时,如果路由下一跳在一个二层网段或者在相同的VLAN下,则会产生ICMP Redirects报文,这种报文是直接进入交换机的控制层面处理的,这类流量由交换机CPU直接处理。单SVI多IP工作模式会过度产生直接由交换机CPU处理的报文,这是导致核心交换机CPU负载高的一个主因。High CPU Due to Excessive ICMP RedirectsYou can get ICMP dropped redirects when one VLAN (or any Layer 3 port) receives a packet where the source IP is on one subnet, the destination IP is on another subnet, and the next hop is on the same VLAN or layer 3 segment.
原因二:由于LVS-DR工作模式的特性,Real Server(后端目标服务器,后续简称RS)在进行响应时,需要使用服务器自身Lo绑定的VIP地址进行回包。LVS后端服务器存在两种部署模式,第一种为后端RS配置公网IP;第二种为后端RS配置内网IP。第一种模式下可以依赖后端RS自身的默认网关完成数据包的回包工作;第二种模式下则需要网络层通过PBR(Policy-Base Route,策略路由)对流量进行特殊的处理。
由于第一种部署模式会将后端服务器直接暴露在互联网上,存在安全风险,所以当初出于安全的考虑,后端服务器采用了第二种部署模式。这就导致需要在网络层使用PBR对这部分特殊的流量进行处理。某些低端核心交换机在开启PBR这个特性时存在一些限制,会导致导致核心交换机CPU负载过高。High CPU Due to Policy Based RoutingPolicy Based Routing (PBR) implementation in Cisco Catalyst 3750 switches has some limitations. If these restrictions are not followed, it can cause high CPU utilization.l You can enable PBR on a routed port or an SVI.l The switch does not support route-map deny statements for PBR.l Multicast traffic is not policy-routed. PBR applies only to unicast traffic.l Do not match ACLs that permit packets destined for a local address. PBR forwards these packets, which can cause ping or Telnet failure or route protocol flapping.l Do not match ACLs with deny ACEs. Packets that match a deny ACE are sent to the CPU, which can cause high CPU utilization.l In order to use PBR, you must first enable the routing template with the sdm prefer routing global configuration command. PBR is not supported with the VLAN or default template.
但随着大数据和分布式计算的应用,业务层面给网络带来的挑战还远远不止这些。分布式计算类型的服务会存在大量的数据交互和复制,其特点是:高带宽、大突发。它们在一定时间里被我们亲切地称之为“内网杀手”。以Hadoop为例,从图9-4可以看出,用户在推送数据块时数据节点之间的复制操作需要频繁地消耗接入层交换机的上行带宽,在初期上行收敛比还是12:1时(8口千兆上行,48口千兆下行),这部分流量必然会给相同机架的其他服务造成影响。
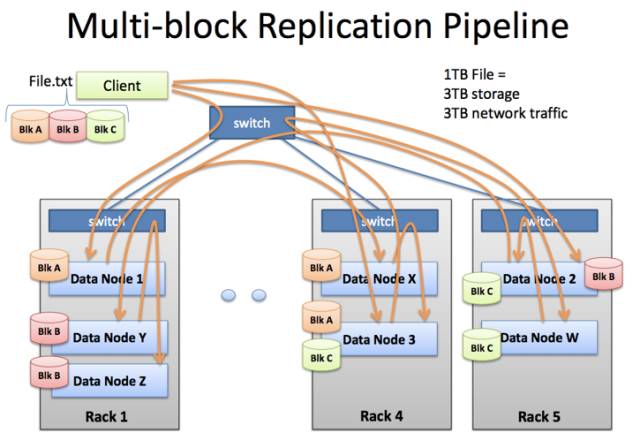
图9-4 分布式计算大量消耗内网上行宽带
针对此类业务的大数据交互的特性,在该案例中,做了以下两个方面的调整。
◎ 优化数据节点,减少跨机柜的交互。◎ 扩容接入层交换机,达到核心上行带宽。
刚才我们谈到收敛比时,应该有读者看出初期阶段核心和接入层之间存在的问题。8口千兆上行收敛比应该是6:1,为什么这里写的是12:1呢?就如之前所介绍的一样,核心和接入层之间运行的生成树协议(STP),天生就会浪费50%的带宽资源。STP会带来两个问题,一是资源浪费,二是冗余切换能力,如果当上行接口聚合组其中一个接口出现异常关闭时,那么接入层交换机的上行收敛比就又会减少1/4,并且这时STP并不会重新进行拓扑计算。
我们在处理Hadoop大流量的问题时,意识到STP这种古老的协议已经不适用于当前数据中心网络了。提升收敛比的首要任务就是将STP备份线路充分利用起来。
业界替代STP的组网方式有很多,如Layer 3组网、网络虚拟化、大二层。但这种在原有网络基础上改造的方式,不同于新建,更多的是需要考虑原有设备利用、割接窗口时长等客观因素。
所以在考虑上述因素后,改造方案选择使用网络虚拟化的方式替代STP组网方式(见图9-5)。这样可以在不更换接入层交换机的情况下,将原有收敛比提升一倍,并且很好地规避了前面提到的STP存在带宽浪费、冗余切换的问题。

图9-5 网络虚拟化
网络虚拟化技术有两个技术类别分支,分别是整机虚拟化和接口虚拟化。
整机虚拟化以Cisco VSS(Virtual Switching System) 和H3C IRF(Intelligent Resilient Framework)为代表,这类整机控制层面虚拟化已经是比较成熟的技术,已有很多商用案例。控制层面虚拟化提供了两种工作模式,分别是一虚多和多虚一,分别应对不同的场景。
多虚一的主要作用是简化网络结构,提升网络横向扩展能力。通常是两台设备进行多虚一,但目前也有部分厂商实现了N:1的整机虚拟化,如H3C IRFv2(Intelligent Resilient Framework 2,第二代智能弹性架构)技术目前最多可4台核心设备N:1虚拟化,H3C等较为主流的交换机产品线均支持IRFv2技术S1250、S9500E、S7500E、S5800等。一虚多技术多数用在虚拟化多租户环境下,整体提升硬件资源的利用率。此类技术多使用在金融和虚拟化公有云环境中。
接口虚拟化以Cisco VPC(Virtual Port Channel)和Arista MLAG(Multi-Chassis Link Aggregation)为代表,接口虚拟化和整机虚拟化在网络结构上没有太大的变化,都进行了跨设备的接口聚合操作。但由于接口虚拟化只关注跨设备的接口聚合,所以在核心层面依然需要使用HSRP/VRRP技术提供冗余支持。
在实际部署中对接口虚拟化各家厂商限制的条条框框较多,相比IRFv2整机虚拟化技术部署起来比较复杂,反观整机虚拟化提供最多4台核心设备的虚拟化能力,接口密度为乘的关系,去除了复杂的VRRP/HSRP配置和大量的地址配置,逻辑上只管理和监控一台设备,提供了良好的管理便利性(见图9-6)。
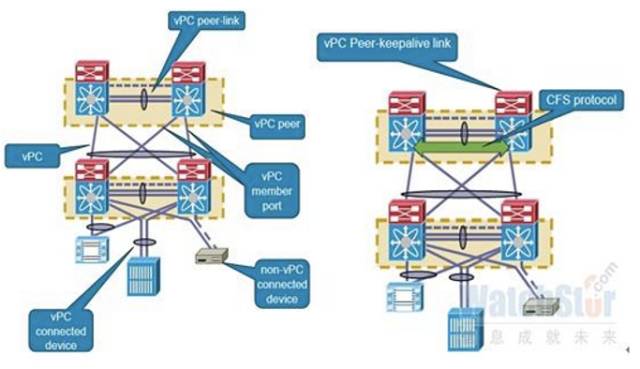
图9-6 整机虚拟化和接口虚拟化部署图
基于以上的分析,在应对初期Hadoop高带宽需求时,我们的解决方法是通过替换核心交换机设备,提升一倍的带宽收敛比,短暂性满足带宽需求,并且尽可能地将Hadoop业务放置在单独的机柜,以防止影响到其他业务。
初期网络运维总结在没有明确需求做数据支撑的前提下,组网方案只停留在了简单的设备堆砌阶段。应用存在不确定增长或大规模爆发情况时,对基础网络造成的冲击非常大。网络运维工程师这时主要承担了救火队的角色。
但这一阶段也有不少收获:第一,逐渐摸清了公司业务流量模型和特点,为后续的规划积累了数据;第二,通过不断的网络平台扩容、改建,总结出以下两条真理。◎ 改造的难度远大于新建。◎ 对于增长不确定的网络规划,核心交换机的规格和投入适当超前。
中期在该案例中,总设备数量的增长,推动了建设新数据中心的需求,让网络工程师有机会在“白纸”上重新构建基础网络,规避初期遇到的问题,重新梳理需求。网络建设和数据中心规模有着密切的关系,如原计划建设一个约500台服务器规模的数据中心,网络的设计容量为支持1000台设备,但如果业务增长超过数据中心规划,这样就导致又要去规划新的数据中心。
这种情况所带来的问题有以下几点。◎ 大量小规模数据中心管理复杂。◎ 数据中心网络设备投入成本大。◎ 小规模数据中心间互联是难题。
当发现这个现象后,为了避免后期出现上述几个问题,采取了“脱壳前进”的数据中心扩容方式。当存在更大规模的数据中心时,将规模小的进行撤离融合到大规模的数据中心去,整体的网络结构、建设成本、运维成本均得到了提升。但这里痛点不在网络层面,而是在业务层面。在这个阶段大量业务还不支持双数据中心冗余切换,需要有损地进行业务迁移。所以需要推动业务架构支持双数据中心部署,为后期双数据中心冗余打好基础。
中期阶段的网络规划在业务分区、边界安全、线路层等方面都进行了相应的优化。同时业务部门也对网络安全提出了更明确的需求,如业务线间安全隔离、互联网访问安全隔离等。下面让我们来看看中期阶段到底为什么这样规划?还遇到了什么挑战?
组网方案为将来建设支撑万台以上设备的大型网络积累经验,在中期规划了两套不同的组网方案,来对比各自的优缺点。但基础的业务分区、安全需求、LVS区域的实现是一致的。 中期组网结构如图9-7所示。

图9-7 中期组网结构图
我们在网络中明确了区域的概念,对公司的不同业务划分了区域。各区域使用不同的物理层设备进行物理和逻辑的双重隔离,做了IP地址段的分区规划,不同IP地址对应不同业务。这样做的好处是逻辑结构清晰,并且便于后续运维及权限划分。可以分为以下三大类:
◎ 互联网区域◎ 内网区域◎ DCI(Data Center Interconnection)区域
互联网区域互联网区域示意图如图9-8所示。主要功能是接入多条运营商线路,各线路入网对应不同的负载均衡集群(LVS),出网对应SNAT集群。入网、出网实现统一化、服务化。
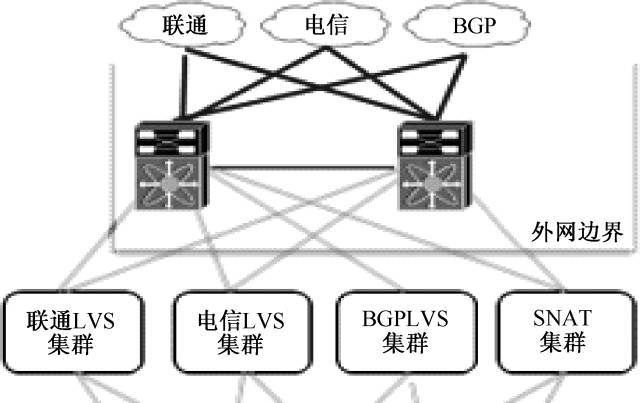
图9-8 互联网区域示意图
如前文所述,该阶段,业务对网络的可用性、安全性都提出了更高的要求,所以运营商线路接入都是采用双上联ECMP方式进行的,并且在每条运营商线路的入向接口提供互联网接口白名单的规则。
LVS/SNAT集群和网络一起规划了OSFP的方式联动部署。LVS也升级到了FULLNAT模式,相比DR模式对网络的要求降低很多。从网络角度来看,FULLNAT的数据流是一个正常的从哪里来从哪里回的数据包,在网络层可以不用对这些报文做特殊的处理(策略路由)。这也极大地简化了网络的复杂程度,LVS的部署和详细内容可以参考LVS章节。
在某案例中,此阶段,互联网线路上更多的是关注质量、故障、成本三个因素,所以我们设计多线路的LVS集群方式,并建议应用尽量运行在互联网单线资源上。这里分享一些线路选择和带宽预留的原则。
1.互联网线路使用指引(1)可调度业务的电信、联通、移动用户使用单线资源覆盖。(2)可调度业务非三大运营商的用户使用多线BGP资源覆盖。(3)SNAT默认只提供BGP出网线路。 2.带宽预留原则(1)物理接口:物理接口使用总和的50%(单10Gbps接口带宽使用范围为5Gbps,双10Gbps负载接口带宽使用范围为10Gbps)。(2)逻辑带宽:带宽Buffer数量为最近一周带宽峰值的50%。
内网区域在某案例中,初期阶段在收敛比上吃了亏,在中期阶段专门规避了这个问题,收敛比初期设计为1:2,但随着采购量的增加和设备成本的下降,逐步地扩容到1:1。根据监控数据看非分布式计算业务机柜在2:1的收敛比下也可以良好地工作,这和业务自身调优也有比较大的关系。但分布式计算业务如Hadoop机柜则建议1:1收敛。
在实际部署中内网区域使用了两套当时比较主流的组网方案,这主要集中在核心接入层和服务器接入层之间。其中一种是Layer 3互联组网方案;另一种则是以Cisco Nexus系列为代表的Pod Design互联组网方案。这两套组网方案各有优劣势。
1.Layer 3互联组网Layer 3互联组网,顾名思义,是核心层和接入层运行OSPF或者BGP路由协议进行互联。业内一直有一种说法是,Layer 3互联组网是一种临时数据中心组网的过渡方案。这种说法其实没有错。我们可以设想一下,在核心设备不支持网络虚拟化或现在主推的大二层解决方案的年代之前(2009年Cisco Catalyst 6500平台开始支持网络虚拟化技术VSS),除了这种Layer 3互联组网方案,核心设备在当时是没有技术支持横向扩展的。
换个角度来说,就是一个数据中心可承载的服务器数量其实局限于核心设备的接口密度。Layer 3的解决方案在满足扁平化的基础上将数据中心可承载的服务器数量提升了8~16倍(主要参考ECMP的数量决定)。当然,Layer 3互联组网方式也完全规避了STP产生资源浪费和冗余切换时间长的问题。
(1)Layer 3互联组网的挑战Layer 3互联组网方式也对运维管理、成本提升、二层应用的部署带来了一定程度的挑战。◎ 运维管理首先,运维管理的挑战是IP地址管理、基础服务应用、接入交换机上限三个方面。可想而知,IP地址管理将变得很复杂。以4个核心为例,每台接入交换机上都会配置4个P2P(Point-To-Point)互联IP地址和一个服务器网段。如果服务器使用共享ILO(Integrated Lights-Out)管理方式,那么还将有服务器管理卡网段。在正常情况下每个接入交换机上将产生5~6个小网段。假设我们有200台接入交换机,在没有良好的CMDB系统协助管理记录的话,运维这种类型的网络难度可想而知。
其次,是基础服务应用。例如服务器上架和装机,因为每台接入交换机自治的原因,所以就需要服务器上架人员和装机人员对此类网络有充分的了解。但在实际环境中往往是负责上述工作的人员和构建网络人员分属两个不同的组或者部门,所属不同的专业维度,要求他们对网络结构、IP地址与网络工程师有一样的认识显然不太合适。最终就变成一些服务器上架和变更需要主机人员和网络人员配合,费时、费力,效率极低。
最后,是接入交换机上线。就如刚才所提到的IP地址管理的复杂性,在初期没有Netconf和Poap(Netconf和Poap实现网络设备加电后自动下发配置的功能)技术支持的情况下,一台接入交换机的初始化配置涉及大量的人工修改,配置的准确性和上线效率都潜在隐患。
◎ 接入交换机成本的提升在传输二层环境下,我们进行接入交换机选型主要关注接口密度、接口Buffer、背板带宽、转发能力、MAC地址容量这几个性能指标即可。但对于Layer 3互联组网,我们在关注上述指标之外,还需要关注设备是否支持三层功能、路由表的容量等信息。这样势必会带来接入交换机的成本提升。这部分设备在数据中心基数较大时,产生的成本量级还是比较大的。
◎ 二层应用部署典型的二层应用就是VRRP(热备份冗余路由协议),如需要提供虚地址方式进行集群冗余的应用,均依赖此协议(如Linux Keepalived)。这样导致依赖此协议的集群服务需要部署在相同的交换机上或者相同的机柜上。显然这样的部署方案在冗余上并不是那么完美。针对这种业务,在Layer 3互联组网方案中,通常的处理方式是将前后排背靠背两个机柜做成多虚一的虚拟机交换机,来满足不同的接入交换机和不同的机柜达到冗余的效果。这里还涉及一个现实的问题是,通常研发或应用运维提交服务器使用申请时是不会标注应用类型的。这样导致负责主机的人员在交付后还要针对使用这种类型的服务进行单独的机柜调整操作,涉及的工作量可想而知。
(2)Layer 3互联组网的优势不可否认,在特定的阶段Layer 3互联组网方案提供了良好的扩展性、冗余性、安全性,这也是此类组网方案的优势所在。扩展性主要体现在可以针对核心层面进行横向扩容;冗余性体现在支持多条冗余上行线路,并且有着良好的切换能力;安全性体现在众所周知的安全性最差的数据链路层上,减少了数据链路层广播风暴的可能性,降低了受广播风暴的影响,但是对特定应用存在一定的部署难题。Layer 3互联组网方式在核心设备与接入层设备品牌选择上提供了差异性支持。接触网络较早的读者一定清楚不同厂商的设备工作在STP环境下会产生莫名其妙的问题。这种组网方式可以规避此类问题,让不同品牌的核心设备和接入层设备工作在网络中。
2.Pod Design互联组网Pod Design互联组网方式,是Cisco Nexus交换平台上推出的组网方案,在物理结构上类似于传统的核心、汇聚、接入三层。实际部署的区别主要在汇聚和接入两层。传统的汇聚和接入采用Layer 2或Layer 3进行互联。 Pod Design以Pod概念替代传统区域的概念,在结构上差异并不大,但功能上略有差别,传统区域定义除了划分区域外,区域汇聚可以提供安全、负载均衡、流量控制等功能,这主要依赖汇聚交换机的设备产品形态。但当前数据中心的网络需求已经从多功能向高带宽、低延迟方向转变,这些较为复杂的功能已经不适合当前数据中心的网络需求了。Pod Design互联组网方案在这两层采用了俗称远端板卡接入方式(Fex),类似于在汇聚层和接入层进行纵向虚拟化,Pod内所有接口的操作、监控、变更在Pod两台核心设备上进行,简化网络结构、减少网络中可管理设备的台数。
(1)Pod Design互联组网的挑战Pod Design的设计思想是将网络按模块进行归类,这种思想和我们设计网络时提到的IP关联业务线不谋而合,甚至是天生就实现的。但此类组网方式也同样面临着Layer 3组网所遇到的三个挑战。◎ 运维管理运维管理所带来的挑战是布线系统 、Pod容量、管理风险三个方面。传统的数据中心核心到接入层布线有两种方式,即EoR(该方式指服务器机柜中所有的服务器接口,都通过跳线连接到机柜上的配线架,再由配线架上的铜缆延伸到网络机柜(位于一组机柜尾部)中的接入交换机)和ToR(该方式将接入交换机放置在每个服务器机柜顶部,机柜内服务器直接通过短跳线连接到顶部的交换机,再经由光纤从交换机的上行链路接口连接到核心交换机)这两种方式的优劣势网上分析文章很多,这里就不做过多的分析了。
目前主流的是ToR布线方式。但Pod互联组网模式的布线方式还和ToR方式略有不同,主要是在汇聚交换机提供到接入交换机的接口方式上有所区别。传统的ToR方式汇聚和接入设备分别提供4个10Gbps SFP+线缆接口互联接口,但Pod Design出于机架空间和端口密度的考虑,多数是提供如图9-9所示的40Gbps MPO线缆类型的接口。此时我们需要通过MPO-to-41C 针对汇聚和接入设备线缆进行跳接。

图9-9 40Gbps MPO线缆类型的接口
这带来了一个问题,就是线缆长度的问题。在设计此类型组网方式时,为了避免单一40Gbps接口故障影响过多的接入层上行带宽的容量,在实际环境中40Gbps接口是分别接入4台不同的接入层设备的,这样当汇聚单设备单40Gbps接口故障时,只是4台接入交换机上行带宽从40Gbps减少到30Gbps而已,这个带宽减少的比例还是可以接受的。
但根据机柜位置的不同,线缆长度也不同,在实际采购过程中发现MPO-to-4lc线缆都不提供定做LC侧超过10m以上规格的线缆。在部署和线缆备件的处理上都比较麻烦,所以采取的是汇聚交换机机架顶部配线架的方式,如图9-10所示。

图9-10 汇聚交换机机架顶部配线架
两个配线架以背靠背48端口LC方式对接,在这样的布线方式下,汇聚交换机使用短距MPO-TO-4LC线缆和配线架1对接,接入层设备根据机柜实际位置选择不同长度的线缆与配线架2互联完成对接。
这样的布线方式较为简单地解决了线缆长度和备件所带来的问题,同时也增加了管理成本,并且配线架背靠背对接存在后期维修故障的难度。这样的配线架模式在后期如果其中一对接口出现问题,那么基本上是不可维修的,因为在配线架上直接进行光纤熔接操作非常容易误碰到其他线缆引起不必要的损失。针对这个问题,布线厂商在后期提供了预端接布线方案,大家可以自行百度查看技术细节,主要是以模块化思路处理了这部分对接,出现异常可以通过更换预端接模块进行简单处理。
Pod内服务器容量设计依赖于厂商限定的条件,以Cisco Nexus为例,在主流千兆服务器接入环境下,根据汇聚交换机工作模式的不同,单Pod容量可分为1152台和2304台服务器两种规格。受限于这样的条件,我们面临Pod内部署什么样的业务,以及业务超过Pod容量后Pod间带宽如何计算配比等问题。
此类组网方式减少了网络可管理的设备台数,全网设备管理集中在几台核心设备上。这样带来的管理是一些较为轻量级的操作,如接入层接口配置变更等都需要登录核心汇聚设备进行。但是为后期的权限划分增加了难度。
◎ 成本问题Pod Design在成本问题上可以分为两块内容,分别是成本提升和成本优化。成本提升主要是在这类组网方案中多了一层汇聚交换机的成本投入。成本优化则体现在业务流量模型清晰化上,可以减少Pod间收敛比、设备板卡及模块的投入,但这个需要视实际业务情况而定。
◎ 二层应用部署二层应用部署其实面临着跟Layer 3互联组网一样的问题,只是在Layer 3二层环境中以接入交换机为单位,Pod Design以汇聚交换机为单位。
(2)Pod Design互联组网的优势Pod Design采用类似多虚一的虚拟化技术,剥离传统接入交换机的控制层面。这样的优势是以Pod为单位只管理两台汇聚交换机,劣势就是接入交换机只能工作在Pod Design工作模式下,因为它自身不具备控制层面,无法单独使用,如Cisco Nexus 2000系列。
安全的挑战安全是任何一家互联网公司都不能忽视的问题,但安全需求在执行落地时都会给业务发展和基础架构带来一定的挑战,在此阶段安全对网络提出了以下需求。
1.互联网端口白名单随着LVS平台对运维工程师的管理权限下放,以及一些LVS无法支持的业务直接暴露在公网上,需要在互联网入口做防护,其规则制定和访问控制是保障业务安全的第一要素。
网络和安全人员一起制定了默认的白名单端口范围,以及特殊端口的申请及审批流程。在某案例中,这个功能在讨论初期存在两种方案,其中一种是在各LVS集群生效访问控制;另一种是在网络设备如防火墙、交换机生效访问控制。在网络设备层面生效的优势是可以在最初的入口完成访问控制,这也是访问规则就近生效的原则。另外,对于部分直接暴露在互联网上的业务,在网络设备层面统一入口生效也有助于对这类业务的保护。
互联网端口白名单可以选择在出口互联网接入层交换机层面生效,也可以通过上层增加硬件防火墙生效。从安全角度出发,使用硬件防火墙是最好的选择,因为硬件防火墙自身是可以实现如Syn Flood、Ack Flood等攻击的防御的,并且基于会话的硬件防火墙可以非常轻松地实现业务单向访问的需求。反观交换机传输ACL隔离,仅可以实现单纯的访问控制,在单向访问和防御Syn Flood、Ack Flood攻击方面则显得无可奈何。
但最终我们还是选择在交换机层面实施互联网端口白名单,其中一个主要原因是设备性能,因为交换机不记录会话,所以会话的多少是不会直接影响交换机的转发性能的。反观硬件防火墙设备,防火墙设备在选型时考虑的两个重要指标就是并发数和每秒新建连接数。当存在高并发业务时,防火墙设备对此类业务的安全过滤显得有些力不从心。另一个原因是成本,在出口并发数为200万,支持200万并发的场景下,防火墙产品和交换机的价格可是天壤之别。
互联网端口白名单有两种实现模式,其中一种是黑名单即明确拒绝特定端口;另一种是白名单即明确允许特定端口。第二种模式明显限制得更为严格,并且具备完善的审批和记录机制,如果遇到安全问题,可以快速地进行事件追溯(也可以通过全流量分析完成)。但这也在一定程度上带来了人力成本的上升。可以根据实际情况酌情选择。
2.内网隔离内网隔离在金融和军政网络中存在比较多,坦白地讲,金融和军政内网隔离相对较容易实现,因为此类网络对服务器数量和未来流量的预期相对有据可依,所以对这类网络可以选择防火墙隔离或网闸等手段来完成内网隔离。
但互联网公司业务存在很多不确定性和高突发流量的情况,在安全和性能之间很难找到一个平衡点,所以在互联网公司内网隔离就变得难以实现。
需要实施内网隔离一般有以下场景。(1)第三方评审如PCI-DSS,全称为Payment Card Industry(PCI)Data Security Standard,第三方支付行业(支付卡行业PCI-DSS)数据安全标准。(2)非授信区域部署第三方开源应用区域,如Discuz、Phpwind等开源程序。(3)业务线间不同业务线均存在不同类型的敏感数据,并相互不信任其对方的安全性,要求不同业务线间进行内网隔离。
针对不同的场景,应当采用不同的隔离方案。首先,安全合规应用属于第三方评审要求,此类内网隔离建议采用硬件防火墙设备,在这种安全至上的业务面前,性能反而不是第一考虑因素了;其次,针对后两种场景的这类安全需求属于公司内部需求,且对网络性能要求很高,这类需求建议采取交换机ACL方式进行安全隔离。
但采取交换机ACL方式实现内网隔离困难和问题依然很多,这主要体现在功能、容量、管理与变更三个方面。① 功能比如ACL实现单向访问困难。在互联网端口白名单中问题不大,因为互联网涉及的IP较少,类型也比较单一。但应用在内网隔离中这部分缺陷就显现出来,内网应用协议繁多,如FTP、DNS这两类应用是不能通过传统ACL实现单向访问的。所以一个折衷的做法是将此类无法实现单向访问的应用和必要的服务(如YUM/NTP等)进行梳理全部放行,同时将此类服务定义为基础设施白名单,该名单中的服务默认在所有生效的ACL区域放行,进入此名单的服务需要通过完善的安全审核机制和流程,保障其安全性。
② 容量 这方面问题主要是因为后期业务之间调用繁多,超过交换机自身设备所能承载ACL条目的规格。交换机ACL规格和防火墙ACL规格不在一个数量级上,防火墙ACL规格在几万甚至几十万级别,但交换机ACL规格往往只在千级别。
③ 管理与变更设想一下,上千条访问规则分别应用在不同的设备上,管理与变更这么庞大的访问规则不是件容易的事情。
中期网络运维总结在这个阶段我们完成了数据中心网络标准化的雏形规划和建设,通过与业务磨合,清晰地了解了业务对网络的需求。随着业务从不规律到逐步稳定上升,业务部门可以提供一定的可参考数据,这对后期建设标准化数据中心网络提供了良好的数据积累。业务部分对网络可提供的服务也有了一定的了解,如数据中心容量、线路资源、安全特性等。在这个阶段数据中心网络模型满足当前业务的需求。
总结前两个阶段,是某真实案例中,从初期到当前现状的核心网络的进化史和血泪史,期间所使用的组网技术和方案不是业界先进的技术和解决方案,都是一些传统的技术和组网解决方案,所以在介绍中并没有过多的技术描述,涉及的技术大家可以自行搜索,有大量的技术文档可供参考。希望通过我们的介绍,让大家对处理不同业务需求和初期网络建设少走一些弯路。
近两年随着云计算的发力,公司在初期阶段和对网络自主性要求不高时,云主机的解决方案是一个非常不错的选择。但随着Docker和OpenStack这些虚拟化服务的大量应用,后期需要考虑的是如何在网络架构中更好地支持虚拟化业务。传统的网络架构提供的扩展性和稳定性已经远远不能满足云计算中心对网络的需求,除了扩展性和稳定性这些基本需求外,对网络灵活性和网络快速适配能力都有较高的要求。
业界应对主流云计算网络架构的技术有很多,如SPB、TRILL、FabricPath、VXLAN、OTV、SDN等,希望这些技术在我们正式应用后继续分享给大家。当然,这个阶段的网络还存在一些问题,如监控的精准度、网络管理自动化等。这些问题和业务无关,是网络自身的运维管理问题,我们希望后续通过平台化以及对上述新技术的研究解决这类问题。
传统行业由于业务单一。增加趋势平稳,所以对于网络只有安全性和健壮性的需求;但互联网行业的特点是服务多元化、业务无规律增加、热点内容等,所以互联网行业的网络服务除了具备安全性、健壮性特点外,还需要支持较高的扩容能力和灵活的按需变化能力。
初期公司创业初期,一方面没有专职的网络运维人员,另一方面对未来网络容量规划缺少可以参考的历史数据(服务器数量、带宽数据等),所以第一阶段的网络建设是在对未来规划毫无数据支撑的情况下进行的。并且这里有个更重要的因素就是在公司产品还没有盈利的情况下,基础建设往往都会处于滞后状态,这应该也是绝大部分创业公司都会面临的问题。
在一穷二白的时候对网络方案的选择更看重以下三个因素。◎ 组网方案的成熟性。◎ 可靠性(主要依赖产品)。◎ 运维便利性。
组网方案和产品选择初期网络产品自身的稳定性决定了整体网络的稳定性,选择一家业界靠谱的网络设备厂商如H3C、Cisco等,是保障初期网络稳定性的必要条件。初期组网拓扑结构图如图9-1所示。
图9-1 初期组网拓扑结构图
第一阶段的网络结构采用了传统分层的Layer 2组网网络,物理上区分了互联网接入层、核心层、接入层设备。自上而下,我们先看互联网接入层。
互联网接入层互联网接入层设备可以选择路由器,也可以选择三层交换机,这里就不展开介绍这两种设备的功能区别了。在某案例中,第一阶段的互联网接入层设备采用的是三层交换机,主要基于两个因素考虑。
(1)端口密度:在流量未形成规模时,同时对互联网接入层设备没有过多功能要求时(初期只运行简单的静态路由),三层交换机的端口密度指标作为优先考虑的条件。
(2)成本问题:同样的成本,端口使用量是路由器的几倍,三层交换机的性价比更高。通常在数据中心接入互联网线路时,线路提供商可以提供如下几种不同的接入方式(不同的互联网供应商可能提供的方式有所区别)。◎ VRRP主备线路◎ ECMP双主线路
在初期网络建设中,互联网接入层设备采用的是双上联接口VRRP主备方式,在互联网流量较小的情况下基本可以满足对业务带宽和冗余的需求。关于互联网接入线路的选择,由于不同数据中心的规模和承建方、人力投入、技术支持、运营能力都不一样,导致数据中心提供的线路也有所区别。
国内比较常见的现象是,一级运营商直接提供数据中心资源,那么数据中心内只能有一级运营商的线路资源。例如,中国联通的数据中心只能提供中国联通的互联网线路。在由二级运营商承建或由不同的一级运营商联合建设的数据中心(此类较少)是可以提供多线或多种单线线路资源的。
线路资源可以分为如下两类。◎ 单运营商线路:中国联通、中国电信、中国移动等国内一级运营商线路。◎ 多运营商BGP线路:双线、四线、六线、八线国内二级运营商提供的线路。
单运营商线路由于是一级运营商直接提供的,所以单线资源在质量、扩容、故障、成本这4个方面要略优于多线资源。但由于中国各运营商自治和网间结算流量费昂贵,导致业务层面需要使用额外技术手段(如DNS调度、全局负载均衡、CDN等)来提升不同区域和不同运营商用户的访问质量。
多运营商BGP线路是由二级运营商和各一级运营商建立的BGP邻居关系,将自有IP地址通过BGP在已建立邻居关系的一级运营商线路内广播。从应用角度来看,可以轻松地实现IP多线路的运行模式,不受骨干网各运营商之间的访问限制,提升了应用访问的速度和品质。
目前国内家用宽带接入运营商以中国电信、中国联通为主,例如,主营客户端游戏的公司通常选择双线(中国电信、中国联通)的线路为主。但随着2008年中国移动和中国铁通的合并和移动互联网的兴起,移动线路和教育网在各数据中心中所占的比重也越来越重要了。各运营商流量占比如图9-2所示。
图9-2 各运营商流量占比
在用户至上的时代,显然在初期使用多线BGP线路这种复合型线路资源解决用户的问题是立竿见影的。但随着业务规模的扩张、调度系统的完善,以及对成本方面的考虑,多线BGP线路的弊端也逐步显现出来。
首先就是成本的压力 ,随着用户量的增加,带宽数量也呈现突飞猛进的增长态势,以四线BGP线路和单运营商线路为例,它们的成本差距在5倍左右,在强调“节能环保”的今天,这种成本的差距显然是不可接受的。
其次是故障率和冗余切换能力 ,由于多线BGP线路主要是二级运营商承建的,从网络角度来看,多一跳就意味着多一个故障的隐患。
再者是冗余切换能力 ,多线BGP线路在冗余切换上分为两类,业内称为真BGP多线和伪BGP多线,两者的区别在于真BGP多线实现了各大一级运营商线路路由的互相备份,当多线BGP线路中其中一个运营商线路出现故障时,故障运营商线路上的路由可以通过其他线路进行绕行访问;然而,伪BGP多线则只能实现多线路的用户访问覆盖,无法做到各线路路由的互相备份,当伪BGP多线其中一个运营商线路出现故障时,网络工程师能做的只是等待运营商进行故障修复。
还有就是多线BGP线路定向扩容能力。多线BGP线路的优势在于它具备优秀的线路整合能力,将原本复杂的互联网环境简单化。这种复合型线路资源势必会产生多资源配比的问题,例如,我们购买了1Gbps的四线BGP线路,这是不是代表这4个运营商线路我们单独都能跑到1Gbps呢?
答案肯定不是这样的。通常BGP带宽资源池中的中国电信、中国联通的带宽会比较富裕,但一些相对占比较少运营商的带宽往往会很少。比如某真实案例中,业务移动端流量爆发,导致移动运营商流量突增,从带宽监控图上看带宽Buffer空间仍然有很多富余,但论坛总是能收到用户投诉超时、连接不上服务器等问题。
最后梳理用户投诉发现均为移动用户,协同二级运营商排查后才确定为是由于二级运营商中的移动线路带宽瓶颈导致的。对于这个问题,由于多线BGP线路每家提供商的资源都有所不同,业界也没有一个固定配比原则,所以这部分依然是盲区,不容易规避。
核心接入层和服务器接入层初期在对业务发展毫无概念的情况下,选择一套简单的通用的组网方案和使用相对靠谱的网络设备是保障网络可用性的两个关键条件。
初期核心接入层和服务器接入层采用Layer 2传统二层互联的方式。这种Layer 2传统组网方式,接入交换机后端服务器的默认网关都在核心交换机上运行,核心交换机采用VRRP/HSRP(热备份冗余路由协议)提供一个虚拟地址为服务器默认网关。
核心接入层和服务器接入层运行STP(生成树协议)提供服务器接入层交换机双上联核心交换机冗余性。STP协议需要生成一个无环并且冗余的网络拓扑,基于 STP协议的特性,需要通过算法在核心和接入层之间选择一个接口将其置为Blocking状态,在默认情况下使用Forwarding状态的接口进行数据转发,当Forwarding状态的接口出现故障时,则再次进行STP计算,然后将原Blocking状态的接口置为(默认35秒完成)Forwarding状态后恢复数据传输。
Layer 2传统组网方式提供了便捷的服务器接入能力,服务器只需要接入交换机接口,并将接口归属到指定的VLAN即可完成服务器上线。但如果在此阶段没有良好的IP地址规划,以及在业务爆发期无规律地上线服务器,再加上某些特殊的应用需要在二层环境下才可以工作,如数据集群(Keepalived)、LVS-DR模式等,这样的需求和现状会导致需要频繁的对接口VLAN信息进行变更,工作量巨大。
为了避免此类操作,初期网络采取了比较粗暴的方式进行处理,在核心交换机SVI(Switch Virtual Interface)以辅助地址的形式运行多IP,这样可以解决因服务器上线和接口变更所带来的网络设备的变更问题(不过因此也为后期埋下了祸根)。interface vlan 100ip policy route-map LVS-DR(坑1)ip address 192.168.1.254 255.255.255.0(坑2)ip address 10.0.1.254 255.255.255.0 secondary(坑3)ip address 10.0.2.254 255.255.255.0 secondary大体上来看,这时的网络结构满足了业务需求,并且通过“技术手段”减少了烦琐的服务器上线和其他业务需要的网络设备变更问题,弥补了初期人力不足的短板。但实际上该阶段的网络规划并没有看起来那么美好和健壮。
比如在该案例中,使用了192.168.1.0/24地址给忘了运维带来了困扰。现在做IP地址规划大家一定不会选择B类192.168.0.0/16私有地址作为内网的主要地址。原因不止是B类地址比A类地址可使用的地址数少这么简单。这里面所带来的问题是,如果数据中心存在192.168.1.0/24这个网段的服务器,我们如何通过远程VPN的方式管理这台服务器呢?因为这个地址段默认被D-Link、TP-Link这些家用无线路由器厂商当作初始化的IP地址段。当我们使用PPTP或L2TP远程拨号VPN远程访问目标服务器时,由于本地直连路由比静态路由的优先级更高,所以访问远程目标服务器的数据不会通过VPN发往数据中心目标服务器,数据包会在本地局域网进行二层查询。
上面这个小问题只是让远程办公的同学们有些不爽而已,还没有真正地对生产网络产生影响。下面两个问题对初期网络造成了不可小觑的影响,一个是单SVI多IP工作模式引起的问题,二是LVS-DR工作模式引起的问题。
网络设备对不同的数据处理分别是基于控制层面和转发层面进行的。这部分内容在网络设备厂商官网有大量的介绍,这里就不详细讲解了。简单来说,进入数据控制层面的报文主要靠CPU能力进行处理,转发平面主要靠硬件能力进行处理。控制层面:控制层面就是各种协议工作的层面。
它的作用是控制和管理各种网络协议的运行。控制层面主要处理两类报文,一是抵达设备自身的,如Telnet、SSH、SNMP;二是负责网络选路和拓扑变化所使用的协议,如生成树协议、动态路由协议、组播协议,这些都是由控制层面直接进行处理的。控制层面的处理能力依赖设备自身的CPU性能,所以在网络优化中也需要对控制层面进行特殊的防护,如CoPP(Control Plane Policing,控制层面策略)。 总结:控制层面通过软件(CPU)处理,效率低。
转发平面:转发平面的工作主要是对穿越网络设备的报文进行处理,Layer 2数据包、Layer 3数据包、访问策略、QoS这些都属于转发平面的任务范畴。转发平面主要依赖设备接口芯片的处理能力。总结:转发平面通过硬件(芯片)处理,效率高。
在初期,某案例中,应用时常出现超时和访问失败等问题,排查后确定是由于核心交换机CPU负载高引起的(见图9-3),那么到底是什么原因引起的CPU负载高呢?
图9-3 核心交换机CPU负载高
原因一:
交换机在进行三层转发时,如果路由下一跳在一个二层网段或者在相同的VLAN下,则会产生ICMP Redirects报文,这种报文是直接进入交换机的控制层面处理的,这类流量由交换机CPU直接处理。单SVI多IP工作模式会过度产生直接由交换机CPU处理的报文,这是导致核心交换机CPU负载高的一个主因。High CPU Due to Excessive ICMP RedirectsYou can get ICMP dropped redirects when one VLAN (or any Layer 3 port) receives a packet where the source IP is on one subnet, the destination IP is on another subnet, and the next hop is on the same VLAN or layer 3 segment.
原因二:由于LVS-DR工作模式的特性,Real Server(后端目标服务器,后续简称RS)在进行响应时,需要使用服务器自身Lo绑定的VIP地址进行回包。LVS后端服务器存在两种部署模式,第一种为后端RS配置公网IP;第二种为后端RS配置内网IP。第一种模式下可以依赖后端RS自身的默认网关完成数据包的回包工作;第二种模式下则需要网络层通过PBR(Policy-Base Route,策略路由)对流量进行特殊的处理。
由于第一种部署模式会将后端服务器直接暴露在互联网上,存在安全风险,所以当初出于安全的考虑,后端服务器采用了第二种部署模式。这就导致需要在网络层使用PBR对这部分特殊的流量进行处理。某些低端核心交换机在开启PBR这个特性时存在一些限制,会导致导致核心交换机CPU负载过高。High CPU Due to Policy Based RoutingPolicy Based Routing (PBR) implementation in Cisco Catalyst 3750 switches has some limitations. If these restrictions are not followed, it can cause high CPU utilization.l You can enable PBR on a routed port or an SVI.l The switch does not support route-map deny statements for PBR.l Multicast traffic is not policy-routed. PBR applies only to unicast traffic.l Do not match ACLs that permit packets destined for a local address. PBR forwards these packets, which can cause ping or Telnet failure or route protocol flapping.l Do not match ACLs with deny ACEs. Packets that match a deny ACE are sent to the CPU, which can cause high CPU utilization.l In order to use PBR, you must first enable the routing template with the sdm prefer routing global configuration command. PBR is not supported with the VLAN or default template.
但随着大数据和分布式计算的应用,业务层面给网络带来的挑战还远远不止这些。分布式计算类型的服务会存在大量的数据交互和复制,其特点是:高带宽、大突发。它们在一定时间里被我们亲切地称之为“内网杀手”。以Hadoop为例,从图9-4可以看出,用户在推送数据块时数据节点之间的复制操作需要频繁地消耗接入层交换机的上行带宽,在初期上行收敛比还是12:1时(8口千兆上行,48口千兆下行),这部分流量必然会给相同机架的其他服务造成影响。
图9-4 分布式计算大量消耗内网上行宽带
针对此类业务的大数据交互的特性,在该案例中,做了以下两个方面的调整。
◎ 优化数据节点,减少跨机柜的交互。◎ 扩容接入层交换机,达到核心上行带宽。
刚才我们谈到收敛比时,应该有读者看出初期阶段核心和接入层之间存在的问题。8口千兆上行收敛比应该是6:1,为什么这里写的是12:1呢?就如之前所介绍的一样,核心和接入层之间运行的生成树协议(STP),天生就会浪费50%的带宽资源。STP会带来两个问题,一是资源浪费,二是冗余切换能力,如果当上行接口聚合组其中一个接口出现异常关闭时,那么接入层交换机的上行收敛比就又会减少1/4,并且这时STP并不会重新进行拓扑计算。
我们在处理Hadoop大流量的问题时,意识到STP这种古老的协议已经不适用于当前数据中心网络了。提升收敛比的首要任务就是将STP备份线路充分利用起来。
业界替代STP的组网方式有很多,如Layer 3组网、网络虚拟化、大二层。但这种在原有网络基础上改造的方式,不同于新建,更多的是需要考虑原有设备利用、割接窗口时长等客观因素。
所以在考虑上述因素后,改造方案选择使用网络虚拟化的方式替代STP组网方式(见图9-5)。这样可以在不更换接入层交换机的情况下,将原有收敛比提升一倍,并且很好地规避了前面提到的STP存在带宽浪费、冗余切换的问题。
图9-5 网络虚拟化
网络虚拟化技术有两个技术类别分支,分别是整机虚拟化和接口虚拟化。
整机虚拟化以Cisco VSS(Virtual Switching System) 和H3C IRF(Intelligent Resilient Framework)为代表,这类整机控制层面虚拟化已经是比较成熟的技术,已有很多商用案例。控制层面虚拟化提供了两种工作模式,分别是一虚多和多虚一,分别应对不同的场景。
多虚一的主要作用是简化网络结构,提升网络横向扩展能力。通常是两台设备进行多虚一,但目前也有部分厂商实现了N:1的整机虚拟化,如H3C IRFv2(Intelligent Resilient Framework 2,第二代智能弹性架构)技术目前最多可4台核心设备N:1虚拟化,H3C等较为主流的交换机产品线均支持IRFv2技术S1250、S9500E、S7500E、S5800等。一虚多技术多数用在虚拟化多租户环境下,整体提升硬件资源的利用率。此类技术多使用在金融和虚拟化公有云环境中。
接口虚拟化以Cisco VPC(Virtual Port Channel)和Arista MLAG(Multi-Chassis Link Aggregation)为代表,接口虚拟化和整机虚拟化在网络结构上没有太大的变化,都进行了跨设备的接口聚合操作。但由于接口虚拟化只关注跨设备的接口聚合,所以在核心层面依然需要使用HSRP/VRRP技术提供冗余支持。
在实际部署中对接口虚拟化各家厂商限制的条条框框较多,相比IRFv2整机虚拟化技术部署起来比较复杂,反观整机虚拟化提供最多4台核心设备的虚拟化能力,接口密度为乘的关系,去除了复杂的VRRP/HSRP配置和大量的地址配置,逻辑上只管理和监控一台设备,提供了良好的管理便利性(见图9-6)。
图9-6 整机虚拟化和接口虚拟化部署图
基于以上的分析,在应对初期Hadoop高带宽需求时,我们的解决方法是通过替换核心交换机设备,提升一倍的带宽收敛比,短暂性满足带宽需求,并且尽可能地将Hadoop业务放置在单独的机柜,以防止影响到其他业务。
初期网络运维总结在没有明确需求做数据支撑的前提下,组网方案只停留在了简单的设备堆砌阶段。应用存在不确定增长或大规模爆发情况时,对基础网络造成的冲击非常大。网络运维工程师这时主要承担了救火队的角色。
但这一阶段也有不少收获:第一,逐渐摸清了公司业务流量模型和特点,为后续的规划积累了数据;第二,通过不断的网络平台扩容、改建,总结出以下两条真理。◎ 改造的难度远大于新建。◎ 对于增长不确定的网络规划,核心交换机的规格和投入适当超前。
中期在该案例中,总设备数量的增长,推动了建设新数据中心的需求,让网络工程师有机会在“白纸”上重新构建基础网络,规避初期遇到的问题,重新梳理需求。网络建设和数据中心规模有着密切的关系,如原计划建设一个约500台服务器规模的数据中心,网络的设计容量为支持1000台设备,但如果业务增长超过数据中心规划,这样就导致又要去规划新的数据中心。
这种情况所带来的问题有以下几点。◎ 大量小规模数据中心管理复杂。◎ 数据中心网络设备投入成本大。◎ 小规模数据中心间互联是难题。
当发现这个现象后,为了避免后期出现上述几个问题,采取了“脱壳前进”的数据中心扩容方式。当存在更大规模的数据中心时,将规模小的进行撤离融合到大规模的数据中心去,整体的网络结构、建设成本、运维成本均得到了提升。但这里痛点不在网络层面,而是在业务层面。在这个阶段大量业务还不支持双数据中心冗余切换,需要有损地进行业务迁移。所以需要推动业务架构支持双数据中心部署,为后期双数据中心冗余打好基础。
中期阶段的网络规划在业务分区、边界安全、线路层等方面都进行了相应的优化。同时业务部门也对网络安全提出了更明确的需求,如业务线间安全隔离、互联网访问安全隔离等。下面让我们来看看中期阶段到底为什么这样规划?还遇到了什么挑战?
组网方案为将来建设支撑万台以上设备的大型网络积累经验,在中期规划了两套不同的组网方案,来对比各自的优缺点。但基础的业务分区、安全需求、LVS区域的实现是一致的。 中期组网结构如图9-7所示。
图9-7 中期组网结构图
我们在网络中明确了区域的概念,对公司的不同业务划分了区域。各区域使用不同的物理层设备进行物理和逻辑的双重隔离,做了IP地址段的分区规划,不同IP地址对应不同业务。这样做的好处是逻辑结构清晰,并且便于后续运维及权限划分。可以分为以下三大类:
◎ 互联网区域◎ 内网区域◎ DCI(Data Center Interconnection)区域
互联网区域互联网区域示意图如图9-8所示。主要功能是接入多条运营商线路,各线路入网对应不同的负载均衡集群(LVS),出网对应SNAT集群。入网、出网实现统一化、服务化。
图9-8 互联网区域示意图
如前文所述,该阶段,业务对网络的可用性、安全性都提出了更高的要求,所以运营商线路接入都是采用双上联ECMP方式进行的,并且在每条运营商线路的入向接口提供互联网接口白名单的规则。
LVS/SNAT集群和网络一起规划了OSFP的方式联动部署。LVS也升级到了FULLNAT模式,相比DR模式对网络的要求降低很多。从网络角度来看,FULLNAT的数据流是一个正常的从哪里来从哪里回的数据包,在网络层可以不用对这些报文做特殊的处理(策略路由)。这也极大地简化了网络的复杂程度,LVS的部署和详细内容可以参考LVS章节。
在某案例中,此阶段,互联网线路上更多的是关注质量、故障、成本三个因素,所以我们设计多线路的LVS集群方式,并建议应用尽量运行在互联网单线资源上。这里分享一些线路选择和带宽预留的原则。
1.互联网线路使用指引(1)可调度业务的电信、联通、移动用户使用单线资源覆盖。(2)可调度业务非三大运营商的用户使用多线BGP资源覆盖。(3)SNAT默认只提供BGP出网线路。 2.带宽预留原则(1)物理接口:物理接口使用总和的50%(单10Gbps接口带宽使用范围为5Gbps,双10Gbps负载接口带宽使用范围为10Gbps)。(2)逻辑带宽:带宽Buffer数量为最近一周带宽峰值的50%。
内网区域在某案例中,初期阶段在收敛比上吃了亏,在中期阶段专门规避了这个问题,收敛比初期设计为1:2,但随着采购量的增加和设备成本的下降,逐步地扩容到1:1。根据监控数据看非分布式计算业务机柜在2:1的收敛比下也可以良好地工作,这和业务自身调优也有比较大的关系。但分布式计算业务如Hadoop机柜则建议1:1收敛。
在实际部署中内网区域使用了两套当时比较主流的组网方案,这主要集中在核心接入层和服务器接入层之间。其中一种是Layer 3互联组网方案;另一种则是以Cisco Nexus系列为代表的Pod Design互联组网方案。这两套组网方案各有优劣势。
1.Layer 3互联组网Layer 3互联组网,顾名思义,是核心层和接入层运行OSPF或者BGP路由协议进行互联。业内一直有一种说法是,Layer 3互联组网是一种临时数据中心组网的过渡方案。这种说法其实没有错。我们可以设想一下,在核心设备不支持网络虚拟化或现在主推的大二层解决方案的年代之前(2009年Cisco Catalyst 6500平台开始支持网络虚拟化技术VSS),除了这种Layer 3互联组网方案,核心设备在当时是没有技术支持横向扩展的。
换个角度来说,就是一个数据中心可承载的服务器数量其实局限于核心设备的接口密度。Layer 3的解决方案在满足扁平化的基础上将数据中心可承载的服务器数量提升了8~16倍(主要参考ECMP的数量决定)。当然,Layer 3互联组网方式也完全规避了STP产生资源浪费和冗余切换时间长的问题。
(1)Layer 3互联组网的挑战Layer 3互联组网方式也对运维管理、成本提升、二层应用的部署带来了一定程度的挑战。◎ 运维管理首先,运维管理的挑战是IP地址管理、基础服务应用、接入交换机上限三个方面。可想而知,IP地址管理将变得很复杂。以4个核心为例,每台接入交换机上都会配置4个P2P(Point-To-Point)互联IP地址和一个服务器网段。如果服务器使用共享ILO(Integrated Lights-Out)管理方式,那么还将有服务器管理卡网段。在正常情况下每个接入交换机上将产生5~6个小网段。假设我们有200台接入交换机,在没有良好的CMDB系统协助管理记录的话,运维这种类型的网络难度可想而知。
其次,是基础服务应用。例如服务器上架和装机,因为每台接入交换机自治的原因,所以就需要服务器上架人员和装机人员对此类网络有充分的了解。但在实际环境中往往是负责上述工作的人员和构建网络人员分属两个不同的组或者部门,所属不同的专业维度,要求他们对网络结构、IP地址与网络工程师有一样的认识显然不太合适。最终就变成一些服务器上架和变更需要主机人员和网络人员配合,费时、费力,效率极低。
最后,是接入交换机上线。就如刚才所提到的IP地址管理的复杂性,在初期没有Netconf和Poap(Netconf和Poap实现网络设备加电后自动下发配置的功能)技术支持的情况下,一台接入交换机的初始化配置涉及大量的人工修改,配置的准确性和上线效率都潜在隐患。
◎ 接入交换机成本的提升在传输二层环境下,我们进行接入交换机选型主要关注接口密度、接口Buffer、背板带宽、转发能力、MAC地址容量这几个性能指标即可。但对于Layer 3互联组网,我们在关注上述指标之外,还需要关注设备是否支持三层功能、路由表的容量等信息。这样势必会带来接入交换机的成本提升。这部分设备在数据中心基数较大时,产生的成本量级还是比较大的。
◎ 二层应用部署典型的二层应用就是VRRP(热备份冗余路由协议),如需要提供虚地址方式进行集群冗余的应用,均依赖此协议(如Linux Keepalived)。这样导致依赖此协议的集群服务需要部署在相同的交换机上或者相同的机柜上。显然这样的部署方案在冗余上并不是那么完美。针对这种业务,在Layer 3互联组网方案中,通常的处理方式是将前后排背靠背两个机柜做成多虚一的虚拟机交换机,来满足不同的接入交换机和不同的机柜达到冗余的效果。这里还涉及一个现实的问题是,通常研发或应用运维提交服务器使用申请时是不会标注应用类型的。这样导致负责主机的人员在交付后还要针对使用这种类型的服务进行单独的机柜调整操作,涉及的工作量可想而知。
(2)Layer 3互联组网的优势不可否认,在特定的阶段Layer 3互联组网方案提供了良好的扩展性、冗余性、安全性,这也是此类组网方案的优势所在。扩展性主要体现在可以针对核心层面进行横向扩容;冗余性体现在支持多条冗余上行线路,并且有着良好的切换能力;安全性体现在众所周知的安全性最差的数据链路层上,减少了数据链路层广播风暴的可能性,降低了受广播风暴的影响,但是对特定应用存在一定的部署难题。Layer 3互联组网方式在核心设备与接入层设备品牌选择上提供了差异性支持。接触网络较早的读者一定清楚不同厂商的设备工作在STP环境下会产生莫名其妙的问题。这种组网方式可以规避此类问题,让不同品牌的核心设备和接入层设备工作在网络中。
2.Pod Design互联组网Pod Design互联组网方式,是Cisco Nexus交换平台上推出的组网方案,在物理结构上类似于传统的核心、汇聚、接入三层。实际部署的区别主要在汇聚和接入两层。传统的汇聚和接入采用Layer 2或Layer 3进行互联。 Pod Design以Pod概念替代传统区域的概念,在结构上差异并不大,但功能上略有差别,传统区域定义除了划分区域外,区域汇聚可以提供安全、负载均衡、流量控制等功能,这主要依赖汇聚交换机的设备产品形态。但当前数据中心的网络需求已经从多功能向高带宽、低延迟方向转变,这些较为复杂的功能已经不适合当前数据中心的网络需求了。Pod Design互联组网方案在这两层采用了俗称远端板卡接入方式(Fex),类似于在汇聚层和接入层进行纵向虚拟化,Pod内所有接口的操作、监控、变更在Pod两台核心设备上进行,简化网络结构、减少网络中可管理设备的台数。
(1)Pod Design互联组网的挑战Pod Design的设计思想是将网络按模块进行归类,这种思想和我们设计网络时提到的IP关联业务线不谋而合,甚至是天生就实现的。但此类组网方式也同样面临着Layer 3组网所遇到的三个挑战。◎ 运维管理运维管理所带来的挑战是布线系统 、Pod容量、管理风险三个方面。传统的数据中心核心到接入层布线有两种方式,即EoR(该方式指服务器机柜中所有的服务器接口,都通过跳线连接到机柜上的配线架,再由配线架上的铜缆延伸到网络机柜(位于一组机柜尾部)中的接入交换机)和ToR(该方式将接入交换机放置在每个服务器机柜顶部,机柜内服务器直接通过短跳线连接到顶部的交换机,再经由光纤从交换机的上行链路接口连接到核心交换机)这两种方式的优劣势网上分析文章很多,这里就不做过多的分析了。
目前主流的是ToR布线方式。但Pod互联组网模式的布线方式还和ToR方式略有不同,主要是在汇聚交换机提供到接入交换机的接口方式上有所区别。传统的ToR方式汇聚和接入设备分别提供4个10Gbps SFP+线缆接口互联接口,但Pod Design出于机架空间和端口密度的考虑,多数是提供如图9-9所示的40Gbps MPO线缆类型的接口。此时我们需要通过MPO-to-41C 针对汇聚和接入设备线缆进行跳接。
图9-9 40Gbps MPO线缆类型的接口
这带来了一个问题,就是线缆长度的问题。在设计此类型组网方式时,为了避免单一40Gbps接口故障影响过多的接入层上行带宽的容量,在实际环境中40Gbps接口是分别接入4台不同的接入层设备的,这样当汇聚单设备单40Gbps接口故障时,只是4台接入交换机上行带宽从40Gbps减少到30Gbps而已,这个带宽减少的比例还是可以接受的。
但根据机柜位置的不同,线缆长度也不同,在实际采购过程中发现MPO-to-4lc线缆都不提供定做LC侧超过10m以上规格的线缆。在部署和线缆备件的处理上都比较麻烦,所以采取的是汇聚交换机机架顶部配线架的方式,如图9-10所示。
图9-10 汇聚交换机机架顶部配线架
两个配线架以背靠背48端口LC方式对接,在这样的布线方式下,汇聚交换机使用短距MPO-TO-4LC线缆和配线架1对接,接入层设备根据机柜实际位置选择不同长度的线缆与配线架2互联完成对接。
这样的布线方式较为简单地解决了线缆长度和备件所带来的问题,同时也增加了管理成本,并且配线架背靠背对接存在后期维修故障的难度。这样的配线架模式在后期如果其中一对接口出现问题,那么基本上是不可维修的,因为在配线架上直接进行光纤熔接操作非常容易误碰到其他线缆引起不必要的损失。针对这个问题,布线厂商在后期提供了预端接布线方案,大家可以自行百度查看技术细节,主要是以模块化思路处理了这部分对接,出现异常可以通过更换预端接模块进行简单处理。
Pod内服务器容量设计依赖于厂商限定的条件,以Cisco Nexus为例,在主流千兆服务器接入环境下,根据汇聚交换机工作模式的不同,单Pod容量可分为1152台和2304台服务器两种规格。受限于这样的条件,我们面临Pod内部署什么样的业务,以及业务超过Pod容量后Pod间带宽如何计算配比等问题。
此类组网方式减少了网络可管理的设备台数,全网设备管理集中在几台核心设备上。这样带来的管理是一些较为轻量级的操作,如接入层接口配置变更等都需要登录核心汇聚设备进行。但是为后期的权限划分增加了难度。
◎ 成本问题Pod Design在成本问题上可以分为两块内容,分别是成本提升和成本优化。成本提升主要是在这类组网方案中多了一层汇聚交换机的成本投入。成本优化则体现在业务流量模型清晰化上,可以减少Pod间收敛比、设备板卡及模块的投入,但这个需要视实际业务情况而定。
◎ 二层应用部署二层应用部署其实面临着跟Layer 3互联组网一样的问题,只是在Layer 3二层环境中以接入交换机为单位,Pod Design以汇聚交换机为单位。
(2)Pod Design互联组网的优势Pod Design采用类似多虚一的虚拟化技术,剥离传统接入交换机的控制层面。这样的优势是以Pod为单位只管理两台汇聚交换机,劣势就是接入交换机只能工作在Pod Design工作模式下,因为它自身不具备控制层面,无法单独使用,如Cisco Nexus 2000系列。
安全的挑战安全是任何一家互联网公司都不能忽视的问题,但安全需求在执行落地时都会给业务发展和基础架构带来一定的挑战,在此阶段安全对网络提出了以下需求。
1.互联网端口白名单随着LVS平台对运维工程师的管理权限下放,以及一些LVS无法支持的业务直接暴露在公网上,需要在互联网入口做防护,其规则制定和访问控制是保障业务安全的第一要素。
网络和安全人员一起制定了默认的白名单端口范围,以及特殊端口的申请及审批流程。在某案例中,这个功能在讨论初期存在两种方案,其中一种是在各LVS集群生效访问控制;另一种是在网络设备如防火墙、交换机生效访问控制。在网络设备层面生效的优势是可以在最初的入口完成访问控制,这也是访问规则就近生效的原则。另外,对于部分直接暴露在互联网上的业务,在网络设备层面统一入口生效也有助于对这类业务的保护。
互联网端口白名单可以选择在出口互联网接入层交换机层面生效,也可以通过上层增加硬件防火墙生效。从安全角度出发,使用硬件防火墙是最好的选择,因为硬件防火墙自身是可以实现如Syn Flood、Ack Flood等攻击的防御的,并且基于会话的硬件防火墙可以非常轻松地实现业务单向访问的需求。反观交换机传输ACL隔离,仅可以实现单纯的访问控制,在单向访问和防御Syn Flood、Ack Flood攻击方面则显得无可奈何。
但最终我们还是选择在交换机层面实施互联网端口白名单,其中一个主要原因是设备性能,因为交换机不记录会话,所以会话的多少是不会直接影响交换机的转发性能的。反观硬件防火墙设备,防火墙设备在选型时考虑的两个重要指标就是并发数和每秒新建连接数。当存在高并发业务时,防火墙设备对此类业务的安全过滤显得有些力不从心。另一个原因是成本,在出口并发数为200万,支持200万并发的场景下,防火墙产品和交换机的价格可是天壤之别。
互联网端口白名单有两种实现模式,其中一种是黑名单即明确拒绝特定端口;另一种是白名单即明确允许特定端口。第二种模式明显限制得更为严格,并且具备完善的审批和记录机制,如果遇到安全问题,可以快速地进行事件追溯(也可以通过全流量分析完成)。但这也在一定程度上带来了人力成本的上升。可以根据实际情况酌情选择。
2.内网隔离内网隔离在金融和军政网络中存在比较多,坦白地讲,金融和军政内网隔离相对较容易实现,因为此类网络对服务器数量和未来流量的预期相对有据可依,所以对这类网络可以选择防火墙隔离或网闸等手段来完成内网隔离。
但互联网公司业务存在很多不确定性和高突发流量的情况,在安全和性能之间很难找到一个平衡点,所以在互联网公司内网隔离就变得难以实现。
需要实施内网隔离一般有以下场景。(1)第三方评审如PCI-DSS,全称为Payment Card Industry(PCI)Data Security Standard,第三方支付行业(支付卡行业PCI-DSS)数据安全标准。(2)非授信区域部署第三方开源应用区域,如Discuz、Phpwind等开源程序。(3)业务线间不同业务线均存在不同类型的敏感数据,并相互不信任其对方的安全性,要求不同业务线间进行内网隔离。
针对不同的场景,应当采用不同的隔离方案。首先,安全合规应用属于第三方评审要求,此类内网隔离建议采用硬件防火墙设备,在这种安全至上的业务面前,性能反而不是第一考虑因素了;其次,针对后两种场景的这类安全需求属于公司内部需求,且对网络性能要求很高,这类需求建议采取交换机ACL方式进行安全隔离。
但采取交换机ACL方式实现内网隔离困难和问题依然很多,这主要体现在功能、容量、管理与变更三个方面。① 功能比如ACL实现单向访问困难。在互联网端口白名单中问题不大,因为互联网涉及的IP较少,类型也比较单一。但应用在内网隔离中这部分缺陷就显现出来,内网应用协议繁多,如FTP、DNS这两类应用是不能通过传统ACL实现单向访问的。所以一个折衷的做法是将此类无法实现单向访问的应用和必要的服务(如YUM/NTP等)进行梳理全部放行,同时将此类服务定义为基础设施白名单,该名单中的服务默认在所有生效的ACL区域放行,进入此名单的服务需要通过完善的安全审核机制和流程,保障其安全性。
② 容量 这方面问题主要是因为后期业务之间调用繁多,超过交换机自身设备所能承载ACL条目的规格。交换机ACL规格和防火墙ACL规格不在一个数量级上,防火墙ACL规格在几万甚至几十万级别,但交换机ACL规格往往只在千级别。
③ 管理与变更设想一下,上千条访问规则分别应用在不同的设备上,管理与变更这么庞大的访问规则不是件容易的事情。
中期网络运维总结在这个阶段我们完成了数据中心网络标准化的雏形规划和建设,通过与业务磨合,清晰地了解了业务对网络的需求。随着业务从不规律到逐步稳定上升,业务部门可以提供一定的可参考数据,这对后期建设标准化数据中心网络提供了良好的数据积累。业务部分对网络可提供的服务也有了一定的了解,如数据中心容量、线路资源、安全特性等。在这个阶段数据中心网络模型满足当前业务的需求。
总结前两个阶段,是某真实案例中,从初期到当前现状的核心网络的进化史和血泪史,期间所使用的组网技术和方案不是业界先进的技术和解决方案,都是一些传统的技术和组网解决方案,所以在介绍中并没有过多的技术描述,涉及的技术大家可以自行搜索,有大量的技术文档可供参考。希望通过我们的介绍,让大家对处理不同业务需求和初期网络建设少走一些弯路。
近两年随着云计算的发力,公司在初期阶段和对网络自主性要求不高时,云主机的解决方案是一个非常不错的选择。但随着Docker和OpenStack这些虚拟化服务的大量应用,后期需要考虑的是如何在网络架构中更好地支持虚拟化业务。传统的网络架构提供的扩展性和稳定性已经远远不能满足云计算中心对网络的需求,除了扩展性和稳定性这些基本需求外,对网络灵活性和网络快速适配能力都有较高的要求。
业界应对主流云计算网络架构的技术有很多,如SPB、TRILL、FabricPath、VXLAN、OTV、SDN等,希望这些技术在我们正式应用后继续分享给大家。当然,这个阶段的网络还存在一些问题,如监控的精准度、网络管理自动化等。这些问题和业务无关,是网络自身的运维管理问题,我们希望后续通过平台化以及对上述新技术的研究解决这类问题。