Prometheus服务发现
文章目录
-
- Prometheus服务发现介绍
- relabeling功能
-
- relabeling简介
- relabeling规则
- 基于Kubernetes API的Prometheus服务发现
-
- k8s集群之内的Prometheus基于API Server实现服务发现
-
- apiserver服务发现及监控
- coredns服务发现及监控
- 集群node节点发现及监控
- 节点cadvisor发现及监控
- pod发现及监控
- k8s集群之外的Prometheus基于API Server实现服务发现
-
- RBAC授权
- 修改Prometheus配置
- 验证
- 基于consul的Prometheus服务发现
-
- 部署Consul
- 添加测试数据
- 修改Prometheus配置
- 验证
- 基于文件的Prometheus服务发现
- 基于DNS的服务Prometheus发现
Prometheus服务发现介绍
Prometheus默认是采用pull的方式拉取监控数据的,每一个被抓取的目标都要暴露一个HTTP接口,prometheus通过这个接口来获取相应的指标数据,这种方式需要由prometheus-server决定采集的目标服务器有哪些,通过配置在scrape_configs中的各种job来实现,无法动态感知新服务,如果后面新增了节点或组件,就需要手动修改prometheus配置,然后重启服务或重新加载配置,所以出现了动态服务发现。
动态服务发现能够自动发现集群中的新端点,并加入到配置中,通过服务发现prometheus能够自动获取需要监控的targets列表,然后通过这些targets获取监控数据。
Prometheus获取数据源target的方式有多种,包括静态配置和动态服务发现配置。prometheus目前支持的服务发现有很多种,具体可以参考prometheus的配置文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#configuration-file
常用的主要有以下几种:
- kubernetes_sd_configs:基于Kubernetes API实现的服务发现,让prometheus动态发现kubernetes中的被监控目标
- static_configs:静态服务发现,基于prometheus配置文件指定监控目标
- dns_sd_configs:基于DNS服务发现监控目标
- consul_sd_configs:基于Consul服务动态发现监控目标
- file_sd_configs:基于指定的文件发现监控目标
relabeling功能
relabeling简介
在Prometheus动态发现的targets中默认都包含一些原始的metadata标签信息,例如通过Kubernetes API动态发现的目标就包含许多以__meta开头的标签,如下图:
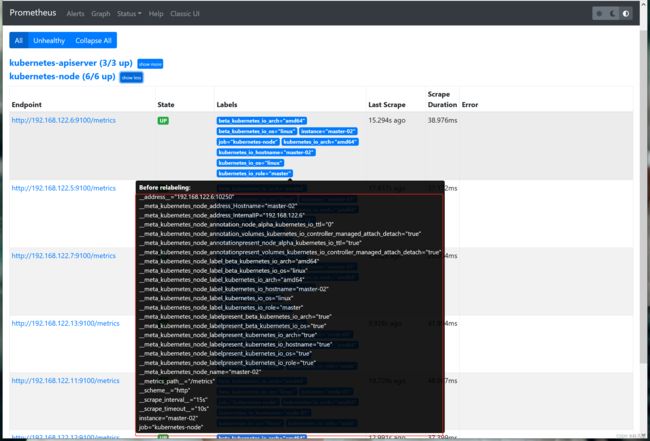
标签含义:
- _address_:以:信息显示目标targets的地址
- _scheme_:采集的目标服务器的Scheme形式,HTTP或等
- _metrics_path_:采集的目标服务器的访问路径
其它标签的含义可以参考Prometheus的官方配置文档。
prometheus的relabeling(标签重写)功能,它允许用户重写这些标签或根据标签做一些过滤操作。目前支持的relabel配置主要有以下4中,它的应用范围和生效时间不一样:
- relabel_configs:在对target进行数据采集之前,可以使用relabel_configs添加、修改或删除一些标签,也可以用来配置只采集特定目标或过滤目标,针对的是target,监控目标
- metric_relabel_configs :在对target采集数据之后,数据写入TSDB之前,可以使用metric_relabel_configs做重新标记和过滤,针对的是metric,指标
- alert_relabel_configs:在被发送到alertmanager之前,对标签进行处理,针对的是alert
- write_relabel_configs:写入远端存储之前进行标签处理
其中较为常用的就是relabel_configs,在配置监控目标时使用。后面介绍的也是relabel_configs

relabeling规则
Relabeling规则主要由以下字段组成:
| 字段 | 作用 |
|---|---|
| source_labels | 源标签,没有经过relabel处理之前的标签名 |
| separator | 分隔符,一个字符串,用于在连接源标签source_labels时分隔它们,默认是分号; |
| target_label | 通过action处理之后新的标签名字 |
| regex | 给定的值或正则表达式,用来匹配源标签的值 |
| action | 对源标签执行的relabeling动作,可选值和作用参考下个表格 |
| modules | 模数,串联的源标签哈希值的模,主要用于 Prometheus 水平分片 |
| replacement | 写在目标标签上,它可以引用regex正则表达式匹配的组$1、$2… |
action字段可用的值和含义如下:
| replace | 设置或替换标签值,是默认的action |
| keep | 源标签值满足regex正则条件的实例进行采集,其它实例丢弃,即只采集成功匹配的实例 |
| drop | 作用和keep相反,即只采集未匹配的实例 |
| labelmap | 将源标签的值映射到一组新的标签中去,action为labelmap时,regex匹配的是标签名,而不是标签值 |
| labelkeep | 保留匹配的标签,其它的进行删除 |
| labeldrop | 删除匹配的标签,保留不匹配的标签 |
| hashmod | 使用hashmod计算源标签的hash值并进行对比,基于自定义的魔术取模,以实现对目标进行分类、重新赋值等 |
基于Kubernetes API的Prometheus服务发现
基于Kubernetes API的服务发现主要通过Prometheus job配置中kubenetes_sd_configs字段来配置,具体配置方式可以参考官网:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
目前支持的发现目标类型有以下几种:
- node:发现node节点
- service:发现service
- pod:发现Pod
- enpoints:通过endpoints获取监控目标
- endpointslice:通过endpointslice获取监控目标
- ingress:发现ingress
k8s集群之内的Prometheus基于API Server实现服务发现
apiserver服务发现及监控
apiserver作为集群如入口,所有请求都是通过apiserver进来的,所以对apiserver指标做监控可以用来判断集群健康状态。我们可以通过目标类型为endpoints的kubenetes_sd_configs配置来自动发现apiserver并监控。
这里因为prometheus-server是部署在k8s集群上的,配置保存在configmap中,所以修改对应的configmap,内容如下:
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: kubernetes_apiserver #添加此job
kubernetes_sd_configs:
- role: endpoints #指定kubernetes_sd_configs发现角色为endpoint
scheme: https #指定访问apiserver协议
tls_config: #apiserver证书。证书和token都是通过ServiceAccount注入到Prometheus-server Pod中的
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
authorization: #访问apiserver的token
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs: #标签重写规则配置
- source_labels: ["__meta_kubernetes_namespace", "__meta_kubernetes_endpoints_name", "__meta_kubernetes_endpoint_port_name"] #指定要匹配的源标签
regex: default;kubernetes;https #匹配规则,这里表示只匹配名称空间为default,endpoints名称为kubernetes,且端口名称为https的实例
action: keep #action为keep,表示匹配的实例保留,然后进行监控
修改完成后,将configmap重新应用的集群中,然后重新加载prometheus配置。
kubectl apply -f prometheus-config.yaml
#重新创建prometheus Pod
kubectl delete pods/prometheus-aswcgth
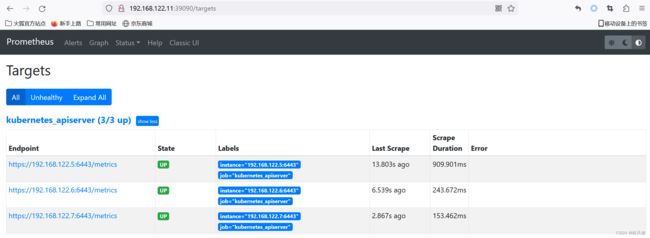
之后就可以在prometheus界面上看到已经自动发现了3个apiserver,状态都为UP
在Grafana导入模板来查看apiserver监控数据, 模板ID 12006
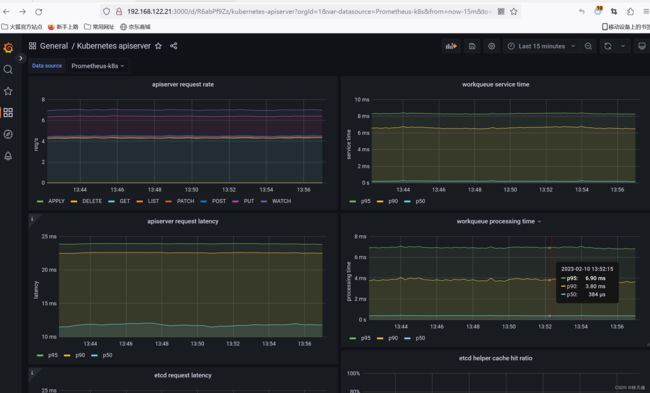
#查询API Server最近10分钟不同方法的请求数量总计
sum(rate(apiserver_request_total[10m])) by (resource,subresource,verb)
coredns服务发现及监控
修改保存prometheus配置的configmap,添加一个job,内容如下:
- job_name: "kubernetes-service-endpoints"
kubernetes_sd_configs:
- role: endpoints
relabel_configs: #标签重写规则
#如果endpoints对应的service资源上存在注解prometheus.io/scrape=true时,目标实例才会被发现为target
- source_labels: ["__meta_kubernetes_service_annotation_prometheus_io_scrape"] #
regex: true
action: keep
#通过service资源的注解prometheus.io/scheme获得抓取目标实例的数据时使用的协议(http或https),并赋值给新标签__scheme__
- source_labels: ["__meta_kubernetes_service_annotation_prometheus_io_scheme"]
regex: (https?)
action: replace
target_label: __scheme__
#通过service资源的注解prometheus.io/path获取目标实例提供监控数据的url路径,并赋值给新标签__metrics_path__
- source_labels: ["__meta_kubernetes_service_annotation_prometheus_io_path"]
regex: (.+)
action: replace
target_label: __metrics_path__
#修改__address__标签的值,即目标实例的地址和端口
- source_labels: ["__address__", "__meta_kubernetes_service_annotation_prometheus_io_port"]
regex: ([^:]+)(?::\d+)?;(\d+)
action: replace
target_label: __address__
replacement: $1:$2
#保留原来存在的以__meta_kubernetes_service_label_开头的标签
- regex: __meta_kubernetes_service_label_(.+)
action: labelmap
#将标签__meta_kubernetes_service_name修改为 kubernetes_service_name
- source_labels: ["__meta_kubernetes_service_name"]
action: replace
target_label: kubernetes_service_name
#将标签__meta_kubernetes_namespace修改为 kubernetes_namespace
- source_labels: ["__meta_kubernetes_namespace"]
action: replace
target_label: kubernetes_namespace
关于资源注解prometheus.io/scrape: true,需要在被发现的目的target定义此注解,且必须匹配成功该注解才会保留监控target,然后再进行数据抓取并进行标签替换,如annotation_prometheus_io_scheme标签为http或https。
修改完成后,将configmap重新应用的集群中,然后重新加载prometheus配置。步骤同上。
然后在prometheus界面查看,就可以看到已经发现了coredns对应的的Pod为target,状态为UP。如下图:
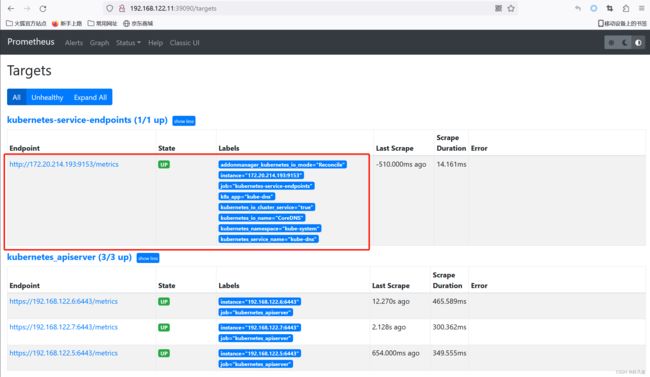
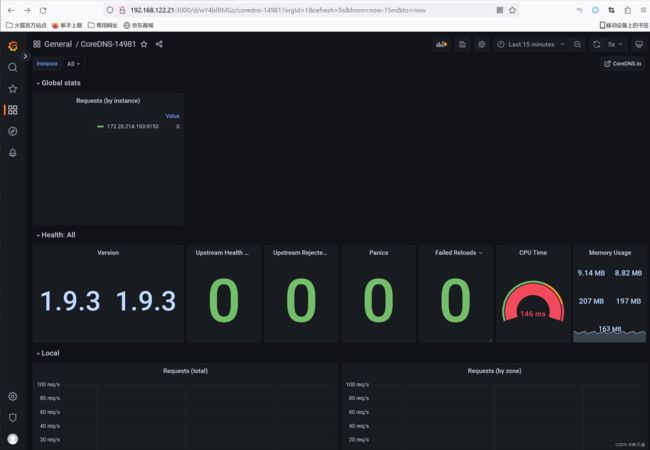
在Grafana导入coredns模板,查看监控数据,模板ID 14981
集群node节点发现及监控
需要提前在集群中每个节点上部署node-exporter服务,否则发现的target无法采集数据,状态为down。
修改保存prometheus配置的configmap,添加一个job,内容如下:
- job_name: "kubernetes-nodes"
kubernetes_sd_configs:
- role: node #指定发现类型为node
relabel_configs:
- source_labels: ["__address__"] #重写target地址,默认端口是kubelet端口10250,修改为node-exporter端口9100
regex: (.*):10250
action: replace
target_label: __address__
replacement: $1:9100
- action: labelmap #保留之前存在的__meta_kubernetes_node_label开头的标签
regex: __meta_kubernetes_node_label_(.+)
修改完成后,将configmap重新应用的集群中,然后重新加载prometheus配置
查看targets状态,相应的target都已经UP。如下图:

Granfana导入node-exporter模板查看数据,模板ID:1890

节点cadvisor发现及监控
可以通过添加下面的job配置,自动发现cadvisor。
- job_name: kubernetes-node-cadvisor
kubernetes_sd_configs:
- role: node
scheme: https #获取监控数据时使用的协议
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: ["__address__"] #重写__address__标签值,修改为集群内kubernetes Service资源域名
action: replace
target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: ["__meta_kubernetes_node_name"] #定义__metrics_path__,监控指标数据获取路径
regex: (.+)
action: replace
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
可以通过https://
修改完成后,将configmap重新应用的集群中,然后重新加载prometheus配置
查看targets状态,相应的target都已经UP。如下图:
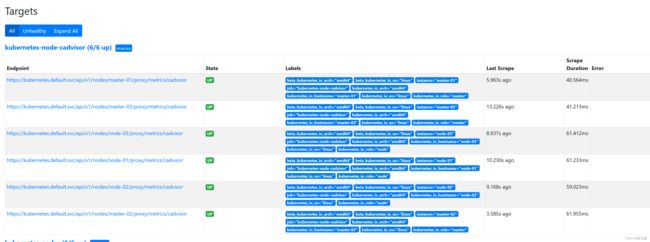
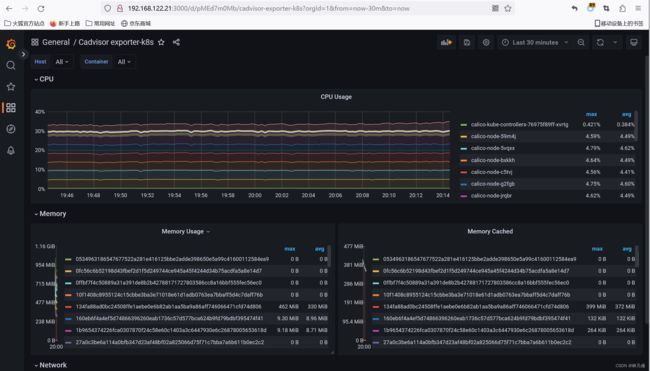
Grafana导入模板,查看数据,模板ID:14282
pod发现及监控
使用pod自动发现时,默认会将Pod上的每一个端口都发现为一个target。例如,一个Pod的定义中开放了2个端口80和3306,那么它就会被发现为两个target:http://
所以,建议在Pod上添加以下注解并结合promethesu relabel功能来实现pod的筛选,防止出现无用的target。
- promethesu.io/scrape:表明Pod是否提供监控指标数据,relabel规则会根据此标签判断是否保留Pod
- prometheus.io/scheme:获取Pod监控指标数据时使用的协议,http或https
- prometheus.io/port:获取Pod监控指标数据时使用的端口
- prometheus.io/path:获取Pod监控指标数据的url路径
可以通过添加下面的job配置,来实现Pod自动发现:
- job_name: kubernetes_pods
kubernetes_sd_configs:
- role: pod #发现类型为Pod
namespaces: #指定在哪些名称空间发现Pod
names:
- default
relabel_configs: #标签重写规则
#带有prometheus.io/scrape=true的Pod才会被保留
- source_labels: ["__meta_kubernetes_pod_annotation_prometheus_io_scrape"]
regex: true
action: keep
#根据Pod注解prometheus.io/scheme修改__scheme__标签值,如果Pod没有此注解,使用默认值http
- source_labels: ["__meta_kubernetes_pod_annotation_prometheus_io_scheme"]
regex: (https?)
action: replace
target_label: __scheme__
replacement: $1
#根据Pod注解prometheus.io/port修改__address__标签值,抓取数据的地址和端口
- source_labels: ["__address__", "__meta_kubernetes_pod_annotation_prometheus_io_port"]
regex: ([^:]+)(?::\d+)?;(\d+)
action: replace
target_label: __address__
replacement: $1:$2
#根据Pod注解prometheus.io/path修改__metrics_path__标签值,如果Pod没有此注解,使用默认值、metrics
- source_labels: ["__meta_kubernetes_pod_annotation_prometheus_io_path"]
regex: (.+)
action: replace
target_label: __metrics_path__
replacement: $1
- regex: __meta_kubernetes_pod_label_(.+)
action: labelmap
- source_labels: ["__meta_kubernetes_namespace"]
action: replace
target_label: kubernetes_namespace
- source_labels: ["__meta_kubernetes_pod_name"]
action: replace
target_label: kubernetes_pod_name
修改完成后,将configmap重新应用的集群中,然后重新加载prometheus配置
之后查看targets状态,如下图,只发现了default名称空间下的一个符合要求的Pod,其余Pod未被发现为target。
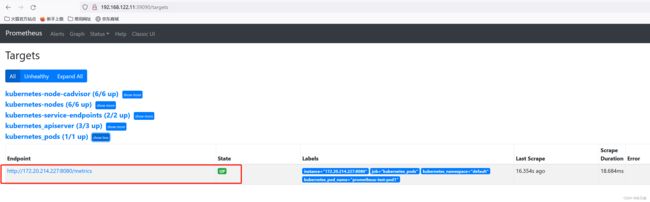

每个Pod提供的监控指标数据是不一样的,需要根据具体运行的应用来自己定制Grafana模板。
k8s集群之外的Prometheus基于API Server实现服务发现
上面的示例中Prometheus是部署在k8s集群内部的,可以直接和apiserver通信。如果是集群外部的Prometheus可以通过以下步骤配置通过API Server实现服务发现。
RBAC授权
集群外部的Prometheus访问API Server需要认证,还需要一定权限查询对应的资源对象。所以,这里先创建一个ServiceAccount和一个ClusterRole,并将它们绑定,之后集群外的Prometheus会以此ServiceAccount的身份访问API Server。yaml文件内容如下:
kind: ServiceAccount
metadata:
name: outside-prometheus
namespace: monitoring
---
apiVersion: v1
kind: Secret
metadata:
name: outside-prometheus-token
namespace: monitoring
annotations:
kubernetes.io/service-account.name: "outside-prometheus"
type: kubernetes.io/service-account-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: outside-prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: outside-prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: outside-prometheus
subjects:
- kind: ServiceAccount
name: outside-prometheus-token
namespace: monitoring
获取ServiceAccount对应Secret资源对象中保存的token,然后将token保存到Prometheus节点上的文件里。
root@master-01:~/resources# TOKEN=`kubectl get secret/outside-prometheus-token -n monitoring -o jsonpath={.data.token}|base64 -d`
root@master-01:~/resources# echo $TOKEN
eyJhbGciOiJSUzI1NiIsImtpZCI6IjhDekNIZGp5SWtEOVpoelcxdkgtTHh2OVlEUXh3Unl6QVJsSzZfcWI2QUUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtb25pdG9yaW5nIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6Im91dHNpZGUtcHJvbWV0aGV1cy10b2tlbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJvdXRzaWRlLXByb21ldGhldXMiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJmMjg3MThkOS00NmVkLTRjNjMtOTA5Ni03ZGEwZWMyNWM3NGIiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6bW9uaXRvcmluZzpvdXRzaWRlLXByb21ldGhldXMifQ.sXCo1OGB7_6ghDW0PgxD7q4JoaH07ESnYV_1fzHgoEqBkoq0w9tJE-oGrg5g01x8mMYiV_OBICb5JOsDUzEXsgJmtNejZoWvukrK5wA70X7NK9bg36ovRVe9JJKJaJ9thLl6rP8M8Lzw_sD7e57iX2ByHtE_pnMkQXMSIQhBRwAwNmRe-975OqeB0iOmt4NsEAM9g3alK4fhxFbsO8a6MGJ__HjZOzjti7XnSJsigtkeU6kfSkumVlsqNtMina35Fjzp1F743cZQimF-FRZSUuJ5Z1MCDRJGdhfrcIckXERm-TxWmNJRujjCmNMVLHw5NMvxxqUB7Jobuw1t3GY5Nw
在Prometheus 节点上
root@prometheus-server-01:/usr/local/prometheus# echo >/usr/local/prometheus/kubernetes-api-token
root@prometheus-server-01:/usr/local/prometheus# cat /usr/local/prometheus/kubernetes-api-token #和上面获取的对比是否一致
修改Prometheus配置
修改Prometheus配置,添加job
#集群api-server自动发现job
- job_name: kubenetes-apiserver
kubernetes_sd_configs:
- role: endpoints
api_server: https://192.168.122.18:6443 #指定API Server地址
#这里的配置证书和token是连接API Server做服务发现时使用
tls_config:
ca_file: /usr/local/prometheus/cert/kubernetes-ca.pem #指定kubernetes ca根证书,用于验证api-server证书
# insecure_skip_verify: true #也可以使用此选项跳过证书验证
authorization:
credentials_file: /usr/local/prometheus/kubernetes-api-token #指定访问api-server时使用的token文件
scheme: https
#这里的配置证书和token是连接从api-server抓取数据时使用
tls_config:
ca_file: /usr/local/prometheus/cert/kubernetes-ca.pem
authorization:
credentials_file: /usr/local/prometheus/kubernetes-api-token
relabel_configs:
- source_labels: ["__meta_kubernetes_namespace", "__meta_kubernetes_endpoints_name", "__meta_kubernetes_endpoint_port_name"]
regex: default;kubernetes;https
action: keep
#集群节点自动发现job
- job_name: "kubernetes-nodes"
kubernetes_sd_configs:
- role: node #指定发现类型为node
api_server: https://192.168.122.18:6443
tls_config:
ca_file: /usr/local/prometheus/cert/kubernetes-ca.pem
authorization:
credentials_file: /usr/local/prometheus/kubernetes-api-token
relabel_configs:
- source_labels: ["__address__"] #重写target地址,默认端口是kubelet端口10250,修改为node-exporter端口9100
regex: (.*):10250
action: replace
target_label: __address__
replacement: $1:9100
- action: labelmap #保留之前存在的__meta_kubernetes_node_label开头的标签
regex: __meta_kubernetes_node_label_(.+)
其实除了需要额外配置访问API Server的证书外,其余配置和集群内的Prometheus服务发现配置基本一致。另外,没有配置关于Pod的服务发现job,因为集群外的Prometheus无法访问集群内的Pod,应该需要添加路由规则才能实现互通,有时间再测试。
验证
配置修改完成后,重启Prometheus,然后在界面查看target状态。
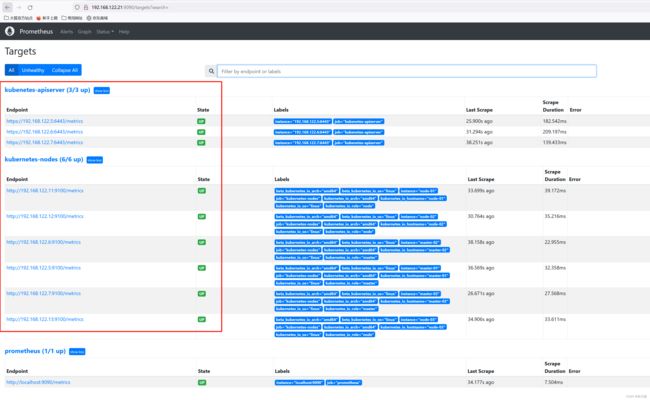
如上图,确认已经发现相应的target,并且为UP状态。
基于consul的Prometheus服务发现
Consul是分布式k/v存储集群,目前常用于服务的服务注册和发现。官网地址:https://www.consul.io/
基于Consul的服务发现主要通过Prometheus job配置中consul_sd_configs字段来配置,具体可以参考官方配置文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
部署Consul
使用3个节点来部署一个consul集群,环境信息如下
192.168.122.21 consul-node/prometheus-server
192.168.122.22 consul-node/node-exporter
192.168.122.23 consul-node/node-exporter
从官网下载安装包
https://developer.hashicorp.com/consul/downloads?host=www.consul.io
wget https://releases.hashicorp.com/consul/1.14.4/consul_1.14.4_linux_amd64.zip
unzip consul_1.14.4_linux_amd64.zip
mv consul /usr/bin
启动consul
第一个节点执行命令
mkdir -p /data/consul
nohup consul agent -server -bootstrap -bind=192.168.122.21 -client=192.168.122.21 -data-dir=/data/consul -ui -node=192.168.122.21 &
第二个节点执行命令
mkdir -p /data/consul
nohup consul agent -bind=192.168.122.22 -client=192.168.122.22 -data-dir=/data/consul -node=192.168.122.22 -join=192.168.122.21 &
第三个节点执行命令
mkdir -p /data/consul
nohup consul agent -bind=192.168.122.23 -client=192.168.122.23 -data-dir=/data/consul -node=192.168.122.23 -join=192.168.122.21 &
访问consul界面
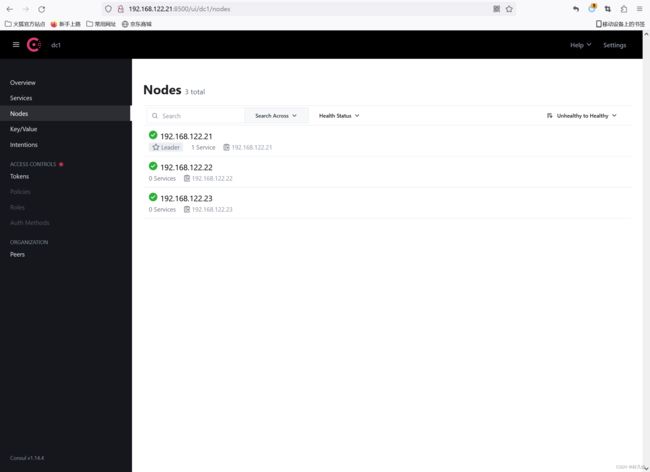
添加测试数据
将192.168.122.22&23两个节点上的node-exporter作为服务添加到consul,模拟服务注册
curl -X PUT -d '{"id": "node-exporter-1","name": "node-exporter","address":"192.168.122.22","port":9100,"tags": ["node-exporter"],"checks": [{"http":"http://192.168.122.22:9100/","interval": "5s"}]}' http://192.168.122.21:8500/v1/agent/service/register
curl -X PUT -d '{"id": "node-exporter-2","name": "node-exporter","address":"192.168.122.23","port":9100,"tags": ["node-exporter"],"checks": [{"http":"http://192.168.122.23:9100/","interval": "5s"}]}' http://192.168.122.21:8500/v1/agent/service/register
添加完成后,在Consul界面上验证是否添加成功

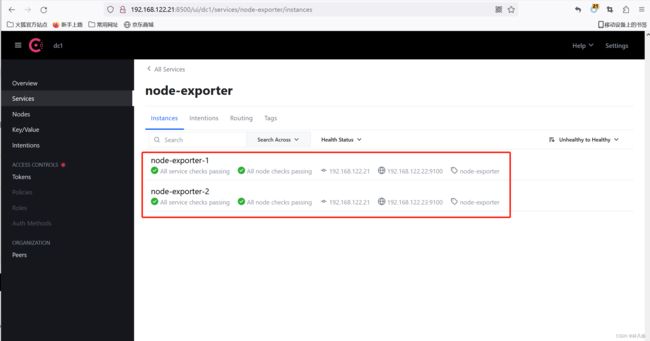
修改Prometheus配置
编辑Prometheus配置,添加job,内容如下:
- job_name: consul_service_discovery
consul_sd_configs:
- server: 192.168.122.21:8500 #指定Consul地址
services: [] #指定要发现的Consul Service资源,默认是所有service
- server: 192.168.122.22:8500
services: []
- server: 192.168.122.23:8500
services: []
scheme: http
metrics_path: /metrics
honor_labels: true
relabel_configs:
- source_labels: ["__meta_consul_service"]
regex: consul
action: drop
- source_labels: ["__meta_consul_tags"]
action: replace
target_label: product
- source_labels: ["__meta_consul_dc"]
action: replace
target_label: idc
honor_labels用来控制Prometheus如何处理已存在于抓取的数据上的标签和Prometheus将要附加到服务器端的标签之间的冲突(例如: job和instance标签、手动配置的target上的标签和服务发现自动生成的标签)
- 如果设置为true,则保留已抓取数据上的标签值并忽略Prometheus服务端准备附加的标签来解决冲突。另外,如果已抓取数据上有标签但值为空,则使用Prometheuss服务端准备附加的同标签的值;如果已抓取数据没有此标签,但Prometheus服务端配置了,那么就是用Prometheus服务端配置的
- 如果设置为false,则通过将已抓取数据上的冲突标签重命名为exported_(例如exported_job、exported_instance)来解决冲突
配置修改完成后,重启Prometheus服务,或重载配置
systemctl restart prometheus
验证
在Prometheus界面查看,可以看到已经发现了对应的target,状态为UP。如下图:
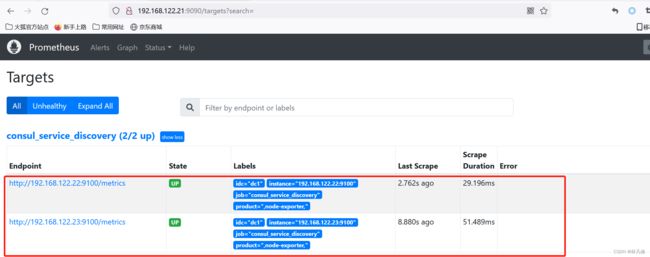
下面测试在Consul中删除一个node-exporter节点,验证Prometheus是否会自动删除对应target
curl --request PUT http://192.168.122.21:8500/v1/agent/service/deregister/node-exporter-1
然后再到Prometheus界面查看,发现192.168.122.22对应target已经被删除。如下图:

基于文件的Prometheus服务发现
Prometheus可以从指定的文件(json或yaml)中动态发现监控目标,如果文件发生修改,Prometheus会根据文件内容动态增加/删除target,无需重启服务。
基于文件的服务发现主要通过Prometheus job配置中consul_file_configs字段来配置,具体可以参考官方文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#file_sd_config
关于保存targets目标的json或yaml文件格式,在配置文档中也有介绍
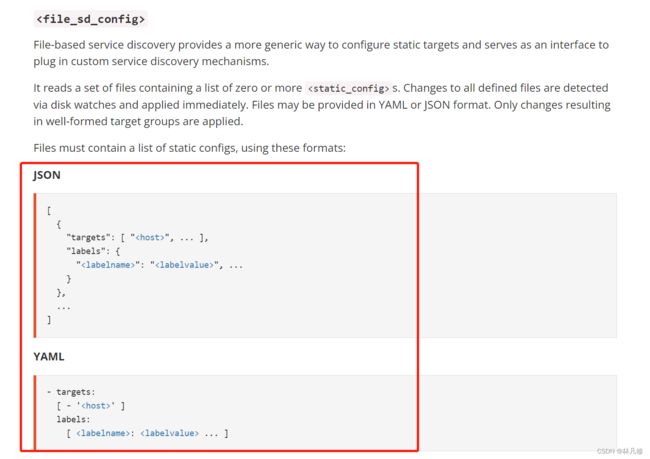
首先在Prometheus节点上准备一个target.json文件,用于保存targets,内容如下:
cat /usr/local/prometheus/file_sd/targets.json
[
{
"targets": [ "192.168.122.21:9100", "192.168.122.22:9100" ]
}
]
编辑Prometheus配置,添加job,内容如下:
- job_name: file_service_discovery
file_sd_configs:
- files: #指定保存targets文件位置,可以指定多个
- /usr/local/prometheus/file_sd/targets.json
refresh_interval: 10s #多长时间从指定的文件中加载一次targets
配置修改完成后,重启Prometheus
systemctl restart prometheus
验证,在Prometheus界面查看target状态,如下图,已经发现对应的target,状态为UP。
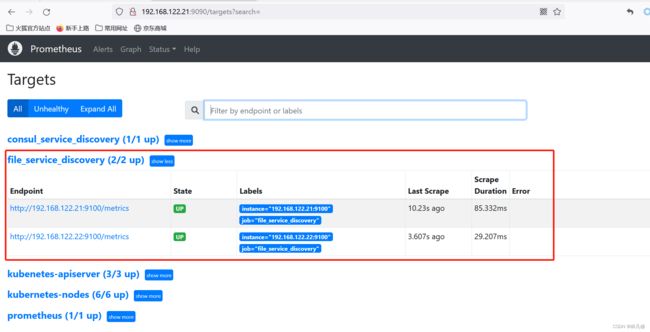
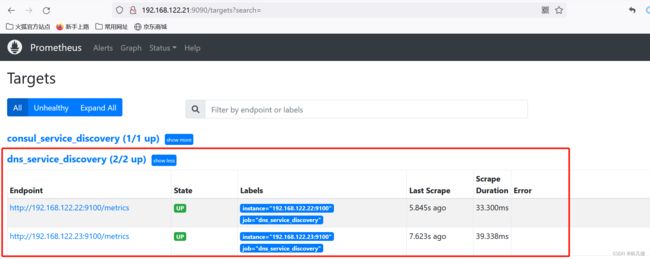
基于DNS的服务Prometheus发现
基于DNS的服务发现允许配置指定一组DNS域名,这些域名会被Prometheus定期查询以发现目标列表,域名需要可以被配置的DNS服务器解析为IP
此服务发现方法仅支持基本的DNS A记录、AAAA记录和SRV记录。
- A记录:域名解析为IP
- SRV记录:SRV记录了哪台计算机提供了具体哪个服务,格式为:自定义的服务名称.协议.域名(例如_example_server._tcp.www.myserver.com)
基于DNS的服务发现主要通过Prometheus job配置中dns_sd_configs字段来配置,具体可以参考官方配置文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#dns_sd_config
由于没有本地DNS服务器测试,所以在/etc/hosts中添加两条域名解析模拟DNS
root@prometheus-server-01:/usr/local/prometheus# cat /etc/hosts
192.168.122.22 node-01.linux.com
192.168.122.23 node-02.linux.com
编辑Prometheus配置,添加job,内容如下:
- job_name: dns_service_discovery
dns_sd_configs:
- names: ["node-01.linux.com", "node-02.linux.com"] #指定要解析的域名
type: A #指定DNS查询类型,A、AAAA或SRV
port: 9100 #查询类型不是SRV时的端口号
配置修改完成后,重启Prometheus
systemctl restart prometheus
验证,在Prometheus界面查看target状态,如下图,已经发现对应的target,状态为UP。