Linux内核进程,线程,进程组,会话组织模型以及进程管理
Linux 内核创世与创生
Linux宇宙诞生之时,创建了三个PID分别为0,1,2的进程, 你可以想象成成组件一个创业团队,第一步需要找到CEO,CTO,CFO,有管理,有技术,有钱,啥事都好办,可以继续发展壮大,三个角色就相当与LINUX内核的这三个初创进程。
创始成员的工号当然要从最前面开始选择,首先,由于初始从GRUB或者UBOOT跳入时刻没有进程存在,bringup阶段首先捏造了PID为0的swapper进程,之所以说是“捏造”,是因为创建0号进程没有依赖进程模板,0号进程之后的所有进程都有parent,但它没有parent,swapper对应task_struct对象init_task是静态分配,并且由bringup流程手动填充的,就好像凭空出现的一样,如同女娲造人一般创建的。有了第一个进程之后就好办了,新剩下的所有进程都是按照init_task swapper进程的样子clone的(通过内核fork),就不再是捏造了。swapper进程最后演化为内核idle进程,它是如此特殊,以至于用任何工具或者/proc文件系统,都找不到它的影子,但是它是却是实实在在存在着的。
swaper在完成自己的任务之前,创建了kernel thread init进程和kthreadd进程,然后就去养老了。把后面的工作留给了两个后继者。其中kernel_thread init进程完成了内核各类驱动的初始化,你看到的modue_init发起的内核驱动初始化调用,多半都是由处于内核态的kernel init进程发起的,kenrel_thread最终不满足于内核的禁闭,在内核态执行的最后阶段,完成了内核驱动初始化使命的init终于破土而出,成为了用户空间的第一个进程,化身了用户态宇宙的创世者。init 生子生孙,子子孙孙构成了丰富多彩的应用场景,完成这些任务后,INIT进程退居二线,承担起了为死去的进程收尸的工作,专门负责埋葬那些中途退出的进程。除了这些责任外,INIT进程还有两条其它进程不具备的能力,分别是起死回生和长生不老,不象人类世界,在Linux建立的秩序下,INIT进程永远不会退出,如果哪天它因为意外去世了,系统会去救活它,以维持秩序的运转。
kthreadd进程则始终在内核中坚守岗位,负责创造一个有一个像它一样默默无闻,兢兢业业而又重要之至的内核态工作线程,当你在驱动中用到workqueue,软中断,RCU等内核为你封装好的组件时,你要想到,其这背后有着kthreadd进程家族的一份功劳。
内核的创世很伟大,仅仅通过三个进程,便为我们创建了一个丰富的,可交互的世界。

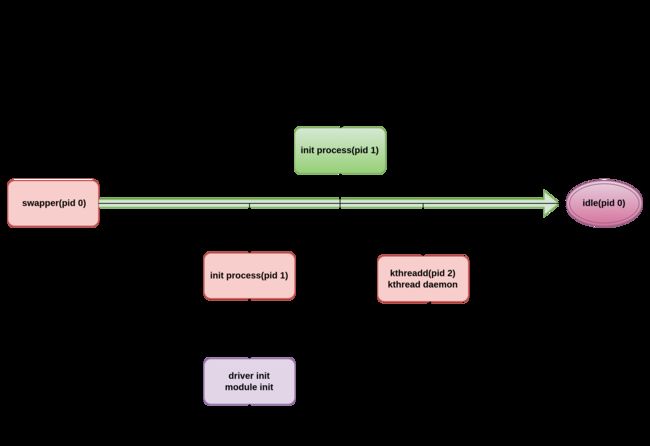
每一个进程都有一个唯一的标识,叫做PID,前面说到,系统启动时“手工”建立的swapper进程的PID为0,以后建立新进程时,使用前一个进程的PID+1,作为新进程的PID,PID是一个数字,用户可以通过/proc/sys/kernel/pid_max文件来设置最大的PID。

在支持多线程的操作系统中,一个进程拥有一个或多个线程,进程有进程ID,这些线程又有不同的线程ID,POSIX标准规定对于同一个进程的多个线程,有一个进程ID,多个线程ID,这样便可以根据PID向整个进程发送信号。但是在LINUX中,每个进程都对应一个struct task_struct结构,当建立线程时,其实也是建立一个struct task_struct结构,所以 task_struct有双重身份,既可以作为进程的TCB对象,也可以作为线程对象,这样即使同一个进程的多个线程,他们的PID都不相同,为此又定义了TGID,其实TGID才是真正意义上的进程ID,当创建一个进程时,该进程的PID和TGID一致。进程和线程归属同一个线程组。而PID==TGID的线程则属于thread group header,所以TGID是真正意义上的PID,而PID只是TID(Thread ID).
进程创建
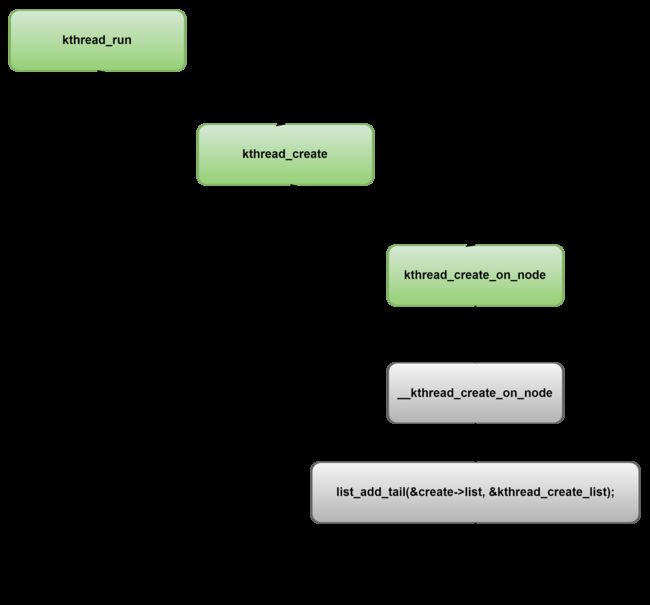
0号进程自不必多言,它是内核bringup阶段手工“捏造”出来的,没有parent,用户态进程通过系统调用clone实现,也无需赘述,只有内核线程kthreadd的子孙可以有多个创建接口,这些接口之间是有一定关系的,常用的kthead_run,kthread_create几种接口不外乎下面几种,他们的关系包括实现与被实现,调用与被调用,封装与被封装。
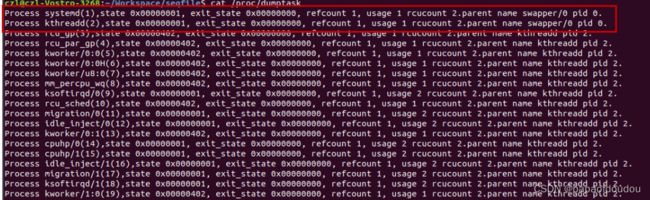
进程0有两个孩子,分别是PID为1的init进程和PID为2的kthreadd进程。

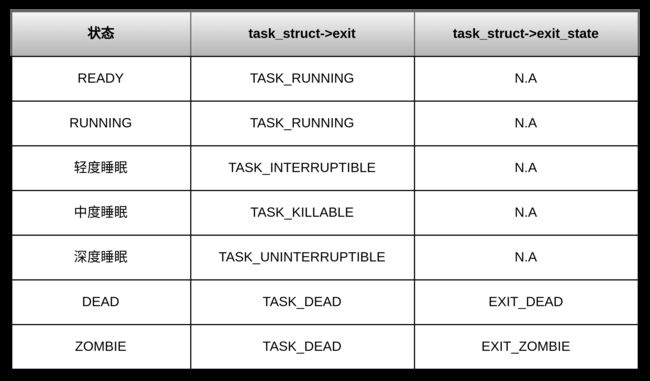
进程状态变迁/进程状态机
通过task_struct->state和task_struct->exit_state的不同组合,内和进程主要有如下几种状态。表中的task_struct->exit是笔误,应该是task_strucdt->state. struc task_struct中没有exit字段。
TASK INTERRUPBLE状态无法接受并处理信号,它是不可中断的睡眠状态,不会处理信号,无法用kill命令关闭处于TASK_UNINTERRUPTBLE的进程。中断处于这种状态的进程是不合适的。因为它可能正在完成某些重要的任务。当它所等待的事件发生时,进程将被显式的唤醒。
![]()


内核中msleep有两种实现,默认的实现是UNINTERRUPTBLE的,这一点要留意。

调用sleep进入休眠的进程处于TASK_INTERRUPTBLE浅睡眠的状态,可以响应信号。可以被KILL信号杀死。

TASK_UNINTERRUPTBLE虽然很强大,无法被唤醒,但是如果给它增加一个“累赘",就会变成可以唤醒的进程状态,这个状态名字叫做TASK_KILLABLE,表示是可以被SIGKILL杀死的,增加的标志叫做TASK_WAKEKILL。

怎么做到的呢?由于唤醒判断条件为或,所以增加了标志的TASK_KILLABLE虽然无法通过TASK_UNINTERRUPTBLE唤醒,但是仍然可以通过TASK_WAKEKILL标志唤醒。再次回到唤醒逻辑,可以看到当resume flag被置位后,带有TASK_WAKEKILL标志的进程就可以被唤醒了。
![]()

中度睡眠的典型唤醒路径如下图所示:
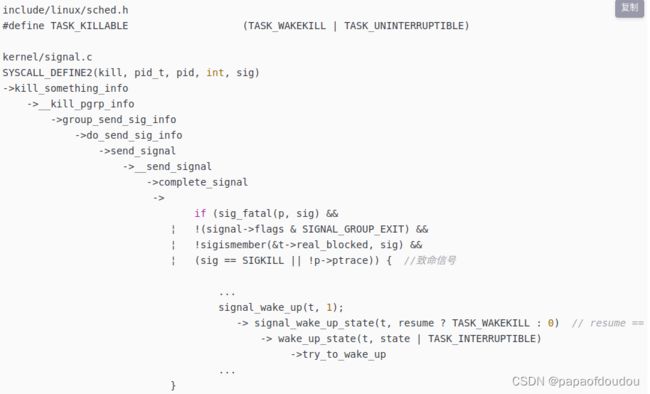
睡眠层次总结

唤醒睡眠状态任意的线程可以用wake_up_process,它可和唤醒处于深度睡眠状态的线程。

 状态转化
状态转化
状态之间的转化以及转化条件如下,可以看到,进入到ZOMBIE和DEAD的进程无法组成回路回到可运行状态,而其它状态则是连通的,可以组成回路,表示状态之间可以迁移往复。

一份PPT上的Linux状态解释,扩充了一些状态,相同状态部分两张图基本一致。

进程组与会话
进程组
什么是进程组?
- 进程组:一组协同工作或关联进程的集合,每个进程组有ID(PGID)
- 每个进程属于一个进程组,每一个进程组有一个进程组长,该进程组长ID(PID)与进程组ID(PGID)相同
- 一个信号可以发送给进程组的所有进程、让所有进程终止、暂停或继续运行.
会话
什么是会话?
会话是一个或多个进程组的集合
- 当用户登录系统时,登录进程会为这个用户创建一个新的会话(session)
- shell进程(如bash)作为会话的第一个进程,称为会话进程(session leader)
- 会话的PID(SID):等于会话首进程的PID
- 会话会分配给用户一个控制终端(只能有一个),用于处理用户的输入输出
- 一个会话包括了该登录用户的所有活动
- 会话中的进程由一个前台进程组和N个后台进程组构成
kernel hack module code:
source file:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
MODULE_AUTHOR("zlcao");
MODULE_LICENSE("GPL");
int seqfile_debug_mode = 0;
module_param(seqfile_debug_mode, int, 0664);
// 开始输出任务列表
// my_seq_ops_start()的返回值,会传递给my_seq_ops_next()的v参数
static void *my_seq_ops_start(struct seq_file *m, loff_t *pos)
{
loff_t index = *pos;
struct task_struct *task;
printk("%s line %d, index %lld.count %ld, size %ld here.\n", __func__, __LINE__, index, m->count, m->size);
if(seqfile_debug_mode == 0) {
// 如果缓冲区不足, seq_file可能会重新调用start()函数,
// 并且传入的pos是之前已经遍历到的位置,
// 这里需要根据pos重新计算开始的位置
for_each_process(task) {
if (index-- == 0) {
return task;
}
}
} else if(seqfile_debug_mode == 1) {
return NULL + (*pos == 0);
} else if(seqfile_debug_mode == 2) {
return NULL + (*pos == 0);
} else if(seqfile_debug_mode == 3) {
return NULL + (*pos == 0);
} else {
return NULL + (*pos == 0);
}
return NULL;
}
// 继续遍历, 直到my_seq_ops_next()放回NULL或者错误
static void *my_seq_ops_next(struct seq_file *m, void *v, loff_t *pos)
{
struct task_struct *task = NULL;
if(seqfile_debug_mode == 0) {
task = next_task((struct task_struct *)v);
// 这里加不加好像都没有作用
++ *pos;
// 返回NULL, 遍历结束
if(task == &init_task) {
return NULL;
}
} else if(seqfile_debug_mode == 1) {
++ *pos;
} else if(seqfile_debug_mode == 2) {
++ *pos;
} else if(seqfile_debug_mode == 3) {
++ *pos;
} else {
++ *pos;
}
return task;
}
// 遍历完成/出错时seq_file会调用stop()函数
static void my_seq_ops_stop(struct seq_file *m, void *v)
{
}
// 此函数将数据写入`seq_file`内部的缓冲区
// `seq_file`会在合适的时候把缓冲区的数据拷贝到应用层
// 参数@V是start/next函数的返回值
static int my_seq_ops_show(struct seq_file *m, void *v)
{
struct task_struct * task = NULL;
struct task_struct * p = NULL;
struct file *file = m->private;
if(seqfile_debug_mode == 0) {
seq_puts(m, " file=");
seq_file_path(m, file, "\n");
seq_putc(m, ' ');
task = (struct task_struct *)v;
seq_printf(m, "PID=%u, task: %s, index=%lld, read_pos=%lld\n", task->tgid, task->comm, m->index, m->read_pos);
} else if(seqfile_debug_mode == 1) {
struct task_struct *g, *p;
static int oldcount = 0;
static int entercount = 0;
char *str;
printk("%s line %d here enter %d times.\n", __func__, __LINE__, ++ entercount);
seq_printf(m, "%s line %d here enter %d times.\n", __func__, __LINE__, ++ entercount);
rcu_read_lock();
for_each_process_thread(g, p) {
if(list_empty(&p->tasks)) {
str = "empty";
} else {
str = "not empty";
}
seq_printf(m, "process %s(%d,cpu%d) thread %s(%d,cpu%d),threadnum %d, %d. tasks->prev = %p, tasks->next = %p, p->tasks=%p, %s.\n",
g->comm, task_pid_nr(g), task_cpu(g), \
p->comm, task_pid_nr(p), task_cpu(p), \
get_nr_threads(g), get_nr_threads(p), p->tasks.prev, p->tasks.next, &p->tasks, str);
if(oldcount == 0 || oldcount != m->size) {
printk("%s line %d, m->count %ld, m->size %ld.\n", __func__, __LINE__, m->count, m->size);
oldcount = m->size;
}
}
rcu_read_unlock();
} else if(seqfile_debug_mode == 2) {
for_each_process(task) {
struct pid *pgrp = task_pgrp(task);
seq_printf(m, "Group Header %s(%d,cpu%d):\n", task->comm, task_pid_nr(task), task_cpu(task));
do_each_pid_task(pgrp, PIDTYPE_PGID, p) {
seq_printf(m, " process %s(%d,cpu%d) thread %s(%d,cpu%d),threadnum %d, %d.\n",
task->comm, task_pid_nr(task), task_cpu(task), \
p->comm, task_pid_nr(p), task_cpu(p), \
get_nr_threads(task), get_nr_threads(p));
} while_each_pid_task(pgrp, PIDTYPE_PGID, p);
}
} else if (seqfile_debug_mode == 3) {
for_each_process(task) {
struct pid *session = task_session(task);
seq_printf(m, "session header %s(%d,cpu%d):\n", task->comm, task_pid_nr(task), task_cpu(task));
do_each_pid_task(session, PIDTYPE_SID, p) {
seq_printf(m, " process %s(%d,cpu%d) thread %s(%d,cpu%d),threadnum %d, %d.\n",
task->comm, task_pid_nr(task), task_cpu(task), \
p->comm, task_pid_nr(p), task_cpu(p), \
get_nr_threads(task), get_nr_threads(p));
} while_each_pid_task(pgrp, PIDTYPE_SID, p);
}
} else if(seqfile_debug_mode == 4) {
struct task_struct *thread, *child;
for_each_process(task) {
seq_printf(m, "process %s(%d,cpu%d):\n", task->comm, task_pid_nr(task), task_cpu(task));
for_each_thread(task, thread) {
list_for_each_entry(child, &thread->children, sibling) {
seq_printf(m, " thread %s(%d,cpu%d) child %s(%d,cpu%d),threadnum %d, %d.\n",
thread->comm, task_pid_nr(thread), task_cpu(thread), \
child->comm, task_pid_nr(child), task_cpu(child), \
get_nr_threads(thread), get_nr_threads(child));
}
}
}
} else {
printk("%s line %d,cant be here, seqfile_debug_mode = %d.\n", __func__, __LINE__, seqfile_debug_mode);
}
return 0;
}
static const struct seq_operations my_seq_ops = {
.start = my_seq_ops_start,
.next = my_seq_ops_next,
.stop = my_seq_ops_stop,
.show = my_seq_ops_show,
};
static int proc_seq_open(struct inode *inode, struct file *file)
{
int ret;
struct seq_file *m;
ret = seq_open(file, &my_seq_ops);
if(!ret) {
m = file->private_data;
m->private = file;
}
return ret;
}
static ssize_t proc_seq_write(struct file *file, const char __user *buffer, size_t count, loff_t *pos)
{
char debug_string[16];
int debug_no;
memset(debug_string, 0x00, sizeof(debug_string));
if (count >= sizeof(debug_string)) {
printk("%s line %d, fata error, write count exceed max buffer size.\n", __func__, __LINE__);
return -EINVAL;
}
if (copy_from_user(debug_string, buffer, count)) {
printk("%s line %d, fata error, copy from user failure.\n", __func__, __LINE__);
return -EFAULT;
}
if (sscanf(debug_string, "%d", &debug_no) <= 0) {
printk("%s line %d, fata error, read debugno failure.\n", __func__, __LINE__);
return -EFAULT;
}
seqfile_debug_mode = debug_no;
//printk("%s line %d, debug_no %d.\n", __func__, __LINE__, debug_no);
return count;
}
static ssize_t proc_seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{
ssize_t ret;
printk("%s line %d enter, fuck size %lld size %ld.\n", __func__, __LINE__, *ppos, size);
ret = seq_read(file, buf, size, ppos);
printk("%s line %d exit, fuck size %lld size %ld,ret = %ld.\n", __func__, __LINE__, *ppos, size, ret);
return ret;
}
static struct file_operations seq_proc_ops = {
.owner = THIS_MODULE,
.open = proc_seq_open,
.release = seq_release,
.read = proc_seq_read,
.write = proc_seq_write,
.llseek = seq_lseek,
.unlocked_ioctl = NULL,
};
static struct proc_dir_entry * entry;
static int proc_hook_init(void)
{
printk("%s line %d, init. seqfile_debug_mode = %d.\n", __func__, __LINE__, seqfile_debug_mode);
entry = proc_create("dumptask", 0644, NULL, &seq_proc_ops);
//entry = proc_create_seq("dumptask", 0644, NULL, &my_seq_ops);
return 0;
}
static void proc_hook_exit(void)
{
proc_remove(entry);
printk("%s line %d, exit.\n", __func__, __LINE__);
return;
}
module_init(proc_hook_init);
module_exit(proc_hook_exit); Makefile
ifneq ($(KERNELRELEASE),)
obj-m:=seqfile.o
else
KERNELDIR:=/lib/modules/$(shell uname -r)/build
PWD:=$(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
rm -rf *.o *.mod.c *.mod.o *.ko *.symvers *.mod .*.cmd *.order
endifinstall, the module support 3 dump method.
sudo insmod seqfile.ko seqfile_debug_mode=0
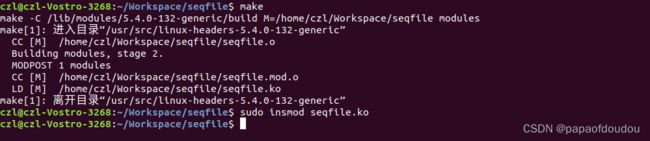
cat /proc/dumpstack
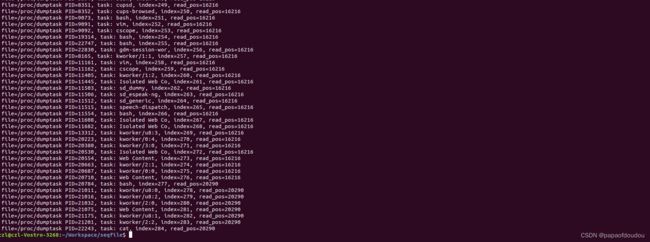
sudo insmod seqfile.ko seqfile_debug_mode=1

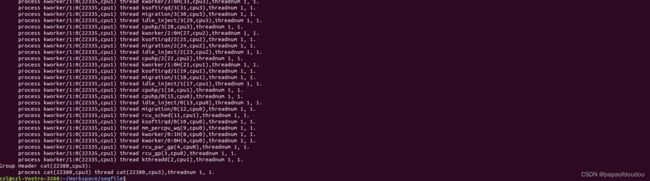
sudo insmod seqfile.ko seqfile_debug_mode=2
conclusion:
系统中所有的进程都组织在init_task的tasks链表下面,每个进程的线程组织在每个进程task_sturct->signal的链表下,如下图所示
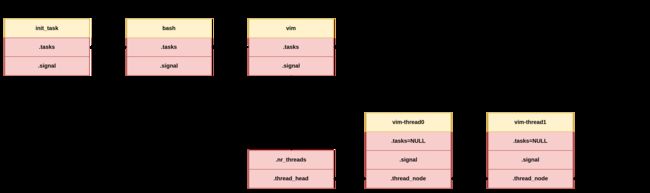
加入子进程的real_parent逻辑关系后,为下图所示:

the related implention in code:

the task struct structure member tasks are used to link all the system process together from init_task, but actually, the task struct member ->tasks in thread are not used. the should be null, but after get the value verbose by above module, you will find the are not empty in thread as belows:
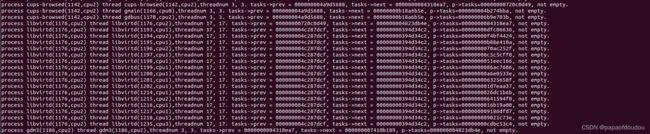
but why? may be this is inherent from the parent,but not used in child process, so it would be inherent from the parent, this not mean the are used. to prove this, we init the task_struct->task in copy_process function:

recompile the kernel and launch the test, you will find all the thread is empty,only the process group leader which link to init_task as process are not empty,说明上面所制的图是符合实际情况的。

获取进程内线程列表的方式:
上面介绍了通过struct task_struct->signal->thread_head成员获取一个进程线程列表的方式,其实除了这种方式,还有另一个方式,看代码:

如同singal成员的作用,group_leader似乎更加符合进程和线程的定位。并且内核中提供的处理对应链表的宏:

修改代码,增加新的case seqfile_debug_mode=5.
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
MODULE_AUTHOR("zlcao");
MODULE_LICENSE("GPL");
int seqfile_debug_mode = 0;
module_param(seqfile_debug_mode, int, 0664);
// 开始输出任务列表
// my_seq_ops_start()的返回值,会传递给my_seq_ops_next()的v参数
static void *my_seq_ops_start(struct seq_file *m, loff_t *pos)
{
loff_t index = *pos;
struct task_struct *task;
printk("%s line %d, index %lld.count %ld, size %ld here.\n", __func__, __LINE__, index, m->count, m->size);
if(seqfile_debug_mode == 0) {
// 如果缓冲区不足, seq_file可能会重新调用start()函数,
// 并且传入的pos是之前已经遍历到的位置,
// 这里需要根据pos重新计算开始的位置
for_each_process(task) {
if (index-- == 0) {
return task;
}
}
} else {
return NULL + (*pos == 0);
}
return NULL;
}
// 继续遍历, 直到my_seq_ops_next()放回NULL或者错误
static void *my_seq_ops_next(struct seq_file *m, void *v, loff_t *pos)
{
struct task_struct *task = NULL;
if(seqfile_debug_mode == 0) {
task = next_task((struct task_struct *)v);
// 这里加不加好像都没有作用
++ *pos;
// 返回NULL, 遍历结束
if(task == &init_task) {
return NULL;
}
} else {
++ *pos;
}
return task;
}
// 遍历完成/出错时seq_file会调用stop()函数
static void my_seq_ops_stop(struct seq_file *m, void *v)
{
}
// 此函数将数据写入`seq_file`内部的缓冲区
// `seq_file`会在合适的时候把缓冲区的数据拷贝到应用层
// 参数@V是start/next函数的返回值
static int my_seq_ops_show(struct seq_file *m, void *v)
{
struct task_struct * task = NULL;
struct task_struct * p = NULL;
struct file *file = m->private;
if(seqfile_debug_mode == 0) {
seq_puts(m, " file=");
seq_file_path(m, file, "\n");
seq_putc(m, ' ');
task = (struct task_struct *)v;
seq_printf(m, "PID=%u, task: %s, index=%lld, read_pos=%lld\n", task->tgid, task->comm, m->index, m->read_pos);
} else if(seqfile_debug_mode == 1) {
struct task_struct *g, *p;
static int oldcount = 0;
static int entercount = 0;
char *str;
printk("%s line %d here enter %d times.\n", __func__, __LINE__, ++ entercount);
seq_printf(m, "%s line %d here enter %d times.\n", __func__, __LINE__, ++ entercount);
rcu_read_lock();
for_each_process_thread(g, p) {
if(list_empty(&p->tasks)) {
str = "empty";
} else {
str = "not empty";
}
seq_printf(m, "process %s(%d,cpu%d) thread %s(%d,cpu%d),threadnum %d, %d. tasks->prev = %p, tasks->next = %p, p->tasks=%p, %s.\n",
g->comm, task_pid_nr(g), task_cpu(g), \
p->comm, task_pid_nr(p), task_cpu(p), \
get_nr_threads(g), get_nr_threads(p), p->tasks.prev, p->tasks.next, &p->tasks, str);
if(oldcount == 0 || oldcount != m->size) {
printk("%s line %d, m->count %ld, m->size %ld.\n", __func__, __LINE__, m->count, m->size);
oldcount = m->size;
}
}
rcu_read_unlock();
} else if(seqfile_debug_mode == 2) {
for_each_process(task) {
struct pid *pgrp = task_pgrp(task);
seq_printf(m, "Group Header %s(%d,cpu%d):\n", task->comm, task_pid_nr(task), task_cpu(task));
do_each_pid_task(pgrp, PIDTYPE_PGID, p) {
seq_printf(m, " process %s(%d,cpu%d) thread %s(%d,cpu%d),threadnum %d, %d.\n",
task->comm, task_pid_nr(task), task_cpu(task), \
p->comm, task_pid_nr(p), task_cpu(p), \
get_nr_threads(task), get_nr_threads(p));
} while_each_pid_task(pgrp, PIDTYPE_PGID, p);
}
} else if (seqfile_debug_mode == 3) {
for_each_process(task) {
struct pid *session = task_session(task);
seq_printf(m, "session header %s(%d,cpu%d):\n", task->comm, task_pid_nr(task), task_cpu(task));
do_each_pid_task(session, PIDTYPE_SID, p) {
seq_printf(m, " process %s(%d,cpu%d) thread %s(%d,cpu%d),threadnum %d, %d.\n",
task->comm, task_pid_nr(task), task_cpu(task), \
p->comm, task_pid_nr(p), task_cpu(p), \
get_nr_threads(task), get_nr_threads(p));
} while_each_pid_task(pgrp, PIDTYPE_SID, p);
}
} else if(seqfile_debug_mode == 4) {
struct task_struct *thread, *child;
for_each_process(task) {
seq_printf(m, "process %s(%d,cpu%d):\n", task->comm, task_pid_nr(task), task_cpu(task));
for_each_thread(task, thread) {
list_for_each_entry(child, &thread->children, sibling) {
seq_printf(m, " thread %s(%d,cpu%d) child %s(%d,cpu%d),threadnum %d, %d.\n",
thread->comm, task_pid_nr(thread), task_cpu(thread), \
child->comm, task_pid_nr(child), task_cpu(child), \
get_nr_threads(thread), get_nr_threads(child));
}
}
}
} else if(seqfile_debug_mode == 5) {
struct task_struct *g, *t;
do_each_thread (g, t) {
seq_printf(m, "Process %s(%d cpu%d), thread %s(%d cpu%d), threadnum %d.\n", g->comm, task_pid_nr(g), task_cpu(g), t->comm, task_pid_nr(t), task_cpu(t), get_nr_threads(g));
} while_each_thread (g, t);
} else {
printk("%s line %d,cant be here, seqfile_debug_mode = %d.\n", __func__, __LINE__, seqfile_debug_mode);
}
return 0;
}
static const struct seq_operations my_seq_ops = {
.start = my_seq_ops_start,
.next = my_seq_ops_next,
.stop = my_seq_ops_stop,
.show = my_seq_ops_show,
};
static int proc_seq_open(struct inode *inode, struct file *file)
{
int ret;
struct seq_file *m;
ret = seq_open(file, &my_seq_ops);
if(!ret) {
m = file->private_data;
m->private = file;
}
return ret;
}
static ssize_t proc_seq_write(struct file *file, const char __user *buffer, size_t count, loff_t *pos)
{
char debug_string[16];
int debug_no;
memset(debug_string, 0x00, sizeof(debug_string));
if (count >= sizeof(debug_string)) {
printk("%s line %d, fata error, write count exceed max buffer size.\n", __func__, __LINE__);
return -EINVAL;
}
if (copy_from_user(debug_string, buffer, count)) {
printk("%s line %d, fata error, copy from user failure.\n", __func__, __LINE__);
return -EFAULT;
}
if (sscanf(debug_string, "%d", &debug_no) <= 0) {
printk("%s line %d, fata error, read debugno failure.\n", __func__, __LINE__);
return -EFAULT;
}
seqfile_debug_mode = debug_no;
//printk("%s line %d, debug_no %d.\n", __func__, __LINE__, debug_no);
return count;
}
static ssize_t proc_seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{
ssize_t ret;
printk("%s line %d enter, fuck size %lld size %ld.\n", __func__, __LINE__, *ppos, size);
ret = seq_read(file, buf, size, ppos);
printk("%s line %d exit, fuck size %lld size %ld,ret = %ld.\n", __func__, __LINE__, *ppos, size, ret);
return ret;
}
static struct file_operations seq_proc_ops = {
.owner = THIS_MODULE,
.open = proc_seq_open,
.release = seq_release,
.read = proc_seq_read,
.write = proc_seq_write,
.llseek = seq_lseek,
.unlocked_ioctl = NULL,
};
static struct proc_dir_entry * entry;
static int proc_hook_init(void)
{
printk("%s line %d, init. seqfile_debug_mo