hadoop安装基础环境安装二
概述
hadoop 3.2.4版本; 修改hadoop的配置文件
相关链接
阅读之前,先浏览一下
hadoop 安装文章聚合
配置文件
如果以前安装过,清除相关数据 配置文件所在地 /data/soft/hadoop-3.2.4/etc/hadoop
[root@hadoop01 hadoop-3.2.4]# rm -rf /data/soft/hadoop-3.2.4
[root@hadoop01 hadoop-3.2.4]# rm -rf /data/hadoop_repo
hadoop-env.sh
[root@hadoop01 hadoop]# vi hadoop-env.sh
# 直接至最后位置
# jdk环境配置
export JAVA_HOME=/data/soft/jdk1.8
# hadoop log 目录配置
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
core-site.xml
注意
fs.defaultFS属性中的主机名需要和主节点的主机名保持一致
[root@hadoop01 hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 是 hadoop文件系统依赖的基本配置,比如跑MapReduce时生成的临时路径本质上其实就是生成在它的下面 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
<!-- 删除文件存在时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
####hdfs-site.xml
修改
hdfs-site.xml文件,将hdfs中文件副本数量设置为2,最多为2,因为现在集群中有两个从节点,还有secondaryNamenode进程所在的节点信息
[root@hadoop01 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop01:50090</value>
</property>
</configuration>
mapred-site.xml
设置mapeRduce使用的资源调试框架
[root@hadoop01 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
设置
yarn上支持运行的服务和环境变量白名单
[root@hadoop01 hadoop]# vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- spark_shuffle,yarn.nodemanager.aux-services.spark_shuffle.class 是spark开启shuffle时才需要配置,还需添加相关jar,否则报错;怕麻烦,只需要配置mapreduce_shuffle即可 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>spark_shuffle,mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs/</value>
</property>
</configuration>
workers
worker节点配置
[root@hadoop01 hadoop]# vi workers
hadoop02
hadoop03
hadoop04
修改脚本
以下四个文件之前加如下内容
start-dfs.sh
# start-dfs.sh
[root@hadoop01 hadoop]# cd /data/soft/hadoop-3.2.4/sbin/
[root@hadoop01 sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
stop-dfs.sh
[root@hadoop01 hadoop]# cd /data/soft/hadoop-3.2.4/sbin/
# stop-dfs.sh
[root@hadoop01 sbin]# vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh
# start-yarn.sh
[root@hadoop01 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
stop-yarn.sh
# stop-yarn.sh
[root@hadoop01 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
hadoop分发
将
hadoop01上配置好的hadoop 3.2.4版本分发
scp -rq /data/soft/hadoop-3.2.4 hadoop02:/data/soft/hadoop-3.2.4
scp -rq /data/soft/hadoop-3.2.4 hadoop03:/data/soft/hadoop-3.2.4
scp -rq /data/soft/hadoop-3.2.4 hadoop04:/data/soft/hadoop-3.2.4
格式化HDFS
格式化
hadoop01节点上的hdfs
[root@hadoop01 hadoop-3.2.4]# pwd
/data/soft/hadoop-3.2.4
[root@hadoop01 hadoop-3.2.4]# bin/hdfs namenode -format
2023-10-17 15:17:00,276 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1232874228-10.32.36.142-1697527020270
2023-10-17 15:17:00,284 INFO common.Storage: Storage directory /data/hadoop_repo/dfs/name has been successfully formatted.
2023-10-17 15:17:00,304 INFO namenode.FSImageFormatProtobuf: Saving image file /data/hadoop_repo/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2023-10-17 15:17:00,385 INFO namenode.FSImageFormatProtobuf: Image file /data/hadoop_repo/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2023-10-17 15:17:00,395 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-10-17 15:17:00,425 INFO namenode.FSNamesystem: Stopping services started for active state
2023-10-17 15:17:00,425 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-10-17 15:17:00,427 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
启动集群
[root@hadoop01 hadoop-3.2.4]# sbin/start-all.sh
Starting namenodes on [hadoop01]
上一次登录:二 10月 17 15:00:12 CST 2023pts/0 上
Starting datanodes
上一次登录:二 10月 17 15:18:45 CST 2023pts/0 上
Starting secondary namenodes [hadoop01]
上一次登录:二 10月 17 15:18:47 CST 2023pts/0 上
2023-10-17 15:18:55,630 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting resourcemanager
上一次登录:二 10月 17 15:18:51 CST 2023pts/0 上
Starting nodemanagers
上一次登录:二 10月 17 15:18:56 CST 2023pts/0 上
验证
# 主节点
[root@hadoop01 hadoop-3.2.4]# jps
13872 NameNode
14650 ResourceManager
14253 SecondaryNameNode
15150 Jps
# worker 节点不正常
[root@hadoop02 ~]# jps
16682 Jps
23595 DataNode
查看节点日志(我的日志在/data/hadoop_repo)
2023-10-17 16:04:56,080 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping NodeManager metrics system...
2023-10-17 16:04:56,080 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NodeManager metrics system stopped.
2023-10-17 16:04:56,080 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NodeManager metrics system shutdown complete.
2023-10-17 16:04:56,081 ERROR org.apache.hadoop.yarn.server.nodemanager.NodeManager: Error starting NodeManager
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2668)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.serviceInit(AuxServices.java:270)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceInit(ContainerManagerImpl.java:323)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:519)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:977)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:1057)
Caused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2660)
... 10 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2540)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2634)
... 11 more
2023-10-17 16:04:56,082 INFO org.apache.hadoop.yarn.server.nodemanager.NodeManager: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NodeManager at hadoop02/10.32.36.143
************************************************************/
原因我在
yarn-site.xml配置了spark_shuffle这个参数,如果只安装hadoop本身是不会有问题的
# 解决 将jar上传至主节点,配置完后,分发至worker节点,重新启动即可
# ${SPARK_HOME}/lib/spark-3.2.4-yarn-shuffle.jar 拷至 ${HADOOP_HOME}/share/hadoop/yarn/lib/
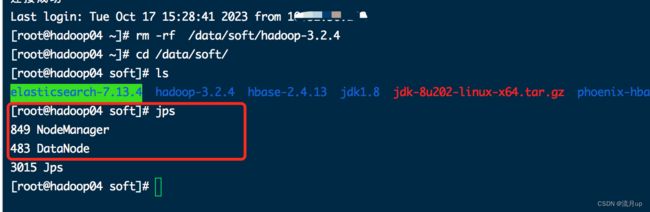
http://10.32.xx.142:9870/dfshealth.html#tab-datanode
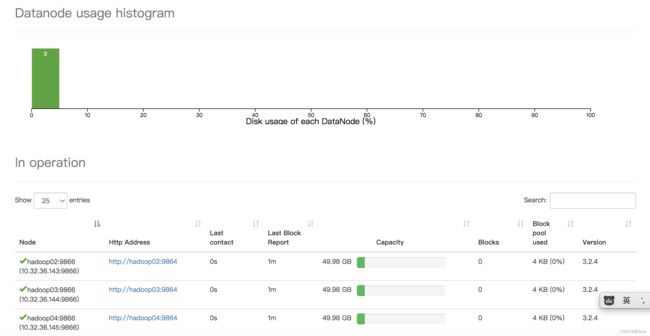
http://10.32.xx.142:8088/cluster/nodes

停止集群
[root@hadoop01 hadoop-3.2.4]# sbin/stop-all.sh
优化
四台机器8线程,16g,分配如下,每个
worker节点分配8线程,10g内存,yarn-site.xml添加如下配置
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>10240value>
<description>该节点上YARN可使用的物理内存总量description>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>8value>
<description>表示集群中每个节点可被分配的虚拟CPU个数description>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>1024value>
<description>每个容器container请求被分配的最小内存description>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>8096value>
<description>每个容器container请求被分配的最大内存,不能给太大description>
property>
<property>
<name>yarn.scheduler.minimum-allocation-vcoresname>
<value>1value>
<description>每个容器container请求被分配的最少虚拟CPU个数description>
property>
<property>
<name>yarn.scheduler.maximum-allocation-vcoresname>
<value>2value>
<description>每个容器container请求被分配的最多虚拟CPU个数description>
property>
效果如下图

结束
一主三从贴近生产的测试环境就出来了