【Spark Streaming】Spark Streaming整合kafka进行操作
目录
整合Kafka两种模式说明
spark-streaming-kafka-0-8
spark-streaming-kafka-0-10
Kafka手动维护偏移量
-
整合Kafka两种模式说明
Receiver接收方式
KafkaUtils.createDstream(开发中不用),Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦。
Receiver哪台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低!
Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护,
spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致
所以不管从何种角度来说,Receiver模式都不适合在开发中使用了,已经淘汰了
Direct直连方式
KafkaUtils.createDirectStream(开发中使用),Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高了并行能力
Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况
当然也可以自己手动维护,把offset存在mysql、redis中
所以基于Direct模式可以在开发中使用,且借助Direct模式的特点+手动操作可以保证数据的Exactly once 精准一次
总结:
Receiver接收方式
- 多个Receiver接受数据效率高,但有丢失数据的风险。
- 开启日志(WAL)可防止数据丢失,但写两遍数据效率低。
- Zookeeper维护offset有重复消费数据可能。
- 使用高层次的API
Direct直连方式
- 不使用Receiver,直接到kafka分区中读取数据
- 不使用日志(WAL)机制。
- Spark自己维护offset
- 使用低层次的API
关于消息语义
| 实现方式 |
消息语义 |
存在的问题 |
| Receiver |
at most once 最多被处理一次 |
会丢失数据 |
| Receiver+WAL |
at least once 最少被处理一次 |
不会丢失数据,但可能会重复消费,且效率低 |
| Direct+手动操作 |
exactly once 只被处理一次/精准一次 |
不会丢失数据,也不会重复消费,且效率高 |
注意
开发中SparkStreaming和kafka集成有两个版本:0.8及0.10+
0.8版本有Receiver和Direct模式(但是0.8版本生产环境问题较多,在Spark2.3之后不支持0.8版本了)
0.10以后只保留了direct模式(Reveiver模式不适合生产环境),并且0.10版本API有变化(更加强大)
-
spark-streaming-kafka-0-8
Receiver
KafkaUtils.createDstream使用了receivers来接收数据,利用的是Kafka高层次的消费者api,偏移量由Receiver维护在zk中,对于所有的receivers接收到的数据将会保存在Spark executors中,然后通过Spark Streaming启动job来处理这些数据,默认会丢失,可启用WAL日志,它同步将接受到数据保存到分布式文件系统上比如HDFS。保证数据在出错的情况下可以恢复出来。尽管这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是启用了WAL效率会较低,且无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。官方现在已经不推荐这种整合方式
Direct
Direct方式会定期地从kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者API读取一定范围的数据。
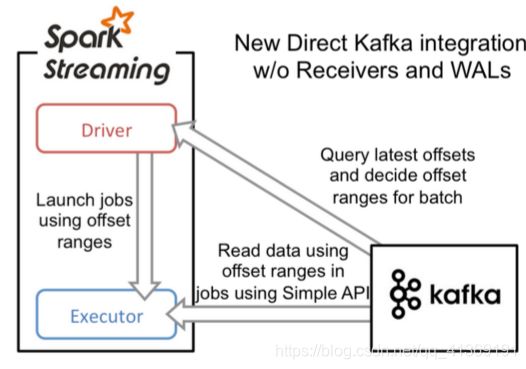
-
spark-streaming-kafka-0-10
pom.xml
org.apache.spark
spark-streaming-kafka-0-10_2.11
${spark.version}
API:http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
代码
//创建sparkConf
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("test01")
//创建SparkContext
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//创建StreamingContext
var ssc = new StreamingContext(sc, Seconds(5))
//设置临时数据存放位置
ssc.checkpoint("./tmpCount")
//准备连接Kafka的参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafkaDemo",
//earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
//这里配置latest自动重置偏移量为最新的偏移量,即如果有偏移量从偏移量位置开始消费,没有偏移量从新来的数据开始消费
"auto.offset.reset" -> "latest",
//false表示关闭自动提交.由spark帮你提交到Checkpoint或程序员手动维护
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//接收kafka数据并根据业务进行计算
//LocationStrategies.PreferConsistent 位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
//ConsumerStrategies.Subscribe 消费策略,源码强烈推荐使用该策略
//kafkaDatas含有key和value
//key:kafka生产数据是指定的key(可能为空)
//value:kafka生产的数据
val kafkaDatas: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Array("test01"), kafkaParams))
//根据业务逻辑进行计算
val kafkaWordAndOne: DStream[(String, Int)] = kafkaDatas.flatMap(z => z.value().split(" ")).map((_, 1))
val wordCount: DStream[(String, Int)] = kafkaWordAndOne.reduceByKeyAndWindow((x: Int, y: Int) => x + y, Seconds(10), Seconds(10))
//打印数据
wordCount.print()
//开启计算任务
ssc.start()
//等待关闭任务
ssc.awaitTermination()
-
Kafka手动维护偏移量
API:http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
代码
def main(args: Array[String]): Unit = {
//创建sparkConf
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
//创建SparkContext
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//5表示5秒中对数据进行切分形成一个RDD
val ssc = new StreamingContext(sc,Seconds(5))
//准备连接Kafka的参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafkaDemo",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//需要连接的主题
val topics = Array("spark_kafka")
//使用KafkaUtil连接Kafak获取数据
//如果MySQL中没有记录offset,则直接连接,从latest开始消费
//如果MySQL中有记录offset,则应该从该offset处开始消费
val offsetMap: mutable.Map[TopicPartition, Long] = OffsetUtil.getOffsetMap("SparkKafkaDemo","spark_kafka")
val recordDStream: InputDStream[ConsumerRecord[String, String]] = if(offsetMap.size > 0){//有记录offset
println("MySQL中记录了offset,则从该offset处开始消费")
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,//位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams,offsetMap))//消费策略,源码强烈推荐使用该策略
}else{//没有记录offset
println("没有记录offset,则直接连接,从latest开始消费")
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,//位置策略,源码强烈推荐使用该策略,会让Spark的Executor和Kafka的Broker均匀对应
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))//消费策略,源码强烈推荐使用该策略
}
//根据业务逻辑进行计算
//注意:我们的目标是要自己手动维护偏移量,也就意味着,消费了一小批数据就应该提交一次offset
//而这一小批数据在DStream的表现形式就是RDD,所以我们需要对DStream中的RDD进行操作
//而对DStream中的RDD进行操作的API有transform(转换)和foreachRDD(动作)
recordDStream.foreachRDD(rdd=>{
if(rdd.count() > 0){//当前这一时间批次有数据
rdd.foreach(record => println("接收到的Kafk发送过来的数据为:" + record))
//接收到的Kafk发送过来的数据为:ConsumerRecord(topic = spark_kafka, partition = 1, offset = 6, CreateTime = 1565400670211, checksum = 1551891492, serialized key size = -1, serialized value size = 43, key = null, value = hadoop spark ...)
//注意:通过打印接收到的消息可以看到,里面有我们需要维护的offset,和要处理的数据
//接下来可以对数据进行处理....或者使用transform返回和之前一样处理
//处理数据的代码写完了,就该维护offset了,那么为了方便我们对offset的维护/管理,spark提供了一个类,帮我们封装offset的数据
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (o <- offsetRanges){
println(s"topic=${o.topic},partition=${o.partition},fromOffset=${o.fromOffset},untilOffset=${o.untilOffset}")
}
//手动提交offset,默认提交到Checkpoint中
//recordDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
//实际中偏移量可以提交到MySQL/Redis中
OffsetUtil.saveOffsetRanges("SparkKafkaDemo",offsetRanges)
}
})
ssc.start()//开启
ssc.awaitTermination()//等待优雅停止
}
/*
手动维护offset的工具类
首先在MySQL创建如下表
CREATE TABLE `t_offset` (
`topic` varchar(255) NOT NULL,
`partition` int(11) NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint(20) DEFAULT NULL,
PRIMARY KEY (`topic`,`partition`,`groupid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
object OffsetUtil {
//从数据库读取偏移量
def getOffsetMap(groupid: String, topic: String) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test01?characterEncoding=UTF-8", "root", "root")
val pstmt = connection.prepareStatement("select * from t_offset where groupid=? and topic=?")
pstmt.setString(1, groupid)
pstmt.setString(2, topic)
val rs: ResultSet = pstmt.executeQuery()
val offsetMap = mutable.Map[TopicPartition, Long]()
while (rs.next()) {
offsetMap += new TopicPartition(rs.getString("topic"), rs.getInt("partition")) -> rs.getLong("offset")
}
rs.close()
pstmt.close()
connection.close()
offsetMap
}
//将偏移量保存到数据库
def saveOffsetRanges(groupid: String, offsetRange: Array[OffsetRange]) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test01?characterEncoding=UTF-8", "root", "root")
//replace into表示之前有就替换,没有就插入
val pstmt = connection.prepareStatement("replace into t_offset (`topic`, `partition`, `groupid`, `offset`) values(?,?,?,?)")
for (o <- offsetRange) {
pstmt.setString(1, o.topic)
pstmt.setInt(2, o.partition)
pstmt.setString(3, groupid)
pstmt.setLong(4, o.untilOffset)
pstmt.executeUpdate()
}
pstmt.close()
connection.close()
}
}