Java8 Stream流操作总结
这篇文章主要是从stream流角度梳理一下stream流特性。
1、介绍 从Java1.8开始提出了Stream流的概念,侧重对于源数据计算能力的封装。
Stream 流操作可以分为 3 种类型:
-
创建 Stream
-
Stream 中间处理
-
终止 Steam
中间处理只是一种标记,只有终止操作才会触发实际计算。 中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果; 结束操作又可以分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如 找到第一个满足条件的元素。之所以要进行如此精细的划分,是因为底层对每一种情况的处理方式不同。

2、创建 Stream
-
stream() : 创建一个新的stream串行流对象
-
parallelStream():创建一个可并行执行的stream流对象
-
Stream.of()/Stream.iterate()/Stream.generate():使用Stream的静态方法创建一个新的stream串行流对象
//集合创建串行流
Stream stream = Arrays.asList("a", "b", "c").stream();
//创建并行流
Stream parallelStream = Arrays.asList("a", "b", "c").parallelStream();
//使用Stream的静态方法
Stream stream3 = Stream.of(1, 2, 3, 4, 5, 6);
Stream stream4 = Stream.iterate(0, (x) -> x + 3).limit(4);
Stream stream5 = Stream.generate(Math::random).limit(3);

2.1 并行流
使用并行流可以有效利用计算机的多 CPU 硬件,提升逻辑的执行速度。并行流通过将一整个 stream 划分为多个片段,然后对各个分片流并行执行处理逻辑,最后将各个分片流的执行结果汇总为一个整体流。
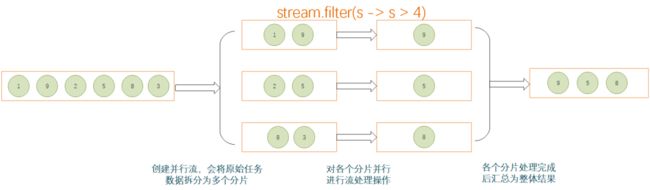
并行流类似于多线程在并行处理,所以与多线程场景相关的一些问题同样会存在,比如死锁等问题,所以在并行流终止执行的函数逻辑,必须要保证线程安全。
3、Stream 中间处理
负责对 Stream 进行处理操作,并返回一个新的 Stream 对象,中间管道操作可以进行叠加。

4、终止 Steam
通过终止Stream操作之后,Stream 流将会结束,最后可能会执行某些逻辑处理,或者是按照要求返回某些执行后的结果数据。
一旦一个 Stream 被执行了终止操作之后,后续便不可以再读这个流执行其他的操作了,否则会报错。

5、Stream收集器Collectors
Stream 主要用于对集合数据的处理场景,所以除了上面几种获取简单结果的终止方法之外,更多的场景是获取一个集合类的结果对象,比如 List、Set 或者 HashMap 等。
这里就需要 collect 方法出场了,collect是Stream流的一个终止方法,会使用传入的收集器(入参)对结果执行相关的操作,这个收集器必须是Collector接口的某个具体实现类,通常我们使用Collectors,Collectors是一个工具类,提供了很多的静态工厂方法,提供了很多Collector接口的具体实现类,是为了方便程序员使用而预置的一些较为通用的收集器(如果不使用Collectors类,而是自己去实现Collector接口,也可以)。
Stream结果收集操作的本质,其实就是将Stream中的元素通过收集器定义的函数处理逻辑进行加工,然后输出加工后的结果。
Collectors里常用搜集器如下:
[图片上传失败...(image-f61f89-1675853638951)]
[图片上传失败...(image-d0773e-1675853638951)]
初始案例:
List servers = new ArrayList<>();
servers.add("Felordcn");
servers.add("Tomcat");
servers.add("Jetty");
servers.add("Undertow");
servers.add("Resin");
5.1、类型归纳
这是一个系列,作用是将元素分别归纳进可变容器 List、Map、Set、Collection 或者ConcurrentMap 。
//Collectors.toList();
//Collectors.toMap();
//Collectors.toSet();
//Collectors.toCollection();
//Collectors.toConcurrentMap();
List list = servers.stream().collect( Collectors.toList()); 5.2、joining连接
将元素以某种规则连接起来。该方法有三种重载 joining(CharSequence delimiter) 和 joining(CharSequence delimiter,CharSequence prefix,CharSequence suffix)
// 输出 FelordcnTomcatJettyUndertowResin
servers.stream().collect(Collectors.joining());
// 输出 Felordcn,Tomcat,Jetty,Undertow,Resin
servers.stream().collect(Collectors.joining("," ));
// 输出 [Felordcn,Tomcat,Jetty,Undertow,Resin]
servers.stream().collect(Collectors.joining(",", "[", "]")); 用的比较多的是读取 HttpServletRequest 中的 body :
HttpServletRequest.getReader().lines().collect(Collectors.joining());
5.3、groupingBy 聚合
按照条件对元素进行分组,和 SQL 中的 group by 用法有异曲同工之妙,通常也建议使用 Java 进行分组处理以减轻数据库压力。groupingBy 也有三个重载方法 我们将 servers 按照长度进行分组:
// 按照字符串长度进行分组,符合条件的元素将组成一个 List 映射到以条件长度为key 的 Map> 中
Map> listMap = servers.stream().collect(Collectors.groupingBy(String::length));
// 生成Map>
Map> setMap = servers.stream().collect(Collectors.groupingBy(String::length, Collectors.toSet()));
我要考虑同步安全问题怎么办? 当然使用线程安全的同步容器啊,那前两种都用不成了吧! 看源码,其实第二种等同于下面的写法:
Supplier>> mapSupplier = HashMap::new;
Map> collect = servers.stream.collect(Collectors.groupingBy(String::length, mapSupplier, Collectors.toSet()));
这就非常好办了,我们提供一个同步 Map 不就行了,于是问题解决了:
Supplier>> mapSupplier = () -> Collections.synchronizedMap(new HashMap<>());
Map> collect = servers.stream.collect(Collectors.groupingBy(String::length, mapSupplier, Collectors.toSet()));
其实同步安全问题 Collectors 的另一个方法 groupingByConcurrent 给我们提供了解决方案。用法和 groupingBy 差不多。
5.4、collectingAndThen
该方法先执行了一个归纳操作,然后再对归纳的结果进行 Function 函数处理输出一个新的结果。
// 比如我们将servers joining 然后转成大写,结果为: FELORDCN,TOMCAT,JETTY,UNDERTOW,RESIN
servers.stream.collect(Collectors.collectingAndThen(Collectors.joining(","), String::toUpperCase));
5.5、partitioningBy 分区
分区是分组的特殊情况,由一个谓词(返回一个布尔值的函数)作为分类函数.所以返回的Map集合只有两个key,一个true,一个false.
// 长度大于5 {false=[Jetty, Resin], true=[Felordcn, Tomcat, Undertow]
Map> map = servers.stream().collect(partitioningBy(e -> e.length() > 5));
// 长度大于5 且 按照长度分组 ,即先分区再分组
//{false={5=[Jetty, Resin]}, true={6=[Tomcat], 8=[Felordcn, Undertow]}}
Map>> map2 = servers.stream().collect(partitioningBy(e -> e.length() > 5, groupingBy(String::length)));
5.6、counting 统计元素的的数量
该方法归纳元素的的数量,非常简单,不再举例说明。
// 5
long size = servers.stream().collect(Collectors.counting ());
5.7、maxBy/minBy 查找大小元素
这两个方法分别提供了查找大小元素的操作,它们基于比较器接口 Comparator 来比较 ,返回的是一个 Optional 对象。 我们来获取 servers 中最小长度的元素:
// Jetty
Optional min = servers.stream().collect(Collectors.minBy(Comparator.comparingInt(String::length)));
这里其实 Resin 长度也是最小,这里遵循了 "先入为主" 的原则 。当然 Stream.min() 可以很方便的获取最小长度的元素。maxBy 同样的道理。
5.8、summingInt/Double/Long 累加计算
用来做累加计算。计算元素某个属性的总和,类似 Mysql 的 sum 函数,比如计算各个项目的盈利总和、计算本月的全部工资总和等等。我们这里就计算一下 servers 中字符串的长度之和 (为了举例不考虑其它写法)。
// 总长度 32
servers.stream.collect(Collectors.summingInt(s -> s.length()));
5.9、summarizingInt/Double/Long 统计数据
如果我们对 5.6章节-5.8章节 的操作结果都要怎么办?难不成我们搞5个 Stream 流吗? 所以就有了 summarizingInt、summarizingDouble、summarizingLong 三个方法。 这三个方法通过对元素某个属性的提取,会返回对元素该属性的统计数据对象,分别对应 IntSummaryStatistics、DoubleSummaryStatistics、LongSummaryStatistics。我们对 servers 中元素的长度进行统计:
DoubleSummaryStatistics doubleSummaryStatistics = servers.stream.collect(Collectors.summarizingDouble(String::length));
// {count=5, sum=32.000000, min=5.000000, average=6.400000, max=8.000000}
System.out.println("doubleSummaryStatistics.toString() = " + doubleSummaryStatistics.toString());
结果 DoubleSummaryStatistics 中包含了 总数,总和,最小值,最大值,平均值 五个指标。
5.10、mapping
该方法是先对元素使用 Function 进行再加工操作,然后用另一个Collector 归纳。比如我们先去掉 servers 中元素的首字母,然后将它们装入 List 。
// [elordcn, omcat, etty, ndertow, esin]
servers.stream.collect(Collectors.mapping(s -> s.substring(1), Collectors.toList()));
有点类似 Stream 先进行了 map 操作再进行 collect :
servers.stream.map(s -> s.substring(1)).collect(Collectors.toList());
5.11 reducing
这个方法非常有用!但是如果要了解这个就必须了解其参数 BinaryOperator 。 这是一个函数式接口,是给两个相同类型的量,返回一个跟这两个量相同类型的一个结果,伪表达式为 (T,T) -> T。默认给了两个实现 maxBy 和 minBy ,根据比较器来比较大小并分别返回最大值或者最小值。当然你可以灵活定制。然后 reducing 就很好理解了,元素两两之间进行比较根据策略淘汰一个,随着轮次的进行元素个数就是 reduce 的。那这个有什么用处呢? Java 官方给了一个例子:统计每个城市个子最高的人。
Comparator byHeight = Comparator.comparing(Person::getHeight);
Map> tallestByCity = people.stream()
.collect(Collectors.groupingBy(Person::getCity, Collectors.reducing(BinaryOperator.maxBy(byHeight))));
结合最开始给的例子你可以使用 reducing 找出最长的字符串试试。
上面这一层是根据 Height 属性找最高的 Person ,而且如果这个属性没有初始化值或者没有数据,很有可能拿不到结果所以给出的是 Optional。 如果我们给出了 identity 作一个基准值,那么我们首先会跟这个基准值进行 BinaryOperator 操作。 比如我们给出高于 2 米 的人作为 identity。 我们就可以统计每个城市不低于 2 米 而且最高的那个人,当然如果该城市没有人高于 2 米则返回基准值identity :
Comparator byHeight = Comparator.comparing(Person::getHeight);
Person identity= new Person();
identity.setHeight(2.);
identity.setName("identity");
Map collect = persons.stream()
.collect(Collectors.groupingBy(Person::getCity, Collectors.reducing(identity, BinaryOperator.maxBy(byHeight))));
这时候就确定一定会返回一个 Person 了,最起码会是基准值identity 不再是 Optional 。
还有些情况,我们想在 reducing 的时候把 Person 的身高先四舍五入一下。这就需要我们做一个映射处理。定义一个 Function mapper 来干这个活。那么上面的逻辑就可以变更为:
Comparator byHeight = Comparator.comparing(Person::getHeight);
Person identity = new Person();
identity.setHeight(2.);
identity.setName("identity");
// 定义映射 处理 四舍五入
Function mapper = ps -> {
Double height = ps.getHeight();
BigDecimal decimal = new BigDecimal(height);
Double d = decimal.setScale(1, BigDecimal.ROUND_HALF_UP).doubleValue();
ps.setHeight(d);
return ps;
};
Map collect = persons.stream()
.collect(Collectors.groupingBy(Person::getCity, Collectors.reducing(identity, mapper, BinaryOperator.maxBy(byHeight))));