Django进阶之模型查询介绍及示例
本篇文章所使用模型查询都在《Django框架之模型自定义管理器》基础上讲解查询和使用示例,通过看前篇可以有助于理解内容。
概述
查询集:从数据库获取的对象集合
查询集可以有多个过滤器
过滤器就是一个函数,根据所给的参数限制查询集结果
从sql角度来说,查询集合与select语句等价,过滤器就像where条件
查询集
链式调用
在管理器上调用过滤器方法返回查询集
查询集经过滤器筛选后返回新的查询集,所以可以写成链式调用。
即:->filter()->filter()
惰性执行
创建查询集不会带来任何数据的访问,直到调用数据才会访问数据。
直接访问数据的情况:迭代、序列化、与if合用。
过滤器
返回查询集的方法称为过滤器
all() 不过滤,返回所有
filter() 保留符合条件的数据
filter(键=值)
filter(键=值,键=值)
filter(键=值)->filter(键=值)
exclude() 过滤掉符合条件的数据
order_by() 排序
values() 一条数据就是一个对象(字典),返回一个列表
返回单条数据
get()
返回一个(唯一)满足条件的对象
示例:
info = Students.stuObj2.get(id=1)注意:
如果没有找到符合条件的对象,会引发“模型类.DoesNotExist”异常
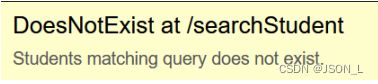
如果找到多个对象,会引发“模型类.MultipleObjectsReturned”异常

count()
返回当前查询集中的对象个数
需要借助于filter来过滤条件,或者不使用过滤器来获取数据全部条数
示例:
num = Students.stuObj2.count()
num = Students.stuObj2.filter(gender=0).count()first()
返回查询集中的第一个对象
示例:
one = Students.stuObj2.first()
one1 = Students.stuObj2.filter(gender=1).first()last()
返回查询集中的最后一个对象
示例:
last = Students.stuObj2.last()
last1 = Students.stuObj2.filter(gender=1).last()exists()
判断查询集中是否有数据,返回布尔值。
示例:
bool = Students.stuObj2.exists()
bool1 = Students.stuObj2.filter(id=1).exists()
bool2 = Students.stuObj2.filter(id=9).exists()update()
执行SQL update语句更新指定字段并返回匹配的数量(该数据仅与匹配的数据量有关)。
示例:
Students.stuObj2.filter(id=1).update(hobby='篮球', desc='三箭定天山')delete()
执行SQL delete语句删除全部匹配的QuerySet数据。
返回被删除的对象总数以及每一类对象具体被删除的数量。
示例:
Students.stuObj2.filter(id=9).delete()注意:当被删除的对象是其他模型数据的外键时,其他模型中相应的数据也会被删除。
限制查询集
查询集返回列表,可以使用下标方法进行限制,等同于mysql中limit。
注意:下标不能是负数
视图
def student_page(request, page):
"""学生列表分页"""
# (0-2) (2-4) (3-6)
# 1 2 3
count = 2
offset = (page - 1) * count
studentList = Students.stuObj2.all()[offset:(page * count)]
return render(request, 'myapp/students.html', {'studentsList': studentList})路由
path('studentPage/', views.student_page, name='studentPage') 模板
Templates/myapp/students.html
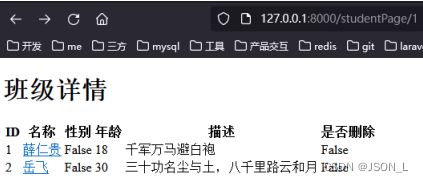
班级详情
班级详情
ID
名称
性别
年龄
描述
是否删除
{% for item in studentsList %}
{{item.id}}
{{item.name}}
{{item.gender}}
{{item.age}}
{{item.desc}}
{{item.isDel}}
{% endfor %}
可通过地址栏更换分页数字查看效果。
查询集的缓存
每个查询集都包含一个缓存,来最小化的对数据库访问。
在新的查询集中,缓存首次为空;第一次对查询集求值,会发生数据缓存,django会将查询出来的数据做缓存,并返回查询结果;之后的查询直接使用查询集缓存。
字段查询
实现了sql中的where语句,作为方法filter()、exclude()、get()的参数
语法:属性名称__比较运算符=值
外键:属性名_id
转义:like语句中使用%是为了匹配占位,匹配数据中的%(where like ‘\%’)
student = Students.stuObj2.filter(name__contains='李%')
print(student)![]()
可用于匹配%号,而不需要转义
比较运算符
exact
完全匹配运算符。由于完全匹配的使用频率最高,因此Django将exact定义为默认查询条件,如果在过滤语句中没有指定查询条件,那么Django将按照完全匹配查找数据。
如:
filter(isDel=False)等价于
filter(isDel_exact=False)contains
是否包含,大小写敏感
Students.stuObj2.filter(name__contains='张')startswith、endswith
以value开头或结尾,大小写敏感
Students.stuObj2.filter(name__startswith='张')注意:以上四个在前面加上i,就标识不区分大小写如iexact、icontains、istartswith/iendswith
isnull、isnotnull
对应SQL语句的IS NULL和IS NOT NULL,可接收参数值为True、False。
例如名称不为空的学生:
Students.stuObj2.filter(name__isnull=False)in
是否包含在范围内。
示例:
Students.stuObj2.filter(pk__in=[1, 2, 3, 4])range
字段值出现在一个区间中。
示例:
start_date = datetime.datetime(2023, 4, 22)
end_date = datetime.datetime(2023, 4, 24)
Grades.objects.filter(create_time__range=(start_date, end_date))gt 大于
gte 大于等于
lt 小于
lte 小于等于
student = Students.stuObj2.filter(age__gt=30)year、month、day、week_day、hour、minute、second
grades = Grades.objects.filter(create_time__year=2023)跨关联查询
处理join查询
语法:模型类名__属性名__比较运算符
Grades.objects.filter(students__desc__contains='天山')查询学生描述中带有天山这两个字数据是属于哪个班级
聚合函数
使用aggregate()函数返回聚合函数的值
avg、count、max、min、sum
引入Max
from django.db.models import Max计算学生中年龄最大的
student = Students.stuObj2.aggregate(Max('age'))结果:
![]()
F对象
可以使用模型的A属性与B属性进行比较
引入F对象
from django.db.models import F使用示例
Grades.objects.filter(girl_num__gt=F('boy_num'))还支持f对象的算术运算,时间的运算
Grades.objects.filter(girl_num__gt=F('boy_num')+10)Q对象
概述:过滤器的方法中的关键字参数,条件为and模式
需求:进行or查询
解决:使用Q对象
引入Q对象
from django.db.models import Q使用Q对象 取id大于3 或者 age大于30的学生
students = Students.stuObj2.filter(Q(pk__gt=3) | Q(age__gte=30))注意:只有一个Q对象,即匹配当前条件。
students = Students.stuObj2.filter(Q(pk__lte=3))加波浪线,表示取反
students = Students.stuObj2.filter(~Q(pk__lte=3))