flask工作原理与机制解析
文章目录
- 阅读flask源码
-
- 获取flask源码
- 如何阅读源码
-
- 1. 立足整体
- 2. 逐个击破
- 3. 由简入繁
- 4. 单步调试
- flask发行版本分析
- flask的设计理念
-
- "微"框架
- 两个核心依赖
- 显式程序对象
- 本地上下文
- 三种程序状态
-
- 1. 程序设置状态
- 2. 程序运行状态
- 3. 请求运行状态
- 丰富的自定义支持
- flask与WSGI
-
- WSGI程序
-
- wsgi实现示例
- Flask中的WSGI实现
- WSGI服务器
- 中间件
-
- wsgi使用中间件示例
- Flask使用中间件示例
- Werkzeug内置中间件
- Flask的工作流程与机制
-
- Flask中的请求响应循环
-
- 1. 程序启动
- 2. 请求In
- 3. 响应Out
- 路由系统
-
- 1. 注册路由
- 2. URL匹配
-
- Werkzeug中进行URL匹配
- FLask中如何根据请求的URL找到对应的视图函数
- 本地上下文
-
- 1. 本地线程与Local
- 2. 堆栈与LocalStack
- 3. 代理与LocalProxy
- 4. 请求上下文
- 5. 程序上下文
- 6. 总结
- 请求与响应对象
-
- 1. 请求对象
- 2. 响应对象
- session
-
- 1. 操作session
-
- session变量
- 查找真实的session对象
- 赋值到SecureCookieSession实例
- 写入到cookie
- 2. session起源
- 蓝本
- 模板渲染
- FQA
-
- app = Flask(__name__)中的__name__有什么作用?
阅读flask源码
为什么要阅读源码呢?
- 了解某个功能的具体实现。
- 学习Flask的设计模式和代码组织方式
获取flask源码
# 我们可以查看Flask从诞生(第一次提交)到最新版本的所有提交记录和发布版本。
git clone https://github.com/pallets/flask.git
如何阅读源码
使用pycharm的好处
- 了解模块代码结构
- 理清函数的调用关系
- 进行断点调试
查看pycharm的快捷键
- 导航栏 -> Help -> Keymap Reference
1. 立足整体
从结构上来说,Flask各个模块联系紧密,并不适合挨个模块从头到尾的线性阅读。我们需要先从整体上了解Flask,就像是读书先看目录一样。对于一个项目来说,我们需要了解flask包由哪些包和模块组成,各个模块又包含哪些类和函数,分别负责实现什么功能。
掌握Flask的整体结构还有一个有效的方法就是阅读Flask的API文档。API文档中包含了所有Flask的主要类、函数以及它们的文档字符串(Doc-string)。这些文档字符串描述了主要功能,还列出了各个参数的类型和作用。在阅读源码时,我们也可以通过这些文档字符串来了解相关的用法。掌握Flask的整体结构会为我们的进一步阅读打下基础。
- Flask程序包各模块分析表
| 模块/包 | 说明 |
|---|---|
| json/ | 提供JSON支持 |
| __init__.py | 构造文件,导入了所有其它模块中开放的类和函数 |
| __main__.py | 用来启动flask命令 |
| _compat.py | 定义python2与python3版本兼容代码 |
| app.py | 主脚本,实现了WSGI程序对象, 包含Flask类 |
| blueprint.py | 蓝本支持, 包含BluePrint类定义 |
| cli.py | 提供命令行支持, 包含内置的几个命令 |
| config.py | 实现配置相关的对象 |
| ctx.py | 实现上下文对象, 比如请求上下文RequestContext |
| debughelpers.py | 一些辅助开发的函数/类 |
| globals.py | 定义全局对象,比如request、session等 |
| helpers.py | 包含一些常用的辅助函数,比如flash(), url_for() |
| logging.py | 提供日志支持 |
| session.py | 实现session功能 |
| signals.py | 实现信号支持, 定义了内置的信号 |
| templating.py | 模板渲染功能 |
| testing.py | 提供用于测试的辅助函数 |
| views.py | 提供了类似Django中的类视图, 我们用于编写 Web API 的 MethodView 就在这里定义 |
| wrappers.py | 实现 WSGI 封装对象, 比如代表请求和响应的 Request 对象和 Response 对象 |
- 查看脚本的代码结构
选择模块 -> 点击左侧的structure标签 -> 查看PyCharm中的symbol图标
2. 逐个击破
在了解了Flask的整体结构后,我们就可以尝试从某一个功能点入手,了解具体的实现方法。在这种阅读方式下,我们可以从某一个函数或类开始,不断地深入。
- 全局搜索
双击Shift键。或 单击Navigate -> Search EveryWhere - 找到整个项目中所有使用某个类/函数/方法等的位置。
在某个symbol的名称上单击右键 -> FindUsages - 跳转到某个类/函数/方法等的定义处
在某个symbol的名称上按住Ctrl键, 然后单击
在阅读源码时,我们需要带着两个问题去读:
- 这段代码实现了什么功能?
- 它是如何实现的?
3. 由简入繁
早期的代码仅保留了核心特性,而且代码量较少,容易阅读和理解。Flask最早发行的0.1版本只包含一个核心脚本——flask.py,不算空行大概只有四百多行代码,非常mini。
- 签出0.1版本的代码
cd flask
git checkout 0.1
通过将早期版本和最新版本进行对比,能让我们了解到Flask的变化, 思考这些变化能加深我们对相关只是的理解。在0.1版本的Flask中,有些用法和Flask的当前版本已经有很大出入,所以不要把其中的代码实现直接应用到开发中。
- 查看提交记录
4. 单步调试
在阅读源码时,我们也可以使用这种方式来了解代码执行和调用的流程(调用栈)。
flask发行版本分析
如果打算从头开始了解Flask的变化,那么比较值得阅读的版本是0.1、0.4、0.5、0.7以及最新版本1.0,其他版本大部分的变动都是在重构、优化代码以及修复错误,因此可以略过。

flask的设计理念
"微"框架
保留核心且易于扩展
两个核心依赖
Flask与Werkzeug的联系非常紧密。从路由处理,到请求解析,再到响应的封装,以及上下文和各种数据结构都离不开Werkzeug,有些函数(比如redirect、abort)甚至是直接从Werkzeug引入的。如果要深入了解Flask的实现原理,必然躲不开Werkzeug。
引入Jinja2主要是因为大多数Web程序都需要渲染模板,与Jinja2集成可以减少大量的工作。除此之外,Flask扩展常常需要处理模板,而集成Jinja2方便了扩展的开发。不过,Flask并不限制你选择其他模板引擎,比如Mako、Genshi等。
显式程序对象
- 显式的程序对象允许多个程序实例存在。
- 允许你通过子类化Flask类来改变程序行为。
- Flask需要通过传入的包名称来定位资源(模板和静态文件)。
- 允许通过工厂函数来创建程序实例,可以在不同的地方传入不同的配置来创建不同的程序实例。
- 允许通过蓝本来模块化程序。
本地上下文
在多线程环境下,要想让所有视图函数都获取请求对象。最直接的方法就是在调用视图函数时将所有需要的数据作为参数传递进去,但这样一来程序逻辑就变得冗余且不易于维护。另一种方法是将这些数据设为全局变量,但是如果直接将请求对象设为全局变量,那么必然会在不同的线程中导致混乱(非线程安全)。本地线程(thread locals)的出现解决了这些问题。
本地线程就是一个全局对象,你可以使用一种特定线程且线程安全的方式来存储和获取数据。也就是说,同一个变量在不同的线程内拥有各自的值,互不干扰。实现原理其实很简单,就是根据线程的ID来存取数据。Flask没有使用标准库的threading.local(),而是使用了Werkzeug自己实现的本地线程对象werkzeug.local.Local(),后者增加了对Greenlet的优先支持。
Flask使用本地线程来让上下文代理对象全局可访问,比如request、session、current_app、g,这些对象被称为本地上下文对象(context locals)。因此,在不基于线程、greenlet或单进程实现的并发服务器上,这些代理对象将无法正常工作,但好在仅有少部分服务器不被支持。Flask的设计初衷是为了让传统Web程序的开发更加简单和迅速,而不是用来开发大型程序或异步服务器的。但是Flask的可扩展性却提供了无限的可能性,除了使用扩展,我们还可以子类化Flask类,或是为程序添加中间件。
三种程序状态
Flask提供的四个本地上下文对象分别在特定的程序状态下绑定实际的对象。如果我们在访问或使用它们时还没有绑定,那么就会看到初学者经常见到的RuntimeError异常。
在Flask中存在三种状态,分别是程序设置状态(application setup state)、程序运行状态(application runtime state)和请求运行状态(request runtime state)。
1. 程序设置状态
当Flask类被实例化,也就是创建程序实例app后,就进入了程序设置状态。这时所有的全局对象都没有被绑定:
>>> from flask import Flask, current_app, g, request, session
>>> app = Flask(__name__)
>>> current_app, g, request, session
(<LocalProxy unbound>, <LocalProxy unbound>, <LocalProxy unbound>, <LocalProxy unbound>)
2. 程序运行状态
当Flask程序启动,但是还没有请求进入时,Flask进入了程序运行状态。在这种状态下,程序上下文对象current_app和g都绑定了各自的对象。使用flask shell命令打开的Python shell默认就是这种状态,我们也可以在普通的Python shell中通过手动推送程序上下文来模拟:
>>> from flask import Flask, current_app, g, request, session
>>> app = Flask(__name__)
>>> ctx = app.app_context()
>>> ctx.push()
>>> current_app, g, request, session
(<Flask '__main__'>, <flask.g of '__main__'>, <LocalProxy unbound>, <LocalProxy unbound>)
在上面的代码中,我们手动使用app_context()方法创建了程序上下文,然后调用push()方法把它推送到程序上下文堆栈里。默认情况下,当请求进入的时候,程序上下文会随着请求上下文一起被自动激活。但是在没有请求进入的场景,比如离线脚本、测试,或是进行交互式调试的时候,手动推送程序上下文以进入程序运行状态会非常方便。
3. 请求运行状态
当请求进入的时候,或是使用test_request_context()方法、test_client()方法时,Flask会进入请求运行状态。因为当请求上下文被推送时,程序上下文也会被自动推送,所以在这个状态下4个全局对象都会被绑定,我们可以通过手动推送请求上下文模拟:
>>> from flask import Flask, current_app, g, request, session
>>> app = Flask(__name__)
>>> ctx = app.test_request_context()
>>> ctx.push()
>>> current_app, g, request, session
(<Flask '__main__'>, <flask.g of '__main__'>, <Request 'http://localhost/' [GET]>, <NullSession {}>)
# 这里因为没有设置程序密钥,所以session是表示无效session的NullSession类实例。
>>> ctx.pop()
这也是为什么你可以直接在视图函数和相应的回调函数里直接使用这些上下文对象,而不用推送上下文——Flask在处理请求时会自动帮你推送请求上下文和程序上下文。
丰富的自定义支持
Flask的灵活不仅体现在易于扩展,不限制项目结构,也体现在其内部的高度可定制化。
from flask import Flask, Request, Response
# 自定义FLask
class MyFlask(Flask):
pass
# 自定义请求类
class MyRequest(Request):
pass
# 自定义响应类
class MyResponse(Response):
pass
app = MyFlask(__name__)
app.request_class = MyRequest
# make_response()并不是直接实例化Response类,而是实例化被存储在Flask.response_class属性上的类,默认为Response类。
app.response_class = MyResponse
flask与WSGI
WSGI指Python Web Server Gateway Interface,它是为了让Web服务器与Python程序能够进行数据交流而定义的一套接口标准/规范。
客户端和服务器端进行沟通遵循了HTTP协议,可以说HTTP就是它们之间沟通的语言。从HTTP请求到我们的Web程序之间,还有另外一个转换过程——从HTTP报文到WSGI规定的数据格式。WSGI则可以视为WSGI服务器和我们的Web程序进行沟通的语言。
WSGI程序
根据WSGI的规定,Web程序(或被称为WSGI程序)必须是一个可调用对象(callable object)。
- 接受environ 和start_response两个参数
- 内部调用 start_respons生成header
- 返回一个可迭代的响应体
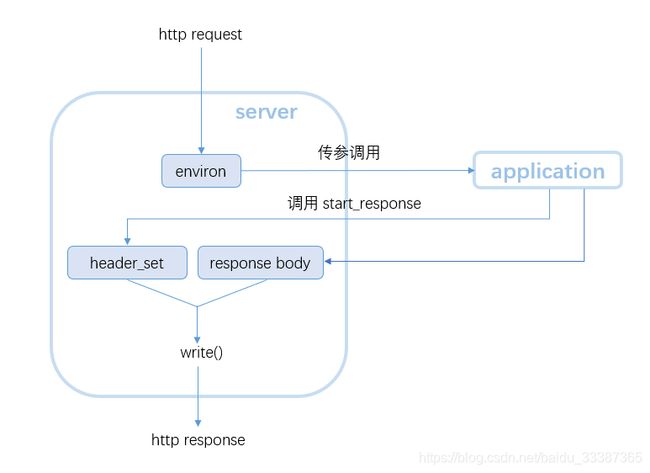
wsgi实现示例
# wsgi_test.py
import os, sys
#application是一个可调用的对象,作为参数传入服务器函数
# WSGI服务器
def run_with_cgi(application):
#wsgi参数设置,解析请求并将其传入environ字典(这里并没有给出解析请求的代码)
environ = dict(os.environ.items())
environ['wsgi.input'] = sys.stdin
environ['wsgi.errors'] = sys.stderr
environ['wsgi.version'] = (1, 0)
environ['wsgi.multithread'] = False
environ['wsgi.multiprocess'] = True
environ['wsgi.run_once'] = True
if environ.get('HTTPS', 'off') in ('on', '1'):
environ['wsgi.url_scheme'] = 'https'
else:
environ['wsgi.url_scheme'] = 'http'
headers_set = []
headers_sent = []
def write(data):
if not headers_set:
raise AssertionError("write() before start_response()")
elif not headers_sent:
# Before the first output, send the stored headers
status, response_headers = headers_sent[:] = headers_set
sys.stdout.write('Status: %s\r\n' % status)
for header in response_headers:
sys.stdout.write('%s: %s\r\n' % header)
sys.stdout.write('\r\n')
sys.stdout.write(data)
sys.stdout.flush()
#start_response的作用是生成响应头
def start_response(status, response_headers, exc_info=None):
if exc_info:
try:
if headers_sent:
# Re-raise original exception if headers sent
raise exc_info[0], exc_info[1], exc_info[2]
finally:
exc_info = None # avoid dangling circular ref
elif headers_set:
raise AssertionError("Headers already set!")
headers_set[:] = [status, response_headers]
return write
#获取application生成的http报文,application返回一个可迭代对象
result = application(environ, start_response)
try:
for data in result:
if data: # don't send headers until body appears
#如果获取到data,就调用write函数输出header和data
write(data)
if not headers_sent:
write('') # send headers now if body was empty
finally:
if hasattr(result, 'close'):
result.close()
# 函数实现web程序
def simple_app(environ, start_response):
"""Simplest possible application object
environ:包含了请求的所有信息的字典。
start_response:需要在可调用对象中调用的函数,用来发起响应,参数是状态码、响应头部等。
"""
status = '200 OK'
#构建响应头
response_headers = [('Content-type', 'text/plain')]
#调用作为参数传入的start_response,其已经在server中定义
start_response(status, response_headers)
#返回可迭代的响应体(即使只有一行,也要写成列表的形式)
return [b'Hello world!\n']
# 类实现web程序
class AppClass:
"""Produce the same output, but using a class
(Note: 'AppClass' is the "application" here, so calling it
returns an instance of 'AppClass', which is then the iterable
return value of the "application callable" as required by
the spec.
If we wanted to use *instances* of 'AppClass' as application
objects instead, we would have to implement a '__call__'
method, which would be invoked to execute the application,
and we would need to create an instance for use by the
server or gateway.
"""
def __init__(self, environ, start_response):
self.environ = environ
self.start = start_response
def __iter__(self):
status = '200 OK'
response_headers = [('Content-type', 'text/plain')]
self.start(status, response_headers)
#__iter__和yield结合,实现了生成器函数,
#result = AppClass(environ, start_response)将返回一个可迭代的实例
yield b"Hello world!\n"
run_with_cgi(simple_app)
run_with_cgi(AppClass)
Flask中的WSGI实现
class Flask(_PackageBoundObject):
...
def wsgi_app(self, environ, start_response):
...
def __call__(self, environ, start_response):
"""Shortcut for :attr:`wsgi_app`."""
return self.wsgi_app(environ, start_response)
WSGI服务器
Python提供了一个wsgiref库,可以在开发时使用
from wsgiref.simple_server import make_server
def hello(environ, start_response):
...
server = make_server('localhost', 5000, hello)
server.serve_forever()
中间件
WSGI允许使用中间件(Middleware)包装(wrap)程序,为程序在被调用前添加额外的设置和功能。当请求发送来后,会先调用包装在可调用对象外层的中间件。这个特性经常被用来解耦程序的功能,这样可以将不同功能分开维护,达到分层的目的,同时也根据需要嵌套。
wsgi使用中间件示例
from wsgiref.simple_server import make_server
def hello(environ, start_response):
status = '200 OK'
response_headers = [('Content-type', 'text/html')]
start_response(status, response_headers)
return [b'Hello, web!
']
class MyMiddleware(object):
def __init__(self, app):
self.app = app
def __call__(self, environ, start_response):
def custom_start_response(status, headers, exc_info=None):
headers.append(('A-CUSTOM-HEADER', 'Nothing'))
return start_response(status, headers)
return self.app(environ, custom_start_response)
wrapped_app = MyMiddleware(hello)
server = make_server('localhost', 5000, wrapped_app)
server.serve_forever()
Flask使用中间件示例
class MyMiddleware(object):
pass
app = Flask(__name__)
# 因为Flask中实际的WSGI可调用对象是Flask.wsgi_app()方法
app.wsgi_app = MyMiddleware(app.wsgi_app)
Werkzeug内置中间件
- ProxyFix: 可以用来对反向代理转发的请求进行修正
- werkzeug.contrib.profiler.ProfilerMiddleware: 可以在处理请求时进行性能分析
- werkzeug.wsgi.DispatcherMiddleware: 可以让你将多个WSGI程序作为一个“程序集”同时运行,你需要传入多个程序实例,并为这些程序设置对应的URL前缀或子域名来分发请求。
Flask的工作流程与机制
Flask中的请求响应循环
1. 程序启动
def run_simple(hostname, port, application, use_reloader=False,
use_debugger=False, use_evalex=True,
extra_files=None, reloader_interval=1,
reloader_type='auto', threaded=False,
processes=1, request_handler=None, static_files=None,
passthrough_errors=False, ssl_context=None):
if use_debugger: # 判断是否使用调试器
from werkzeug.debug import DebuggedApplication
# 使用DebuggedApplication中间件为程序添加调试功能。
application = DebuggedApplication(application, use_evalex)
if static_files:
from werkzeug.wsgi import SharedDataMiddleware
# 使用SharedDataMiddleware中间件为程序添加提供(serve)静态文件的功能。
application = SharedDataMiddleware(application, static_files)
...
def inner():
try:
fd = int(os.environ['WERKZEUG_SERVER_FD'])
except (LookupError, ValueError):
fd = None
srv = make_server(hostname, port, application, threaded,
processes, request_handler,
passthrough_errors, ssl_context,
fd=fd) # 创建服务器
if fd is None:
log_startup(srv.socket)
srv.serve_forever() # 运行服务器
if use_reloader: # 判断是否使用重载器
...
from werkzeug._reloader import run_with_reloader
run_with_reloader(inner, extra_files, reloader_interval,
reloader_type)
else:
inner()
2. 请求In
- WSGI程序
请求上下文在Flask类的wsgi_app方法的开头创建,在这个方法的最后没有直接调用pop()方法,而是调用了auto_pop()方法来移除。也就是说,请求上下文的生命周期开始于请求进入调用wsgi_app()时,结束于响应生成后。
# flask/app.py
class Flask(_PackageBoundObject):
...
def wsgi_app(self, environ, start_response):
"""The actual WSGI application. This is not implemented in
`__call__` so that middlewares can be applied without losing a
reference to the class. So instead of doing this::
app = MyMiddleware(app)
It's a better idea to do this instead::
app.wsgi_app = MyMiddleware(app.wsgi_app)
Then you still have the original application object around and
can continue to call methods on it.
.. versionchanged:: 0.7
The behavior of the before and after request callbacks was changed
under error conditions and a new callback was added that will
always execute at the end of the request, independent on if an
error occurred or not. See :ref:`callbacks-and-errors`.
:param environ: a WSGI environment
:param start_response: a callable accepting a status code,
a list of headers and an optional
exception context to start the response
"""
ctx = self.request_context(environ)
ctx.push()
error = None
try:
# 首先尝试从Flask.full_dispatch_request()方法获取响应,如果出错那么就根据错误类型来生成错误响应。
try:
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
except:
error = sys.exc_info()[1]
raise
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)
def __call__(self, environ, start_response):
"""Shortcut for :attr:`wsgi_app`."""
return self.wsgi_app(environ, start_response)
- 请求调度
# flask/app.py
class Flask(_PackageBoundObject):
...
def full_dispatch_request(self):
"""Dispatches the request and on top of that performs request
pre and postprocessing as well as HTTP exception catching and
error handling.
.. versionadded:: 0.7
"""
self.try_trigger_before_first_request_functions()
try:
request_started.send(self) # 发送请求进入信号
rv = self.preprocess_request() # 预处理请求, 这会执行所有使用before_re-quest钩子注册的函数。
if rv is None:
rv = self.dispatch_request() # 会匹配并调用对应的视图函数,获取其返回值
except Exception as e:
rv = self.handle_user_exception(e) # 处理异常
return self.finalize_request(rv) # 接收视图函数返回值生成响应
...
3. 响应Out
# flask/app.py
class Flask(_PackageBoundObject):
def finalize_request(self, rv, from_error_handler=False):
"""Given the return value from a view function this finalizes
the request by converting it into a response and invoking the
postprocessing functions. This is invoked for both normal
request dispatching as well as error handlers.
Because this means that it might be called as a result of a
failure a special safe mode is available which can be enabled
with the `from_error_handler` flag. If enabled, failures in
response processing will be logged and otherwise ignored.
:internal:
"""
# 把视图函数返回值转换为响应,然后调用后处理函数。
response = self.make_response(rv) # 生成响应对象
try:
response = self.process_response(response) # 响应发送给WSGI服务器前执行所有使用after_request钩子注册的函数。另外,这个方法还会根据session对象来设置cookie.
request_finished.send(self, response=response) # 发送信号
except Exception:
if not from_error_handler:
raise
self.logger.exception('Request finalizing failed with an '
'error while handling an error')
# 返回作为响应的response后,代码执行流程就回到了wsgi_app()方法,最后返回响应对象,WSGI服务器接收这个响应对象,并把它转换成HTTP响应报文发送给客户端。
return response
路由系统
1. 注册路由
- 创建路由表Map,并添加三个URL规则:
>>> from werkzeug.routing import Map, Rule
>>> m = Map()
>>> rule1 = Rule('/', endpoint='index')
>>> rule2 = Rule('/downloads/', endpoint='downloads/index')
>>> rule3 = Rule('/downloads/' , endpoint='downloads/show')
>>> m.add(rule1)
>>> m.add(rule2)
>>> m.add(rule3)
- route方法
class Flask(_PackageBoundObject):
...
def route(self, rule, **options):
def decorator(f):
endpoint = options.pop('endpoint', None)
# 注册路由也可以直接使用add_url_rule实现
self.add_url_rule(rule, endpoint, f, **options)
return f
return decorator
- add_url_rule()方法
class Flask(_PackageBoundObject):
...
@setupmethod
def add_url_rule(self, rule, endpoint=None, view_func=None, provide_automatic_options=None, **options):
# 设置方法和端点
...
# rule是Werkzeug提供的Rule实例(werkzeug.routing.Rule),其中保存了端点和URL规则的映射关系。
rule = self.url_rule_class(rule, methods=methods, **options)
rule.provide_automatic_options = provide_automatic_options
# url_map是Werkzeug的Map类实例(werkzeug.routing.Map)。它存储了URL规则和相关配置。
self.url_map.add(rule)
if view_func is not None:
old_func = self.view_functions.get(endpoint)
if old_func is not None and old_func != view_func:
raise AssertionError('View function mapping is overwriting an '
'existing endpoint function: %s' % endpoint)
# view_function则是Flask类中定义的一个字典,它存储了端点和视图函数的映射关系。
self.view_functions[endpoint] = view_func
2. URL匹配
Werkzeug中进行URL匹配
>>> m = Map()
>>> rule1 = Rule('/', endpoint='index')
>>> rule2 = Rule('/downloads/', endpoint='downloads/index')
>>> rule3 = Rule('/downloads/' , endpoint='downloads/show')
>>> m.add(rule1)
>>> m.add(rule2)
>>> m.add(rule3)
>>>
# Map.bind()方法和Map.bind_to_environ()都会返回一个MapAdapter对象,它负责匹配和构建URL。
>>> urls = m.bind('example.com') # 传入主机地址作为参数
# MapAdapter类的match方法用来判断传入的URL是否匹配Map对象中存储的路由规则(存储在self.map._rules列表中)。
>>> urls.match('/', 'GET')
('index', {}) # 返回一个包含URL端点和URL变量的元组。
>>> urls.match('/downloads/42')
('downloads/show', {'id': 42})
"""
为了确保URL的唯一,Werkzeug使用下面的规则来处理尾部斜线问题:当你定义的URL规则添加了尾部斜线时,用户访问未加尾部斜线的URL时会被自动重定向到正确的URL;反过来,如果定义的URL不包含尾部斜线,用户访问的URL添加了尾部斜线则会返回404错误。
"""
>>> urls.match('/downloads')
Traceback (most recent call last):
...
RequestRedirect: http://example.com/downloads/
>>> urls.match('/missing')
Traceback (most recent call last):
...
NotFound: 404 Not Found
"""
MapAdapter类的build()方法用于创建URL,我们用来生成URL的url_for()函数内部就是通过build()方法实现的。
"""
>>> urls.build('index', {}) '/'
>>> urls.build('downloads/show', {'id': 42}) '/downloads/42'
>>> urls.build('downloads/show', {'id': 42}, force_external=True) 'http://example.com/downloads/42'
FLask中如何根据请求的URL找到对应的视图函数
- 请求的最终处理方法
# flask/app.py
class Flask(_PackageBoundObject):
...
def dispatch_request(self):
"""正是dispatch_request()方法实现了从请求的URL找到端点,
再从端点找到对应的视图函数并调用的过程。
"""
# URL的匹配工作在请求上下文对象中实现。
req = _request_ctx_stack.top.request
if req.routing_exception is not None:
self.raise_routing_exception(req)
rule = req.url_rule
# 如果为这个URL提供了自动选项并且方法为OPTIONS,则自动处理
if getattr(rule, 'provide_automatic_options', False) \
and req.method == 'OPTIONS':
return self.make_default_options_response()
# 否则调用对应的视图函数
return self.view_functions[rule.endpoint](**req.view_args)
- 请求上下文对象
# flask/ctx.py
class RequestContext(object):
def __init__(self, app, environ, request=None):
self.app = app
if request is None:
request = app.request_class(environ)
self.request = request
self.url_adapter = app.create_url_adapter(self.request)
...
self.match_request() # 匹配请求到对应的视图函数
- 匹配请求方法
flask/ctx.py
class RequestContext(object):
...
def match_request(self):
try:
# 设置return_rule=True可以在匹配成功后返回表示URL规则的Rule类实例
url_rule, self.request.view_args = self.url_adapter.match(return_rule=True)
self.request.url_rule = url_rule
except HTTPException as e:
self.request.routing_exception = e
- 创建URL Adapter方法
class Flask(_PackageBoundObject):
...
def create_url_adapter(self, request):
if request is not None:
# 如果子域名匹配处于关闭状态(默认值)
# 就在各处使用默认的子域名
# url_map属性是一个Map对象,
subdomain = ((self.url_map.default_subdomain or None) if not self.subdomain_matching else None)
return self.url_map.bind_to_environ(request.environ, server_name=self.config['SERVER_NAME'], subdomain=subdomain)
if self.config['SERVER_NAME'] is not None:
return self.url_map.bind(self.config['SERVER_NAME'], script_name=self.config['APPLICATION_ROOT'], url_scheme=self.config['PREFERRED_URL_SCHEME'])
本地上下文
Flask提供了两种上下文,请求上下文和程序上下文,这两种上下文分别包含request、session和current_app、g这四个变量,这些变量是实际对象的本地代理(local proxy),因此被称为本地上下文(context locals)。这些代理对象定义在globals.py脚本中,这个模块还包含了和上下文相关的两个错误信息和三个函数.
- 上下文全局对象
# flask/globals.py
from functools import partial
from werkzeug.local import LocalStack, LocalProxy
# 两个错误信息
_request_ctx_err_msg = '''\
Working outside of request context.
This typically means that you attempted to use functionality that needed
an active HTTP request. Consult the documentation on testing for
information about how to avoid this problem.\
'''
_app_ctx_err_msg = '''\
Working outside of application context.
This typically means that you attempted to use functionality that needed
to interface with the current application object in a way. To solve
this set up an application context with app.app_context(). See the
documentation for more information.\
'''
# 查找请求上下文对象
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
# 查找程序上下文对象
def _lookup_app_object(name):
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return getattr(top, name)
# 查找程序实例
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
# context locals
# 2个堆栈
_request_ctx_stack = LocalStack() # 请求上下文堆栈
_app_ctx_stack = LocalStack() # 程序上下文堆栈
# 4个全局上下文代理对象
"""当上下文没被推送时,响应的全局代理对象处于未绑定状态。而如果这里不使用代理,那么在导入这些全局对象时就会尝试获取上下文,然而这时堆栈是空的,所以获取到的全局对象只能是None。
当请求进入并调用视图函数时,虽然这时堆栈里已经推入了上下文,但这里导入的全局对象仍然是None。
总而言之,上下文的推送和移除是动态进行的,而使用代理可以让我们拥有动态获取上下文对象的能力。
另外,一个动态的全局对象,也让多个程序实例并存有了可能。这样在不同的程序上下文环境中,current_app总是能对应正确的程序实例。"""
current_app = LocalProxy(_find_app) # 使用current_app是防止与程序实例的名称冲突
request = LocalProxy(partial(_lookup_req_object, 'request'))
session = LocalProxy(partial(_lookup_req_object, 'session'))
g = LocalProxy(partial(_lookup_app_object, 'g'))
1. 本地线程与Local
在保存数据的同时记录下对应的线程ID,获取数据时根据所在线程的ID即可获取到对应的数据。就像是超市里的存包柜,每个柜子都有一个号码,每个号码对应一份物品。
- Flask中的本地线程使用Werkzeug提供的Local类实现
# werkzeug/local.py
# 优先使用Greenlet提供的协程ID,如果Greenlet不可用再使用thread模块获取线程ID。
try:
from greenlet import getcurrent as get_ident
except ImportError:
try:
from thread import get_ident
except ImportError:
from _thread import get_ident
class Local(object):
__slots__ = ('__storage__', '__ident_func__')
def __init__(self):
object.__setattr__(self, '__storage__', {})
object.__setattr__(self, '__ident_func__', get_ident)
def __iter__(self):
return iter(self.__storage__.items())
def __call__(self, proxy):
"""Create a proxy for a name."""
return LocalProxy(self, proxy)
def __release_local__(self):
"""用来释放线程/协程,它会清空当前线程/协程的数据。"""
self.__storage__.pop(self.__ident_func__(), None)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
# __storage__是一个嵌套的字典,外层的字典使用线程ID作为键来匹配内部的字典,内部的字典的值即真实对象。所以全局使用的上下文对象不会在多个线程中产生混乱。
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
def __delattr__(self, name):
try:
del self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
2. 堆栈与LocalStack
堆栈或栈是一种常见的数据结构,它的主要特点就是后进先出(LIFO,Last In First Out),指针在栈顶(top)位置. 堆栈涉及的主要操作有push(推入)、pop(取出)和peek(获取栈顶条目)。其他附加的操作还有获取条目数量,判断堆栈是否为空等。

使用列表实现堆栈结构
class Stack:
def __init__(self):
self.items = []
def push(self, item): # 推入条目
self.items.append(item)
def is_empty(self):
return self.items == []
@property
def pop(self): # 移除并返回栈顶条目
if self.is_empty():
return None
return self.items.pop()
@property
def top(self): # 获取栈顶条目
if self.is_empty():
return None
return self.items[-1]
- LocalStack
平时导入的request对象是保存在堆栈里的一个RequestContext实例,导入的操作相当于获取堆栈的栈顶(top),它会返回栈顶的对象(peek操作),但并不删除它。
为什么Flask使用LocalStack而不是直接使用Local存储上下文对象。主要的原因是为了支持多程序共存。将程序分离成多个程序很类似蓝本的模块化分离,但它们并不是一回事。前面我们提到过,使用Werkzeug提供的DispatcherMiddleware中间件就可以把多个程序组合成一个WSGI程序运行。
class LocalStack(object):
"""LocalStack是基于Local实现的栈结构(本地堆栈,即实现了本地线程的堆栈)
"""
def __init__(self):
self._local = Local()
def __release_local__(self):
self._local.__release_local__()
def _get__ident_func__(self):
return self._local.__ident_func__
def _set__ident_func__(self, value):
object.__setattr__(self._local, '__ident_func__', value)
__ident_func__ = property(_get__ident_func__, _set__ident_func__)
del _get__ident_func__, _set__ident_func__
def __call__(self):
# 当LocalStack实例被直接调用时,会返回栈顶对象的代理,即LocalProxy类实例。
def _lookup():
rv = self.top
if rv is None:
raise RuntimeError('object unbound')
return rv
return LocalProxy(_lookup)
def push(self, obj):
"""Pushes a new item to the stack"""
# 把数据存储到Local中,并将数据的字典名称设为'stack'。
rv = getattr(self._local, 'stack', None)
if rv is None:
self._local.stack = rv = []
rv.append(obj)
return rv
def pop(self):
"""Removes the topmost item from the stack, will return the
old value or `None` if the stack was already empty.
"""
stack = getattr(self._local, 'stack', None)
if stack is None:
return None
elif len(stack) == 1:
release_local(self._local)
return stack[-1]
else:
return stack.pop()
@property
def top(self):
"""The topmost item on the stack. If the stack is empty,
`None` is returned.
"""
try:
return self._local.stack[-1]
except (AttributeError, IndexError):
return None
- 查看LocalStack中的请求上下文和程序上下文
# hello.py
from flask import Flask
from flask.globals import _request_ctx_stack, _app_ctx_stack
app = Flask(__name__)
@app.route('/')
def index():
# {线程/协程ID: {'stack': 实际数据}}
# {139754749810432: {'stack': []}, 139754741417728: {'stack': []}}
print(_request_ctx_stack._local.__storage__)
# {139754749810432: {'stack': []}, 139754741417728: {'stack': []}}
print(_app_ctx_stack._local.__storage__)
return "index"
app.run(threaded=True)
3. 代理与LocalProxy
通过创建一个代理对象。我们可以使用这个代理对象来操作实际对象。
- 使用python实现代理类
class Proxy(object):
def __init__(self, obj):
object.__setattr__(self, "_obj", obj)
def __getattr__(name):
return getattr(self._obj, name)
def __setattr__(self, name, value):
self._obj[name] = value
def __delattr__(self, name):
del self._obj[name]
- LocalProxy的定义
这些代理可以在线程间共享,让我们可以以动态的方式获取被代理的实际对象。
@implements_bool
class LocalProxy(object):
__slots__ = ('__local', '__dict__', '__name__', '__wrapped__')
def __init__(self, local, name=None):
object.__setattr__(self, '_LocalProxy__local', local) # 等效于 self.__local = local
object.__setattr__(self, '__name__', name)
if callable(local) and not hasattr(local, '__release_local__'):
# "local" is a callable that is not an instance of Local or
# LocalManager: mark it as a wrapped function.
object.__setattr__(self, '__wrapped__', local)
def _get_current_object(self):
"""获取被代理的实际对象。"""
if not hasattr(self.__local, '__release_local__'):
return self.__local()
try:
return getattr(self.__local, self.__name__)
except AttributeError:
raise RuntimeError('no object bound to %s' % self.__name__)
...
def __getattr__(self, name):
if name == '__members__':
return dir(self._get_current_object())
return getattr(self._get_current_object(), name)
def __setitem__(self, key, value):
self._get_current_object()[key] = value
def __delitem__(self, key):
del self._get_current_object()[key]
...
4. 请求上下文
在Flask中,请求上下文由RequestContext类表示。当请求进入时,被作为WSGI程序调用的Flask类实例(即我们的程序实例app)会在wsgi_app()方法中调用Flask.request_context()方法。这个方法会实例化RequestContext类作为请求上下文对象,接着wsgi_app()调用它的push()方法来将它推入请求上下文堆栈。
- request对象使用app.request_class(environ)创建,传入了包含请求信息的env-iron字典。
- session在构造函数中只是None,它会在push()方法中被调用,即在请求上下文被推入请求上下文堆栈时创建。
# flask/ctx.py
class RequestContext(object):
"""The request context contains all request relevant information. It is
created at the beginning of the request and pushed to the
`_request_ctx_stack` and removed at the end of it. It will create the
URL adapter and request object for the WSGI environment provided.
Do not attempt to use this class directly, instead use
:meth:`~flask.Flask.test_request_context` and
:meth:`~flask.Flask.request_context` to create this object.
When the request context is popped, it will evaluate all the
functions registered on the application for teardown execution
(:meth:`~flask.Flask.teardown_request`).
The request context is automatically popped at the end of the request
for you. In debug mode the request context is kept around if
exceptions happen so that interactive debuggers have a chance to
introspect the data. With 0.4 this can also be forced for requests
that did not fail and outside of ``DEBUG`` mode. By setting
``'flask._preserve_context'`` to ``True`` on the WSGI environment the
context will not pop itself at the end of the request. This is used by
the :meth:`~flask.Flask.test_client` for example to implement the
deferred cleanup functionality.
You might find this helpful for unittests where you need the
information from the context local around for a little longer. Make
sure to properly :meth:`~werkzeug.LocalStack.pop` the stack yourself in
that situation, otherwise your unittests will leak memory.
"""
def __init__(self, app, environ, request=None):
self.app = app
if request is None:
request = app.request_class(environ)
self.request = request # 请求对象
self.url_adapter = app.create_url_adapter(self.request)
self.flashes = None # flash消息队列
self.session = None # session字典
# Request contexts can be pushed multiple times and interleaved with
# other request contexts. Now only if the last level is popped we
# get rid of them. Additionally if an application context is missing
# one is created implicitly so for each level we add this information
self._implicit_app_ctx_stack = []
# indicator if the context was preserved. Next time another context
# is pushed the preserved context is popped.
self.preserved = False
# remembers the exception for pop if there is one in case the context
# preservation kicks in.
self._preserved_exc = None
# Functions that should be executed after the request on the response
# object. These will be called before the regular "after_request"
# functions.
self._after_request_functions = []
self.match_request()
def _get_g(self):
return _app_ctx_stack.top.g
def _set_g(self, value):
_app_ctx_stack.top.g = value
g = property(_get_g, _set_g)
del _get_g, _set_g
def copy(self):
"""Creates a copy of this request context with the same request object.
This can be used to move a request context to a different greenlet.
Because the actual request object is the same this cannot be used to
move a request context to a different thread unless access to the
request object is locked.
.. versionadded:: 0.10
"""
return self.__class__(self.app,
environ=self.request.environ,
request=self.request
)
def match_request(self):
"""Can be overridden by a subclass to hook into the matching
of the request.
"""
try:
url_rule, self.request.view_args = \
self.url_adapter.match(return_rule=True)
self.request.url_rule = url_rule
except HTTPException as e:
self.request.routing_exception = e
def push(self):
"""Binds the request context to the current context."""
# If an exception occurs in debug mode or if context preservation is
# activated under exception situations exactly one context stays
# on the stack. The rationale is that you want to access that
# information under debug situations. However if someone forgets to
# pop that context again we want to make sure that on the next push
# it's invalidated, otherwise we run at risk that something leaks
# memory. This is usually only a problem in test suite since this
# functionality is not active in production environments.
top = _request_ctx_stack.top # 获取请求上下文栈顶条目
if top is not None and top.preserved:
top.pop(top._preserved_exc)
# Before we push the request context we have to ensure that there
# is an application context.
# 当请求进入时,程序上下文会随着请求上下文一起被创建。在推入请求上下文前先推入程序上下文
app_ctx = _app_ctx_stack.top
if app_ctx is None or app_ctx.app != self.app:
app_ctx = self.app.app_context() # 获取程序上下文对象
app_ctx.push() # 将程序上下文对象推入堆栈
self._implicit_app_ctx_stack.append(app_ctx)
else:
self._implicit_app_ctx_stack.append(None)
if hasattr(sys, 'exc_clear'):
sys.exc_clear()
_request_ctx_stack.push(self) # 把自己推入请求上下文堆栈
# Open the session at the moment that the request context is
# available. This allows a custom open_session method to use the
# request context (e.g. code that access database information
# stored on `g` instead of the appcontext).
self.session = self.app.open_session(self.request)
if self.session is None:
self.session = self.app.make_null_session()
def pop(self, exc=_sentinel):
"""Pops the request context and unbinds it by doing that. This will
also trigger the execution of functions registered by the
:meth:`~flask.Flask.teardown_request` decorator.
.. versionchanged:: 0.9
Added the `exc` argument.
"""
app_ctx = self._implicit_app_ctx_stack.pop()
try:
clear_request = False
if not self._implicit_app_ctx_stack:
self.preserved = False
self._preserved_exc = None
if exc is _sentinel:
exc = sys.exc_info()[1]
self.app.do_teardown_request(exc) # 这个方法会执行所有使用teardown_request钩子注册的函数。
# If this interpreter supports clearing the exception information
# we do that now. This will only go into effect on Python 2.x,
# on 3.x it disappears automatically at the end of the exception
# stack.
if hasattr(sys, 'exc_clear'):
sys.exc_clear()
request_close = getattr(self.request, 'close', None)
if request_close is not None:
request_close()
clear_request = True
finally:
rv = _request_ctx_stack.pop()
# get rid of circular dependencies at the end of the request
# so that we don't require the GC to be active.
if clear_request:
rv.request.environ['werkzeug.request'] = None
# Get rid of the app as well if necessary.
if app_ctx is not None:
app_ctx.pop(exc) # 在请求上下文移除之后移除程序上下文
assert rv is self, 'Popped wrong request context. ' \
'(%r instead of %r)' % (rv, self)
def auto_pop(self, exc):
"""这个方法里添加了一个if判断,用来确保没有异常发生时才调用pop()方法移除上下文。
异常发生时需要保持上下文以便进行相关操作,比如在页面的交互式调试器中执行操作或是测试。"""
if self.request.environ.get('flask._preserve_context') or \
(exc is not None and self.app.preserve_context_on_exception):
self.preserved = True
self._preserved_exc = exc
else:
self.pop(exc)
def __enter__(self):
self.push()
return self
def __exit__(self, exc_type, exc_value, tb):
# do not pop the request stack if we are in debug mode and an
# exception happened. This will allow the debugger to still
# access the request object in the interactive shell. Furthermore
# the context can be force kept alive for the test client.
# See flask.testing for how this works.
self.auto_pop(exc_value)
if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None:
reraise(exc_type, exc_value, tb)
def __repr__(self):
return '<%s \'%s\' [%s] of %s>' % (
self.__class__.__name__,
self.request.url,
self.request.method,
self.app.name,
)
5. 程序上下文
# flask/ctx.py
class AppContext(object):
"""The application context binds an application object implicitly
to the current thread or greenlet, similar to how the
:class:`RequestContext` binds request information. The application
context is also implicitly created if a request context is created
but the application is not on top of the individual application
context.
"""
def __init__(self, app):
self.app = app # current_app变量指向的app属性
# 构建URL的url_for()函数会优先使用请求上下文对象提供的url_adapter,如果请求上下文没有被推送,则使用程序上下文提供的url_adapter。所以AppContext的构造函数里也同样创建了url_adapter属性。
self.url_adapter = app.create_url_adapter(None)
# g使用保存在app_ctx_globals_class属性的_AppCtxGlob-als类表示,只是一个普通的类字典对象。我们可以把它看作“增加了本地线程支持的全局变量”。有一个常见的疑问是,为什么说每次请求都会重设g?这是因为g保存在程序上下文中,而程序上下文的生命周期是伴随着请求上下文产生和销毁的。每个请求都会创建新的请求上下文堆栈,同样也会创建新的程序上下文堆栈,所以g会在每个新请求中被重设。
self.g = app.app_ctx_globals_class() # g变量指向的g属性
# Like request context, app contexts can be pushed multiple times
# but there a basic "refcount" is enough to track them.
self._refcnt = 0
def push(self):
"""Binds the app context to the current context."""
self._refcnt += 1
if hasattr(sys, 'exc_clear'):
sys.exc_clear()
_app_ctx_stack.push(self)
appcontext_pushed.send(self.app)
def pop(self, exc=_sentinel):
"""Pops the app context."""
try:
self._refcnt -= 1
if self._refcnt <= 0:
if exc is _sentinel:
exc = sys.exc_info()[1]
self.app.do_teardown_appcontext(exc)
finally:
rv = _app_ctx_stack.pop()
assert rv is self, 'Popped wrong app context. (%r instead of %r)' \
% (rv, self)
appcontext_popped.send(self.app)
def __enter__(self):
self.push()
return self
def __exit__(self, exc_type, exc_value, tb):
self.pop(exc_value)
if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None:
reraise(exc_type, exc_value, tb)
- 手动创建上下文
可以使用程序上下文对象中的push()方法,也可以使用with语句。 - 程序上下文和请求上下文的联系
0.1版本的代码,在flask.py底部,全局对象创建时只存在一个请求上下文堆栈。四个全局对象都从请求上下文中获取。可以说,程序上下文是请求上下文的衍生物。这样做的原因主要是为了更加灵活。
程序中确实存在着两种明显的状态,分离开可以让上下文的结构更加清晰合理。这也方便了测试等不需要请求存在的使用场景,这时只需要单独推送程序上下文,而且这个分离催生出了Flask的程序运行状态。
6. 总结
Flask中的上下文由表示请求上下文的RequestContext类实例和表示程序上下文的AppContext类实例组成。请求上下文对象存储在请求上下文堆栈(_request_ctx_stack)中,程序上下文对象存储在程序上下文堆栈(_app_ctx_stack)中。而request、session则是保存在RequestContext中的变量,相对地,cur-rent_app和g则是保存在AppContext中的变量。当然,re-quest、session、current_app、g变量所指向的实际对象都有相应的类:
- request——Request
- session——SecureCookieSession
- current_app——Flask
- g——_AppCtxGlobals
当第一个请求发来的时候:
1)需要保存请求相关的信息——有了请求上下文。
2)为了更好地分离程序的状态,应用起来更加灵活——有了程序上下文。
3)为了让上下文对象可以在全局动态访问,而不用显式地传入视图函数,同时确保线程安全——有了Local(本地线程)。
4)为了支持多个程序——有了LocalStack(本地堆栈)。 还没弄明白, 是这么实现的?
5)为了支持动态获取上下文对象——有了LocalProxy(本地代理)。
6)……
7)为了让这一切愉快的工作在一起——有了Flask。
请求与响应对象
1. 请求对象
# flask/wrappers.py
from werkzeug.wrappers import Request as RequestBase
from werkzeug.wrappers.json import JSONMixin as _JSONMixin
class JSONMixin(object):
... # 定义is_json、json属性和get_json()方法
class Request(RequestBase, JSONMixin):
"""Flask中的这个Request类主要添加了一些Flask特有的属性,比如表示所在蓝本的blueprint属性,或是为了方便获取当前端点的endpoint属性等。"""
url_rule = None
view_args = None
routing_exception = None
@property
def max_content_length(self):
"""返回配置变量MAX_CONTENT_LENGTH的值"""
if current_app:
return current_app.config['MAX_CONTENT_LENGTH']
@property
def endpoint(self):
"""与请求相匹配的端点。"""
if self.url_rule is not None:
return self.url_rule.endpoint
@property
def blueprint(self):
"""当前蓝本名称。"""
if self.url_rule and '.' in self.url_rule.endpoint:
return self.url_rule.endpoint.rsplit('.', 1)[0]
...
2. 响应对象
在Flask中的请求-响应循环中,响应是由finalize_request()方法生成的,它调用了flask.Flask.make_response()方法生成响应对象,传入的rv参数是dispatch_request()的返回值,也就是视图函数的返回值。这个Flask.make_response()方法主要的工作就是判断返回值是哪一种类型,最后根据类型做相应处理,最后生成一个响应对象并返回它。
- 视图函数允许的返回值

- 响应类的定义
# flask/wrappers.py
from werkzeug.wrappers import Response as ResponseBase
from werkzeug.wrappers.json import JSONMixin as _JSONMixin
class JSONMixin(object):
...
class Response(ResponseBase, JSONMixin):
"""The response object that is used by default in Flask. Works like the
response object from Werkzeug but is set to have an HTML mimetype by
default. Quite often you don't have to create this object yourself because
:meth:`~flask.Flask.make_response` will take care of that for you.
If you want to replace the response object used you can subclass this and
set :attr:`~flask.Flask.response_class` to your subclass.
.. versionchanged:: 1.0
JSON support is added to the response, like the request. This is useful
when testing to get the test client response data as JSON.
.. versionchanged:: 1.0
Added :attr:`max_cookie_size`.
"""
# 设置了默认的MIME类型。
default_mimetype = "text/html"
def _get_data_for_json(self, cache):
return self.get_data()
@property
def max_cookie_size(self): # 返回配置变量MAX_COOKIE_SIZE的值"
"""Read-only view of the :data:`MAX_COOKIE_SIZE` config key.
See :attr:`~werkzeug.wrappers.BaseResponse.max_cookie_size` in
Werkzeug's docs.
"""
if current_app:
return current_app.config["MAX_COOKIE_SIZE"]
# return Werkzeug's default when not in an app context
# 上下文未推送时返回Werkzeug中Response类的默认值
return super(Response, self).max_cookie_size
session
Flask提供了“session变量/对象”来操作“用户会话(Session)”,它把用户会话保存在“一块名/键为session的cookie”中。
- 在flask中使用session
from flask import Flask, session
app = Flask(__name__)
app.secret_key = 'secret string'
# 当用户访问set_answer视图时, 会将数字42存储到session对象里,以answer作为键。
@app.route('/set')
def set_answer():
"""向session中存储值时, 会生成加密的cookie加入响应。这时用户的浏览器接收到响应会将cookie存储起来。"""
session['answer'] = 42
return 'Hello, Flask!
'
# 当用户访问get_answer视图时, 再次从session通过answer获取这个数字。
@app.route('/get')
def get_answer():
"""当用户再次发起请求时,浏览器会自动在请求报文中加入这个cookie值。Flask接收到请求会把session cookie的值解析到session对象里。这时我们就可以再次从session中读取内容。"""
return session['answer']
1. 操作session
session变量
# flask/globals.py
from functools import partial
from werkzeug.local import LocalProxy
from werkzeug.local import LocalStack
def _lookup_req_object(name):
# Flask从请求上下文堆栈的栈顶(_request_ctx_stack.top)获取请求上下文
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
# 从用于获取属性的内置函数getattr()可以看出session是请求上下文对象(即RequestContext)的一个属性, 这也就意味着,session变量是在生成请求上下文的时候创建的。
return getattr(top, name)
_request_ctx_stack = LocalStack()
session = LocalProxy(partial(_lookup_req_object, "session"))
查找真实的session对象
# werkzeug/local.py
class LocalProxy(object):
def _get_current_object(self):
"""Return the current object. This is useful if you want the real
object behind the proxy at a time for performance reasons or because
you want to pass the object into a different context.
"""
if not hasattr(self.__local, "__release_local__"):
return self.__local() # self.__local为partial(_lookup_req_object, "session")
try:
return getattr(self.__local, self.__name__)
except AttributeError:
raise RuntimeError("no object bound to %s" % self.__name__)
...
def __setitem__(self, key, value):
self._get_current_object()[key] = value # self._get_current_object()获取到对象为SecureCookieSession实例
赋值到SecureCookieSession实例
在Werkzeug中进行一系列查询工作后,最终在SecureCookieSession类的__setitem__方法中执行on_update()方法,这个方法会将两个属性self.modified和self.accessed设为True,说明更新(modify)并使用(access)了session。这两个标志会在保存session的方法中使用,我们下面会了解到。
- SecureCookieSession类在构造函数中定义了一个on_update函数,并赋值给on_update参数
# flask/sessions.py
class SecureCookieSession(CallbackDict, SessionMixin):
"""Base class for sessions based on signed cookies."""
def __init__(self, initial=None):
def on_update(self):
self.modified = True
self.accessed = True
super(SecureCookieSession, self).__init__(initial, on_update)
...
- SecureCookieSession的父类CallbackDict的构造方法接收一个on_update参数,并赋值给on_update属性。
# werkzeug/datastructures.py
class CallbackDict(UpdateDictMixin, dict):
"""一个字典,每当产生改变化时会调用传入的函数"""
def __init__(self, initial=None, on_update=None):
dict.__init__(self, initial or ())
self.on_update = on_update
...
- UpdateDictMixin中重载了所有的字典操作,并在这些操作中调用了on_update函数。
# werkzeug/datastructures.py
class UpdateDictMixin(object):
"""当字典被修改时调用self.on_update"""
on_update = None
def calls_update(name):
def oncall(self, *args, **kw):
rv = getattr(super(UpdateDictMixin, self), name)(*args, **kw)
if self.on_update is not None:
self.on_update(self)
return rv
oncall.__name__ = name
return oncall
def setdefault(self, key, default=None):
...
def pop(self, key, default=_missing):
...
__setitem__ = calls_update('__setitem__')
__delitem__ = calls_update('__delitem__')
clear = calls_update('clear')
popitem = calls_update('popitem')
update = calls_update('update')
del calls_update
写入到cookie
- session的更新操作就在finalize_request()方法中。finalize_request()调用了process_response()对响应对象进行预处理
# flask/app.py
class Flask(_PackageBoundObject):
...
def process_response(self, response):
ctx = _request_ctx_stack.top
...
# session操作使用了中间变量session_interface,它默认的值在Flask类中定义,为SecureCookieSessionInterface类。
if not self.session_interface.is_null_session(ctx.session):
self.session_interface.save_session(self, ctx.session, response)
return response
- 调用save_session()方法来保存session
# flask/sessions.py
class SecureCookieSessionInterface(SessionInterface):
...
def save_session(self, app, session, response):
domain = self.get_cookie_domain(app)
path = self.get_cookie_path(app)
# 如果session被清空,删除cookie
# 如果session为空,不设置cookie,直接返回
if not session:
if session.modified:
response.delete_cookie(
app.session_cookie_name,
domain=domain,
path=path
)
return
# 如果session被访问,添加一个Vary: Cookie首部字段
if session.accessed:
response.vary.add('Cookie')
# 检查session是否被修改,如果没修改则返回空值
if not self.should_set_cookie(app, session):
return
httponly = self.get_cookie_httponly(app)
secure = self.get_cookie_secure(app)
expires = self.get_expiration_time(app, session)
# 生成session cookie的值
val = self.get_signing_serializer(app).dumps(dict(session))
# 调用set_cookie方法设置cookie,这个方法的定义在werkzeug.wrappers.BaseResponse类中
response.set_cookie(
app.session_cookie_name,
val,
expires=expires,
httponly=httponly,
domain=domain,
path=path,
secure=secure
)
-
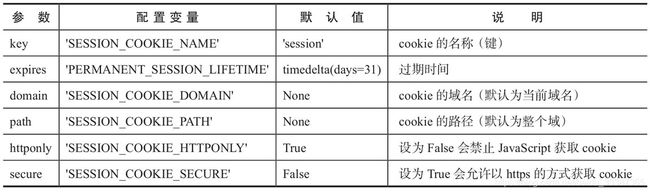
set_cookie方法接受的参数及说明
SESSION_COOKIE_SECURE = True表示浏览器只能通过https协议将cookie发送到服务器。
-
get_signing_serializer()获取序列化器
# flask/sessions.py
class SecureCookieSessionInterface(SessionInterface):
salt = 'cookie-session' # 为计算增加随机性的“盐”
digest_method = staticmethod(hashlib.sha1) # 签名的摘要方法
key_derivation = 'hmac' # 衍生密钥的算法
serializer = session_json_serializer # 序列化器
session_class = SecureCookieSession
def get_signing_serializer(self, app):
if not app.secret_key:
return None
signer_kwargs = dict(
key_derivation=self.key_derivation,
digest_method=self.digest_method
)
# 创建一个具有过期时间且URL安全的令牌(字符串)
return URLSafeTimedSerializer(app.secret_key,
salt=self.salt,
serializer=self.serializer,
signer_kwargs=signer_kwargs)
2. session起源
- 生成session对象
# flask/ctx.py
class RequestContext(object):
def __init__(self, app, environ, request=None):
...
self.session = None
...
...
def push(self):
...
if self.session is None:
session_interface = self.app.session_interface
# 调用open_session()方法来创建session
self.session = session_interface.open_session(
self.app, self.request
)
if self.session is None:
self.session = session_interface.make_null_session(self.app) # NullSession不能设值
...
- 从cookie中读取session
# flask/sessions.py
class SecureCookieSessionInterface(SessionInterface):
...
def open_session(self, app, request):
# 如果没有设置secrect key, 则返回None
s = self.get_signing_serializer(app)
if s is None:
return None
val = request.cookies.get(app.session_cookie_name)
if not val:
return self.session_class()
max_age = total_seconds(app.permanent_session_lifetime)
try:
data = s.loads(val, max_age=max_age)
return self.session_class(data)
except BadSignature:
return self.session_class()
- 解析session cookie的值
签名可以确保session cookie的内容不被篡改,但这并不意味着没法获取加密前的原始数据。所以session中不能存入敏感数据
>>> from itsdangerous import base64_decode
>>> s = 'eyJjc3JmX3Rva2VuIjp7IiBiI...'
>>> data, timstamp, secret = s.split('.')
>>> base64_decode(data)
'{"answer":42}'
- 服务器端存储用户会话
Flask提供的session将用户会话存储在客户端。
另一种实现用户会话的方式是在服务器端存储用户会话,而客户端只存储一个session ID。当接收到客户端的请求时,可以根据cookie中的session ID来找到对应的用户会话内容。这种方法更为安全和强健,可以使用扩展Flask-Session来实现这种方式的session。
蓝本
- route()方法
# flask/blueprints.py
class Blueprint(_PackageBoundObject):
def route(self, rule, **options):
"""Like :meth:`Flask.route` but for a blueprint. The endpoint for the
:func:`url_for` function is prefixed with the name of the blueprint.
"""
def decorator(f):
endpoint = options.pop("endpoint", f.__name__)
self.add_url_rule(rule, endpoint, f, **options)
return f
return decorator
- add_url_rule()方法
class Blueprint(_PackageBoundObject):
...
def add_url_rule(self, rule, endpoint=None, view_func=None, **options):
"""Like :meth:`Flask.add_url_rule` but for a blueprint. The endpoint for
the :func:`url_for` function is prefixed with the name of the blueprint.
"""
if endpoint:
assert "." not in endpoint, "Blueprint endpoints should not contain dots"
if view_func and hasattr(view_func, "__name__"):
assert (
"." not in view_func.__name__
), "Blueprint view function name should not contain dots"
self.record(lambda s: s.add_url_rule(rule, endpoint, view_func, **options))
...
- record()方法
这个方法主要的作用是把传入的函数添加到deferred_functions属性中,这是一个存储所有延迟执行的函数的列表。
# flask/blueprints.py
class Blueprint(_PackageBoundObject):
...
def record(self, func):
"""Registers a function that is called when the blueprint is
registered on the application. This function is called with the
state as argument as returned by the :meth:`make_setup_state`
method.
"""
if self._got_registered_once and self.warn_on_modifications:
from warnings import warn
warn(
Warning(
"The blueprint was already registered once "
"but is getting modified now. These changes "
"will not show up."
)
)
# 蓝本中的视图函数和其他处理函数(回调函数)都临时保存到deferred_functions属性对应的列表中。可以猜想到,在注册蓝本时会依次执行这个列表包含的函数。
self.deferred_functions.append(func)
- record_once()方法
蓝本可以被注册多次,但是这并不代表蓝本中的其他函数可以被注册多次。比如模板上下文装饰器context_processor。为了避免重复写入deferred_functions列表,这些函数使用record_once()函数来录入,它会在调用前进行检查.
class Blueprint(_PackageBoundObject):
...
def record_once(self, func):
"""Works like :meth:`record` but wraps the function in another
function that will ensure the function is only called once. If the
blueprint is registered a second time on the application, the
function passed is not called.
"""
def wrapper(state):
# 通过state对象的first_registration属性来判断蓝本是否是第一次注册,以决定是否将函数加入deferred_functions列表。
if state.first_registration:
func(state)
# functools.wraps装饰器就是调用了update_wrapper方法。这样能让装饰函数保持原始函数的签名
return self.record(update_wrapper(wrapper, func))
- 使用Flask.register_blueprint()方法将蓝本注册到程序实例上
# flask/blueprints.py
class Flask(_PackageBoundObject):
...
@setupmethod
def register_blueprint(self, blueprint, **options):
"""Register a :class:`~flask.Blueprint` on the application. Keyword
arguments passed to this method will override the defaults set on the
blueprint.
Calls the blueprint's :meth:`~flask.Blueprint.register` method after
recording the blueprint in the application's :attr:`blueprints`.
:param blueprint: The blueprint to register.
:param url_prefix: Blueprint routes will be prefixed with this.
:param subdomain: Blueprint routes will match on this subdomain.
:param url_defaults: Blueprint routes will use these default values for
view arguments.
:param options: Additional keyword arguments are passed to
:class:`~flask.blueprints.BlueprintSetupState`. They can be
accessed in :meth:`~flask.Blueprint.record` callbacks.
.. versionadded:: 0.7
"""
first_registration = False
if blueprint.name in self.blueprints:
assert self.blueprints[blueprint.name] is blueprint, (
"A name collision occurred between blueprints %r and %r. Both"
' share the same name "%s". Blueprints that are created on the'
" fly need unique names."
% (blueprint, self.blueprints[blueprint.name], blueprint.name)
)
else:
# 蓝本注册后将保存在Flask类的blueprints属性中,它是一个存储蓝本名称与对应的蓝本对象的字典。
self.blueprints[blueprint.name] = blueprint
self._blueprint_order.append(blueprint)
# 将表示第一次注册的标志first_registration设为True
first_registration = True
blueprint.register(self, options, first_registration)
- register()方法
class Blueprint(_PackageBoundObject):
...
def register(self, app, options, first_registration=False):
"""Called by :meth:`Flask.register_blueprint` to register all views
and callbacks registered on the blueprint with the application. Creates
a :class:`.BlueprintSetupState` and calls each :meth:`record` callback
with it.
:param app: The application this blueprint is being registered with.
:param options: Keyword arguments forwarded from
:meth:`~Flask.register_blueprint`.
:param first_registration: Whether this is the first time this
blueprint has been registered on the application.
"""
self._got_registered_once = True
# 这个state对象其实是BlueprintSetupState类的实例
state = self.make_setup_state(app, options, first_registration)
if self.has_static_folder:
state.add_url_rule(
self.static_url_path + "/" ,
view_func=self.send_static_file,
endpoint="static",
)
for deferred in self.deferred_functions:
# deferred 为lambda s: s.add_url_rule(rule, endpoint, view_func, **options)
# state 为BlueprintSetupState对象
deferred(state)
...
- BlueprintSetupState类
class BlueprintSetupState(object):
"""Temporary holder object for registering a blueprint with the
application. An instance of this class is created by the
:meth:`~flask.Blueprint.make_setup_state` method and later passed
to all register callback functions.
"""
def __init__(self, blueprint, app, options, first_registration):
#: a reference to the current application
self.app = app
#: a reference to the blueprint that created this setup state.
self.blueprint = blueprint
#: a dictionary with all options that were passed to the
#: :meth:`~flask.Flask.register_blueprint` method.
self.options = options
#: as blueprints can be registered multiple times with the
#: application and not everything wants to be registered
#: multiple times on it, this attribute can be used to figure
#: out if the blueprint was registered in the past already.
self.first_registration = first_registration
subdomain = self.options.get("subdomain")
if subdomain is None:
subdomain = self.blueprint.subdomain
#: The subdomain that the blueprint should be active for, ``None``
#: otherwise.
self.subdomain = subdomain
url_prefix = self.options.get("url_prefix")
if url_prefix is None:
url_prefix = self.blueprint.url_prefix
#: The prefix that should be used for all URLs defined on the
#: blueprint.
self.url_prefix = url_prefix
#: A dictionary with URL defaults that is added to each and every
#: URL that was defined with the blueprint.
self.url_defaults = dict(self.blueprint.url_values_defaults)
self.url_defaults.update(self.options.get("url_defaults", ()))
def add_url_rule(self, rule, endpoint=None, view_func=None, **options):
"""A helper method to register a rule (and optionally a view function)
to the application. The endpoint is automatically prefixed with the
blueprint's name.
"""
if self.url_prefix is not None:
if rule:
rule = "/".join((self.url_prefix.rstrip("/"), rule.lstrip("/")))
else:
rule = self.url_prefix
options.setdefault("subdomain", self.subdomain)
if endpoint is None:
endpoint = _endpoint_from_view_func(view_func)
defaults = self.url_defaults
if "defaults" in options:
defaults = dict(defaults, **options.pop("defaults"))
# 调用程序实例上的Flask.add_url_rule()方法来添加URL规则。
self.app.add_url_rule(
rule,
"%s.%s" % (self.blueprint.name, endpoint),
view_func,
defaults=defaults,
**options
)
模板渲染
在视图函数中,我们使用render_template()函数来渲染模板,传入模板的名称和需要注入模板的关键词参数.
- render_template()函数
# flask/templating.py
# template_name_or_list参数是文件名或是包含文件名的列表
# **context参数是我们调用render_template()函数时传入的上下文参数
def render_template(template_name_or_list, **context):
"""Renders a template from the template folder with the given
context.
:param template_name_or_list: the name of the template to be
rendered, or an iterable with template names
the first one existing will be rendered
:param context: the variables that should be available in the
context of the template.
"""
ctx = _app_ctx_stack.top
ctx.app.update_template_context(context) # 更新模板上下文
return _render(
ctx.app.jinja_env.get_or_select_template(template_name_or_list),
context,
ctx.app,
)
- update_template_context()方法
# flask/app.py
class Flask(_PackageBoundObject):
...
# 我们使用context_processor装饰器注册模板上下文处理函数,这些处理函数被存储在Flask.template_context_processors字典里. 字典的键为蓝本的名称,全局的处理函数则使用None作为键。默认的处理函数是templa ting._default_template_ctx_pro-cessor(),它把当前上下文中的request、session和g注入模板上下文。
self.template_context_processors = {None: [_default_template_ctx_processor]}
...
def update_template_context(self, context):
"""Update the template context with some commonly used variables.
This injects request, session, config and g into the template
context as well as everything template context processors want
to inject. Note that the as of Flask 0.6, the original values
in the context will not be overridden if a context processor
decides to return a value with the same key.
:param context: the context as a dictionary that is updated in place
to add extra variables.
"""
# 获取全局的模板上下文处理函数
funcs = self.template_context_processors[None]
reqctx = _request_ctx_stack.top
if reqctx is not None:
bp = reqctx.request.blueprint
if bp is not None and bp in self.template_context_processors:
# 获取蓝本下的模板上下文处理函数
funcs = chain(funcs, self.template_context_processors[bp])
# 先复制原始的context并在最后更新了它,这是为了确保最初设置的值不被覆盖,即视图函数中使用render_tem-plate()函数传入的上下文参数优先。
orig_ctx = context.copy()
for func in funcs:
# update_template_context()方法的主要任务就是调用这些模板上下文处理函数,获取返回的字典,然后统一添加到con-text字典。
context.update(func())
# make sure the original values win. This makes it possible to
# easier add new variables in context processors without breaking
# existing views.
context.update(orig_ctx)
- jinja_env()方法
# flask/app.py
class Flask(_PackageBoundObject):
...
# locked_cached_property装饰器定义在flask.helpers.locked_cached_property中,它的作用是将被装饰的函数转变成一个延迟函数,也就是它的返回值会在第一次获取后被缓存。同时为了线程安全添加了基于RLock的可重入线程锁。
@locked_cached_property
def jinja_env(self): # 用来加载模板的Jinja2环境(templating.Environment类实例)
"""The Jinja environment used to load templates.
The environment is created the first time this property is
accessed. Changing :attr:`jinja_options` after that will have no
effect.
"""
return self.create_jinja_environment()
- create_jinja_environment()方法
# flask/app.py
from .templating import Environment
class Flask(_PackageBoundObject):
...
jinja_environment = Environment
...
def create_jinja_environment(self):
"""Create the Jinja environment based on :attr:`jinja_options`
and the various Jinja-related methods of the app. Changing
:attr:`jinja_options` after this will have no effect. Also adds
Flask-related globals and filters to the environment.
.. versionchanged:: 0.11
``Environment.auto_reload`` set in accordance with
``TEMPLATES_AUTO_RELOAD`` configuration option.
.. versionadded:: 0.5
"""
options = dict(self.jinja_options)
if "autoescape" not in options: # 设置转义
options["autoescape"] = self.select_jinja_autoescape
if "auto_reload" not in options: # 设置自动重载选项
options["auto_reload"] = self.templates_auto_reload
rv = self.jinja_environment(self, **options) # 用于加载模板
# 虽然之前已经通过调用update_template_context()方法向模板上下文中添加了request、session、g(由_default_template_ctx_processor()获取),这里再次添加是为了让导入的模板也包含这些变量。
rv.globals.update( # 添加多个全局对象
url_for=url_for,
get_flashed_messages=get_flashed_messages,
config=self.config,
# request, session and g are normally added with the
# context processor for efficiency reasons but for imported
# templates we also want the proxies in there.
request=request,
session=session,
g=g,
)
rv.filters["tojson"] = json.tojson_filter # 添加tojson过滤器
return rv
- templating.Environ ment类
#flask/templating.py
from jinja2 import Environment as BaseEnvironment
class Environment(BaseEnvironment):
"""Works like a regular Jinja2 environment but has some additional
knowledge of how Flask's blueprint works so that it can prepend the
name of the blueprint to referenced templates if necessary.
"""
def __init__(self, app, **options):
if "loader" not in options:
options["loader"] = app.create_global_jinja_loader()
BaseEnvironment.__init__(self, **options)
self.app = app
- get_or_select_template()方法
# jinja2/environment.py
class Environment(object):
...
@internalcode
def _load_template(self, name, globals):
if self.loader is None:
raise TypeError("no loader for this environment specified")
cache_key = (weakref.ref(self.loader), name)
if self.cache is not None:
template = self.cache.get(cache_key)
if template is not None and (
not self.auto_reload or template.is_up_to_date
):
return template
# 通过load方法加载模板
template = self.loader.load(self, name, globals)
# 第一次加载模板后,会存到self.cache中,后面直接从self.cache中获取模板
if self.cache is not None:
self.cache[cache_key] = template
return template
@internalcode
def get_template(self, name, parent=None, globals=None):
"""Load a template from the loader. If a loader is configured this
method asks the loader for the template and returns a :class:`Template`.
If the `parent` parameter is not `None`, :meth:`join_path` is called
to get the real template name before loading.
The `globals` parameter can be used to provide template wide globals.
These variables are available in the context at render time.
If the template does not exist a :exc:`TemplateNotFound` exception is
raised.
.. versionchanged:: 2.4
If `name` is a :class:`Template` object it is returned from the
function unchanged.
"""
if isinstance(name, Template):
return name
if parent is not None:
name = self.join_path(name, parent)
return self._load_template(name, self.make_globals(globals))
@internalcode
def get_or_select_template(self, template_name_or_list, parent=None, globals=None):
"""Does a typecheck and dispatches to :meth:`select_template`
if an iterable of template names is given, otherwise to
:meth:`get_template`.
.. versionadded:: 2.3
"""
if isinstance(template_name_or_list, (string_types, Undefined)):
return self.get_template(template_name_or_list, parent, globals)
elif isinstance(template_name_or_list, Template):
return template_name_or_list
return self.select_template(template_name_or_list, parent, globals)
def make_globals(self, d):
"""Return a dict for the globals."""
if not d:
return self.globals
return dict(self.globals, **d)
- load()方法
# jinja2/loaders.py
# flask.templating.DispatchingJinjaLoader类的父类
class BaseLoader(object):
@internalcode
def load(self, environment, name, globals=None):
"""Loads a template. This method looks up the template in the cache
or loads one by calling :meth:`get_source`. Subclasses should not
override this method as loaders working on collections of other
loaders (such as :class:`PrefixLoader` or :class:`ChoiceLoader`)
will not call this method but `get_source` directly.
"""
code = None
if globals is None:
globals = {}
# first we try to get the source for this template together
# with the filename and the uptodate function.
source, filename, uptodate = self.get_source(environment, name)
# try to load the code from the bytecode cache if there is a
# bytecode cache configured.
bcc = environment.bytecode_cache
if bcc is not None:
bucket = bcc.get_bucket(environment, name, filename, source)
code = bucket.code
# if we don't have code so far (not cached, no longer up to
# date) etc. we compile the template
if code is None:
code = environment.compile(source, name, filename)
# if the bytecode cache is available and the bucket doesn't
# have a code so far, we give the bucket the new code and put
# it back to the bytecode cache.
if bcc is not None and bucket.code is None:
bucket.code = code
bcc.set_bucket(bucket)
return environment.template_class.from_code(
environment, code, globals, uptodate
)
- DispatchingJinjaLoader类的get_source()方法
class DispatchingJinjaLoader(BaseLoader):
"""A loader that looks for templates in the application and all
the blueprint folders.
"""
def __init__(self, app):
self.app = app
def get_source(self, environment, template):
if self.app.config["EXPLAIN_TEMPLATE_LOADING"]:
return self._get_source_explained(environment, template)
return self._get_source_fast(environment, template)
...
def _get_source_fast(self, environment, template):
for _srcobj, loader in self._iter_loaders(template):
try:
return loader.get_source(environment, template)
except TemplateNotFound:
continue
raise TemplateNotFound(template)
def _iter_loaders(self, template):
loader = self.app.jinja_loader
if loader is not None:
yield self.app, loader
for blueprint in self.app.iter_blueprints():
loader = blueprint.jinja_loader
if loader is not None:
yield blueprint, loader
- jinja_loader()方法
# flask/helpers.py
class _PackageBoundObject(object):
@locked_cached_property
def jinja_loader(self):
"""The Jinja loader for this package bound object.
.. versionadded:: 0.5
"""
if self.template_folder is not None:
return FileSystemLoader(os.path.join(self.root_path, self.template_folder))
- 最终调用FileSystemLoader类的get_source()方法
# jinja2/loaders.py
class FileSystemLoader(BaseLoader):
...
def get_source(self, environment, template):
pieces = split_template_path(template)
for searchpath in self.searchpath:
filename = path.join(searchpath, *pieces)
f = open_if_exists(filename)
if f is None:
continue
try:
contents = f.read().decode(self.encoding)
finally:
f.close()
mtime = path.getmtime(filename)
def uptodate():
try:
return path.getmtime(filename) == mtime
except OSError:
return False
return contents, filename, uptodate
raise TemplateNotFound(template)
- _render()函数
# flask/templating.py
def _render(template, context, app):
"""Renders the template and fires the signal"""
# 发送信号
before_render_template.send(app, template=template, context=context)
# 渲染模板, 渲染工作结束后会返回渲染好的unicode字符串,这个字符串就是最终的视图函数返回值,即响应的主体,也就是返回给浏览器的HTML页面。
rv = template.render(context)
# 发送信号
template_rendered.send(app, template=template, context=context)
return rv
FQA
app = Flask(name)中的__name__有什么作用?
Flask类的构造函数只有一个必须指定的参数,即应用主模块或包的名称。在大多数应用中,Python的__name__变量就是所需的值。Flask用这个参数确定应用的位置,进而找到应用中其他文件的位置,例如模板和其它静态文件。