MobileNetV2详解与多动物分类实战
一.MobileNet详解
MobileNetV1
传统的CNN内存需求大,运算量大,导致无法在移动设备以及嵌入式设备上运行。通过研究发现,卷积层和全连接层是最费时的两个阶段,batch_size越大耗时越大,因此需要对他进行轻量化。

在MobileNet中,使用深度可分离卷积,即DW(deoth-wise)卷积和PW(point-wise)卷积代替传统的卷积,可以有效减少参数数量。
DW卷积的每一个卷积核只负责输入特征矩阵的一个channel维度,所以卷积核的channel=1,输入特征矩阵的channel=卷积核个数=输出特征矩阵channel。也就是说,经过DW卷积之后,特征矩阵维度(channel)不会发生变化。
PW卷积的结构与传统卷积相同,它的特点是卷积核大小为1 。
将DW与PW卷积结合使用就构成了MobileNet网络。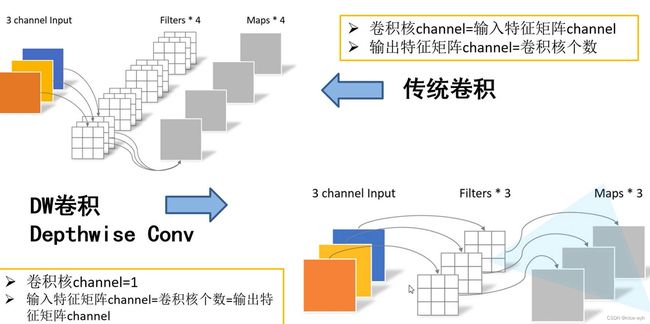

这样构成的网络可以有效减少参数数量,使网络更加轻量化。
在参数量的计算上,传统卷积为DF*DF*DK*DK*M*N,DW+PW为DF*DF*DK*DK*M+DF*DF*M*N

在网络中,还有2个超参数α和β,分别控制卷积核个数 和输入图片分辨率.
对于下图的网络结构,Conv/s1代表DW卷积,Conv/s1代表PW卷积,网络就是有这些模块堆叠而成;输入的尺寸大小为224*224*3,卷积层最后一层输出的是7*7*1024,之后经过全局平均池化把每一个7*7求一个平均值,变成了1*1*1024,再把这1024个数喂到全连接层(FC),输出这1000个;类别的logist,再经过sofamax归一化变成1000个概率。
MobileNetV2
V1网络主要使用深度可分离卷积的堆叠,原论文指出,在训练完成后。DW卷积的大部分卷积核参数都是0,说明并没有起到作用,因此诞生了改进版本的MobileNetV2。
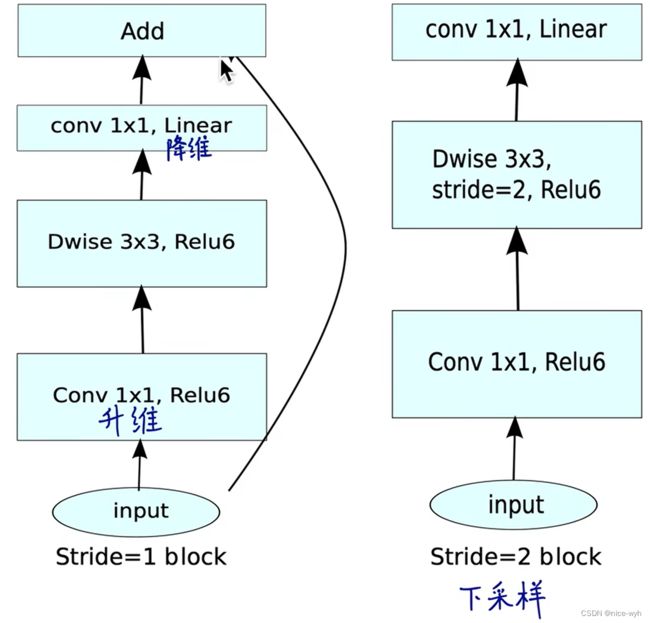
在V2中,除了还继续使用深度可分离之外,还使用了Expansion layer和Projection layer。
projection layer也是使用1*1卷积将低维空间映射到高维空间;Expansion layer则是使用1*1卷积将低维空间映射到高维空间。
此图更详细的展示了整个模块的结构。我们输入是24维,最后输出也是24维。但这个过程中,我们扩展了6倍,然后应用深度可分离卷积进行处理。整个网络是中间胖,两头窄,像一个纺锤形。bottleneck residual block(ResNet论文中的)是中间窄两头胖,在MobileNetV2中正好反了过来,所以,在MobileNetV2的论文中我们称这样的网络结构为Inverted residuals。需要注意的是residual connection是在输入和输出的部分进行连接。另外,我们之前已经花了很大篇幅来讲Linear Bottleneck,因为从高维向低维转换,使用ReLU激活函数可能会造成信息丢失或破坏(不使用非线性激活数数)。所以在projection convolution这一部分,我们不再使用ReLU激活函数而是使用线性激活函数。
二.数据集准备
新建一个项目文件夹MobileNet,并在里面建立data_set文件夹用来保存数据集,在data_set文件夹下创建新文件夹"raw_data",下载一个准备好的数据集(这里采用的10分类的动物数据集)
链接: https://pan.baidu.com/s/12fxvkaIJ9cnmz7iTbU3RtA 提取码: 8x8w 复制这段内容后打开百度网盘手机App,操作更方便哦
将它解压到raw_data文件夹下,执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val。

split.py如下:
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "raw_data")
origin_flower_path = os.path.join(data_root, "raw_photo")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
之后会在文件夹下生成train和val数据集,到此,完成了数据集的准备。
三.定义网络
根据网络的整体结构可以了解到V2网络采用了bottleneck(倒残差结构),多个(表格中的参数n为其个数)bottleneck组合成block。
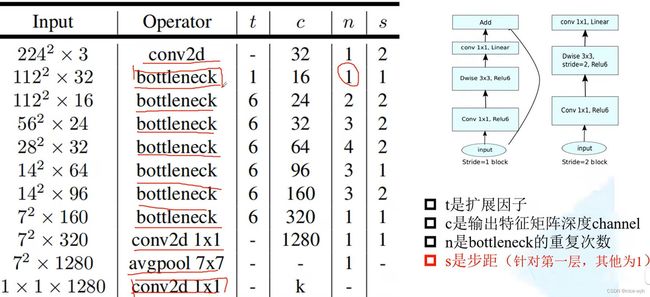
这里根据pytorch官方给出代码进行简单修改和简化,完成网络定义,具体的代码逻辑可以看下方修改后的代码注释。
pytorch官方源代码MobileNetV2
修改后的train.py:
from torch import nn
import torch
# 将channel调整为离8最近的整数倍,这样的处理对硬件更加的友好,也有一定训练速度的提升
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
# 这里如果group=1,则为普通卷积;group=输入特征矩阵的深度时,则为DW卷积
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
# 当步长为1,且输入输出维度相同时,使用捷径分支
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
# t:将输入特征矩阵深度调整t倍
# c:输入channel
# n:bottle(倒残差结构重复的次数)
# s:每个block中,第一个bottleneck的步长
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
if __name__ == "__main__":
net = MobileNetV2(num_classes=10)
in_data = torch.randn(1, 3, 224, 224)
out = net(in_data)
print(out)
完成网络的定义之后,可以单独执行一下这个文件,用来验证网络定义的是否正确。如果可以正确输出,就没问题。
在这里输出为
tensor([[-0.1906, 0.1323, -0.0054, 0.0503, -0.4200, -0.2074, -0.1114, 0.4141,
0.2739, -0.0870]], grad_fn=
说明网络定义正确。
四.开始训练
加载数据集
首先定义一个字典,用于用于对train和val进行预处理,包括裁剪成224*224大小,训练集随机水平翻转(一般验证集不需要此操作),转换成张量,图像归一化。
然后利用DataLoader模块加载数据集,并设置batch_size为16,同时,设置数据加载器的工作进程数nw,加快速度。
import os
import sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"using {device} device.")
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 获取数据集路径
image_path = os.path.join(os.getcwd(), "data_set", "raw_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
# 加载数据集,准备读取
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"), transform=data_transform["train"])
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"])
nw = min([os.cpu_count(), 16 if 16 > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
# 加载数据集
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True, num_workers=nw)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=16, shuffle=False, num_workers=nw)
train_num = len(train_dataset)
val_num = len(validate_dataset)
print(f"using {train_num} images for training, {val_num} images for validation.")生成json文件
将训练数据集的类别标签转换为字典格式,并将其写入名为'class_indices.json'的文件中。
- 从
train_dataset中获取类别标签到索引的映射关系,存储在flower_list变量中。 - 使用列表推导式将
flower_list中的键值对反转,得到一个新的字典cla_dict,其中键是原始类别标签,值是对应的索引。 - 使用
json.dumps()函数将cla_dict转换为JSON格式的字符串,设置缩进为4个空格。 - 使用
with open()语句以写入模式打开名为'class_indices.json'的文件,并将JSON字符串写入文件
# {'cane':0, 'cavallo':1, 'elefante':2, 'farfalla':3, 'gallina':4, 'gatto':5, 'mucca':6, 'pecora':7, 'ragno':8, 'scoiattolo':9}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)加载预训练模型开始训练
首先定义网络对象net,在这里我们使用了迁移学习来使网络训练效果更好;这里需要注意的是因为预训练参数是基于ImageNet数据集训练的,类别为1000,而我们这里需要做的是10分类,所以需要删掉最后一层参数,只保留其他部分;训练10轮,并使用train_bar = tqdm(train_loader, file=sys.stdout)来可视化训练进度条,之后再进行反向传播和参数更新;同时,每一轮训练完成都要进行学习率更新;之后开始对验证集进行计算精确度,完成后保存模型。
# load pretrain weights
# download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
net = MobileNetV2(num_classes=10)
model_weight_path = "./mobilenet_v2.pth"
assert os.path.exists(model_weight_path), f"file {model_weight_path} dose not exist."
pre_weights = torch.load(model_weight_path, map_location='cpu')
# delete classifier weights,因为预训练参数是基于ImageNet数据集训练的,类别为1000,所以需要删掉最后一层参数,只保留其他部分
pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# freeze features weights
for param in net.features.parameters():
param.requires_grad = False
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
epochs = 5
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = f"train epoch[{epoch + 1}/{epochs}] loss:{loss:.3f}"
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = f"valid epoch[{epoch + 1}/{epochs}]"
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net, "./MobileNetV2.pth")
print('Finished Training')
if __name__ == '__main__':
main()最后对代码进行整理,完整的train.py如下
import os
import sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"using {device} device.")
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 获取数据集路径
image_path = os.path.join(os.getcwd(), "data_set", "raw_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
# 加载数据集,准备读取
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"), transform=data_transform["train"])
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"])
nw = min([os.cpu_count(), 16 if 16 > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
# 加载数据集
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True, num_workers=nw)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=16, shuffle=False, num_workers=nw)
train_num = len(train_dataset)
val_num = len(validate_dataset)
print(f"using {train_num} images for training, {val_num} images for validation.")
# {'cane':0, 'cavallo':1, 'elefante':2, 'farfalla':3, 'gallina':4, 'gatto':5, 'mucca':6, 'pecora':7, 'ragno':8, 'scoiattolo':9}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# load pretrain weights
# download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
net = MobileNetV2(num_classes=10)
model_weight_path = "./mobilenet_v2.pth"
assert os.path.exists(model_weight_path), f"file {model_weight_path} dose not exist."
pre_weights = torch.load(model_weight_path, map_location='cpu')
# delete classifier weights,因为预训练参数是基于ImageNet数据集训练的,类别为1000,所以需要删掉最后一层参数,只保留其他部分
pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# freeze features weights
# 预训练模型中,我们只希望微调最后几层,因此冻结前面的权重和偏置参数
for param in net.features.parameters():
param.requires_grad = False
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
epochs = 5
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = f"train epoch[{epoch + 1}/{epochs}] loss:{loss:.3f}"
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = f"valid epoch[{epoch + 1}/{epochs}]"
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net, "./MobileNetV2.pth")
print('Finished Training')
if __name__ == '__main__':
main()
五.模型预测
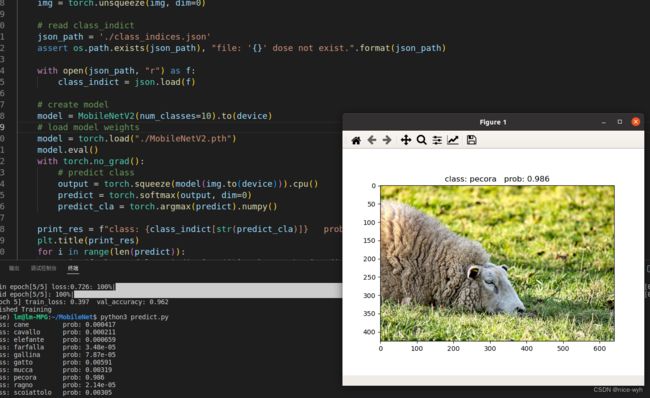
新建一个predict.py文件用于预测,将输入图像处理后转换成张量格式,img = torch.unsqueeze(img, dim=0)是在输入图像张量 img 的第一个维度上增加一个大小为1的维度,因此将图像张量的形状从 [通道数, 高度, 宽度 ] 转换为 [1, 通道数, 高度, 宽度]。然后加载模型进行预测,并打印出结果,同时可视化。
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "./ea34b0062bf4063ed1584d05fb1d4e9fe777ead218ac104497f5c978a6ebb3bf_640.jpg"
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = MobileNetV2(num_classes=10).to(device)
# load model weights
model = torch.load("./MobileNetV2.pth")
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = f"class: {class_indict[str(predict_cla)]} prob: {predict[predict_cla].numpy():.3}"
plt.title(print_res)
for i in range(len(predict)):
print(f"class: {class_indict[str(i)]:10} prob: {predict[i].numpy():.3}")
plt.show()
if __name__ == '__main__':
main()
预测结果
六.模型可视化
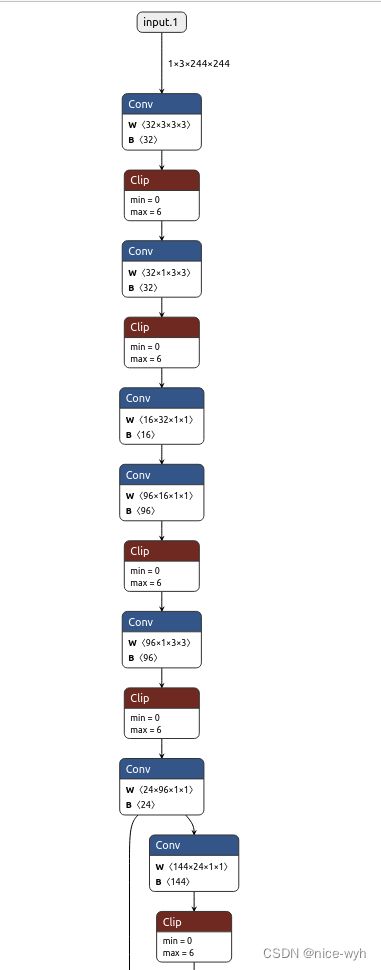
将生成的pth文件导入netron工具,可视化结果为

发现很不清晰,因此将它转换成多用于嵌入式设备部署的onnx格式
编写onnx.py
import torch
import torchvision
from model_v2 import MobileNetV2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MobileNetV2(num_classes=10).to(device)
model=torch.load("/home/lm/MobileNet/MobileNetV2.pth")
model.eval()
example = torch.ones(1, 3, 244, 244)
example = example.to(device)
torch.onnx.export(model, example, "MobileNetV2.onnx", verbose=True, opset_version=11)
七.批量数据预测
现在新建一个dta文件夹,里面放入五类带预测的样本,编写代码完成对整个文件夹下所有样本的预测,即批量预测。
batch_predict.py如下:
import os
import json
import torch
from PIL import Image
from torchvision import transforms
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
# 指向需要遍历预测的图像文件夹
imgs_root = "./data/imgs"
# 读取指定文件夹下所有jpg图像路径
img_path_list = [os.path.join(imgs_root, i) for i in os.listdir(imgs_root) if i.endswith(".jpg")]
# read class_indict
json_file = open('./class_indices.json', "r")
class_indict = json.load(json_file)
# create model
model = MobileNetV2(num_classes=10).to(device)
model = torch.load("./MobileNetV2.pth")
# prediction
model.eval()
batch_size = 8 # 每次预测时将多少张图片打包成一个batch
with torch.no_grad():
for ids in range(0, len(img_path_list) // batch_size):
img_list = []
for img_path in img_path_list[ids * batch_size: (ids + 1) * batch_size]:
img = Image.open(img_path)
img = data_transform(img)
img_list.append(img)
# batch img
# 将img_list列表中的所有图像打包成一个batch
batch_img = torch.stack(img_list, dim=0)
# predict class
output = model(batch_img.to(device)).cpu()
predict = torch.softmax(output, dim=1)
probs, classes = torch.max(predict, dim=1)
for idx, (pro, cla) in enumerate(zip(probs, classes)):
print(f"image: {img_path_list[ids*batch_size+idx]} class: {class_indict[str(cla.numpy())]} prob: {pro.numpy():.3}")
if __name__ == '__main__':
main()
运行之后,输出
image: ./data/imgs/ea34b4062cf6043ed1584d05fb1d4e9fe777ead218ac104497f5c97ca5edb3bd_640.jpg class: ragno prob: 1.0
image: ./data/imgs/e833b20820f4073ed1584d05fb1d4e9fe777ead218ac104497f5c97ca5ecb5b1_640.jpg class: ragno prob: 1.0
image: ./data/imgs/ea37b0062bfc093ed1584d05fb1d4e9fe777ead218ac104497f5c97faeebb5bb_640.jpg class: farfalla prob: 1.0
image: ./data/imgs/ea37b70b20fd003ed1584d05fb1d4e9fe777ead218ac104497f5c97faeebb5bb_640.jpg class: farfalla prob: 0.998
image: ./data/imgs/ea34b4062cf7013ed1584d05fb1d4e9fe777ead218ac104497f5c97ca5edb3bd_640.jpg class: ragno prob: 0.922
image: ./data/imgs/ea36b0082af5053ed1584d05fb1d4e9fe777ead218ac104497f5c97faee8b1b8_640.jpg class: farfalla prob: 0.998
image: ./data/imgs/ea34b3072ff1043ed1584d05fb1d4e9fe777ead218ac104497f5c97ca5edb3bd_640.jpg class: ragno prob: 0.957
image: ./data/imgs/ea37b20d2bfc063ed1584d05fb1d4e9fe777ead218ac104497f5c97faee8b1b8_640.jpg class: farfalla prob: 0.998
image: ./data/imgs/ea34b3072ff1033ed1584d05fb1d4e9fe777ead218ac104497f5c97ca5ecb3b9_640.jpg class: ragno prob: 0.983
image: ./data/imgs/ea36b7072ff0023ed1584d05fb1d4e9fe777ead218ac104497f5c97faeebb5bb_640.jpg class: farfalla prob: 0.989
image: ./data/imgs/ea36b7072ff7083ed1584d05fb1d4e9fe777ead218ac104497f5c97faee9bdba_640.jpg class: farfalla prob: 0.999
image: ./data/imgs/e834b2082afc093ed1584d05fb1d4e9fe777ead218ac104497f5c97ca5edb3bd_640.jpg class: ragno prob: 0.906
image: ./data/imgs/e832b5072ef4053ed1584d05fb1d4e9fe777ead218ac104497f5c97ca5edb3bd_640.jpg class: ragno prob: 0.982
image: ./data/imgs/ea36b4092dfc033ed1584d05fb1d4e9fe777ead218ac104497f5c97faee9bdba_640.jpg class: farfalla prob: 0.998
image: ./data/imgs/e83cb4072bf21c22d2524518b7444f92e37fe5d404b0144390f8c47ba7ebb0_640.jpg class: ragno prob: 1.0
image: ./data/imgs/ea36b10929f6023ed1584d05fb1d4e9fe777ead218ac104497f5c97faeebb5bb_640.jpg class: farfalla prob: 0.999
完成预期功能
八.模型改进
这里采用了迁移学习的方法,可以有效的提高训练精度,更快的收敛;同时由于模型的轻量化,模型预测速度很快,可以有效的部署在嵌入式设备上,典型应用如手机的人脸识别等。
同时,这里采用的是MobileNetV2,后续也将尝试MobileNetV3网络。
还有其他方法会在之后进行补充。