小红书达人账号数据分析
文章目录
-
- 一、项目背景
- 二、数据预处理
-
- 1、查看数据
- 2、数据清洗
-
- 2.1对达人列表进行清洗
- 2.2对涨分榜进行清洗
- 2.3对MCN列表进行清洗
- 2.4对定性变量(分类变量)进行处理
- 3、表格处理
-
- 3.1合并达人列表和涨粉榜
- 三、分析与数据可视化
-
- 1、对达人列表进行相关性分析
- 2、达人账号指标可视化
-
- 2.1笔记报价与签约mcn公司
- 2.2达人账号标签选择
- 2.3赞藏总数与认证信息
- 四、总结
一、项目背景
本项目对小红书一个月的达人列表、MCN签约列表和涨粉榜三表进行分析,通过Tableau数据可视化和相关性分析探究小红书达人账号的运营情况。
明确问题:
分析影响达人账号获得点赞收藏和笔记报价的主要指标有哪些;
分析哪类标签博主在小红书发展趋势较好,为新账号提供发展方向;
分析签约MCN公司对运营较好的达人账号的影响,为未签约的博主提供建议。
二、数据预处理
1、查看数据
#导入库
import pandas as pd
import matplotlib.pyplot as plt
#解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
#pd读入文件
blogger = pd.read_csv('/home/mw/input/xiaohongshu2316/达人列表_小红书.csv',sep = ',')
fans = pd.read_csv('/home/mw/input/xiaohongshu2316/涨粉榜_2021-10.csv', sep = ',')
mcn = pd.read_csv('/home/mw/input/xiaohongshu2316/MCN列表_小红书.csv', sep = ',')
#查看数据规模
print(blogger.shape)
#查看数据前3行,查看列名是否一致
blogger.info()
blogger.head(3)

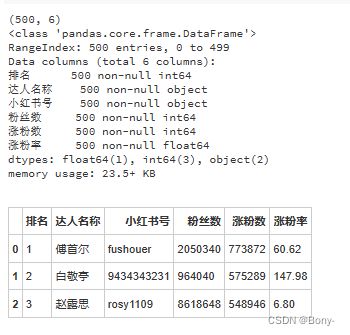
print(fans.shape)
fans.info()
fans.head(3)
print(mcn.shape)
mcn.info()
mcn.head(3)


2、数据清洗
检查数据集完整性,对空白值进行删除或填空。
#定义查看数据集情况的函数
def dfinfo(df):
print('重复数据条数:',df.duplicated().sum())
print('数据缺失情况:')
print(df.isnull().sum())
2.1对达人列表进行清洗
#查看达人列表数据情况
print(dfinfo(blogger))
#把报价和赞藏总数转换为浮点型
blogger['赞藏总数']= pd.to_numeric(blogger['赞藏总数'],errors='coerce')
blogger['图文笔记报价']= pd.to_numeric(blogger['图文笔记报价'],errors='coerce')
blogger['视频笔记报价']= pd.to_numeric(blogger['视频笔记报价'],errors='coerce')

可见达人列表没有重复值,认证信息和签约MCN字段缺失值过半,删除缺失值会导致数据量大幅度减少,所以采用填充方法处理缺失值:
(1)对“地域”、“简介”、“认证信息”、“签约MCN”、“达人标签”、“更新时间”这类文本字段的缺失值填充“未设置”;
(2)因“赞藏总数”只缺失一个,缺失值较少,对此填充”0“;
(3)因报价差距偏大,平均值易受影响,所以用中位数填充“视频笔记报价”和“图文笔记报价”字段的缺失值。
blogger["地域"].fillna('未设置',inplace=True)
blogger["简介"].fillna('未设置',inplace=True)
blogger["认证信息"].fillna('未认证',inplace=True)
blogger["签约MCN"].fillna('未签约',inplace=True)
blogger["达人标签"].fillna('未设置',inplace=True)
blogger["更新时间"].fillna('未设置',inplace=True)
blogger["赞藏总数"].fillna(0,inplace=True)
blogger["图文笔记报价"].fillna(blogger["图文笔记报价"].median(),inplace=True)
blogger["视频笔记报价"].fillna(blogger["视频笔记报价"].median(),inplace=True)
#填充后再次查看达人数据情况
dfinfo(blogger)
blogger.head(3)

2.2对涨分榜进行清洗
#查看涨分榜数据情况
dfinfo(fans)

可见涨分榜数据完整,没有缺失值
2.3对MCN列表进行清洗
#查看MCN列表数据情况
dfinfo(mcn)

同理达人列表:
(1)对“机构公司”、“简介”、“小红书号”、“TOP3达人”这类文本字段缺失值填充“未设置”;
(2)对“达人粉丝总数”这类数值型字段缺失值填充“0”。
mcn["机构公司"].fillna('未设置',inplace=True)
mcn["简介"].fillna('未设置',inplace=True)
mcn["小红书号"].fillna('未设置',inplace=True)
mcn["TOP3达人"].fillna('未设置',inplace=True)
mcn["达人粉丝总数"].fillna('0',inplace=True)
#填充后再次查看MCN数据情况
dfinfo(mcn)

2.4对定性变量(分类变量)进行处理
定量变量之间能直接计算相关系数进行相关性分析,但为更好地分析定性变量与定量变量之间的相关性,此处需要把定性变量转换为虚拟变量(哑变量),即从分类变量转化为数值型数据,可与定性变量计算相关系数。
#对达人标签字段进行处理
#消除标签栏首尾空格
blogger["达人标签"]=blogger["达人标签"].str.strip()
#把标签以空格为间隔生成为列表
tags=blogger["达人标签"].str.split(' ')
print(tags.head(3))
#把所有标签列表打散合成一个总列表
i=0
b_tags=[]
for i in range(len(tags)):
b_tags.extend(tags[i])
#查看总列表
print(b_tags[1])
#对标签列进行分类
blogger['分类达人标签']=blogger['达人标签']
#索引所有不等于未认证的行进行赋值
blogger.loc[blogger['分类达人标签'] != '未设置','分类达人标签'] = '已设置'

#同理对性别、认证信息、品牌合作人、签约MCN定性变量进行转化
#把认证信息和签约MCN分类
blogger['分类认证信息']=blogger['认证信息']
#索引所有不等于未认证的行进行赋值
blogger.loc[blogger['分类认证信息'] != '未认证','分类认证信息'] = '已认证'
blogger['分类签约MCN']=blogger['签约MCN']
#索引所有不等于未认证的行进行赋值
blogger.loc[blogger['分类签约MCN'] != '未签约','分类签约MCN'] = '已签约
#将达人列表的定性变量转换为哑变量
bl_dum = pd.DataFrame()
for i in ['性别','品牌合作人','认证类型','分类认证信息','分类签约MCN','分类达人标签']:
i = pd.get_dummies(blogger[i], prefix = i)
bl_dum = pd.concat([bl_dum,i],axis = 1)
bl_dum.head(2)'

#把所有哑变量和定量变量合成新表格
ls=['赞藏总数','粉丝数','图文笔记报价','视频笔记报价','商业笔记数']
blogger1=pd.concat([blogger[ls],bl_dum],axis = 1)
blogger1.head(3)

3、表格处理
3.1合并达人列表和涨粉榜
#基于小红书号进行连接
b_fans=pd.merge(blogger,fans,on="小红书号")
print(b_fans.shape)
b_fans.head(2)

三、分析与数据可视化
1、对达人列表进行相关性分析
#计算达人列表各字段之间的相关性
bl_pr=blogger1.corr(method="pearson")
bl_pr

#查看与赞藏总数相关性较高的指标
blogger1.corr(method="pearson")['赞藏总数'].sort_values(ascending = False)

相关系数r的判定条件为:|r|<= 0.3 不存在线性相关;0.3<=|r|<= 0.5 低度线性关系;0.5<=|r|<= 0.8 显著线性关系;|r| > 0.8 高度线性关系。由相关矩阵可知,达人账号的赞藏总数与粉丝数存在线性相关关系,与其他字段也存在一定的相关,其中相关度前五的指标分别为粉丝数 、商业笔记数、视频笔记报价 、分类达人标签_已设置、分类认证信息_已认证 。
#视频笔记报价比图文笔记报价普遍要高,查看与视频笔记报价相关性较高的指标
blogger1.corr(method="pearson")['视频笔记报价'].sort_values(ascending = False)
 达人账号的视频笔记报价相关度前三的指标分别为分类签约MCN_已签约 、图文笔记报价 、赞藏总数 、商业笔记数 、分类达人标签_已设置 。
达人账号的视频笔记报价相关度前三的指标分别为分类签约MCN_已签约 、图文笔记报价 、赞藏总数 、商业笔记数 、分类达人标签_已设置 。
2、达人账号指标可视化
运用Tableau进行数据可视化
2.1笔记报价与签约mcn公司
 二咖传媒和仙梓文化达人的笔记报价较高。
二咖传媒和仙梓文化达人的笔记报价较高。

在众多MCN公司中,侵尘文化、众灿互动、告趣和仙梓文化是发展较好的
2.2达人账号标签选择

多数达人账号会打上美妆个护、美食、搞笑、时尚和运动健身等标签,这些领域在小红书平台上较受欢迎。
2.3赞藏总数与认证信息
 美妆、美食、时尚博主和演员的赞藏总数比较多,其中演员的粉丝数最多,所以演员的赞藏总数可能是明星效应导致的。
美妆、美食、时尚博主和演员的赞藏总数比较多,其中演员的粉丝数最多,所以演员的赞藏总数可能是明星效应导致的。
四、总结
赞藏总数和笔记报价都是评判小红书账号商业价值的重要指标,根据相关性分析结果交叉验证,得出以下结论:
1、赞藏总数多的账号伴随着粉丝数较多,随后与之相关的就是商业笔记数、视频笔记报价 、美妆、美食、时尚博主和演员的标签和认证信息。因此,对于个人账号,应当保持一定频率的笔记更新,并选择美妆、美食、时尚博主等方向作为自己的主要方向,可以选择搞笑和运动健身作为附加标签。
2、视频笔记报价略高于图文笔记报价,对商家可以优先选择图文笔记进行推广,其中二咖传媒和仙梓文化的报价较高,但粉丝数也较高,商家可以根据宣发方案选择合适的博主。
3、大部分运营较好的账号都签约了MCN公司,个人账号可选择签约MCN公司以帮助运营账号,从商业价值和粉丝数这两方面来看,仙梓文化是较优秀的公司,若注重粉丝增长方面,可考虑侵尘文化、众灿互动、告趣公司。