java基础+数据库基础+系统+JVM问题
的哎的哎
1、基础部分
java线程池 队列的选择
答:
SingleThreadPool:适用于多个任务顺序执行的场景。
它使用的是LinkedBlockingQueue<>(),无界的阻塞队列,就意味着会有内存溢出的风险。
FixedThreadPool: 适用于任务量固定耗时长的任务。
队列同上
CachedThreadPool: 适合任务量大但耗时少的任务。
使用队列SynchronousQueue<>(),如果存在大量长时间的任务,会导致cpu占用率100%。
ScheduledThreadPool:适合固定周期的任务。
队列:DelayedWorkQueue,但无界的队列和无限的最大线程数,意味着它可能出现内存溢出和CPU占用率100%的问题
volatile 什么情况下会用到
答:
(可见性)适用一个线程写、多个线程读的场合,eg.作为状态转换标记
(线程间可见性+禁止指令重排)eg.双重检查的懒汉式单例,
对private static xxxSingleton singleton; 加volatile,可以防止内存判空和赋值的指令重排。
java 在多线程中操作共享变量的过程中,会存在指令重排序与共享变量工作内存缓存的问题。
系统用到的IO模型,各个模型的比较
答:Linux中有5中IO模型:
阻塞式IO模型
非阻塞式IO模型
IO多路复用
信号驱动的IO模型
异步IO模型
Java共支持三种网络编程模型(IO模型):
BIO 同步阻塞
NIO 同步非阻塞
AIO 异步非阻塞
应用场景:(最常用的就是同步阻塞 IO 和 IO 多路复用)
BIO:服务器启动ServerSocket;客户端启动ClientSocket,与服务器进行通讯。服务端也可以使用线程池。
NIO:位于java.nio包下,有三大核心部件:Seletor、Channel、Buffer;
IO多路复用(是NIO的一种):
如 Java 的 NIO、Redis、Nginx 的底层实现就是此类 IO 模型的应用,经典的 Reactor 模式也是基于此类 IO 模型。
RPC框架在网络通信上更倾向于哪种网络IO模型?
https://time.geekbang.org/column/article/204696?utm_source=related_read&utm_medium=article&utm_term=related_read
用到的设计模式
答:
工厂模式,在各种BeanFactory以及ApplicationContext创建中都用到了。AC是饿汉式加载,BF可设置成懒加载。
模版模式,同上,在BF\AC实现中有用到。
AbstractApplicationContext的refresh方法,就是模版模式应用。这里提供了3个扩展点,obtainFreshBeanFactory方法,postProcessBeanFactory方法,以及onRefresh方法,我们点进去这三个方法,可以看到他们并没有具体的实现,而是留给子类扩展实现。
代理模式,Spring AOP 利用了AspectJ AOP实现的。AspectJ AOP的低层用了动态代理。
动态代理有两种:目标方法有接口时,自动选用JDK动态代理。
目标方法没有接口时,选CGLib动态代理。
策略模式,加载资源文件的方式,使用了不同的方式,比如,ClassPathResource、FileSystemResource、ServletContextResource、UriResource,但他们都有公共的接口Resource.
单例模式,比如在spring创建bean的时候
建造者模式,减少参数传递,在内部创建对象,不对外直接暴露创建对象,链式调用。SpringBuilder、SpringSecurity都是用的建造者模式。
无损发布的问题?
为了发布不要影响到用户访问,为了不再在凌晨三点熬夜发布版本,无损发布就显得非常重要了。
那么能做到无损发布吗?答案是肯定的,需要nginx和web server配合完成,请看下面的流程图。
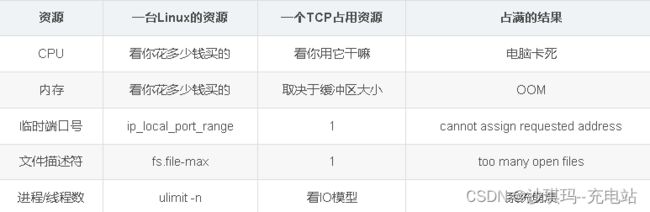
TCP连接数的问题
https://blog.csdn.net/qq_37165235/article/details/132448153
最大TCP连接数量限制有:可用端口号数量、文件描述符数量、线程、内存、CPU等。每个TCP连接都需要以下资源
1、可用端口号限制
Q:一台主机可以有多少端口号?端口号与TCP连接?是否能修改?端口号限制因素?
第一:端口号是16位的,所以总共有65535个,即可创建65535个TCP连接
第二:端口分为知名端口(01023)、注册端口(102449511)、动态/私有端口(49152~65535)
第三:端口数可以修改。
3、线程的限制
C10K:当服务器连接数达到 1 万且每个连接都需要消耗一个线程资源时,操作系统就会不停地忙于线程的上下文切换,最终导致系统崩溃。
传统的多线程并发模型:一个TCP连接就需要创建一个线程
I/O多路复用 :一个线程可以管理多个 TCP 连接的资源
解决: 不使用传统的多线程并发模型,而采用I/O多路复用技术
4、内存的限制
TCP连接数过大可能会出现: ERROR: out of memory ,即内存溢出。
**原因:**每个TCP连接本身,以及这个连接所用到的缓冲区,都是需要占用一定内存的,现在内存已经被占满了,不够用了就会报这个错。
5、CPU的限制
每个TCP连接都是需要占用CPU资源的,若占用CPU资源过多,则会导致死机,用户啥也干不了,然后就重启了,TCP连接也就全没了。
6、总结
数据库乐观锁
乐观锁的实现方式(ps:实现方式是多样的,没有定数,不过依赖的是相同的思想–要修改的数据要和读取的数据是同一数据,中途不能被修改)
1、建表时新增一个version字段,用于数据版本控制。
2、通过CAS算法实现
优点:
乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。
缺点:
乐观锁适用于读比较少的情况下(多写场景),如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能
所以一般多写的场景下用悲观锁就比较合适。
ThreadLocal 实现
https://baijiahao.baidu.com/s?id=1666270412047190730&wfr=spider&for=pc
ThreadLocal 实现,ThreadLocal应该是一个静态对象,执行set方法的时候实际上是执行的thread所持有的map的一个set方法,然后ThreadLocal 这个对象作作为map的key
最后调用remove方法删除数据,防止内存泄漏和数据混乱。
使用场景:一些ORM框架的Session管理,web系统的会话管理等
简单总结:一个ThreadLocal只能保存一个变量的副本,如果需要多个,就得创建多个变量;我们确定使用完需要执行remove避免内存泄漏。
2、数据库
如何解决慢查询
- 数据库表设计不佳
- 大量数据查询
- 锁竞争
- 查询语句的优化不足
- 数据库服务器性能问题
数据库回表
哪些情况下不会触发回表?
?3.1 覆盖索引
?3.2 使用聚簇索引
什么情况下会触发回表?
2.1 索引不Cover所有需要查询的字段
2.2 使用了非聚簇索引(非聚簇索引(Secondary Index)只包含了索引列的副本以及指向对应主键的引用,查询需要通过回表才能获取完整的行数据。)
2.3 使用了覆盖索引但超过了最大索引长度
在MySQL的InnoDB存储引擎中,每个索引项的最大长度是767字节,如果查询需要返回的字段长度超过了该限制,同样会触发回表操作。
需要注意的是,回表操作主要发生在读取操作(SELECT)中,写入操作(INSERT、UPDATE、DELETE)一般不会触发回表。
回表操作的问题和场景
?4.1 性能问题
回表操作通常需要访问两次索引,增加了IO开销和CPU消耗,对查询性能有一定的影响。特别是在高并发、大数据量的情况下,回表可能成为性能瓶颈。
?4.2 数据一致性
由于回表操作是基于物理地址来获取数据,如果在回表过程中发生了数据修改(如DELETE、UPDATE),则可能会读取到不一致或错误的数据。
?4.3 是否使用覆盖索引的判断
在选择是否使用覆盖索引时,需要综合考虑查询的字段以及字段长度,以及查询操作的频率和数据量。如果查询需要返回的字段较多或字段长度较长,可能需要权衡回表带来的性能损耗和数据完整性的需求。
索引怎么创建
3、建表的时候创建索引

1、使用CREATE INDEX创建,语法如下:
![]()
2、使用ALTER语句创建,语法如下:
![]()
主库从库的问题
https://zhuanlan.zhihu.com/p/612577857
MySQL主从同步基本流程

MySQL主从同步延迟原因

MySQL主从同步延迟原因

MySQL主从同步解决方案
介绍MySQL多线程同步工具(Transfer)的设计思路 以下为文字解释版

MVCC
https://blog.csdn.net/weixin_44941128/article/details/117871517
多版本并发控制
mysql会在数据表中默认添加三个隐藏列:
DB_ROW_ID:行id,若表没有主键,InnoDB 会自动生成一个隐藏主键
DB_TRX_ID:事务ID,当有事务开启时会生成这样一个全局递增的id;
DB_ROLL_PTR:回滚指针,通过这个指针可以找到该数据的历史版本,也就是所说的版本链。
版本链就是用一个单链表的结构存放每个事务版本对应的行的数据,通过我当前的事务id可以获取对应的数据。
Read View就是事务进行快照读操作的时候生产的可读视图(Read View),用来判断该数据版本是否可被访问,可读视图可以简单的理解成有三个全局属性:
trx_list:存放当前正活跃的事务ID;
low_limit_id:记录trx_list中事务ID最小的ID;
up_limit_id:可读视图生成时当前全局事务ID的最大值(也有一说是目前已出现过的事务ID的最大值+1)。
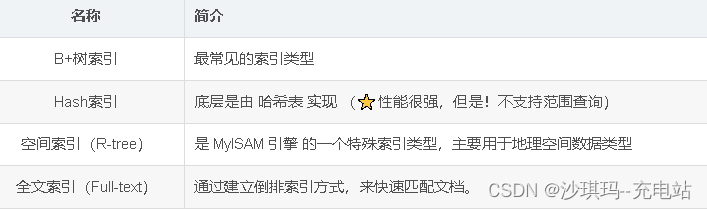
B+树的描述
二分查找数–》红黑树(平衡二叉树)–》B树(多路平衡二叉树)–》B+树(mysql的索引结构)
MySQL索引是在 存储引擎层 实现的,不同的存储引擎层,有不同的索引结构,主要包含四种索引:
3、系统
QPS统计怎么做
QPS(Query Per Second):每秒请求数,就是说服务器在一秒的时间内处理了多少个请求。
OK,用日志来估计!那日志怎么记录呢,细分下来,有两种方式。
方式一:自己在接口里记录
方式二:调用链
我们现在估计出了单机的QPS。接下来,估算集群的QPS。(QPS = 总请求数 / (进程总数 * 请求时间))
这就要根据负载均衡的策略来估计!
比如,你部署了32台机器,负载均衡的策略恰巧为轮询,那集群的QPS就是单机的QPS乘32就好了。
所以,根据具体的策略,来估计整个集群的QPS多大!一般有2000qps已经是很高的了。
CPU高的问题如何解决
系统监控层面
系统熔断,限流
4、具体项目
能够比较清晰的描述出具体项目做的一些内容已经具体的业务场景
说明一下各个系统之间的交互,以及系统的职责
5、JVM问题
java进程启动用到了哪些jvm命令,为什么要这样设置,比如NewRatio,CMS,ParNew,survivalRatio等
是否做过JVM调优
为什么要进行JVM调优
具体case
关于JVM的一些灵魂拷问
6、类加载器
双亲委派机制
上下文类加载器(上下文类加载器是线程在初始化的时候,从父线程中继承过来的)
写一道双亲委托的题(主要考察代理模式)
线程上下文类加载器有什么作用