天池零基础金融风控比赛小结
1 背景
去年九月份参加了天池举办的零基础入门金融风控-贷款违约预测比赛,赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的信息预测其是否有违约的可能,以此判断是否通过此项贷款,是一个典型的分类问题。
2 数据
赛题数据来源于某信贷平台的贷款记录,总数据量为120W,训练集,测试集A,测试集B数据量各位80W,20W,20W。原数据中包含47列变量信息,主要包括:贷款信息(金额,利率,贷款等级等),贷款人信息(就业信息,收入信息,债务比,FICO(一种信用评分),贷款记录等),贷款人行为计数特征信息(匿名特征)。查询完整的字段表可以访问赛题官网"赛题官网",或点击阅读原文查看我们Blog上的文章。
| Field | Description |
|---|---|
| id | 为贷款清单分配的唯一信用证标识 |
| loanAmnt | 贷款金额 |
| term | 贷款期限(year) |
| interestRate | 贷款利率 |
| installment | 分期付款金额 |
| grade | 贷款等级 |
| subGrade | 贷款等级之子级 |
| employmentTitle | 就业职称 |
| employmentLength | 就业年限(年) |
| homeOwnership | 借款人在登记时提供的房屋所有权状况 |
| annualIncome | 年收入 |
| verificationStatus | 验证状态 |
| issueDate | 贷款发放的月份 |
| purpose | 借款人在贷款申请时的贷款用途类别 |
| postCode | 借款人在贷款申请中提供的邮政编码的前3位数字 |
| regionCode | 地区编码 |
| dti | 债务收入比 |
| delinquency_2years | 借款人过去2年信用档案中逾期30天以上的违约事件数 |
| ficoRangeLow | 借款人在贷款发放时的fico所属的下限范围 |
| ficoRangeHigh | 借款人在贷款发放时的fico所属的上限范围 |
| openAcc | 借款人信用档案中未结信用额度的数量 |
| pubRec | 贬损公共记录的数量 |
| pubRecBankruptcies | 公开记录清除的数量 |
| revolBal | 信贷周转余额合计 |
| revolUtil | 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 |
| totalAcc | 借款人信用档案中当前的信用额度总数 |
| initialListStatus | 贷款的初始列表状态 |
| applicationType | 表明贷款是个人申请还是与两个共同借款人的联合申请 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 |
| title | 借款人提供的贷款名称 |
| policyCode | 公开可用的策略_代码=1新产品不公开可用的策略_代码=2 |
| n系列匿名特征 | 匿名特征n0-n14,为一些贷款人行为计数特征的处理 |
赛题需要参赛者输出每个测试样本为1(违约)的概率,以AUC为指标评估模型,如若模型输出有:
| id | isDefault |
|---|---|
| 800001 | 0.7 |
则代表模型预测id为80001的贷款违约概率为70%。
3 思路和方法
3.1 EDA+数据清洗
该部分主要为了了解数据类型,各种特征的数据分布和缺失值情况,并了解特征间的相关关系以及特征和目标值之间的相关关系。为接下来对数据进行简单清洗做准备。

特征箱线图
整体而言赛题数据相对干净,通过箱线图发现有一些数值特征中存在明显的异常值,决定使用箱型图+3-Sigma进行去除。对于缺失值,选择先构造一个新字段记录一个样本中缺失特征/总特征数量的比例(missrate),再用纵向填充的方法填充缺失值。此外通过计算Pearson相关系数可以看出有几对相关度很高的变量,例如匿名变n2-n3-n9,保留一个变量即可。
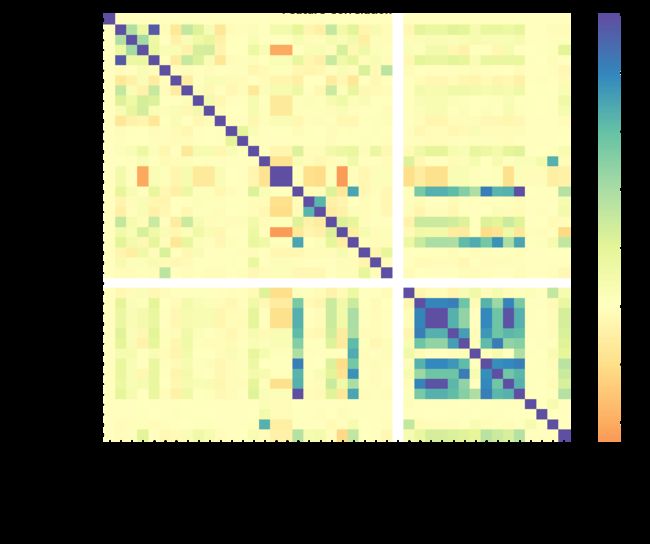
特征相关性热图
3.2 特征工程
经过EDA可以发现特征中有较多离散型变量,如贷款等级,工作职称,贷款目的,邮编等等,这些变量需要通过一定的编码方法进行变换。常见的one-hot encoding对于较低维度的变量(unique values < 100)效果不错,但是如果应用在高维变量上(如邮编,职称等),会产生过于稀疏的矩阵,导致每个类别里可以学习的数据过少。所以对于高维变量,一种比较有效的编码方式是target encoding,即用类别对应的标签的期望来代替原始的类别,这样相当于将高维的离散变量转换成了在0-1之间的数字变量。比较常用的定义方式为:

其中p为全部标签的均值,alpha为系数,用于控制该变量对依赖变量的拟合程度。
特征交互方面,简单构造了一些可能有实际意义的交互特征,这一部分的业务经验不多,有经验的小伙伴欢迎在评论区分享一下特征构造的思路。
# 利率/贷款总额
data['interestRateOLoanAmnt'] = data['interestRate']/data['loanAmnt']
# 年收入/贷款总额
data['annualIncomeOLoanAmnt'] = data['annualIncome']/data['loanAmnt']
# 年收入/就业年限
data['annualIncomeOImploymentLength'] = data['annualIncome']/data['employmentLength']
# 年收入*就业年限
data['annualIncomeMImploymentLength'] = data['interestRate']*data['loanAmnt']
# 未结信用额度的数量/当前的信用额度总数
data['openAccOTotalAcc'] = data['openAcc']/data['totalAcc']
# 未结信用额度的数量/最早信用额度开立距今时间
data['openAccOEarliestCreditLine'] = data['openAcc']/data['earliesCreditLine']
# 贬损公共记录的数量/贷款发放距今时间
data['pubRecOissueDate'] = data['pubRec']/data['issueDate']
最后根据EDA中的相关系数计算,去除了有高相关性的特征n2,n3(匿名变量,随机去除)和只有唯一值的特征,加上离散特征一共保留了约150个特征。
3.3 模型训练
模型训练部分的思路是尝试构造几个表现较强的单模型,再进行模型融合。一共尝试了 XGBoost, Light-GBM, Catboost以及MLP(4 layers) 4种模型,训练时对模型进行独立的参数优化。CatBoost 模型本身就可以很好地处理离散特征,并且碰巧它也是使用基于target encoding衍生的方法处理高维离散特征,所以使用CatBoost时省略了对离散特征进行预处理的步骤。此外对MLP模型处理之前,额外尝试了使用自动编码器进行变量交互,但是效果明显不如Boosting模型。
为了冲刺竞赛排名,模型融合也比较关键。我选择了表现较强的的三个Boosting模型,用简单加权平均(每个模型权重相同)的方法进行ensemble,让AUC成绩由单模型的0.7342提高到最终的0.7397。
4个单模型的训练表现如下:
| 模型 | Training AUC | Validation AUC | Test AUC * |
|---|---|---|---|
| XGBoost(baseline) | 0.7845 | 0.7367 | - |
| Light-GBM | 0.7407 | 0.7351 | - |
| CatBoost | 0.7446 | 0.7434 | 0.7342 |
| MLP | 0.7263 | 0.7247 | - |
-
获取test AUC数据需要上传预测值到天池平台,每天只有一次测试机会,所以在前期训练单个模型时,只收集了效果最好的CatBoost模型的AUC结果。
从模型对比来看,XGBoost的过拟合现象较为严重,LightGBM 比较均衡,CatBoost泛化能力很好并且表现出众。XGBoost模型中,超参数min_child_weight的值相对其他LightGBM中较小,这可能是模型过拟合的原因。CatBoost的优秀表现主要得益于对类别变量的强大处理能力。MLP模型表现一般,可能是数据规模还没有足够大到让它能够完全发挥挖掘非线性特征的能力。
3.4 特征重要性
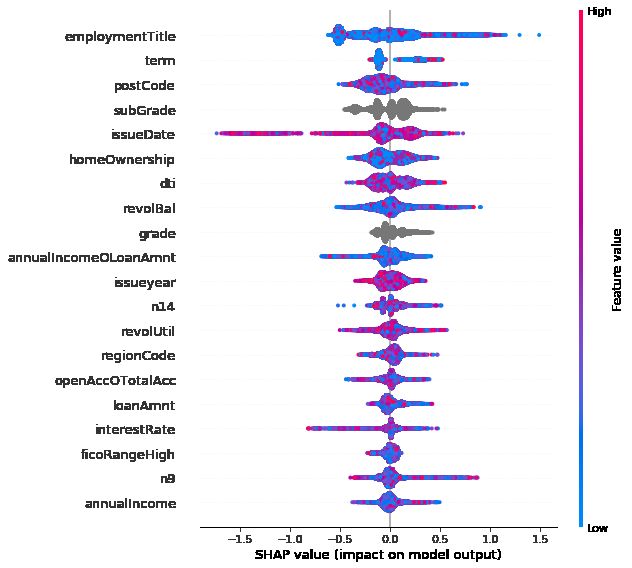
CatBoost模型特征的SHAP值- Top20
三个Boosting模型对特征重要性的评估略有区别,比较明显的区别是CatBoost模型中,离散数据的重要性普遍较高。以CatBoost的SHAP值为例,最重要的特征有点出乎意料地是申请人职称,此外,贷款期数,贷款子级,地区邮编,债务收入比等也有较高的SHAP值。对于数值型特征而言,三个模型的排序基本相似。在特征工程中构造的少数几个变量如审批时间,有效账户/总账户比也有幸被选进重要度前20。
4 总结
这次的赛题是一个经典的机器学习分类预测问题,Boosting模型实乃这种数据量的比赛中的大杀器,其中CatBoost又尤为适合挖掘离散型变量。再利用模型融合,最终在正赛阶段排名榜的Top30。但是由于业务经验有限,在特征工程方面给模型表现带来的提升不多,这应该是后期模型表现优化的主要方向。
5 参考
-
天池竞赛 零基础入门金融风控-贷款违约预测: https://tianchi.aliyun.com/competition/entrance/531830/information
-
Target Encoding 参考文献: A Preprocessing Scheme for High-Cardinality Categorical Attributes in Classification and Prediction Problems
-
CatBoost库: https://CatBoost.ai/