文本三剑客
grep
grep -v 取反
除了root用户,显示其他用户

grep -m 数字 多个匹配的,只取第几个

grep -i 不区分大小写
grep -c 显示过滤的个数

grep -o 只显示匹配的内容

grep -q 静默模式,不显示匹配的内容
如果想展示匹配的内容,可以将他重定向到一个新的文件中
grep -A 数字 只要匹配到一个,就把后面的几行一起展示出来

grep -B 数字 只要匹配到一个,就把前面的几行一起展示出来

grep -C 数字 只要匹配到一个,就把前面和后面的几行一起展示

grep -e 逻辑或

grep -w 精确匹配整个单词

grep -E 使用扩展正则表达式
grep-F 不支持扩展正则表达式
grep -f 以第一个文件为参照物,匹配文件2中所有包括文件1的内容

grep -r 递归目录,但不处理软链接
grep -R 递归目录,可以处理软链接
sort
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
sort -f 忽略大小写,默认会大写字母排在前面
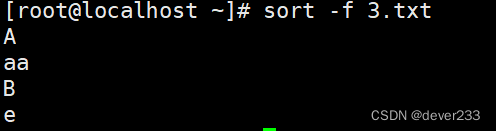
sort -b 忽略每行前面的空格
sort-n:按照数字进行排序

sort -r 反向排序

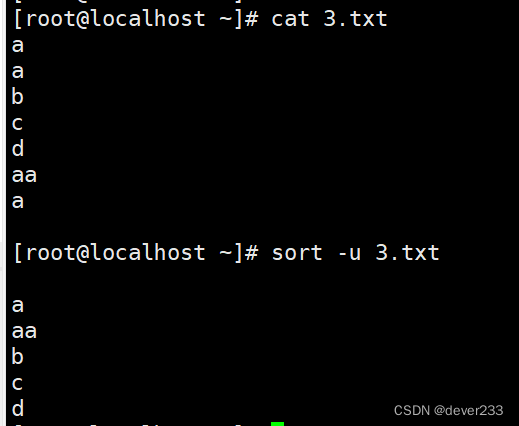
sort -u 去重
sort -t 指定字段分隔符,默认使用tab键分隔
sort -k 指定排序字段
sort -o 将排序的结果转存至指定文件
uniq
uniq命令用于报告或者忽略文件中连续的重复行,常与sort命令结合使用。
uniq -c 统计连续重复的行的次数,并且合并重复的行

uniq -u显示仅出现一次的行(包括不连续的重复行)

uniq -d 仅显示重复出现的行(的重复行)

tr
常用于对来自标准输入的字符进行替换、压缩和删除
tr -c 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换

tr -d :删除所有属于字符集1的字符

tr -s : 将重复出现的字符串压缩为一个字符串,用字符集2 替换 字符集1
![]()
-t:字符集2 替换 字符集1,不加也行
cut
对字段进行截取和剪裁
cut -d 指定分隔符(默认分隔符为Tab)
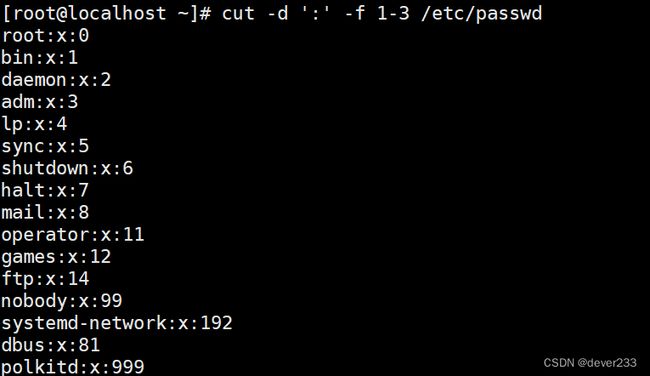
cut -f 按字段进行截取
以":"作为分隔符,指定第一个到第三个字段进行输出
cut -b 以字节为单位进行截取
cut -c 以字符为单位进行截取
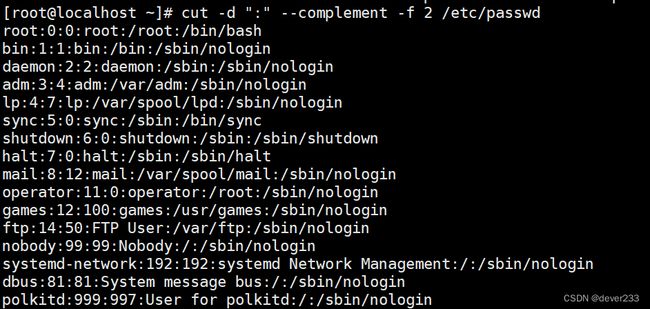
cut –complement 排除所指定的字段
以:为分隔符,打印除了第二个字段
cut -output-delimiter 更改输出内容的分隔符
以:为分隔符,将1-5列的分隔符替换成#,并打印出来

split
split命令用于在Linux下将大文件拆分为若干小文件。
格式:split 选项 参数 原始文件 拆分后文件名前缀
split -l 指定行数拆分

split -b 指定文件大小

paste
按照字段来进行文件的合并
paste是左右合并
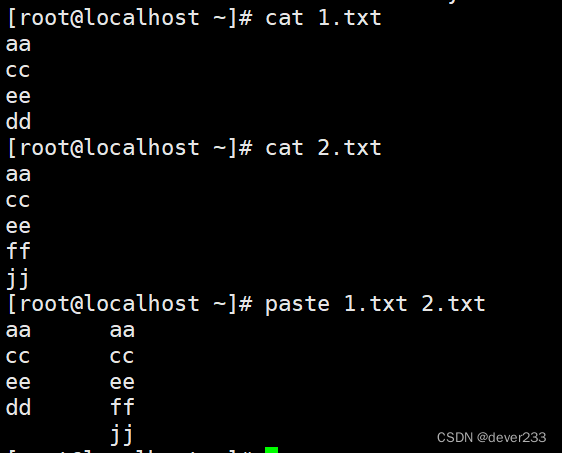
cat是上下合并
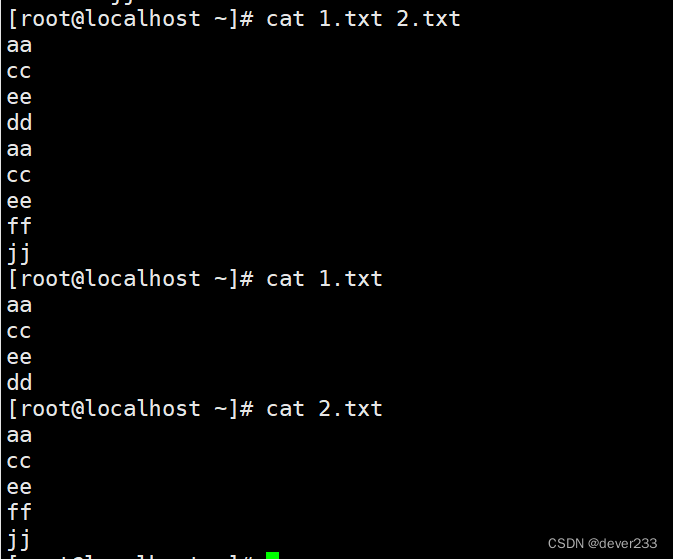
paste -d用于指定文件的分隔符(默认情况下为制表符"\n")
paste -s将列和行的内容进行互相交换

通配符
*:通配符匹配任意一个或多个字符
?:匹配一个任意字符(只能匹配一个)
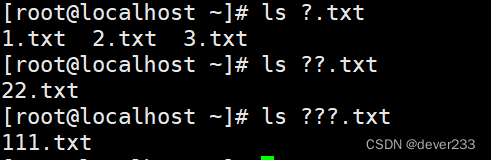
[ ] 匹配列表中的任意单个字符

基本正则表示式
[a-zA-Z] #同时匹配大小写
. 匹配任意单个字符,可以是一个汉字
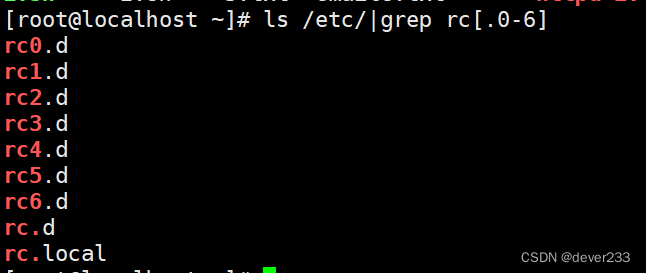
\. 转义字符+. 表示单个一个点

匹配空格 [[:space:]]
表示次数
* 匹配前面的字符任意次,包括0次
o不管有多少个,都能匹配出来,没有也可以匹配
.* 任意长度的任意字符,不包括0次,也就是匹配所有
o出现>=1次
\? 匹配其前面的字符出现0次或1次,即:可有可无
o只能有1个或者没有
\+ 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
o至少出现一次
\{n\} 匹配前面的字符n次
o只能出现2次
\{m,n\} 匹配前面的字符至少m次,至多n次
o出现至少2次,最多5次
\{,n\} 匹配前面的字符至多n次,<=n
g出现的次数必须小于4次,包含0次
\{n,\} 匹配前面的字符至少n次
o出现2次以上
位置锚定
^ 行首锚定, 用于模式的最左侧
grep "^root$" 过滤出只有root的这一行
过滤出不是以“#”开头的
^$ 只取空行 grep "^[[:space:]]*$"
$ 行尾锚定,用于模式的最右侧
\< 或 \b 词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\> 或 \b 词尾锚定,用于单词模式的右侧
只能用于单词的匹配
sed
主要是对文件内容按照行的方式进行增删改查
工作流程
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,
称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,
把缓冲区的内容送往屏幕。
接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等
sed 流编辑器的工作过程
sed的工作流程主要包括读取、执行和显示三个过程:
读取: sed从输入流 (文件、管道、标准输入) 中读取一行内容并
存储到临时的缓冲区中(又称模式空间,pattern space )。
执行: 默认情况下,所有的sed命令都在模式空间中顺序地执行,除非指定了行的地址,
否则sed命令将会在所有的行上依次执行。
显示: 发送修改后的内容到输出流。在发送数据后,
模式空间将会被清空。在所有的文件内容都被处理完成之前,上述过程将重复执行,
直至所有内容被处理完。
在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的sed命令都是在模式空间内执行的,
因此输入的文件并不会发生任何变化,除非使用"sed -i"修改源文件、或使用重定向输出到新的文件中。
sed命令的常用选项
-e 或--expression=:表示用指定命令来处理输入的文本文件,只有一个操作命令时可省略,一般在执行多个操作命令使用
-f 或--file=:表示用指定的脚本文件来处理输入的文本文件。
-h 或--help:显示帮助。
-i 直接修改目标文本文件
-n 仅显示script处理后的结果
sed命令的操作符
s:替换,替换指定字符。ky27 kyy27
d:删除,删除选定的行。
a:增加,在当前行下面增加一行指定内容。
i:插入,在选定行上面插入一行指定内容。
c:替换,将选定行替换为指定内容。
y:字符转换,转换前后的字符长度必须相同。
p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以 ASCII 码输出。其通常与“-n”选项一起使用。
=:打印行号。
l(小写L):打印数据流中的文本和不可打印的ASCII字符(比如结束符$、制表符\t)
r:高级正则表达式
查找
按照行号寻址打印
sed有一个默认输出,加上P,会打印两遍,因此需要加上-n,禁止默认输出
删除空行的三种方法
grep -v "^$" test1.txt ----过滤出非空行
cat test1.txt |tr -s "\n" ----压缩换行符
sed '/^$/d' test1.txt ----删除空行
替换
s:替换字符串(替换内容长度可不一致)
c:整行替换
y:字符替换,替换前后的字符串长度必须相同
指定第二个root,替换为了test
把所有的root改成test
增加
a:在下一行添加内容
i:在上一行插入内容
r:在行后读入文件内容
在111这行下面插入three
awk
工作原理:
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理,
且默认情况下字段的分隔符为空格或 tab 键。
awk 执行结果可以通过 print 的功能将字段数据打印显示
awk的基本格式及其内置变量:
awk 选项 '模式或条件 {操作}' 文件1 文件2...
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-v(小v) var=value 变量赋值
注意一定是单引号:'模式或条件 {操作}'
{ }外指定条件,{ }内指定操作。
用逗号指定连续的行,用 || 指定不连续的行。&&表示”且“。
内建变量,不能用双引号括起来,不然系统会把它当成字符串。
内置变量
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
NR:当前处理的行的行号(序数)
NF:当前处理的行的字段个数。$NF代表最后一个字段
FS:列分割符。指定每行文本的字段分隔符,输入内容的分隔符,
默认为空格或制表位。与"-F"作用相同 用-F可以不加单引号 -F:,用FS必须用=""
OFS:输出内容的列分隔符
FILENAME:被处理的文件名
RS:行分隔符。awk从文件中读取资料时,
将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是"\n"
处理过程:
1、在awk处理指定的文本之前,需要先执行BEGIN{...}模式里的命令操作
2、中间的{...} 是真正用于处理文件的命令操作
3.在awk处理完文件后才会执行END{...}模式里的命令操作。END{ }语句块中,往往会放入打印结果等语句。
x的变量范围是根据文本中内容的行数来的
对字段进行处理打印
以:为分隔符,打印第一列
-v的用法:变量赋值
将输入的时候的分隔符:改成+输出,打印第一列和第三列
以:为分隔符,换行输出
#默认就是换行输出,不需要改
awk的精准筛选:
$n(> < ==): 用于对比数值
$n~"字符串": 代表第n个字段包含某个字符串
$n!~"字符串": 代表第n个字段不包含某个字符串
$n=="字符串": 代表第n个字段为某个字符串
$n!="字符串": 代表第n个字段不为某个字符串
$NF: 代表最后一个字段
输出第七个字段包含“bash”所在行的第一个字段和最后一个字段
输出第七个字段不包含“nologin”所在行的第一个字段和最后一个字段
输出第六个字段为/home/qiao,第七个字段为/bin/bash的这些行的第一列和最后一列
指定输出的分隔符
OFS:输出内容的列分隔符。($n=$n用于激活,否则不生效,n必须存在)
对于输出时改变分隔符,我们常用到tr,awk,它们都可以实现在输出内容改变原本的分隔符
输出时将分隔符改成:
数组
定义数组打印
awk中的数组形成遍历,在awk中打印变量不需要加$