python多进程实战——4k图片抓取
技术交流贴:不可用于违法违规用途
成果图:

背景:疫情宅家太无聊了,练习了一下爬虫,里面用到了伪装请求头、多进程、代理IP等技术

开始:
首先我们来分析一下网页,只要找到我们需要的清析度的图片真实网址,再模仿正常的访问就能拿到图片了
!

我们先来看看图片的链接有没有藏在html里面,经过验证这个是缩略图,在点开一张高清的看看

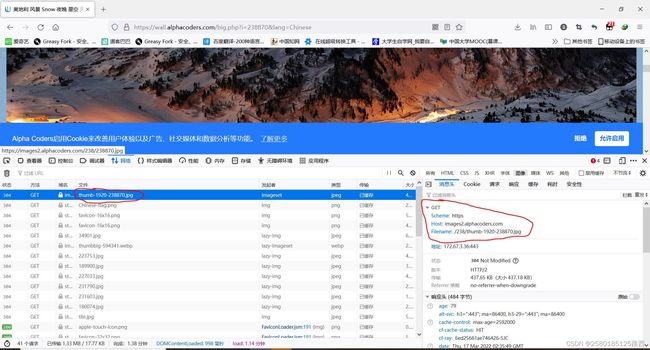
对比发现,高清的图和缩略的图网址很接近,所以我们可以通过筛选出缩略图的网址,然后拼接成高清图片网址
其实就是一个big和-1920的区别,我们通过批量操作字符串可以很容易实现,这样我们就得到了真实的网址.
接下来就是模拟请求了,我们来查看一下高清图片的请求头信息

经过测试,这个网站几乎没有什么反爬措施,简单伪装一下请求头就能拿到数据,我也尝试用异步爬虫,但是请求过快服务器就之间断开连接了
我之所以要用代理IP和多进程,是为了提升爬取速度,每一页有30张图片,他这个栏目下有一万多张图片呢,
代理IP获取方法过于简单,我就不讲了,直接在代码里体现
import requests
from bs4 import BeautifulSoup
import time
class Proiex:
def __init__(self,urls):
self.urls = urls
def get_ip(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Referer': 'http://www.ip3366.net/?page=1'}
priexy = []
for url in self.urls:
r = requests.get(url, headers=headers)
print('正在请求{}...{}'.format(url, r.status_code))
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'lxml')
tobdy = soup.select('.table > tbody:nth-child(2) > tr')
for tr in tobdy:
ip = {}
Str = tr.text.split('\n')
# print(Str)
pro = Str[2]
add = Str[1]
head = Str[4]
# if head == 'HTTP':
# ip = head + '://' + add + ':' + pro
ip[head] = head + '://' + add + ':' + pro
priexy.append(ip)
time.sleep(1)
return priexy
def get_good_ip(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Referer': 'http://www.ip3366.net/?page=1'}
Url = 'https://www.baidu.com'
priexy = self.get_ip()
good_ip = []
for IP in priexy:
try:
res = requests.get(Url, headers=headers, proxies=IP)
print('正在验证{}...'.format(IP))
if res.status_code == 200:
good_ip.append(IP)
else:
pass
except:
pass
return good_ip
def run(self):
good_ip = self.get_good_ip()
print('可用IP有{}个'.format(len(good_ip)))
with open('代理IP.txt', 'a+', encoding='utf-8') as file:
for ip in good_ip:
file.write(str(ip) + ',')
print('代理IP保存成功')
if __name__ == '__main__':
urls = ['http://www.ip3366.net/?page={}'.format(i) for i in range(10)]
pro = Proiex(urls)
pro.run()
最后,我把代码封装起来了
**
上完整代码
**
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
import time
import os
import random
class Spider:
'''
这是一个图片爬虫类,
目标地址是:https://wall.alphacoders.com/by_category.php?id=10&name=%E8%87%AA%E7%84%B6+%E5%A3%81%E7%BA%B8&lang=Chinese
爬取该分类页面下1920*1080的爬虫,可根据自己的需求爬取相应的页数
里面应用了伪装请求头、代理IP、多进程
最后封装成类
'''
# 定义构造函数
def __init__(self,start_page,end_page):
self.start_page = start_page
self.end_page = end_page
# 随机获取一个请求头
def get_headers(self):
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
# 新版移动ua
"Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
]
return {
'Referer': 'https://wall.alphacoders.com/by_category.php?id=10&name=%E8%87%AA%E7%84%B6+%E5%A3%81%E7%BA%B8&filter=4K+Ultra+HD&lang=Chinese',
'User-Agent': random.choice(user_agent),
# 'Host':'wall.alphacoders.com',
'Cookie': '_ga_HL65XQTV30=GS1.1.1647389732.1.1.1647391529.0; _ga=GA1.2.420384196.1647389733; _gid=GA1.2.698323620.1647389733; bfp_sn_rf_8b2087b102c9e3e5ffed1c1478ed8b78=Direct/External; bfp_sn_rt_8b2087b102c9e3e5ffed1c1478ed8b78=1647389744622; bafp=36b8b960-a4be-11ec-bfda-c9dda86621eb; __gads=ID=a88d3f8639452fd5-22504efc01d100bb:T=1647389743:S=ALNI_MZUA8rg6eS6ZHqexIHYatVptp7Rkg; trc_cookie_storage=taboola%2520global%253Auser-id%3D1d921eb9-1ade-445e-8797-ff6f04b4520d-tuct92ab1f4; cto_bundle=paAq4V9XbGZSODlEOUhoOVoyakUlMkJLY3dXVWJpazNuQUdLeHNJMUxaR3YzcTRMWUZDVmFZWG9MdE42YjN5T21COSUyQk5ybEx1Wjd6aEJRTTQ3SnZ1bFhyWEFHZm1pYTRCRm9heFdPaEVaJTJCeGRYJTJGU2hXVnJaNld2a3h1NU9QcXNFT0daOVFNUzBjcENwRzNkM1hkR0ZLcnVCUVloZyUzRCUzRA; bfp_sn_pl=1647389739|8_792043541195; session_depth=wall.alphacoders.com%3D8%7C881384258%3D16',
}
# 获取图片缩略图的url,后面处理它得到高清图的url
def get_src(self):
# 设置一个空列表,用于存放缩略图url
srcs = []
# page = 2
for i in range(self.start_page,self.end_page):
params = {
'scheme': 'https',
'host': 'wall.alphacoders.com',
'filename': '/by_category.php',
'id': '10',
'name': '自然 壁纸',
'filter': '4K Ultra HD',
'lang': 'Chinese',
'quickload': '11199',
'page': i,
}
headers = {
'Referer': 'https://wall.alphacoders.com/by_category.php?id=10&name=%E8%87%AA%E7%84%B6+%E5%A3%81%E7%BA%B8&filter=4K+Ultra+HD&lang=Chinese',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Host': 'wall.alphacoders.com',
'Cookie': '_ga_HL65XQTV30=GS1.1.1647389732.1.1.1647391529.0; _ga=GA1.2.420384196.1647389733; _gid=GA1.2.698323620.1647389733; bfp_sn_rf_8b2087b102c9e3e5ffed1c1478ed8b78=Direct/External; bfp_sn_rt_8b2087b102c9e3e5ffed1c1478ed8b78=1647389744622; bafp=36b8b960-a4be-11ec-bfda-c9dda86621eb; __gads=ID=a88d3f8639452fd5-22504efc01d100bb:T=1647389743:S=ALNI_MZUA8rg6eS6ZHqexIHYatVptp7Rkg; trc_cookie_storage=taboola%2520global%253Auser-id%3D1d921eb9-1ade-445e-8797-ff6f04b4520d-tuct92ab1f4; cto_bundle=paAq4V9XbGZSODlEOUhoOVoyakUlMkJLY3dXVWJpazNuQUdLeHNJMUxaR3YzcTRMWUZDVmFZWG9MdE42YjN5T21COSUyQk5ybEx1Wjd6aEJRTTQ3SnZ1bFhyWEFHZm1pYTRCRm9heFdPaEVaJTJCeGRYJTJGU2hXVnJaNld2a3h1NU9QcXNFT0daOVFNUzBjcENwRzNkM1hkR0ZLcnVCUVloZyUzRCUzRA; bfp_sn_pl=1647389739|8_792043541195; session_depth=wall.alphacoders.com%3D8%7C881384258%3D16',
}
url = 'https://wall.alphacoders.com/by_category.php?id=10&name=自然 壁纸&filter=4K Ultra HD&lang=Chinese&quickload=11199&page=' + str(
i)
print('开始请求第{}页'.format(i))
r = requests.get(url, headers=headers, data=params)
# print(r.status_code,r.text)
soup = BeautifulSoup(r.text, 'lxml')
img = soup.select('img.img-responsive')
for i in img:
src = i['src']
srcs.append(src)
time.sleep(1)
print('---------------------- 页面请求已完成 ----------------------')
return srcs
def url_chuli(self,srcs):
print('开始处理srcs')
urls = []
for src in srcs:
s = src.split('thumbbig')[0]
s1 = src.split('-')[1]
zhong = 'thumb-1920-'
url = s + zhong + s1
urls.append(url)
print('srcs处理已完成')
return urls
# 读入代理IP
def read_ip(self):
f = open('代理IP.txt', 'r', encoding='utf-8').read()
good_id = f.split(',')
num = len(f.split(','))
return good_id,num
def download(self,url):
filename = url.split('com')[1]
host = url.split('/')[2]
params = {
'scheme': 'https',
'host': host,
'filename': filename,
}
headers = self.get_headers()
params = {
'scheme': 'https',
'host': host,
'filename': filename,
}
good_id,num = self.read_ip()
pro = eval(good_id[random.randint(0, num-2)])
path = 'D:\\量化交易策略\\代码部分\\4k图片爬虫\\风景'
# 如果没有path文件夹,将生成path文件夹
if not os.path.exists(path):
os.mkdir(path)
res = requests.get(url, headers=headers, data=params, proxies=pro)
if res.status_code == 200:
with open(path + '\\' + '{}'.format(url.split('-')[-1]), 'wb') as file:
file.write(res.content)
print('{}下载成功'.format(url))
else:
print('下载失败,错误原因:{}'.format(res.status_code))
# 定义主函数,调用各个函数
def main(self):
Start_time = time.time()
pool = Pool(processes=6)
urls = self.url_chuli(self.get_src())
pool.map(self.download,urls)
End_time = time.time()
M = (End_time - Start_time) // 60
S = (End_time - Start_time) % 60
print('耗时{}分{:.2f}秒'.format(M, S))
class Proiex:
'''
这个类主要用来获取代理IP
目标地址是:http://www.ip3366.net/
这个网站没什么反爬,倒是很好获取,秉承着避免重复造轮子的思想将他封装成类
'''
def __init__(self,urls):
self.urls = urls
def get_ip(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Referer': 'http://www.ip3366.net/?page=1'}
priexy = []
for url in self.urls:
r = requests.get(url, headers=headers)
print('正在请求{}...{}'.format(url, r.status_code))
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'lxml')
tobdy = soup.select('.table > tbody:nth-child(2) > tr')
for tr in tobdy:
ip = {}
Str = tr.text.split('\n')
# print(Str)
pro = Str[2]
add = Str[1]
head = Str[4]
# if head == 'HTTP':
# ip = head + '://' + add + ':' + pro
ip[head] = head + '://' + add + ':' + pro
priexy.append(ip)
time.sleep(1)
return priexy
def get_good_ip(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Referer': 'http://www.ip3366.net/?page=1'}
Url = 'https://www.baidu.com'
priexy = self.get_ip()
good_ip = []
for IP in priexy:
try:
res = requests.get(Url, headers=headers, proxies=IP)
print('正在验证{}...'.format(IP))
if res.status_code == 200:
good_ip.append(IP)
else:
pass
except:
pass
return good_ip
def run(self):
good_ip = self.get_good_ip()
print('可用IP有{}个'.format(len(good_ip)))
with open('代理IP.txt', 'a+', encoding='utf-8') as file:
for ip in good_ip:
file.write(str(ip) + ',')
print('代理IP保存成功')
if __name__ == '__main__':
'''
代理IP类在第一次使用之后就可以注释掉了,不然每次运行都要先爬取一下代理网站,会造成资源的浪费
'''
# # 获取代理IP的前5页,得到可用的IP,并保存在本地,因为使用的是追加写,每次执行前,需要把’代理IP.txt‘清空
# urls = ['http://www.ip3366.net/?page={}'.format(i) for i in range(5)]
# pro = Proiex(urls)
# pro.run()
# Spider(起始页,结束页)
start = int(input('请输入需要下载的起始页:'))
end = int(input('请输入需要下载的结束页:'))
spider = Spider(start,end)
spider.main()
用了多进程,效率提升不是一点点啊
感谢阅读,下次再见