kafka生产者和消费者的分区分配策略
引言
我们都知道在kafka中producer向topic推送消息,而consumer是主动去拉取消息。而在topic中存在着分区和分片,那么kafka生产者和消费者应该采用什么样的分区分配策略呢
目录
-
- 一、producer的分区分配策略
- 二、consumer的分区分配策略
- 附加
一、producer的分区分配策略
我们向topic发送消息的时候是要把messages封装成一个ProducerRecord对象的,源码如下:

(1)可以看到后面4种是需要我们自己指定分区的,所以可以直接将消息发送到指定分区
(2)第二行需要我们指定一个key,这种是将key的hash值与topic的partition数求余得到分区值,是不知道会发往哪一个分区的
(3)而第一行是你既没有指定partition又没有指定key的值,第一次调用时会随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic的 partition数取余得到partition值,也就是常说的 round-robin 算法,这也是默认的分区分配策略,能够保证负载均衡
这里我只测试一下常见的第3种分区分配策略:
1、我们先创建一个有3个分区的topic

2、我们向这个topic发送8条消息

3、那么如果我们只启动一个consumer,是不是这3个分区都只能它一个人来消费,因为kafka每一个分区内的数据是顺序的,同时这一个消费者是一个分区一个分区里面的数据来消费(如果你消费了第一个分区的一条数据又去消费第二个分区的一条数据这样IO是不是很大),那么按照轮训的策略,是不是一个分区的数据是1、4、7,一个分区的数据是2、5、8,还有一个分区的数据是3、6。那么如果它是轮训的,先消费哪一个分区的数据不重要,但是147和258和36肯定是一起消费的。
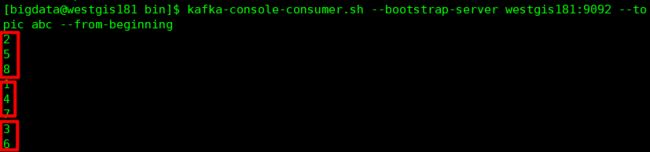
结果是不是完全符合我们的猜想
二、consumer的分区分配策略
我们都知道consumer是以consumer group的名义订阅topic,而topic中有多个partition,consumer group中又有多个consumer,那么consumer和partition之前的对应关系又是怎样的呢?
换句话说,就是同一个consumer group中的每一个consumer应该负责哪些分区,这个分配关系又是如何确定的呢?
我们都知道一个partition只能被一个consumer消费,这能保证不重复消费消息和顺序消费分区里面的数据
可以看到org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor这个类默认有3种实现方式,如果要自定义分配策略的话,只需要继承AbstractPartitionAssignor这个类

1、Range策略
range策略对应的实现类org.apache.kafka.clients.consumer.RangeAssignor
,同时这是默认的分配策略可以通过consumer配置partition.assignment.strategy参数来指定分配策略,它的值是类的全路径,是一个数组
官方解释如下:
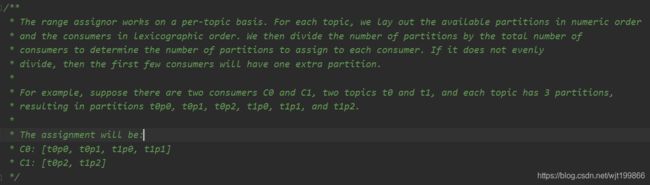
意思就是一个group中的两个consumer同时订阅了两个topic,这两个topic都有3个分区,其他一个consumer被分配到了t0p0, t0p1, t1p0, t1p1,另一个consumer被分配到了t0p2, t1p2,那么为什么会这样分配呢?
这是因为range策略是基于主题进行划分分区的
对于每个主题,我们以数字顺序排列可用分区,以字典顺序排列消费者。然后,将分区数量除以消费者总数,以确定分配给每个消费者的分区数量。如果没有平均划分(有余数),那么最初的几个消费者将有一个额外的分区。
简而言之,就是:
1、range分配策略针对的是主题(也就是说,这里所说的分区指的某个主题的分区,消费者指的是订阅这个主题的消费者组中的所有消费者)
2、首先,将分区按数字顺序排行序,消费者按消费者名称的字典序排好序,然后,用分区总数除以消费者总数。如果能够除尽,则皆大欢喜,平均分配
3、若除不尽,则位于排序前面的消费者将多负责一个分区
2、RoundRobin(轮询)策略
roundronbin分配策略的具体实现是org.apache.kafka.clients.consumer.RoundRobinAssignor
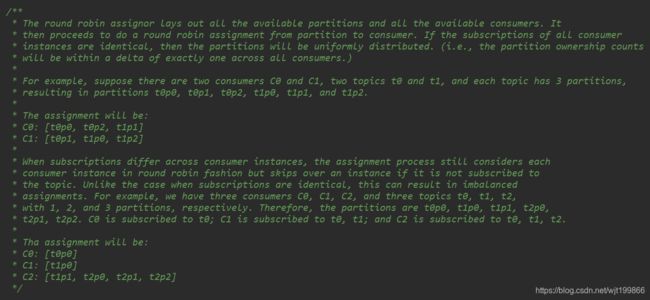
意思就是一个group中的两个consumer同时订阅了两个topic,这三个topic都有3个分区,其中一个consumer被分配到了t0p0, t0p2, t1p1,另一个consumer被分配到了t0p1, t1p0, t1p2,那么为什么会这样分配呢?
这是因为轮询分配策略是基于所有可用的消费者和所有可用的分区的,与前面的range策略最大的不同就是它不再局限于某个主题,如果所有的消费者实例的订阅都是相同的,那么这样最好了,可用统一分配,均衡分配
假设,组中每个消费者订阅的主题不一样,分配过程仍然以轮询的方式考虑每个消费者实例,但是如果没有订阅主题,则跳过实例。当然,这样的话分配肯定不均衡。
什么意思呢?也就是说,消费者组是一个逻辑概念,同组意味着同一时刻分区只能被一个消费者实例消费,换句话说,同组意味着一个分区只能分配给组中的一个消费者。事实上,同组也可以不同订阅,这就是说虽然属于同一个组,但是它们订阅的主题可以是不一样的。
根据上面的文档我们是不是还看到一种情况:有3个主题t0、t1、t2,有3个消费者c0、c1、c2。然而c0只订阅到t0,c1订阅t0、 t1,c2订阅t0、t1、t2。其中t0有1个分区p0,t1有2个分区p0、p1,t2有3个分区p0、p1、p2,最后c1消费t0p0,c2消费t1p0,c3消费t1p1、 t2p0、t2p1,、t2p2,那为什么会这样呢?
首先,肯定是轮询的方式,t0p0只在c0中轮询,t1p0、t1p2在c1、c2中轮询,t2p0、t2p1、t2p2只在c2中轮询,结果是不是就是上面的结果
其实这种情况下是不是跟range分配的结果是一样的
3、StickyAssignor策略
我们再来看一下StickyAssignor策略,“sticky”这个单词可以翻译为“粘性的”,Kafka从0.11.x版本开始引入这种分配策略
它主要有两个目的:
分区的分配要尽可能的均匀;
分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。
鉴于这两个目标,StickyAssignor策略的具体实现要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。
我们举例来看一下StickyAssignor策略的实际效果。
假设消费组内有3个消费者:C0、C1和C2,它们都订阅了4个主题:t0、t1、t2、t3,并且每个主题有2个分区,也就是说整个消费组订阅了t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1这8个分区。最终的分配结果如下:
消费者C0:t0p0、t1p1、t3p0
消费者C1:t0p1、t2p0、t3p1
消费者C2:t1p0、t2p1
是不是看上去和采用RoundRobinAssignor策略所分配的结果相同,但事实是否真的如此呢?再假设此时消费者C1脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采用RoundRobinAssignor策略,那么此时的分配结果如下:
消费者C0:t0p0、t1p0、t2p0、t3p0
消费者C2:t0p1、t1p1、t2p1、t3p1
而如果此时使用的是StickyAssignor策略,那么分配结果为:
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
可以看到分配结果中保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1的“负担”分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。StickyAssignor策略如同其名称中的“sticky”一样,让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗以及其它异常情况的发生。
我们再来看看consumer group中consumer订阅不同的topic的情况
举例,消费组内有3个消费者:C0、C1和C2,集群中有3个主题:t0、t1和t2,这3个主题分别有1、2、3个分区,也就是说集群中有t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区。消费者C0订阅了主题t0,消费者C1订阅了主题t0和t1,消费者C2订阅了主题t0、t1和t2。
如果此时采用RoundRobinAssignor策略,那么最终的分配结果如下所示:
消费者C0:t0p0
消费者C1:t1p0
消费者C2:t1p1、t2p0、t2p1、t2p2
如果此时采用的是StickyAssignor策略,那么最终的分配结果为:
消费者C0:t0p0
消费者C1:t1p0、t1p1
消费者C2:t2p0、t2p1、t2p2
是不是比RoundRobinAssignor策略更合理
假如此时消费者C0脱离了消费组,那么分配结果为:
消费者C1:t1p0、t1p1、t0p0
消费者C2:t2p0、t2p1、t2p2
可以看到StickyAssignor策略保留了消费者C1和C2中原有的5个分区的分配:t1p0、t1p1、t2p0、t2p1、t2p2。
从结果上看StickyAssignor策略比另外两者分配策略而言显得更加的优异,这个策略的代码实现也是异常复杂。
附加
如果一个组的消费者的数量大于订阅的topic分区的数量呢,又该怎么分配分区呢?比如有一个topic有两个分区,两个消费者订阅了这个这个topic,那么肯定是一个消费者消费一个分区,如果这个时候又增加了一个消费者,那么这个消费者一定就会分不到分区消费数据吗?我们可以来看一下
1、我们创建一个有两个分区的topic

2、开启一个生产者和两个消费者
这里我们需要制定consumer的配置文件,要不然每次启动一个消费者都会随机生成一个groupid
生产者发送5条数据:

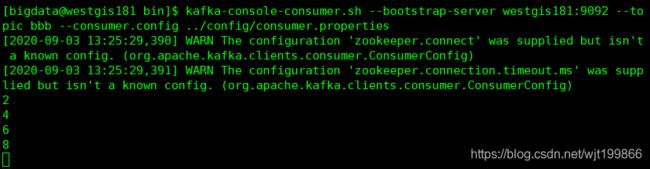
消费者1消费到了第2,4条数据
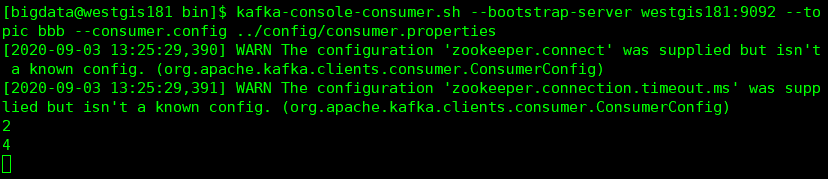
消费者2消费到了第1,3,5条数据(注意:消费者不管你是不是在其他机器上面启动,只要是新开了一个窗口他们就都是属于新的消费者)
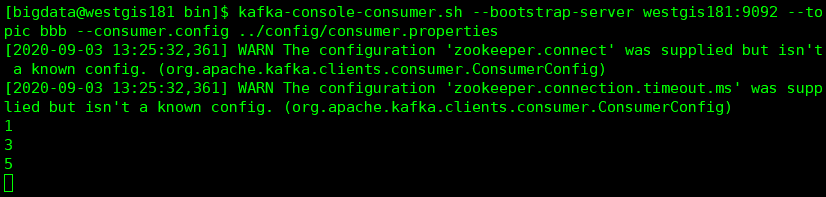
可以看到消息是轮询发往每个分区的
3、接着新开一个窗口,启动消费者3。这时候生产者向topic发送数据6,7,8,9
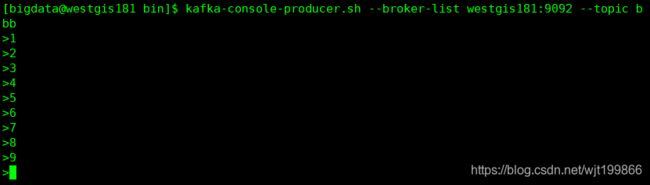
这时候可以看到consumer3消费到了第7,9条数据
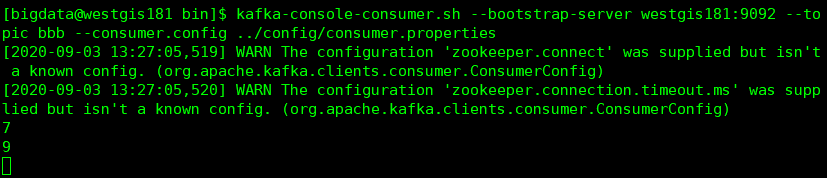
消费者1消费到了第6,8条数据,而consumer2消费不到数据了
总结
每次新加入consumer,都会触发consumer的分区分配策略