spacy 用已经token化,分词的list 列表作为输入
2022/1/11更新 针对新版3.0处理
import spacy
nlp = spacy.load('en_core_web_sm')
from spacy.tokens import Doc
doc = Doc(nlp.vocab, words=['Conceptually', 'cream', 'skimming', 'has', 'two', 'basic', 'dimensions', '-', 'product', 'and', 'geography', '.'])
# Tagger(doc)
for name,tool in nlp.pipeline:
tool(doc)
for t in doc:
print(t.text, t.pos_, t.tag_, t.dep_ ,t.head,t.ent_type_)网上都是一些抄来抄去的spacy用法,一些特殊问题的处理方法都找不到,哎,只能老老实实啃官网文档EntityRecognizer · spaCy API Documentation,先直接上方法和结果。
import spacy
from spacy.tokens import Doc
nlp = spacy.load('en_core_web_sm')
doc = Doc(nlp.vocab, words=['Conceptually', 'cream', 'skimming', 'has', 'two', 'basic', 'dimensions', '-', 'product', 'and', 'geography', '.'])
nlp.tagger(doc)#词性
nlp.parser(doc)#依存
for t in doc:
print(t.text, t.pos_, t.tag_, t.dep_, t.head)其中spaces参数:可迭代布尔值列表,指示每个单词是否有后续空格。如果指定的话,该spaces列表长度必须与单词具有相同的长度。默认为True的序列。
如: I've => ["I","'ve"] => [False,False]
["hello", "world", "!"] => [True, False, False]
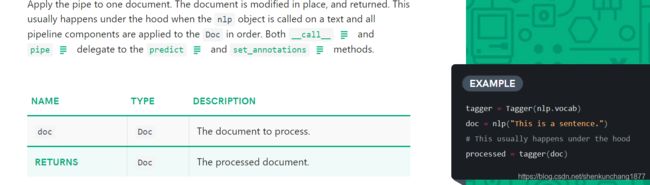
DOC的参数说明:
| NAME | TYPE | DESCRIPTION |
|---|---|---|
vocab |
Vocab |
A storage container for lexical types. |
words |
iterable | A list of strings to add to the container. |
spaces |
iterable | A list of boolean values indicating whether each word has a subsequent space. Must have the same length as words, if specified. Defaults to a sequence of True. |
| RETURNS | Doc |
The newly constructed object. |

spacy原本是读取一段文本作为输入,如果想输入一段已经分词好的列表作为输入的话,参考官网的教程。但是如果只看了第一步的朋友会发现,以下这样可以得到dep和pos关系。但是如果按照第二种输入列表的方式再按照第一种方法去获取dep和pos则无法得到结果。
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("The new rights are nice enough")
print(len(doc))
print([token.text for token in doc])
print([token.pos_ for token in doc])
print([token.dep_ for token in doc])第二种:无法得到pos和dep
import spacy
from spacy.tokens import Doc
nlp = spacy.load('en_core_web_sm')
doc = Doc(nlp.vocab, words=['Conceptually', 'cream', 'skimming', 'has', 'two', 'basic', 'dimensions', '-', 'product', 'and', 'geography', '.'])
print([token.text for token in doc])
print([token.pos_ for token in doc])
print([token.dep_ for token in doc])
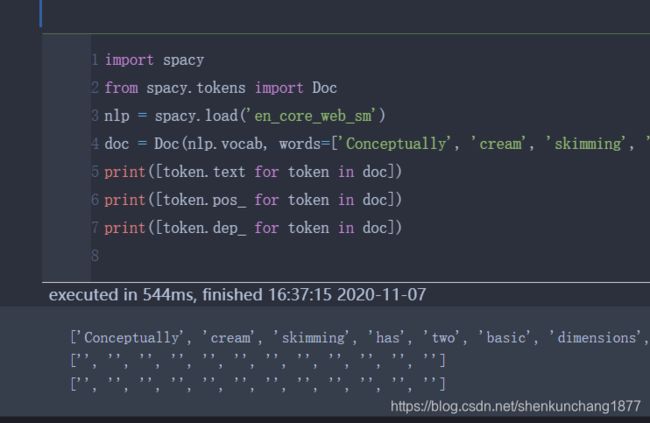
参考官网,doc需要用对应的处理tagger进行处理才能获得对应的标签。dep 依存关系同理 参考:Tagger · spaCy API Documentation