python | 写一个简单的缓存系统
今天来做一个最简单的例子,写一个最简单的缓存系统,要求:
以key``value的方式保持数据,并且需要将内容中的数据落地到文件,以便下次启动的时候,将文件的内容加载进内存中来。
还是需要声明一点,本篇文章所依赖的
python环境为:

项目展示
该demo将分为2个部分展示,第一个部分我们会写入一些key和value进入到缓存系统中,而后关闭程序。
第二部分则会去获取第一个部分写入的key的名称。
第一部分main方法如下:

其中,dbCache是我们定义的类,而set是写入方法,cacheSetting设置一些基础环境变量,例如:
queueMaxKeys: 需要制定增删改缓存队列,类型为int,如果满了,则立即落地到磁盘中。ageSec: 间隔时间,参数为秒数,若操作第一个key和操作第二个key时间大于该设置,则落地到磁盘。
set则是写入方法,参数为key和value。
运行后,代码效果如下:

由于我们只有set,所以不会输出任何信息,上述open file error 是正常的警告信息,不用管它。
第一部分操作完毕了,我们可以修改第二部分,使用get去获取第一次存储的数据。
修改main如下:
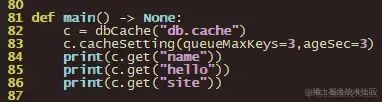
运行后,效果如下:
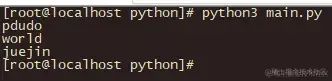
由此可以验证,从磁盘读取文件并且加载进内存,没什么问题。
除此之外,该库还支持其他操作,例如:
# 定义一个缓存对象
c = dbCache("db.cache")
# 配置环境变量
c.cacheSetting(queueMaxKeys=3,ageSec=3)
# 写
c.set("name","pdudo")
# 读
print(c.get("name"))
# 修改
c.update("name", "juejin")
# 删除
c.delete("name")
接下来,我们就来看下,如何一步一步完成这个最简单的缓存系统。
不用落地的缓存系统系统应该如何实现
在python中,给我们提供了很多基础的数据类型,例如 列表、字典等。所以说,就没必要自己在定义一套属于自己的数据类型了,可以直接使用现有的数据类型,例如本篇文章所使用的就是字典,这里简单的铺垫一下字典的增删改查。
铺垫python字典基本操作
定义一个空的字典a,可以使用如下代码:
a = {}
写入key可以直接使用a[key] = value即可,例如:
a["name"] = "pdudo"
修改也是和上述一样的
关于查询,我们直接使用a[key]即可。
若没有这个key会抛错: KeyError: 'key'。
print(a["name"])
检查是否存在key,可以使用key in dict来判断,例如: 想判断name是否是字典a中的key,可以写为:
print("name" in a)
若存在于a中,会返回True,否则会返回False。
定义一个不用落地的缓存系统
有了上述关于字典的基本操作,我们可以将其封装一下,定义为自己的操作方法,例如:
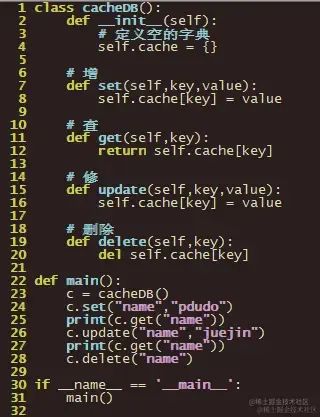
我们可以将上述方法,封装在一个class中,从而实现调用。
例如,运行之后结果为:

数据如何落地
上述,我们已经写了一个最简单的缓存系统,如果此时进程挂掉了,重新启动后,内存中的数据就都没了,所以为了避免重启后数据丢失,可以将数据定时落地到磁盘中,本篇文章所介绍的内置库为: pickle,该可可以将python对象存储到文件中,从而保存到磁盘,这个对象可以是字典、也可以是列表,我们来看下,具体方法:
将对象保存到磁盘
使用pickle的dump方法,可以将对象保持到文件中,这里举一个很简单的例子:
import pickle
list1 = ["name","juejin","hello"]
with open("test.txt","wb") as f:
pickle.dump(list1,f)
上述代码,先引入了pickle库,而后定义了列表list1,最后打开文件,使用pickle.dump将列表对象保持到文件中,这里保存的是二进制,所以是wb模式。使用with...open方法,它可以主动在最后帮我们关闭文件句柄。
此时如我们执行脚本后,想查看一下文件,会发现是二进制格式的,例如:

将对象从磁盘中导入到内存中
上述,我们已经将对象保持到磁盘中,接下来,我们使用pickle的load方法,将磁盘数据导入到内存中来,这里同样举一个很简答的例子:
import pickle
with open("test.txt","rb") as f:
list2 = pickle.load(f)
print(list2)
上述代码,还是先引入pickle库,而后在以二进制的模式读取文件,最后通过pickle.load方法,将数据从磁盘中导入到list2下,接着输出list2的值。
运行后,可以发现,该值就是我们上述落地到磁盘的对象:

将数据落地和缓存系统结合起来
我们已经将数据落地测试完毕了,如何和缓存系统结合起来呢? 很简单,我们仅需要在程序启动时,检测一下是否有该文件,若有,则直接读取数据再并入到对象中,否则创建一个新的字典就好。
而后每次有增删改操作,都将数据落地即可,这里用新增数据函数举个例子:
class cacheDB():
def __init__(self):
try:
with open("db.cache","rb") as f:
self.cache = pickle.load(f)
except Exception as e:
self.cache = {}
def set(self,key,value):
self.cache[key] = value
with open("db.cache","wb") as f:
pickle.dump(self.cache,f)
上述在cacheDB的__init__ 函数中,就尝试读取本地文件db.cache,若存在,就load到内存中,若不存在,就创建一个新的字典。
这样的话,存储的数据就不会因为程序重启而丢失了。
如何保证并发安全
作为一个服务对开提供访问时,需要注意一下并发安全,当多个函数对一个变量进行操作的时候,很容易引起数据混乱,所以还是有必要加一下锁的,我们可以引入threading库来完成加锁解锁操作,其加锁和解锁代码如下:
import threading
lock = threading.Lock # 定义lock
lock.acquire() # 加锁
lock.release() # 释放锁
我们可以将次引入到代码中,例如:
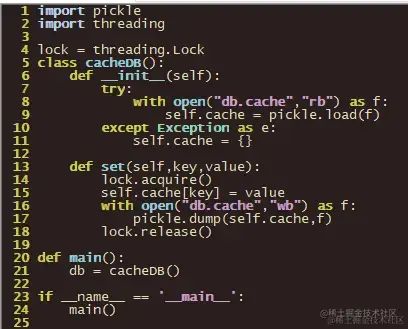
这里就不做演示了。
总结
本篇文章,介绍如何写一个最简单的缓存系统,其核心点是定义了一个字典类型来保存key/value数据,并且根据相应的逻辑,使用pickle的load方法保持到本地磁盘中,而后需要加载的时候再从本地文件加载到内容中即可,最后作为一个服务,应当考虑到并发安全的问题,给增删改方法加一个锁,从而避免并发问题。最后的最后,再将功能重复代码给踢出来,稍微润色一下,就差不多可以了。
Python 的迅速崛起对整个行业来说都是极其有利的 ,但“人红是非多”,导致它平添了许许多多的批评,不过依旧挡不住它火爆的发展势头。
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取
点击这里

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


5️⃣Python兼职渠道
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。

上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方二维码免费领取
