如何用(Python)网页请求的方式接入星火认知大模型API
1.得到他的服务(产品)
在这个平台获取其API服务
讯飞开放平台-以语音交互为核心的人工智能开放平台
2.创建一个专门做这类工作的Python的虚拟环境
例如:我在这个地方创建了一个专门的文件夹
E:\Python\Spark

在文件夹地址栏输入cmd,进入命令行
在命令行输入:
Virtualenv --python=python3.8 venv
注意:Virtualenv是一个专门管理Python虚拟环境的第三方库,没有安装这个库的同学需要先自行安装。
--python=python3.8 是指定Python的版本,可以不指定,用默认版本就可以了,这条命令适用于安装了多个Python版本的同学使用。
venv 是在当前文件夹再创建一个名为“venv”的文件夹,把虚拟环境放入该文件中。
然后就创建好了专门的干净的虚拟环境了
注意:用Web的方式接入API还需要安装这个第三方库:
pip install websocket-client

3.获取讯飞的星火API模块,可以直接从讯飞星火官网下载
星火认知大模型Web文档 | 讯飞开放平台文档中心
我这里直接展示其内容:
import _thread as thread
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
import ssl
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
import websocket # 使用websocket_client
answer = ""
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, Spark_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(Spark_url).netloc
self.path = urlparse(Spark_url).path
self.Spark_url = Spark_url
# 生成url
def create_url(self):
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": self.host
}
# 拼接鉴权参数,生成url
url = self.Spark_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws,one,two):
print(" ")
# 收到websocket连接建立的处理
def on_open(ws):
thread.start_new_thread(run, (ws,))
def run(ws, *args):
data = json.dumps(gen_params(appid=ws.appid, domain= ws.domain,question=ws.question))
ws.send(data)
# 收到websocket消息的处理
def on_message(ws, message):
# print(message)
data = json.loads(message)
code = data['header']['code']
if code != 0:
print(f'请求错误: {code}, {data}')
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
print(content,end ="")
global answer
answer += content
# print(1)
if status == 2:
ws.close()
def gen_params(appid, domain,question):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"random_threshold": 0.5,
"max_tokens": 2048,
"auditing": "default"
}
},
"payload": {
"message": {
"text": question
}
}
}
return data
def main(appid, api_key, api_secret, Spark_url,domain, question):
# print("星火:")
wsParam = Ws_Param(appid, api_key, api_secret, Spark_url)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open)
ws.appid = appid
ws.question = question
ws.domain = domain
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
4.获取讯飞的星火API的Demo模块,可以直接从讯飞星火官网下载
星火认知大模型Web文档 | 讯飞开放平台文档中心
我这里直接展示其内容:
import SparkApi
# 以下密钥信息从控制台获取
appid = "你自己的appid" # 填写控制台中获取的 APPID 信息
api_secret = "你自己的api secret" # 填写控制台中获取的 APISecret 信息
api_key = "你自己的api key" # 填写控制台中获取的 APIKey 信息
# 用于配置大模型版本,默认“general/generalv2”
domain = "general" # v1.5版本
# domain = "generalv2" # v2.0版本
# 喜欢用哪个版本就调用哪个版本
# 云端环境的服务地址
Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址
# Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址
# 使用对应版本的对应环境地址
text =[]
# 就是对话历史(内容),包括用户对话和AI的回答,最大存储上线是8000字,超出会截断。
# length = 0
# 后续处理对话历史的长度,实现一定的上下文状态管理
def getText(role, content):
jsoncon = {}
# 星火认知大模型使用JSON格式来存储对话历史
jsoncon["role"] = role
# 内容的键名是role,键名的内容是user或者assistant
jsoncon["content"] = content
# 键值的内容是 用户的提问 或者 AI的回答
text.append(jsoncon)
# 程序会把这个JSON数据存储到text中,最大存储上线是8000字,超出会截断。
# print(f'jsoncon: {jsoncon}')
# print(f'jsoncon["role"]: {jsoncon["role"]}')
# print(f'jsoncon["content"] {jsoncon["content"]}')
# print(f'text: {text}')
return text
def getlength(text):
# 用于计算历史对话的长度
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
# print(f'length: {length}')
return length
def checklen(text):
# 检查历史对话的长度,避免长度大于8000字符,因为不同的套餐的最大字符不同。这里用的是8000
while (getlength(text) > 8000):
del text[0]
return text
if __name__ == '__main__':
text.clear()
# 确保text是空值,是一个新的对话,新的开始。
while True:
Input = input("\n" +"我:")
if Input == "退出":
print("对话结束。")
break # 用户输入"退出"时跳出循环
question = checklen(getText("user", Input))
SparkApi.answer = ""
print("星火:", end="")
SparkApi.main(appid, api_key, api_secret, Spark_url, domain, question)
getText("assistant", SparkApi.answer)
# print(str(text))
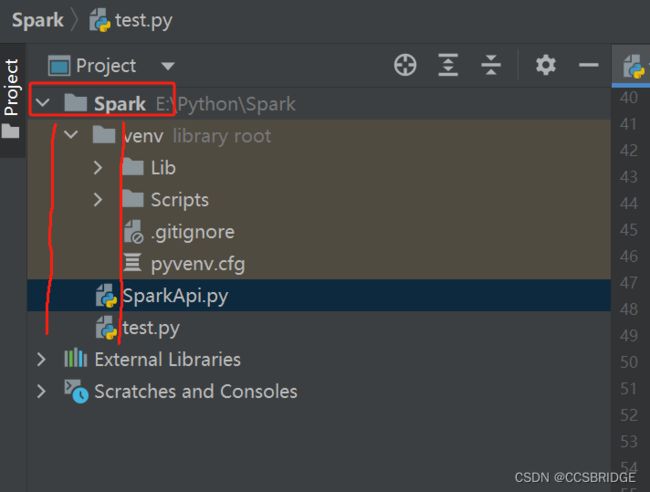
5.确认Python脚本文件的结构如下:

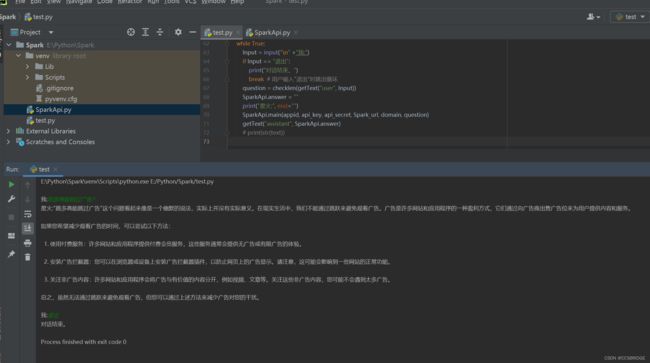
6.运行Demo脚本: