ImageReward:文本到图像生成中的人类偏好学习

ImageReward和ReFL的概览。(上)ImageReward的标注和训练,包括数据收集、标注和偏好学习。(下)ReFL利用ImageReward的反馈直接优化后随机去噪步骤的扩散模型
ImageReward解决方案由以下几个步骤组成:
-
专业的大规模数据集ImageRewardDB:约13.7万个⽐较pairs,完全开源。
-
通⽤的反映⼈类对于⽂本到图像偏好的模型ImageReward:文生图奖励模型之先锋,优于现有的⽂本-图像评分⽅法,例如CLIP、Aesthetic和BLIP;也是新的文生图自动评价指标。
-
借助ImageReward的直接优化⽅法ReFL:用人类偏好改进扩散生成模型。
具体的方法介绍在下文展开。
1. 为什么文生图也需要RLHF?
文生图存在什么痛点问题?
⽂本到图像⽣成模型,包括⾃回归(主要是一系列基于Transformer架构的模型例如DALLE、CogView、Parti等)和基于扩散(基于Diffusion架构的模型例如DALLE-2、Stable Diffusion等)的⽅法,近年来取得了快速发展。给定一个适当的⽂本描述(即prompt),这些模型便可以在⼴泛的主题上⽣成相应的⾼质量图像,引起了公众对其潜在应⽤和影响的广泛关注。

尽管取得了一定的进展,但现有的⾃监督预训练图像⽣成模型还远⾮完美,⽣成的图像中存在一系列被广泛反映的问题,包括但不限于:
-
图文一致性:生成的图像未能准确描述所有的数字、属性和⽂字提⽰中描述的对象关系。(例如上图中的a, b,“小女孩被地上的向日葵挡住去路”以及“太阳神加冕”)
-
肢体问题:生成的图像呈现了扭曲、不完整、重复或者异常的肢体部位(例如:四肢等),这一问题在人类或动物中均可能出现。(例如上图中的e和f)
-
审美问题:生成的图像偏离⼈类对审美⻛格的平均或主流偏好。(例如上图中的c和d)
-
有害与偏⻅内容:生成的图像具有有害、暴⼒、性相关、存在歧视、⾮法或引起⼼理不适的内容。(例如上图中的e和f)
然⽽,这些普遍存在的挑战很难仅通过改进模型架构和预训练数据来解决。
2. LLM中的RLHF回顾
在自然语言处理中,研究⼈员利⽤基于⼈类反馈的强化学习 (RLHF: Reinforcement Learning from Human Feedback) 来指导⼤型语⾔模型接近⼈类的偏好和价值观。该⽅法依赖于训练一个奖励模型 (RM),该奖励模型能通过大量对不同模型输出的专业标注来捕获⼈类偏好。虽然这一方法非常有效,但是标注的过程可能花费非常⾼昂的成本,且具有较大的挑战性,因为它需要通过数⽉的努⼒来建⽴标注标准、招募和培训标注专家、验证标注结果并最终训练生成RM。
2.1 为什么RLHF有希望解决文生图现在的问题?
文生图现存问题很大程度上受限于预训练数据的质量:预训练的数据分布嘈杂,而且与实际的⽤⼾prompt数据的分布不同。
RM (reward model):为人类偏好建模。
RM as metric:当前文生图并没有令人满意的自动评测指标(FID和CLIPScore各有问题),RM为引入人类偏好进行评价成为可能。更好的评价体系决定更好的发展,引导解决当前痛点。
RLHF:借助RM促使模型与⼈类的偏好分布趋向⼀致。
3. ImageRewardDB:人类偏好的数据集构建
-
prompt采样和生成图像收集。我们的数据集使用了来⾃开源数据集DiffusionDB的真实⽤⼾提⽰。为了确保所选提⽰的多样性,我们采⽤了⼀种基于图的算法,该算法利⽤基于语⾔模型的文本相似性。通过这一方法我们选择产⽣了
10,000个候选prompt,每个提⽰都伴随着来⾃ DiffusionDB 的4到9个样本图像,从⽽产⽣了177,304个⽤于标记的候选对。 -
人工标注设计:prompt标注(对promp进⾏分类;指出promp中存在的问题);图片rating(对图像根据文本-图像一致性、图像质量和⽆害性进⾏评价);图片ranking:按偏好顺序对图像进⾏排名。
-
人工标注分析。经过2个⽉的标注,我们收集了对
8,878个prompt的有效标注,产⽣了136,892个⽐较对。原论文的附录中对标注数据进行了详尽的分析。
4 ImageReward:人类偏好预测模型
4.1 训练过程
模型结构:BLIP(ViT-L作为图像编码器的,12层Transformer作为文本编码器)+ MLP(打分器)
训练方法:对于同一个prompt对应的k张图片,根据其排序结果得到pairs,每个pair中有相对更受偏好和不受偏好的两张图片。ImageReward训练所用的目标函数如下,其中T表示prompt,x表示生成的图片。

训练技巧:
-
训练时,BLIP的参数全都固定或者全都不固定都不能达到满意的准确率;事实上,我们发现固定70%的Transformer层是最有效的;
-
训练对超参数很敏感,我们通过搜索超参数发现1e-5的学习率和64的batch大小最合适。
4.2 模型性能
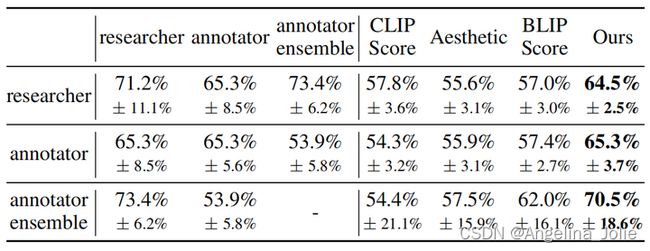
人类偏好的一致性分析。在大多数情况下,人们会就哪个图像更好达成一致。然而,考虑到模型生成的一些图像之间可能各有优缺点,在某些情况下,不同的人认为更好的图像可能是不同的。在测量模型的性能之前,我们首先需要测量人们在选择更好的图像方面达成一致的可能性。我们使用其他40个prompt(778个pairs)来计算不同标注者和研究人员之间的偏好一致性(agreement)。如上表所示,标注员相互之间的agreement均值为65.3%;而我们的模型达到了这样的agreement,远超过其他模型。
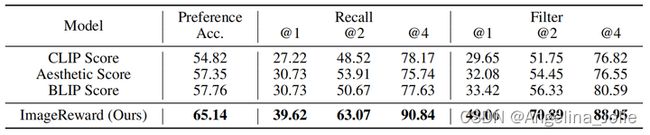
偏好准确率。模型预测人类偏好的准确率,计算方式是对于两个不同的图片,模型是否和人对于图片优劣的判断一致。在测试集上,ImageReward的偏好准确率达到65.14%(和人与人之间的agreement差不多大),比50%(随机)高出15.14%,约为7.76%(BLIP Score)的两倍。

人类评测。为了评估ImageReward在大量生成的图片中选出最受人类偏好图片的能力,我们构建了另一个数据集,从DiffusionDB中收集同一个prompt下对应的9/25/64张生成图片,并使用包括ImageReward在内的不同方法从这些图片中分别选择top3的结果。标注者对这些top3图片进行排序,上图显示了ImageReward的胜率。ImageReward可以选择与文本更对齐、保真度更高的图像,并避免有毒内容。
5 ImageReward作为自动评测指标
训练文本到图像的生成模型是困难的,但合理地评估这些模型则更难。
目前,FID和CLIP Score是两种流行的评估方法。
FID(fine-tune或者zero-shot):使用MS-COCO image caption数据集,文本到图像生成模型与真实图像进行评估。
CLIP Score:使用CLIP来衡量模型生成的图片和文本之间的匹配度。
FID存在以下几个问题:
-
零样本使用:由于生成模型现在主要被公众以没有微调的零样本方式使用,微调后的FID可能不会真实地反映模型在实际使用中的实际性能。此外,尽管在最近的流行做法中采用了零样本FID,一些模型的预训练数据中MS-COCO的可能泄漏将使其成为一个潜在的不公平设置。
-
人类偏好:FID衡量生成的图像和参考真实图像之间的平均距离,因此在评估中未能包含对文本到图像合成至关重要的人类偏好。此外,FID依赖于整个数据集的平均值来提供准确的评估,而在许多情况下,我们需要该指标作为单个图像的选择器。
看到这些挑战,本文提出ImageReward作为一个有效的零样本自动评估指标,用于文本到图像的模型比较和图片选择。

与人类偏好更加符合的模型评测指标。研究人员对6个流行的高分辨率(约512 × 512)可用的文本到图像模型进行了评测:CogView 2、Versatile Diffusion (VD)、Stable Diffusion (SD) 1.4和2.1、DALL-E 2(通过OpenAI API)和Openjourney。测试所用的100个prompt从真实用户使用prompt中采样得到,每个模型根据每个prompt生成10个图片作为候选。为了比较这些模型,我们首先从每个模型对每个prompt的10个输出中选择最佳的图像。然后,标注员根据ImageRewardDB中描述的排序规则,对每个prompt下来自不同模型的图像进行排序。每个模型对所有其他模型的最终获胜计数见上表。如表所示:ImageReward与人类排名很一致,而零样本的FID和CLIP则不一致。

更好的区分度。另一个亮点是,与CLIP相比,我们观察到ImageReward可以更好地区分单个样本之间的质量。上图展示了ImageReward的箱线图和CLIP在每个模 型的1000张图片上的分数分布。使用每个模型的最小值和最大值ImageReward和CLIP分数将分布归一化到0.0~1.0,并丢弃异常值。如图所示,ImageReward在每个模型的得分比CLIP的得分有更大的方差,这意味着ImageReward可以很好地区分彼此的图像质量。此外,在跨模型的比较方面,我们发现ImageReward分数的中位数也大致与人类排名一致。考虑到分布已经标准化,这尤其令人惊讶。相反,CLIP的中位数未能呈现属性。
6 ReFL:文生图Diffusion的奖励反馈学习(Reward Feedback Learning)
6.1 已有算法回顾
语言模型的RLHF不能直接应用在Diffusion中。在NLP中,有研究工作使用强化学习算法例如PPO来引导语言模型与人类偏好相一致,代表性的工作包括OpenAI的InstructGPT和ChatGPT,基于一次完整生成的likelihood来更新整个模型。然而,与基于Transformer的语言模型不同,Latent Diffusion Models的多步去噪生成无法产生一次完整生成的likelihood,因此不能采用相同的RLHF方法。
现有的LDM人类反馈微调方法都是间接的。目前可用的人类反馈微调LDM的优化方法基本上可以分为两类,一类是使用奖励模型获取新的数据集,另一类是使用奖励模型改变损失函数的系数。但是这些方法都是间接的,效果有限,这可以在后面的实验结果部分得到体现。
6.2 算法设计

通过观察去噪步骤中的ImageReward分数,我们得出了一个有趣的发现(参见上图左)。对于一个降噪过程,例如降噪步数为40步时,在降噪过程中途直接预测中间降噪结果对应的原图:
-
当t ≤ 15:ImageReward得分和最终结果的一致性很低;
-
当15 ≤ t ≤ 30:高质量生成结果的ImageReward得分开始脱颖而出,但总体上我们仍然无法根据目前的ImageReward分数清楚地判断所有生成结果的最终质量;
-
当t ≥ 30:不同生成结果对应的ImageReward分数的已经可以区分。
根据观察,我们得出结论,经过30步去噪(总步数为40步),而不需要到最后一步降噪,ImageReward分数可以作为改进LDM的可靠反馈。因此,我们提出了一种直接微调LDM的算法。算法流程可见上图右。将RM的分数视为人类的偏好损失,将梯度反向传播到去噪过程中随机挑选的后一步t(在我们的例子中t取值范围为30~40)。随机选择t而不是使用最后一步的原因是,如果只保留最后一个去噪步骤的梯度,训练被证明是非常不稳定的,结果是不好的。在实践中,为了避免快速过拟合和稳定微调,我们对ReFL Loss进行重新加权,并用Pre-training Loss进行正则化。
6.3 ReFL的实验结果

我们的实验基于Stable Diffusion v1.4,奖励模型统一采用ImageReward,使用PNDM作为noise scheduler,classifier free guidance采用默认值7.5。相比于微调之前的Stable Diffusion v1.4,ReFL微调模型最受青睐而且胜率最高。当和其他方法相互比较时,ReFL的结果总是更受偏好。

论文链接:arxiv.org/abs/2304.05977
代码主页:
https://github.com/THUDM/ImageRewardgithub.com/THUDM/ImageReward
模型下载:huggingface.co/THUDM/ImageRewar
数据集:huggingface.co/datasets/THUDM/ImageRewardDB