性能测试基础和尖峰测试+梯度压测
最近系统学习了一下性能测试,发现以前学习过程中有很多不足的地方,不够完善。因此记录一下,也算是把我学习到的知识和大家分享。
场景:
领导A:小张,最近我们的项目需要性能测试,你没事测一下。于是小张立马打开jmeter,新建线程组,新建请求,新建结果树,输入参数就开始压测了。那么问题就来了,压测的前提条件一个没提,需要达到多少TPS?系统最少保证多少用户正常使用?压测会占用系统多少资源?系统能否承受的了这么多请求同时访问?占用内存太大会不会影响程序运行?压测环境是用服务器还是用自己的电脑就行?
测试场景:
场景一:淘宝双十一用户下单,需要系统能够支持5000/s并发请求。
场景二:某一上班打卡系统,总共有120W用户,在早上尖峰时刻8-9点有30%用户访问,TPS要求1000/s。
在实际情况中很多公司其实并不需要以上这么大请求数量,但是为了能够全面理解性能测试,场景一采用多机器并发测试来分析。
一、性能测试常用指标和名词
在测试之前要先了解一下专业术语。
1.虚拟用户数
虚拟用户数就是线程数,每一个线程相当于一个用户
2.事务
事务代表一个完整的功能。一般由测试 人员自己决定,它可以是一个接口也可以是多个接口,多个接口组成的流程也叫事务。
3.并发数
在某一时间,一定数量的虚拟用户同时对系统的某个功能进行交互。
4.吞吐量
吞吐量是指单位时间内,系统能够处理多少请求(一般以秒为单位)。一般我们主要考虑TPS和QPS和RT(响应时间)。
TPS:事务数/秒。一个事务可以包含多个操作,场景一中有20W淘宝用户同时下单,那么TPS就是20W订单/秒。一般用总的事务数/总的运行时间来计算。
QPS:每秒查询率。场景一中每一个用户下单会产生好几个QPS(因为不止请求一个接口,还有其它的资源信息,请求服务器一次算一个QPS)。
RT:响应时间,用户执行请求到服务器响应总共花费的时间。场景一种用户下单从付钱到付款成功一整个响应时间。
5.资源占用率
性能测试中资源占用率指的是在测试中会占用系统多少资源,其中最常见的就是CPU、内存、网络、磁盘。在性能测试过程中,当然占用的资源越少越好,尽量用最小成本和资源支撑最多的吞吐量,支撑最小的响应时间。
二、性能测试整体流程
先了解一下整体的测试流程
1.需求分析和需求
性能测试的起点,一般来源于客户、产品经理、项目组领导(本次举例需求就来源于领导)
2.性能测试计划和方案制定
一般都是这四个测试标准为主:基准测试、负载测试、压力测试、稳定性测试
测试计划和方案由测试内部撰写,包含测试人员角色分工,测试指标、计划分工、需求分析(测试指标等)、测试用例、系统环境、场景及性能指标估算、性能指标监控要求等等。目的是分配测试人员,各司其职,分析好要求的性能指标,制定测试用例,准备系统环境,查看系统性能是否达到指标要求。
3.性能测试准备阶段
开始准备人力、硬件、软件、环境折算(服务器环境等)
4.测试执行阶段
开始用工具模拟业务
1)场景设计:采用jmeter进行业务流程的设计
2)指标监控:可采用grafana性能监控等软件监控CPU、内存等等信息
3)性能瓶颈定位和性能调优
5.测试报告和总结
根据测试结果编写报告,汇报性能情况
三、性能测试场景内容
上一章说了大致的流程。实际中还有一些需要注意的点。性能测试并不是上来就干,机器数量,前置条件,机器配置,都是我们要考虑到的。如果用户太多,为了追求高并发,需要多加几台服务器,机器的配置也必须一致。如果测试过程中动态变化,测试数据会失去准确性。
1.前置条件
1)性能测试机器:要求和正式环境相同的机器配置
2)固定的硬件配置:CPU、内存、网络、磁盘
3)固定的软件配置:连接池配置、JVM配置、限流配置
2.机器数量
采用多机器并发为理解。为了满足场景一5000/s的并发请求,公司有5台服务器(没有强制是五台,数量取决于你有多少服务器能满足以下压测需求)。
1)先单机压测
理论上每台服务器能够承载1000/s请求
2)再小集群压测
场景一中一台机器1000/s,五台机器理论上会达到5000/s,由于集群部署,机器之间会网络通信损耗,一般会是实际的80%-90%,所以五台机器理论上能处理的请求>4000/s
3.测试方式
在较正规的公司中。请求数量,例如jmeter中线程数量不是由测试来决定,而是由多方面因素来决定,主要是预估系统请求最高峰值:
1)市场:市场规模,公司的系统有多少目标用户。
2)产品:产品规划、产品日活–产品每日使用人数、用户操作习惯–哪个时间段用户操作最多。在场景二中,日活1200W用户,但有30%都集中在上午8-9点操作,那么就是360W用户,每分钟约6W人,每秒1000人,这时需求就是TSP为1000/s。
3)架构师:架构师根据已有线上数据进行分析,或者后台服务器系统数据统计分析。如果是新系统,那么就1000/s*10倍。
四、性能测试是否通过标准
主要通过以下几个指标来判断:
1)请求错误率:几千请求一般要求0错误率,一般情况下主要由产品经理来决定错误率。
2)响应时间在接受范围内:由产品提出要求,太慢用户接受不了
3)资源使用在可接受范围内:监控服务器(压测过程中网络流量、CPU、内存是否在可接受范围内,否则资源消耗过大会影响程序运行),一般在80%-90%。
五、尖峰测试+梯度测试
尖峰测试:适用于某一瞬间或者多个频次下用户数和压力陡然增加的场景。
梯度测试:个人理解请求数量就像梯子一样慢慢上升或者下降,常用于找到系统的瓶颈,不断增加请求来发现系统是否变得迟缓找到最大请求量。
由于机器数量有限,我们主要用场景二进行测试,场景二需求为TPS1000/s,在早上8-9点人数最多每秒1000人,平时500人。在分析完以上信息后,才可以开始用jmeter进行测试。
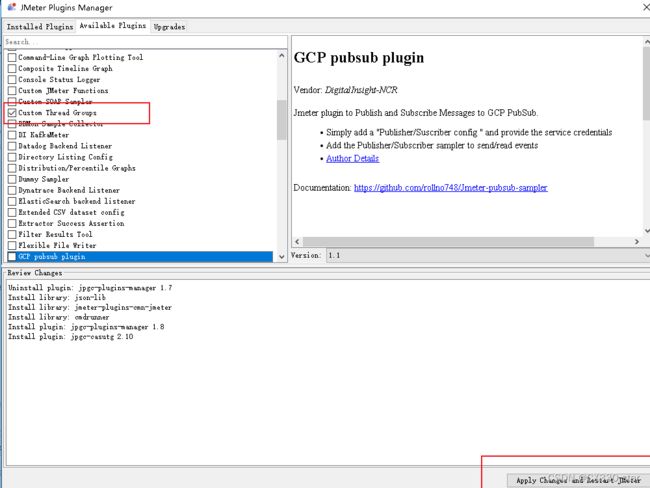
1.jmeter插件安装
由于需要用到jmeter中的梯度测试线程组,需要安装插件。参考:plungins manager插件安装
进入jmeter后如下操作
2.建线程组
jmeter重启后会发现新建线程组多了几个,选择新建Ultimate Thread Group(终极线程组),用这个线程组可以模拟所有场景,不用再添加其他线程组。

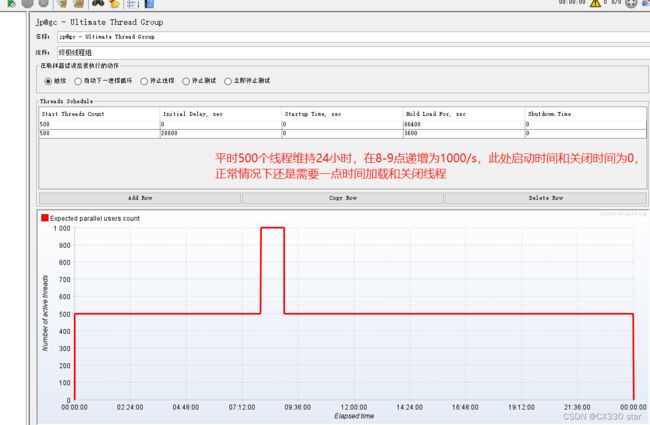
以图中为例:
Start Threads Count:开始线程数。图中启动100线程。
Initial Delay,sec:初始延迟,秒。图中初始延迟多久后再启动开始线程数,此处不延迟。
Startup Time,sec:启动时间,秒。图中表示启动时长30s,可以看到曲线在30秒开始才达到100,前面都在慢慢启动。
Hold Load For,sec:保持加载,秒。图中保持60s,可以看到有60S请求数都维持在100.
Shutdown Time:关机时间。和启动时间一样,启动时间在30S内慢慢启动,关机时间在10S内慢慢关闭为0。
场景二的情况应该为如图所示:
在终极线程组下正常添加HTTP请求即可,后续操作结果树等和平时使用jmeter一样,就不做讲解了
3.开始测试
填写完HTTP请求和查看结果树后,不建议在GUI界面上使用开始测试键来进行压测。界面加载需要时间,当数据量大的时候显示结果需要消耗资源,例如CPU或者内存,一般数据量大的时候采用命令行进行压测。将测试内容导出为test.jmx文件。
jmeter路径/bin/jmeter -n -t test.jmx -l test1.tjl -e -o ./report
#-n 命令行模式
#-t 执行要执行的jmx脚本路径
#-l 记录测试结果的文件
#-e 测试完成后生成报表
#-o 指定测试报告生成的文件夹(必须存在且为空)
命令执行完成后会在report文件夹中形成测试报告可供查看。
以上是性能测试前提和如何分析性能测试结果的个人理解。整个过程并没有实战,只是一个思路,具体的HTTP请求等还要根据实际情况来,可以自行找一个接口,定好要求的吞吐量等等来进行压测实战。