五个向量搜索中的难题,以及我们在Cassandra中如何解决它们
由于检索增强生成(RAG)如FLARE帮助LLMs加入最新的、定制的信息同时避免幻觉,所以向量搜索是生成性AI工具的关键组成部分。同时,向量搜索是一个功能,而不是一个产品 - 您需要查询与您其他数据相关的向量,而不是孤立地查询,您不应该需要构建一个流水线来同步其余的数据与一个向量存储。
2023年,向量搜索产品和项目经历了爆炸式的增长,选择其中的一个变得极为困难。在研究这些选项时,您需要考虑以下难题以及解决它们的不同方法。在这里,我将带您了解这些挑战,并描述DataStax如何为我们的DataStax Astra DB和Apache Cassandra的向量搜索实现解决它们。
维度的诅咒
在这些难题的核心是研究者所称的“维度的诅咒”。在实践中,这意味着对于2-D或3-D空间中的精确向量搜索有效的算法,如K-D树,在向量的维度达到10s、100s或1000s时会崩溃。结果是,对于高维向量的精确相似性搜索没有捷径;为了获得对数时间的结果,我们需要使用近似最近邻(ANN)算法,这些算法带来了以下领域的挑战。
问题1:扩展
许多向量搜索算法都是为适应单机内存的数据集设计的,而这仍然是ann-benchmarks唯一测试的场景。(Ann-benchmarks进一步限制其测试到单核心!)这对于有一百万文档或行的学术工作可能是可以的,但这已经有很多年不能被认为是代表真实世界的工作负载。
与任何其他领域一样,扩展需要复制和分区,以及处理替换死亡副本的子系统,修复网络分区后的它们,等等。
对我们来说,这是一个简单的问题:Cassandra的主要优势是扩展复制,结合新的Cassandra-5.0中的SAI(存储关联索引——参见CEP-7了解它的工作原理——和SAI文档了解如何使用它)为我们的向量搜索实现提供了强大的扩展能力,实际上是免费的。
问题2:高效的垃圾收集
所谓的“垃圾收集”是指从索引中移除过时的信息——清除已删除的行,并处理其索引向量值已更改的行。这可能看起来不值一提——在关系数据库世界中,这几乎已经是一个解决了的问题已有四十年——但向量索引是独一无二的。
关键问题是我们所知道的所有提供低延迟搜索和高召回结果的算法都是基于图的。有很多其他的向量索引算法可用——FAISS实现了其中的很多——但它们都要么构建太慢,搜索太慢,或者召回太低(有时三者兼而有之)不能作为一个通用解决方案。这就是为什么我知道的每一个生产向量数据库都使用一个基于图的索引,最简单的就是HNSW。层次可导航的小世界图由Yury Malkov等人在2016年引入;这篇论文相当易读,我强烈推荐它。关于HNSW的更多内容在下面。
图索引的挑战在于,当行或文档更改时,你不能只是撕掉旧的(与向量关联的)节点;如果你这样做超过几次,你的图将不再能够完成其定向BFS(广度优先搜索)到查询向量更相似区域的目的。
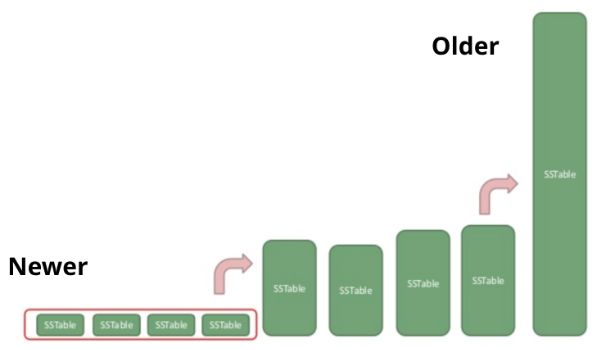
所以你需要在某个时候重建你的索引来进行这个垃圾收集,但是何时——以及如何——你组织它?如果你在更改时总是重建一切,你会大大增加实际写入的数量;这被称为写放大。另一方面,如果你从不重建,那么你在查询时会做额外的工作来过滤掉过时的行(“读放大”)。
这又是Cassandra多年来一直在研究的问题空间。由于SAI索引附加到主存储周期,它们也参与了Cassandra的压缩,对存储单元进行对数增长,以在读和写之间提供一个健康的平衡。
侧边栏:云应用工作负载
DataStax Astra DB建立在Apache Cassandra之上,为云应用工作负载提供一个平台。这意味着工作负载是:
大量并发的,每秒有成千上万的请求,通常是检索少量的行。这就是为什么你不能在Snowflake上运行Netflix,即使你能负担得起:Snowflake和类似的分析系统设计为只处理几个并发请求,每个请求运行时间为几秒到几分钟甚至更长。
大于内存。如果你的数据集适应于单机的内存,你使用什么工具几乎都无所谓。SQLite,MongoDB,MySQL——它们都工作得很好。但当不是这种情况时,事情变得更具挑战性——而且坏消息是,向量嵌入通常是几KB或大约是典型数据库文档的一个数量级,所以你会很快达到大于内存。
应用的核心。如果你不在乎是否丢失你的数据,无论是因为它不那么重要,还是因为你可以从实际的记录源重建它,那么再次,你使用什么工具都无所谓。像Cassandra和Astra DB这样的数据库是为了确保你的数据无论如何都是可用的和持久的而构建的。
问题3:并发性
如我上文所提及,著名的 ann-benchmarks 比较将所有算法限制在一个单核上。虽然这使得各个算法处于同一起跑线上,但这也限制了那些能够利用过去二十年内硬件改进的主要来源的算法。
一个相关的问题是 ann-benchmarks 一次只执行一种操作:首先构建索引,然后查询它。在搜索中交错地处理更新是可选的 - 甚至可能是一个障碍;如果您知道不需要处理更新,那么您可以做出许多简化的假设,这在人工基准上看起来效果很好。
如果你关心的是能够使用你的索引并发执行多个操作或在它构建完成后更新它,那么你需要深入了解它是如何工作的以及涉及到的权衡。
首先,我知道的所有通用向量数据库都使用基于图的索引。这是因为您可以在插入第一个向量后立即开始查询图索引。大多数其他选择要么要求您在查询它之前构建整个索引,要么至少要对数据进行初步扫描以了解一些统计属性。
然而,在图索引类别内部仍然有重要的实施细节。例如,我们最初认为我们可以通过使用 Lucene 的 HNSW 索引实现来节省时间,像 MongoDB、Elastic 和 Solr 那样。但我们很快发现 Lucene 只提供单线程、非并发的索引构建。也就是说,您既不能在构建时查询它(这应该是使用这种数据结构的主要原因之一!)也不能允许多个线程并发构建它。
HNSW 论文建议可以使用细粒度的锁定方法,但我们做得更好,构建了一个非阻塞索引。这是在 JVector 中开源的。
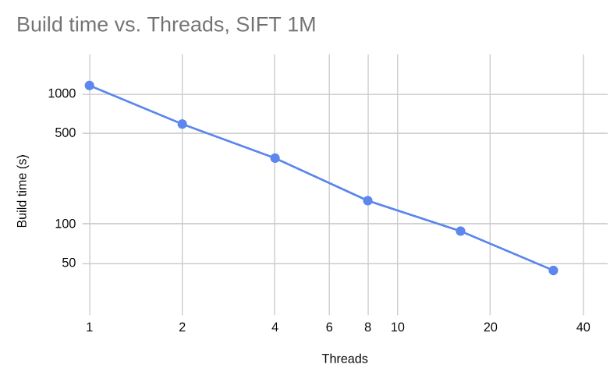
JVector 将并发更新线性扩展到至少32个线程。这张图在 x 轴和 y 轴上都是对数刻度,显示加倍线程数可以将构建时间减半。
这张图在 x 轴和 y 轴上都是对数刻度,显示加倍线程数可以将构建时间减半。
更重要的是,JVector 的非阻塞并发性更有助于混合搜索与更新的现实工作负载。这是 Astra DB 的性能(使用 JVector)与 Pinecone 在不同数据集上的比较。虽然 Astra DB 的静态数据集比 Pinecone 快大约10%,但在同时索引新数据时,它的速度是 Pinecone 的8到15倍。

Astra DB 保持更高的召回率和精确度:

虽然 Astra DB 的静态数据集比 Pinecone 快大约10%,但在同时索引新数据时,它的速度是 Pinecone 的8到15倍。
问题4:有效使用磁盘
我们开始使用 HNSW 图索引算法,因为它构建索引快、查询快、准确性高,且实现简单。然而,它有一个众所周知的缺点:它需要大量的内存。
HNSW 索引是一系列的层,其中每个高于基层的层都有大约10%的节点数量。这使得上层可以充当跳过列表,允许搜索定位到包含所有向量的底层的正确邻域。
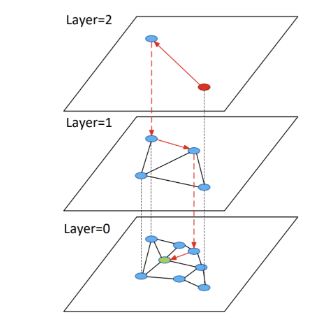
但是,这种设计意味着(与所有图索引一样)你不能仅仅依赖说:“磁盘缓存会拯救我们”,因为与常规的数据库查询工作负载不同,图中的每个向量都有几乎相等的机会与搜索相关。(例外是我们可以并且确实缓存的上层。)
这就是为什么在我们使用 Lucene 时,在我的64GB RAM 的桌面上为一个包含大约120GB 的 Wikipedia 文章块的100M 向量数据集提供服务的简介:

Cassandra 几乎花费了所有的时间等待从磁盘上读取向量。
为了解决这个问题,我们实施了一个更先进的算法叫做 DiskANN,并将其作为一个独立的嵌入式向量搜索引擎开源,叫做 JVector。(具体来说,JVector 实现了 FreshDiskANN 论文中描述的 DiskANN 的增量版本。)简而言之,DiskANN 使用与 HNSW 更长的边的单级图和一个优化的向量和邻居的布局来减少磁盘 IOPS,并在内存中保留向量的压缩表示来加速相似性计算。这使得 Wikipedia 工作负载的吞吐量增加了三倍。
以下是在没有客户端/服务器组件的纯嵌入式场景下的 HNSW 与 DiskANN 的对比。这测量了在 Lucene(HNSW)和 JVector(DiskANN)下搜索 Deep100M 数据集的速度。Lucene 索引是55GB,包括索引和原始向量。JVector 索引是64GB。搜索是在我的24GB MacBook上进行的,其内存约为索引RAM大小的三分之一。

问题5:组合性
在数据库系统的背景下,组合性指的是无缝整合各种功能和能力的能力,使之以连贯的方式呈现。当讨论新类别能力,如向量搜索的集成时,这尤为重要。非玩具应用程序将始终需要经典的CRUD数据库功能以及新的向量搜索。
考虑一个简单的Astra DB的AI聊天机器人示例应用程序。这是你能找到的一个纯粹的RAG应用程序,使用向量搜索将适当的文档呈现给LLM以回应用户的问题。然而,即使是这样一个简单的演示也仍然需要对Astra DB进行“正常”的、非向量查询以检索对话历史记录,这也必须与每一个请求到LLM一起被包含,这样它可以“记住”已经发生的事情。因此,关键查询包括:
-
找到与用户问题最相关的文档(或文档片段)。
-
检索用户对话中的最后二十条信息。
在一个更真实的用例中,我们的一位解决方案工程师最近与亚洲的一家公司合作,他们希望在产品目录中添加语义搜索,但也希望启用基于术语的匹配。例如,如果用户搜索[“红色”球阀],那么他们希望限制搜索的项目是其描述与术语“红色”匹配的,无论向量嵌入的语义相似性如何。新的关键查询(在经典功能如会话管理、订单历史和购物车更新的基础上)因此是:限制产品为包含所有引用术语的产品,然后找到与用户搜索最相似的产品。
这第二个例子明确表示,应用程序不仅需要经典的查询功能和向量搜索,而且它们经常需要在同一个查询中使用每个元素。
在这个年轻领域的当前艺术状态是尝试在一个“正常”的数据库中做我所称的经典查询,在一个向量数据库中进行向量查询,然后在同时需要两者时用拼凑的方式将两者结合在一起。这是容易出错的,速度慢,成本高;它的唯一优点是你可以使它工作,直到你有一个更好的解决方案。
在Astra DB中,我们基于Cassandra SAI构建了(并开源了)一个更好的解决方案。因为SAI允许创建与Cassandra Stable和压缩生命周期都相关的自定义索引类型,所以Astra DB可以很容易地允许开发者混合和匹配布尔谓词、基于术语的搜索和向量搜索,而不需要管理和同步独立的系统。这为构建生成性AI应用程序的开发者提供了更高级的查询功能,驱动更高的生产力和更快的上市时间。
结论
向量搜索引擎是一个重要的新数据库功能,具有多种架构挑战,包括扩展、垃圾回收、并发性、有效使用磁盘和组合性。我相信,在为Astra DB构建向量搜索时,我们已经能够利用Cassandra的能力为生成AI应用程序的开发者提供一流的体验。
作者:Jonathan Ellis
更多内容请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。