一个关于国产化适配 的PPT文案
前一阵,对外做了一个直播,主题是关于信创国产化,由于本身就为公开对外直播,无保密相关问题,因此,当时的PPT文案在此公开,供大家参考。由于初次审核以有广告嫌疑为理由拒绝,这里我将公司名称统一替换成了XXX,这里我就是单纯的分享下,无任何广告目的。
1. 信创国产化背景&XXX产品国产化历程
在进入本次分享的正题之前,首先需要简单了解一下信创国产化的背景,以及,XXX产品国产化的历程。
1.1 信创国产化背景及要求
2020年初始,随着我们伟大祖国的日渐强大,以及,在计算机软硬件领域能力及实力的提升,国家提出了信息创新的口号,即,常常被提到的:信创或者信创国产化。并计划于3年之内,即2022年底,政府机关和事业等单位全面完成芯片、操作系统、数据库的国产替代。
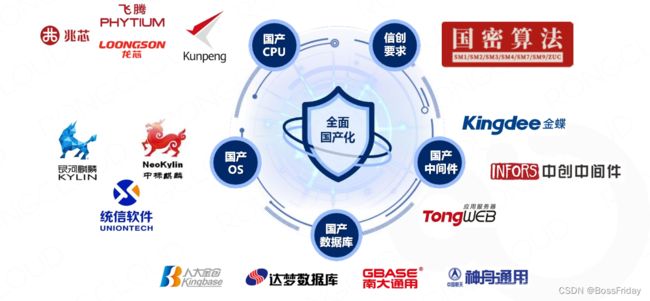
PPT中所展示的是,一张我个人绘制的国产化全景图,从图中我们可以看出:
- 在国产芯片方面,会涉及到:兆芯、龙芯、飞腾、鲲鹏等,后续的介绍中会包含其主要CPU型号详情。
- 在国产操作系统方面,会经常遇到:中标麒麟、银河麒麟和统信软件。早年间,中标麒麟和银河麒麟各自独立运营,之后他们强强联合,合并为麒麟软件,目前麒麟软件占据了国产操作系统大部分的市场份额。
统信软件最近几年在国产操作系统方面发力迅猛,目前逐步形成了后起之势。 - 在国产数据库方面,主要还是老牌的四家:金仓、达梦、南通和神通。 需要补充说明的是,神通主要涉军,并且通过了中国人民解放军军用信息安全产品军B级认证,在非涉军项目的交付中,一般只会遇到前三者的概率居多。
除了芯片、操作系统、数据库三个方面外,在国产化的交付中常常还会碰到:国产化中间件和国密算法支持等其他要求,从图中,我们可以看到: 国产化中间件主要包括:东方通、中创、金蝶等,在实际的交付可能还会碰到普元、宝兰德、华宇等其他国产中间件。
对于国密算法,大家可以先简单了解到国密算法包括:国1,国2,国3,国4和国7、国9以及祖冲之密码算法。 不同国密算法会对应不同的密保强度,其国1可以认为与常用的AES对称加密算法处于同一等级。
在过去的2020年和2021年,全面支持国产化还可以说是政企行业的核心竞争力之一,但随着2022年的临近,信创国产化必将成为政企行业的必要门槛之一。
1.2 XXX产品国产化历程
接下来,向大家介绍一下 XXX产品国产化的历程以及取得的一些成果。
2020年是信创产业推广的元年,XXX于当年上半年,就完成了首套,鲲鹏920+达梦V8+统信V20的国产化适配,并取得相关认证。
2020年下半年到2022年,XXX在信创国产化方面持续发展和完善,累计取得信创国产化相关认证累计达十多套,覆盖组合类型数量达到200+。由于篇幅所限,这里只贴出主要国产芯片、操作系统、数据库、中间件的认证证书。
2022年,XXX并没有满足与过去所取得的成绩,积极的与国密厂商合作,在国密支持方面持续投入,目前,在传输及存储的国密支持方面,已初具成效。
目前XXX产品国产化适配已经比较全面,适配范围足以涵盖实际交付中能够碰到的绝大多数情况。除此之外,XXX在信创项目的实施经验也十分丰富,目前XXX已经正在牵头制定信创相关领域的行业标准,可以说XXX在信创国产化方面成绩斐然,基本领先与同行厂商。
2.服务端国产化适配
接下来,正式进入今天的话题,首先,从服务端国产化适配方面,谈谈我们所走过的弯路及其应对策略。
2.1 国产数据库命名建议
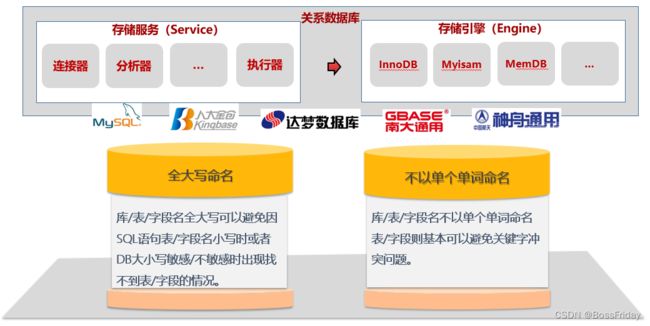
首先谈谈国产数据库适配方面的问题,2020年上半年,本人做为XXX国产化适配的负责人,带领团队完成了XXX产品国产化适配项目的一期工程,并且拿到了XXX的首个国产化认证证书,在项目初期,国产DB的适配是工时投入占比较大的一块。一般来说,
支持SQL的数据库由:存储服务(service)和存储引擎(engine)两个部分组成,其中,连接器负责client的连接及鉴权,分析器负责SQL语句的词法和语法分析,执行器则负责与存储引擎交互进行SQL语句的执行。国产关系数据库分析器层面均遵循SQL规范,但在存储引擎上则各不相同。因此,主要的国产关系数据库虽然都支持SQL,但并不意味着,MySQL上执行没有问题的SQL语句,在国产数据库上执行一定没有问题。也不意味着,金仓上能跑通的SQL在南通数据库下也能跑通。为了尽量的保障一条SQL语句在各个关系型数据库上执行均没有问题,XXX建议:库/表/字段的命名全部大写,并且避免以单个单词命名,极端的情况下,个人认为可以将其列为开发规范去明令禁止。
- 全大写的好处是,可以避免因数据库大小写敏感设置导致的找不到库/表或者字段的情况发生。需要说明的是,在实际的交付中,国产DB往往不会由己方人员进行安装,通常遇到的情况是:由国产数据库厂商进行提供。如果自身的适配工作不能有一定的包容性,那么在实际的交付中,往往需要投入更多的人力成本。大家可能都有一个感触,厂商之间的协作与沟通,往往更让人更加的头疼和无奈。
- 不以单个单词进行库/表/字段等的命名的原因是,之前提到的,各家虽然都基于SQL,但是存储引擎却各不相同,导致关键字的各不相同。根据我们在国产DB适配的经验,如果不以单个单词进行命名,关键字冲突的问题则基本不会发生。
2.2 使用jdk-8u192做为Java运行环境
接下来,我们谈谈服务端国产化适配中的第2个问题,上图是XXX企业版中较为典型的网络拓扑结构。谈到网络拓扑,网络连通一定会涉及DMZ区,内网区,存储区等。XXX企业版为了保障系统的高性能,自研了高效的私有协议,我们称之为RMTP协议(Rong Message Transmit Protocol XXX消息传输协议,该协议可以理解为一个非标的MQTT协议,说到MQTT自然一定会联想到其精简性),序列化则使用高效的Protobuf,缓存方面大量使用LRU缓存淘汰算法,RPC方面则基于经典的Actor模型,同时所有接入/接口服务均使用Netty框架进行实现。很多事情有利有弊,Netty虽然是一个高效的异步NIO框架,但Netty自身所依赖的第三方包也比较多,这势必也会导致其中的某些包不支持ARM或者MIPS的可能性也较大。在国产化适配测试的过程,我们曾经遇到推送不可用问题,经过排查后定位为netty引用的第三方包不支持arm。 最终,我们通过:使用jdk-8u192做为Java运行环境并在对应架构下重新编译的方式解决了该类问题。
需要补充说明的是,2019年1月起,Oracle开始对JDK8进行收费,8u192是2018年的最后一个update,这意味着,能够没有任何问题的继续无偿使用下去。
2.3 性能测试应覆盖主要国产化交付组合
服务端国产化适配的最后一个问题是:性能测试应覆盖主要国产化交付组合。
2.3.1 国产CPU现状
在介绍该问题之前,我们需要首先了解一下国产CPU的现状,说到CPU或者芯片,我们需要简单了解芯片指令集的概念,简单来说,芯片指令集大致分为2个阵营,即:复杂指令集和精简指令集,他们就是我们通常说的CISC & RISC,需要特别说明的是,复杂指令集(RISC)的设计初衷是:高性能但同时高功耗,而精简指令集(RISC)则是:小尺寸低功耗。由此,我们可以简单得出一个结论:相同规格的复杂指令集架构的CPU性能一定高于精简指令集架构下的CPU。例如,同样是8核的CPU,X86的至强或者酷睿性能一定高于ARM架构的鲲鹏或者飞腾等。
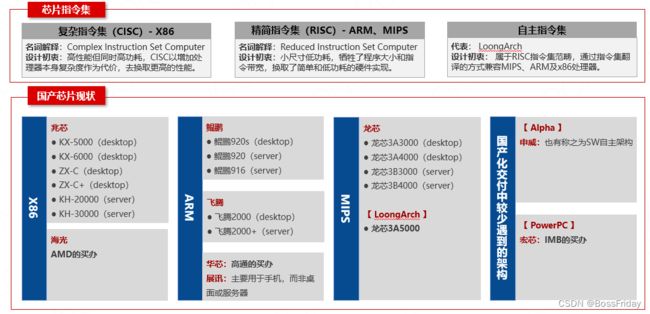
如果你有心想在这方面关于国产化去深入了解下去,可能你会看到:自主指令集的字眼,目前交付中涉及到这方面的可能性主要来自于龙芯的基于自主LoongArch架构的龙芯3A5000。关于LoongArch,大家需要知道的是:LoongArch 仍为RISC指令集范畴即可,不过需要说明的是:LoongArch通过指令集翻译的方式兼容MIPS、ARM及x86处理器,龙芯的目标是在2025年的时候消除指令集之间的壁垒。翻译效率方面目前公开的数据是:MIPS:100%、ARM:90%、x86:Linux下翻译的效率可达80%。可能有的时候你还会看到自主架构SW的字眼,不过从公开的资料来看,SW架构实际上是比较小众的Alpha架构,其对应的芯片为申威,并且该芯片主要应用于涉军项目,通常的交付中难以碰到。
在PPT中,我已经罗列出了目前国产化项目交付中,多数情况下可能碰到的CPU型号,这里我就不一一赘述了。如果大家需要PPT稿件以备后续查阅,可以扫描PPT最后一页的二维码,关注XXX公众号即可获取。
2.3.2 建议覆盖范围

接下来,分享一下国产化性能测试应覆盖的范围。由于国产芯片以RISC架构居多,显然在国产化项目交付的时候,所需要的服务器资源不能用非国产化下的基数去进行估算。XXX针对主要的国产化交付组合做了大量的性能测试和实际验证,最终得到了较为合理的评估标准基数,配合服务器资源配算工具,可以做到快速评估服务器资源。由于这个性能指标基数一定需要结合CPU、OS、系统本身来谈,因此这就需要各自对自己的系统在不同的组合下去进行实测。建议的覆盖范围是:鲲鹏:920/920S、飞腾:2000/2000+、龙芯:3B3000/4000,搭配统信V20及麒麟V10。这项摸底工作的展开过程中,往往会碰到拿不到对应的环境的问题,我们是通过两种方式进行的解决:
- 鲲鹏环境从华为云上获取。
- 从合作厂商借用机器进行测试、以及直接使用客户的测试环境进行摸底。
关于服务器资源配算工具,可以直接使用Excel来实现,毕竟估算方法和自己系统的实测配算基数有了之后,无非就是加减乘除,四舍五入,只舍不入,只入不舍或者十位/百位取整什么的,这些Excel公式都有,由于公司各核心系统的压力测试工具也是我写的,所以很自然服务器资源配算工具的提供也落到我头上了,这里我给大家打个样:

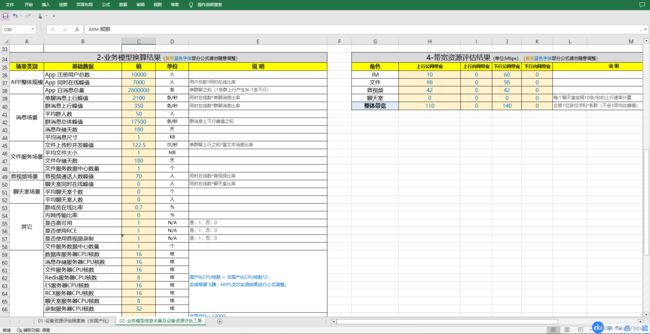
需要补充说明的是,在国产化交付的工作中,我们需要大致了解操作系统与CPU的关系,由于涉及比较专业的操作系统基础知识,这里我不一一带读,大家只要简单知道:ARM下编译的builder只能在ARM运行,其他架构也是同样。在国产化项目交付的工作中,我们需要将操作系统与CPU架构一起来说,不同CPU架构下的同名操作系统需要认为是不同操作系统。因此今后不要只说UOS下的性能表现如何,ARM下的表现如何?而应该把两者结合在一起去说,否则都是不严谨的。
3. 客户端国产化适配
服务端国产化适配的相关问题和经验就此介绍完毕,接下来我们从客户端和部署交付这两个方面来谈谈其他问题和经验。
3.1 不同操作系统打包规范不同
在客户端国产化适配功能测试阶段,发现了很多因为不同操作系统打包规范不同所导致的问题,例如:桌面客户端卸载之后应用Ico图标未被清理、客户端托盘不能闪烁以及客户端托盘活生生的直接显示为2个图标等问题。这些问题,我们都可以归结为客户端的打包与相应系统的打包规范不一致所导致的。这个世界上,最难的事情往往不是解决问题本身,而是提出或者发现一个新的问题,该问题的解决策略可以直接而简单的去找国产操作系统厂商索要打包规范,然后依据规范进行打包即可。联系信创厂商这件事情,大家完全可以不要有任何的顾虑,因为目前芯片、操作系统、数据库等方面早已经迈过了基础能力建设的阶段,各大信创厂商自身也都十分重视生态发展,因此,各大信创厂商对此都是很开放的。
3.2 不同操作系统 libc 版本不一致
接下来我们来看另外一个客户端适配中所遇到的问题:不同操作系统 libc 版本不一致。
对于桌面的客户端的研发,相比于服务端,最为重要的一个区别是:服务端往往更多考虑高并发所引发的相关问题,而客户端则涉及的较少,毕竟一人用一端嘛。但是,客户端的研发,往往也会分层,同样也会涉及缓存、DB和其他复杂逻辑的组件封装,就是我们通常说的,客户端本地缓存、客户端本地DB以及客户端SDK或者协议栈和插件等。XXX企业版客户端RCE,协议栈使用C++做为开发语言,同时一些插件也是基于C++进行开发,例如:截屏插件。在XXX国产化适配的过程中,一个困扰客户端很长时间的问题就是这些C++的协议栈和插件因为不同操作系统 libc 版本不一致所引发的问题。根据我们的经验,建议:不管是ARM还是MIPS架构都在麒麟系统上进行编译,因为同一架构下麒麟系统的libc版本都比统信系统低,一般麒麟系统的libc版本为2.2.3,统信的则为2.2.8。
3.3 静态编译QT的基础上编译其他插件node文件
在国产化适配客户端功能测试中,客户端截屏功能无法正常使用是最早暴露的问题之一,和上一个问题类似,但是不同的是,这里只针对客户端插件的范畴去给出另外的一种解决方案,概要来说就是:客户端插件通过静态编译QT的基础上编译其他插件node文件方式来处理。静态编译后,最终的执行其实是基于解释性的执行方式,天生具备了良好的兼容性。而动态编译方式下,最终的执行则是由执行器直接执行编译产物。从上述的描述中大家应该能够明白为什么这里只是针对客户端插件的范畴,因为像截屏插件这种实现上选择不多,又不要求其执行效率要求多高的插件,利用静态编译天生具备的良好兼容性去解决,无疑更佳。
4.国产化部署交付
最后我们从国产化部署交付方面分享一下XXX产品国产化适配过程中所需要关注的问题。
4.1 不同操作系统 glibc 版本不一致
PPT中所展示是XXX企业版系统逻辑架构图,从图中我们可以看出,整个系统分为:界面UI层、接入/接口层、中间逻辑层、数据存储层。几乎所有的应用应用系统都会使用和依赖一些中间件或者工具,例如:数据存储中间件、消息队列中间件、缓存中间件等,另外进程管理工具在部署交付一般都会用到,例如:supervisor。从图中我们可以看出XXX企业版同样依赖这里所提到的几个方面的中间件,毕竟重复造轮子的事情需要有足够的理由才会去考虑。
在部署交付之前,大家常常都会预先把所有的部署资源提前准备好,包括:服务自身的编译包、中间件等,现场临时编译显然不是明智之举,这样即不能做到快速部署,过程也不可控。XXX企业版本所依赖的中间件中,一部分基于C或者其他非Java语言,万恶的国产化Linux C编译问题再次袭来。为了统一编译,达到泛部署的目的,我们需要找到一个合适的版本进行中间件的编译,以适应多数的场景。这个合适的版本不能过高也不能过低,因为过高的版本在遇到低版本一定出问题,过低的版本则有可能出现中间件依赖找不到的情况,我们针对麒麟、统信做了大量的摸索和尝试,终于使得预编译部署资源在多数场景下可以正常使用,从而达到了范部署的效果。
4.2 不同操作系统Path环境变量不同

不同操作系统Path环境变量不同,这个问题处理起来特别简单,其原因也特别浅显,就是:很多服务或者中间件的正常运行都依赖Path环境变量的设置。但是,这里我们给出的优先解决方式是:通过软链方式去解决该问题。我们的考虑是:做为操作系统的使用者,各方面的理解及评估能力一定远远不及厂商自身,不直接修改操作系统环境变量则一定能够完全规避修改环境变量引发其他问题的可能,无疑,这种解决方式是:将产生其他的影响的可能性降到最低的一种方式。
4.3 不同操作系统rpm包存在差异
最后,谈谈部署工具本身在国产化适配中碰到的问题,通常在自动化部署工具的实现上,大家都用python,毕竟,不会python的运维不是好运维。但是python的运行环境需要依赖python-rpm package。在不同操作系统rpm包存在差异情况下,就可能出现问题。自动化部署工具自身都出现各种问题,那么何谈快速部署?解决该问题的办法,优先推荐直接使用操作系统厂商所提供的rpm包。其实这个问题在非国产操作系统上也存在,那么我们推荐的做法是:直接从操作系统自身的yum源中去获取。这里再次提到了优先联系操作系统厂商获取帮助(之前介绍客户端国产化适配遇到的问题中,也提到找操作系统厂商获取打包规范)。这里,最后分享一条不是经验的经验就是:与国产化厂商建立良好的合作关系也是非常重要和必要的,因为出现问题后如果可以直接从对应厂商处获取到协助,无疑是最为高效及有效的。