ICCV 2021 | High-Fidelity Pluralistic Image Completion with Transformers 阅读笔记(部分翻译)
High-Fidelity Pluralistic Image Completion with Transformers
作者:Ziyu Wan 1 ^1 1 Jingbo Zhang 1 ^1 1 Dongdong Chen 2 ^2 2 Jing Liao 1 ∗ ^{1*} 1∗
单位: 1 ^1 1City University of Hong Kong 2 ^2 2Microsoft Cloud + AI
会议:ICCV 2021
项目地址:raywzy.com/ICT
Abstract
由于CNN的一些固有属性(spatial-invariant kernels等),其不能做到很好的理解全局特征;最近transformer展示了其在long-term关系中的有效性,但是他们的计算复杂度是与输入长度成平方的,这妨碍了高分辨率图像的处理。概论提出了两个世界的最好组合去图像修复:使用transformer来实现重构先验,使用CNN来补充纹理。transformer恢复了粗糙的一致性结构,CNN在粗糙的先验基础上增强了局部纹理细节。(还可以得到多个不同的图像修复结果)
1. Introduction
CNN也存在一些固有的局限性:1)卷积运算的局部归纳先验使得对图像的全局结构建模困难;2) CNN滤波器具有空间不变性,即相同的卷积核对所有位置的特征进行操作,使得重叠的图案或模糊的伪影经常出现在masked区域。另一方面,CNN模型具有固有的确定性(指同样的输入只能有一个输出)。为了实现不同的修复输出,最近的一些框架[39,37]依赖于优化实例似然的变分下限(optimizing the variational lower bound of instance like-lihood)。然而,额外的分布假设将不可避免地损害生成内容[38]的质量。
Transformer,作为语言任务中探索得很好的架构,在许多计算机视觉任务中正在崛起。与CNN模型相比,它抛弃了局部归纳性先验(baked-in local inductive prior),通过dense注意力模块[31]来支持long-term interaction。使用transformer进行合成的另一个优点是,它通过直接优化底层数据分布可以自然地支持多元化输出。然而,transformer也有其自身的不足。由于其计算复杂度是输入长度的二次方,它在高分辨率图像合成或处理中遇到了困难。此外,现有的基于transformer的生成模型[24,5]大多是以自回归的方式工作的,即,按照固定的顺序合成像素,就像栅格扫描顺序一样,这就阻碍了它在图像修复任务中的应用,因为缺失区域的形状和大小往往是任意的。
本文提出了好方法:Transformer的全局结构理解能力和多元支持能力,以及CNN模型的局部纹理细化能力和效率。为此,我们将图像补全分解为两个步骤:使用transformer进行多元外观先验重构以恢复相干图像结构,使用CNN进行低分辨率上采样以补充精细纹理。具体来说,给定一个缺失区域的输入图像,我们首先利用transformer来采样低分辨率的补全结果,即表象先验appearance priors。然后,在表象先验和输入图像可用像素的指导下,利用另一个上采样CNN模型对缺失区域进行高保真纹理渲染,同时保证与相邻像素的一致性。特别是,不像之前的自回归方法(5、30),为了使transformer模型能够通过考虑所有可用的上下文来补全丢失的区域,我们优化了基于双向条件(bi-directional conditions)的缺失像素的对数似然目标(we optimize the log-likelihood objective of missing pixels based on the bi-directional conditions),这是受masked的语言模型BERT所启发[9]。
1)与之前的只有一个输出的修复方法相比,我们的方法在各种指标上大大优于他们的方法;2)与以往的多元补全方法相比,我们的方法进一步提高了结果的多样性,同时实现了更高的补全保真度;3)由于transformer具有较强的结构建模能力,我们的方法在完成超大缺失区域和大型泛型数据集(如ImageNet)时,泛化效果更好,如图1所示。值得注意的是,与最先进的PIC[39]方法相比,ImageNet上的FID评分最多提高了41.2分。
2. Related Works
Visual Transformers Vaswaniet al.[31]首先提出了用于机器翻译的transformer。transformer的整体结构是由堆叠的自注意层和point-wise前馈层组成的编码器和解码器组成。但这些方法在生成图像时依赖于固定的排列顺序,不适用于填充形状不同的缺失区域。
Deterministic Image Completion 这些方法可以产生合理的修复结果,但是缺乏产生多样化结果的能力。
Pluralistic Image Completion 虽然他们在一定程度上取得了多样性,但由于variational训练,他们的修复质量受到了限制。与这些方法不同,我们直接通过transformer优化离散空间的对数似然,而不需要辅助假设。
3. Method
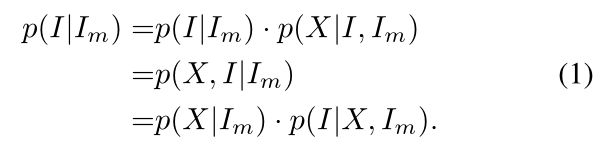
I m I_m Im是缺损图像, I I I是完整图像, p ( I ∣ I m ) p(I|I_m) p(I∣Im)是给定 I m I_m Im后 I I I的条件分布; X X X是第一阶段粗糙的先验信息。这个公式推导的有点奇怪。。最后一行前半个是第一阶段的任务,后半个是第二阶段的任务。
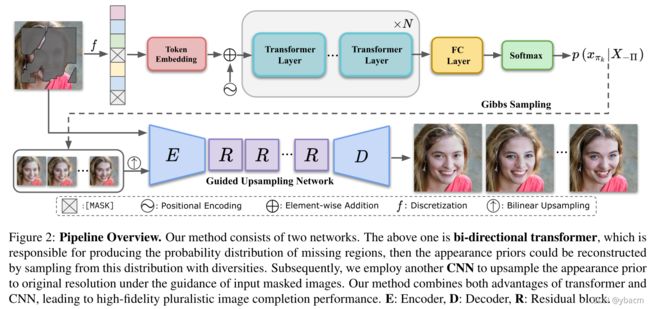
3.1. Appearance Priors Reconstruction
Discretization 由于multi-head attention高昂的计算成本(quadratically increasing),我们使用了32×32或48×48分辨率的结构信息作为第一阶段的粗糙结果。尽管如此,RGB像素表示( 25 6 3 256^3 2563)的维数仍然太大。为了进一步降低维数并真实再现低分辨率图像,使用整个ImageNet [8] RGB像素空间的KMeans聚类中心生成一个额外的视觉词汇表,该词汇表具有512×3的空间大小。然后,对于每个表象先验像素,我们从视觉词汇表中搜索最接近元素的索引,以获得其离散表示。另外,对应hole区域的表征序列的元素将被替换为一个特殊的标记token[MASK],这也是transformer的学习目标。为此,我们将先验的表象转化为离散序列。
Transformer 对于离散序列的每个标记 X = { x 1 , x 2 , . . . , x L } X=\{x_1,x_2,...,x_L\} X={x1,x2,...,xL},其中 L L L是X的长度,我们通过预先添加可学习的embedding将其投影到d-维度特征向量中。为了对空间信息进行编码,额外的可学习位置embedding将被添加到每个位置 1≤i≤L 的标记特征中,以形成transformer模型的最终输入 E ∈ R L × d E∈R^{L×d} E∈RL×d。
与GPT-2[26]类似,我们使用仅解码器transformer作为我们的网络架构,它主要由基于transformer层的N个self-attention的组成。在每个transformer层,计算公式为:

其中LN、MSA、MLP分别表示层归一化[1]、多头自注意层和FC层。更具体地说,给定输入E,MSA可以计算为:
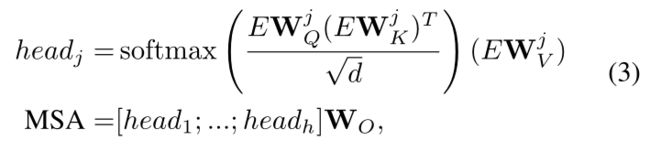
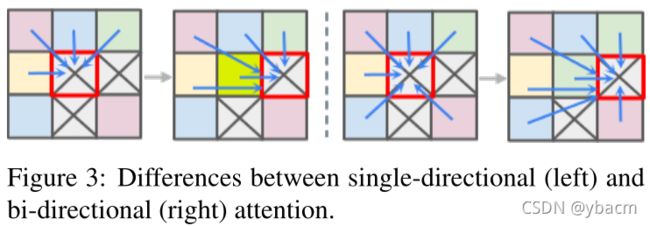
其中 h 是头部的数量, W Q j W^j_Q WQj、 W K j W^j_K WKj 和 W V j W^j_V WVj 是三个可学习的线性投影层,1≤j≤h。 W O W_O WO 也是一个可学习的 FC 层,其目标是融合来自不同头部的输出的串联。 通过调整transformer layer N的参数,嵌入embedding维度d和head数h,我们可以很容易地缩放transformer的大小。 还应该注意的是,与自回归transformer[5,24] 不同,自回归transformer通过单向注意力生成元素,即仅受扫描线前上下文的约束,我们使每个标记关注所有位置以实现双向注意,如图3所示。 这确保生成的分布可以捕获所有可用的上下文,无论是在光栅扫描顺序中的mask位置之前还是之后,从而导致生成内容和未mask区域之间的一致性。
使用全连接层和 softmax 函数,最终transformer层的输出进一步投影到(超过了) 512 个视觉词汇中的每个元素。 我们采用与 BERT [9] 中使用的相似的掩码语言模型 (MLM) 目标来优化transformer模型。 具体而言,令 Π = { π 1 , π 2 , . . . , π K } Π =\{π_1, π_2, . . . , π_K\} Π={π1,π2,...,πK} 表示离散化输入中 [MASK] 标记的索引,其中 K 是mask标记的数量。 令 X Π X_Π XΠ 表示 X 中的 [MASK] token集, X − Π X_{−Π} X−Π 表示未masked token集。 MLM 的目标是在所有观察到的区域条件下最小化 X Π X_Π XΠ 的负对数似然:
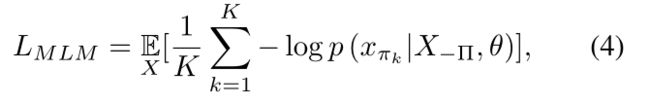
其中θ为transformer参数。引入双向注意的MLM目标保证了transformer模型能够捕获整个上下文信息,从而预测缺失区域的概率分布。
Sampling Strategy 在本节中,我们将介绍如何使用经过训练的 Transformer 获得合理且多样化的表象先验。 给定transformer的生成分布,由于独立性,直接对整个mask位置集进行采样不会产生好的结果。 相反,我们使用 Gibbs 采样在不同位置对token进行迭代采样。 具体来说,在每次迭代中,从 p ( x π k ∣ X − Π , X < π k , θ ) p(x_{π_k}|X_{−Π}, X_{<π_k}, θ) p(xπk∣X−Π,X<πk,θ) 中采样一个网格位置,其中包含前 K 个预测元素,其中 X < π k X_{<π_k} X<πk 表示之前生成的标记。 然后对应的 [MASK] token被替换为采样的令牌,并重复该过程,直到更新所有位置。 与 PixelCNN [30] 类似,默认情况下以光栅扫描方式顺序选择位置。 采样后,我们可以获得一堆完整的token序列。 对于从transformer采样的每个完整的离散序列,我们通过查询视觉词汇来重建其表象先验 X ∈ R L × 3 X∈R^{L×3} X∈RL×3。
3.2. Guided Upsampling
在重构低维表象先验后,我们将 X reshape为 I t ∈ R L × L × 3 I_t∈R^{\sqrt{L}×\sqrt{L}×3} It∈RL×L×3 以进行后续处理。 由于 I t I_t It包含了多样性,现在的问题是如何学习确定性映射将 I t I_t It重新缩放为原始分辨率H×W×3,同时保持masked区域和未masked区域之间的边界一致性。 为了实现这一点,由于 CNN 具有建模纹理模式的优势,这里我们引入了另一个引导上采样网络,它可以在masked输入 I m I_m Im 的引导下渲染重建表象先验的高保真细节。引导上采样(guided upsampling)的处理可以写为:
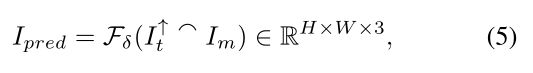
其中 I t ↑ I^↑_t It↑是 I t I_t It的双线性插值结果, ⌢ \frown ⌢表示沿通道维度的级联操作。F是由δ参数化的上采样网络的骨干,主要由编码器、解码器和几个残差块组成。 可以在补充材料中找到有关架构的更多详细信息。
最小化预测值 I p r e d I_{pred} Ipred和真实值 I I I的L1 loss:![]()
为了产生更现实的细节,额外的对抗损失也包含在训练过程中,具体来说,
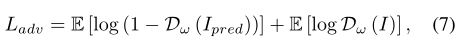
其中 D 是由 ω 参数化的鉴别器。 我们通过解决以下优化来联合训练上采样网络 F 和鉴别器 D,

在所有实验中,损失权重设置为 α1=1.0 和 α2=0.1。 我们还观察到,涉及实例归一化 (instance normalization, IN) [29] 会在优化过程中导致颜色不一致和严重的伪影。 因此,我们删除了上采样网络中的所有 IN。
4. Experiments
我们在第 4.1 节中介绍了实现的细节,随后评估(第 4.2 节)并深入研究(第 4.3 节)提出的基于transformer的图像完成方法。 多元图像补全实验在 FFHQ[16]、Places2[40] 和 ImageNet[27] 三个数据集上以 256×256 分辨率进行。 我们保留了整个 FFHQ 中的 1K 图像用于测试,并在其余数据集中使用原始的常见训练和测试分割。 PConv [19] 提供的多样化的不规则mask数据集用于训练和评估。
4.1. Implementation Details
我们通过同时平衡数据集的表征能力和大小来控制transformer架构的规模。 FFHQ 的离散序列长度为 48×48。 受计算资源的限制,我们在大规模数据集 Places2 和 ImageNet 上将可行 L 减少到 32×32。 不同transformer模型的详细配置附在补充材料中。
我们使用 8 个 Tesla V100 GPU 用于 FFHQ,batch size为 64, 4×8 Tesla V100 GPU 用于 Places2 和 ImageNet,batch size为 256 来训练transformer直到收敛。 我们使用 AdamW [22] 优化网络参数,其中 β1=0.9 和 β2=0.95。学习率在第一个 epoch 中从 0 线性增加到 3e-4,然后在剩余迭代中通过余弦调度器(cosine scheduler)衰减到 0。 模型中没有采用额外的权重衰减和dropout策略。 为了训练引导上采样网络,我们使用 Adam[17] 优化器,固定学习率为 1e-4,β1=0.0 和 β2=0.9。 在优化过程中,根据经验将不同损失项的权重设置为第 3.2 节中描述的固定值。
4.2. Results
与Edge-Connect I C C V ’ 19 _{ICCV’19} ICCV’19(EC) [23], DeepFillv2 I C C V ’ 19 _{ICCV’19} ICCV’19(DFv2) [35], MED E C C V ’ 20 _{ECCV’20} ECCV’20[20] and PIC C V P R ’ 19 _{CVPR’19} CVPR’19[39] 的预训练模型进行比较。
Qualitative Comparisons 我们采用sec.3.1中引入的采样策略,k =50,并行生成20个解决方案,然后选择PIC[39]之后的上采样网络的判别器评分排名前6的结果。所有报告的结果,我们的方法是直接输出的训练模型,没有额外的后处理步骤。
我们在图4中显示ffhq and places2 数据集上的结果。具体来说,EC[23]和MED[20]一般可以产生缺失区域的基本成分,但纹理细节的缺失使得它们的结果非真实感。DeepFillv2[35]基于多阶段恢复框架,可以生成清晰的细节。然而,当掩膜区域相对较大时,严重的伪影就会出现。此外,他们的方法只能为每个输入产生一个单一的解。PIC[39]作为目前最先进的多元化图像修复方法,其内容往往过于光滑,图案奇怪,语义上合理的变化也局限在一个小范围内。与这些方法相比,我们的方法在真实感和多样性方面都有优势。图5中,我们进一步展示了与DeepFillv1 C V P R ′ 18 _{CVPR'18} CVPR′18(DFv1)[34]和PIC[39]在ImageNet数据集上的比较。在这种具有挑战性的设置下,完全基于cnn的方法不能很好地理解全局上下文,导致不合理的补全。遇到较大的mask时,甚至不能保持图5第二行所示的精确结构。相比之下,我们的方法得到了较好的结果,证明了我们的方法在大规模数据集上具有特殊的泛化能力。

Quantitative Comparisons 我们在数值上将我们的方法与表 1 和表 2 中的其他基线进行了比较。 峰值信噪比(PSNR)、结构相似指数(SSIM)和relative l1(Mean absolute error, MAE)用于比较恢复输出和真实值的low-level差异,更适合衡量 小比例的mask设置。 为了评估较大的缺失区域,我们采用 Fréchet Inception Distance (FID) [13],它计算完成结果和自然图像之间的特征分布距离。 由于我们的方法可以产生多个解决方案,我们需要找到一个示例来计算提到的指标。 与 PIC [39] 不同,PIC [39] 为每个样本选择具有高排序判别器分数的结果,这里我们直接提供随机采样结果,同时 K=50 以证明其泛化能力。此外,我们还提供了表 1 中给定 K=1 的确定性采样结果。可以看出,与其他竞争对手相比,我们采用 top-1 抽样的方法在几乎所有指标上都取得了优异的结果。在相对较大的掩码区域的情况下,前 50 名top-50采样会导致 FID 分数略好。在 ImageNet 数据集上,如表 2 所示,我们的方法明显优于 PIC,尤其是在 FID 指标方面(大型掩码为超过 41.2 ratio)。


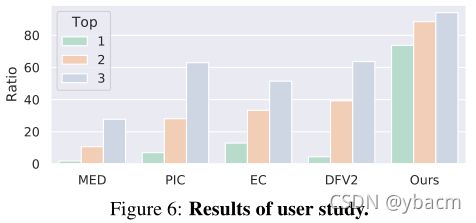
User Study 为了更好地评估主观质量,我们进一步进行了用户研究,将我们的方法与其他基线进行比较。 具体来说,我们从测试集中随机选择 30 张mask图像。 对于测试图像,我们使用每种方法生成一个完成结果,并要求参与者将五个结果从最高真实感到最低真实感进行排名。 我们收集了 28 位参与者的答案,并计算了每种方法被选为前 1、2、3 的比例,统计数据如图 6 所示。 我们的方法被选为第一的可能性要高 73.70%,证明了它的明显优势。
4.3. Analysis
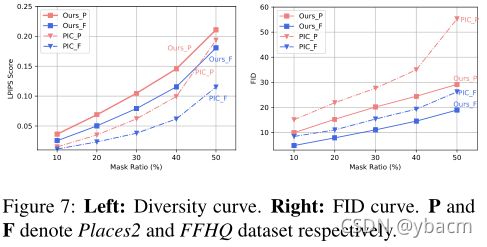
Diversity 根据Zhuet al.[41],我们计算来自相同输入的随机采样输出对之间的平均LPIPS距离[36],以测量修复的多样性。具体来说,我们在不同的掩码比例下,每个输入都有5对输出。基于在ImageNet上预先训练的VGG[28]模型的深度特征计算LPIPS。多样性得分如图 7 所示。 由于内容多样但无意义的修复也会导致高LPIPS分数,我们同时在图7的右侧部分提供了在整个采样结果(10K)和自然图像之间计算的每个级别的FID分数。 我们的方法在所有情况下都实现了更好的多样性。 此外,在 Places2 的最大掩码比率中,虽然 PIC [39] 接近我们方法的多样性,但我们完成的感知质量大大优于 PIC [39]。
Robustness for the completion of extremely large holes. 为了进一步了解transformer的能力,我们进行了额外的实验,设置非常大的hole,这意味着只有非常有限的像素可见。虽然transformer和上采样网络都只使用PConv[19](最大掩码比60%)的数据集进行训练,但我们的方法可以很好地推广到这个困难的设置。在图8中,几乎所有的基线都失败了,缺失区域很大,而我们的方法可以产生高质量、多样化的修复结果。

If the transformer could better understand global structure than CNN? 为了回答这个问题,我们对一些几何图元进行了补全实验。 具体来说,我们询问我们基于transformer 的方法和其他完整的 CNN 方法,即 DeepFillv1 [34] 和 PIC [39],在 ImageNet 上训练以恢复图 10 中五角星形状的缺失部分。 正如预期的那样,所有完整的 CNN 方法都无法重建丢失的形状,这可能是由卷积核的局部性引起的。 相比之下,transformer 可以轻松地在低维离散空间中重建正确的几何形状。 基于这种精确的外观先验,上采样网络最终可以更有效地呈现原始分辨率结果。
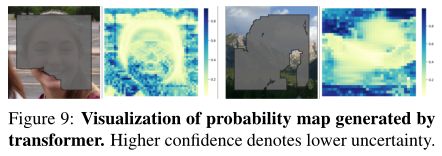
Visualization of probability map. 直观上,由于缺失区域的轮廓与现有像素相邻,因此从掩码边界到内部区域的补全置信度应该逐渐降低。置信度越低,结果就越多样化。为了验证这一点,我们在图9中绘制概率图,其中每个像素表示transformer生成视觉词汇表的最大概率。我们有一些有趣的观察结果:1)在图9右边的部分,不确定性确实从外部向内部增加。2)在人像补全示例中,面部区域的不确定性总体上低于毛发部分。其根本原因是面部的可见部分在一定程度上限制了其他区域的多样性。3)在其余mask区域中,肖像示例右脸颊的概率最高,说明transformer 捕捉到了对称属性。

5. Concluding Remarks
在图像补全领域存在一个长期存在的困境,以实现足够的多样性和逼真的质量。 现有的尝试大多是通过完整的 CNN 架构优化变分下界,这不仅限制了生成质量,而且难以呈现自然变化。 在本文中,我们首先提出两全其美的方法:transformers 的结构理解能力和多元化支持,以及 CNN 的局部纹理增强和效率,以实现高保真自由形式的多元图像完成。 进行了大量实验以证明我们的方法与最先进的完全卷积方法相比的优越性,包括在常规评估设置上的巨大性能增益,更加多样化和生动的结果,以及对大规模掩码和数据集的卓越泛化能力。