人工智能AI 全栈体系(九)
第一章 神经网络是如何实现的
如何用神经网络处理不等长文本的方法?
八、循环神经网络(RNN: Recurrent Neural Network)
- 处理不等长文本的神经网络 – 循环神经网络 RNN。

1. 从句子理解说起

- 上次讲了用词向量表示词,一句话也可以表示为一个向量。
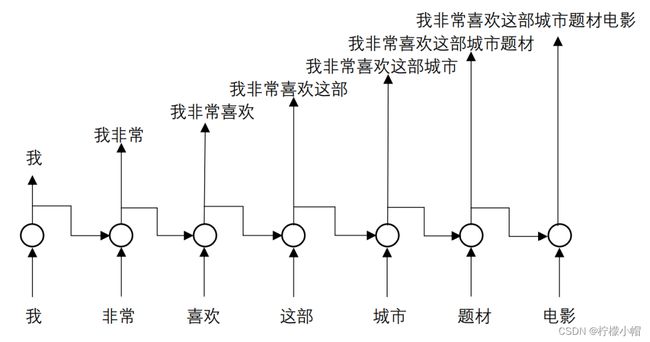
- 我们在看一个句子的时候,是一个词一个词地看的,当看了前几个词之后,对句子所表达的内容就已经有所了解,每增加一个词,句子表达的意思就清楚一些,直到看完了句子的全部词,就完全了解了该句子所要表达的准确含义。对句子的理解是一点一点渐进地理解的。
- 比如我们举例的这个句子:“我非常喜欢这部城市题材电影”。第一个词只有一个“我”,这时我们知道这句话可能是要表达“我如何”;当第二个词“非常”出现后,就了解到这句话可能是想表达“我非常如何”,可能是喜欢,也可能是讨厌等。随着第三个词“喜欢”的出现,我们就知道可能是想表达“我非常喜欢”某种东西或者某件事情……,以此类推,直到句子结束,我们就知道了这句话表达的是什么内容。这个过程用图示的形式表达出来如下图所示,图中每个圆圈接受当前词和之前所有词的语义信息作为输入,而圆圈的输出就是到当前这个词时,包括当前词在内的前面几个词合在一起的语义信息,最后一个圆圈的输出则表达了整个句子的语义信息。
2. 循环神经网络的设计

- 假设第 i 个词用长度为 n 的词向量 x ( i ) = [ x 1 ( i ) , x 2 ( i ) , . . . , x n ( i ) ] x^{(i)} = [x_1^{(i)},x_2^{(i)},... ,x_n^{(i)}] x(i)=[x1(i),x2(i),...,xn(i)] 表示,一句话从第一个词到第 i 个词所包含的语义信息我们用长度为 m 的向量 h ( i ) h^{(i)} h(i) 表示, h ( i ) = [ h 1 ( i ) , h 2 ( i ) , . . . , h m ( i ) ] h^{(i)} = [h_1^{(i)},h_2^{(i)},...,h_m^{(i)}] h(i)=[h1(i),h2(i),...,hm(i)] ,那么就可以设计如图所示的一个循环神经网络,图中每个圆圈可以看成是一个只有输入层和输出层的全连接神经网络,我们称为子网络。该循环神经网络由若干个这样的子网络由左到右连接组成,其中第 i 个子网络的输入分别为当前词的词向量 x ( i ) x^{(i)} x(i) 、前面 i-1 个词的向量表示 h ( i − 1 ) h^{(i-1)} h(i−1) ,输出为前面 i 个词合在一起的向量表示 h ( i ) h^{(i)} h(i) 。这样一句话中最后一个子网络的输出 h ( t ) h^{(t)} h(t) 就可以认为是这句话的向量表示,我们可以称为句向量。这种神经网络由于是一个词一个词地处理一句话中的每一个词,所以称为循环神经网络,简称 RNN。
- 图中每个圆圈就是一个只有输入层和输出层的全连接神经网络——称为子网络,每个子网络如图(a)所示,输入分别是词向量 x ( i ) x^{(i)} x(i) 、前面 i-1 个词的向量表示 h ( i − 1 ) h^{(i-1)} h(i−1) ,输出是前 i 个词合在一起的向量表示 h ( i ) h^{(i)} h(i) 。为了表达的更清楚起见,我们可以将图(a)画成图(b)的样子,这样更容易与一个全连接神经网络对应起来。输入分成了 h ( i − 1 ) = [ h 1 ( i − 1 ) , h 2 ( i − 1 ) , . . . , h m ( i − 1 ) ] h^{(i-1)} = [h_1^{(i-1)},h_2^{(i-1)},...,h_m^{(i-1)}] h(i−1)=[h1(i−1),h2(i−1),...,hm(i−1)] 和 x ( i ) = [ x 1 ( i ) , x 2 ( i ) , . . . , x n ( i ) ] x^{(i)} = [x_1^{(i)},x_2^{(i)},...,x_n^{(i)}] x(i)=[x1(i),x2(i),...,xn(i)] 两组,这两组输入连接在一起可以看成一组输入,输出层每个神经元对应 h ( i ) h^{(i)} h(i) 的一个分量, h ( i − 1 ) h^{(i-1)} h(i−1) 和 x ( i ) x^{(i)} x(i) 的每个分量到输出层的每个神经元都有连接,如果 h ( i − 1 ) h^{(i-1)} h(i−1) 的第 j 个分量到输出层第 k 个神经元的权重为 w k , j w_{k,j} wk,j , x ( i ) x^{(i)} x(i) 的第 l l l 个分量到输出层第 k 个神经元的权重为 u k , l u_{k,l} uk,l ,则施以 tanh 激活函数后,输出层第 k 个神经元的输出 h k i h_k^i hki 为:
h k i = t a n h ( w k , 1 ⋅ h 1 ( i − 1 ) + w k , 2 ⋅ h 2 ( i − 1 ) + ⋯ + w k , m ⋅ h m ( i − 1 ) + h_k^i = tanh(w_{k,1} \cdot h_1^{(i-1)} + w_{k,2} \cdot h_2^{(i-1)} + \cdots + w_{k,m} \cdot h_m^{(i-1)} + hki=tanh(wk,1⋅h1(i−1)+wk,2⋅h2(i−1)+⋯+wk,m⋅hm(i−1)+
u k , 1 ⋅ x 1 ( i ) + u k , 2 ⋅ x 2 ( i ) + ⋯ + u k , n ⋅ x n ( i ) ) u_{k,1} \cdot x_1^{(i)} + u_{k,2} \cdot x_2^{(i)} + \cdots + u_{k,n} \cdot x_n^{(i)}) uk,1⋅x1(i)+uk,2⋅x2(i)+⋯+uk,n⋅xn(i))


- 每个子网络就是一个标准的全连接神经网络,然后若干个子网络再横向串联在一起,就组成了循环神经网络。
- 对于第一个子网络怎么处理呢?计算 h ( 1 ) h^{(1)} h(1) 时要用到 h ( 0 ) h^{(0)} h(0) , h ( 0 ) h^{(0)} h(0) 怎么得到呢?
- h ( 0 ) h^{(0)} h(0) 默认为0就可以了,也就是 h ( 0 ) h^{(0)} h(0) 的每个分量都设置为0,相当于对于 h ( 1 ) h^{(1)} h(1) 来说,只有输入 x ( 1 ) x^{(1)} x(1) 而没有 h ( 0 ) h^{(0)} h(0) 一样。
3. 循环神经网络的训练
- 无论是训练全连接神经网络,还是训练神经网络语言模型,总有一个希望的输出,并以此为根据设计损失函数,再用 BP 算法求损失函数最小,从而达到训练目的。
- 但是在循环神经网络中,只是说一个句子中最后一个子网络的输出 h ( t ) h^{(t)} h(t) 是句向量,并不知道句向量的希望输出是什么,如何构造损失函数呢?
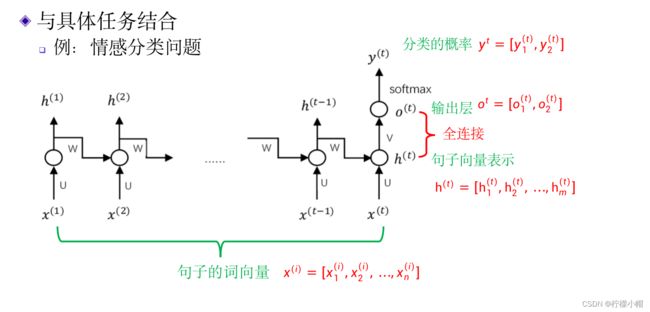
- 比如前面曾经举过的短文本情感分类的例子,我们可以在上图的基础上,在 h ( t ) h^{(t)} h(t) 上面再接一个具有两个神经元的全连接层 o t = [ o 1 ( t ) , o 2 ( t ) ] o^t = [o_1^{(t)}, o_2^{(t)}] ot=[o1(t),o2(t)] ,最后通过 softmax 激活函数获得两个输出 y t = [ y 1 ( t ) , y 2 ( t ) ] y^t = [y_1^{(t)}, y_2^{(t)}] yt=[y1(t),y2(t)] ,分别表示输入句子属于正情感的概率和负情感的概率。

-
在 h ( t ) h^{(t)} h(t) 的上面增加了一个具有两个神经元的全连接层 o t = [ o 1 ( t ) , o 2 ( t ) ] o^t = [o_1^{(t)}, o_2^{(t)}] ot=[o1(t),o2(t)] ,再通过softmax激活函数得到情感的概率输出。设 h k ( t ) h_k^{(t)} hk(t) 到 o l ( t ) o_l^{(t)} ol(t) 的连接权重为 v l , k v_{l,k} vl,k ,用公式表示如下:
o 1 ( t ) = v 1 , 1 ⋅ h 1 ( t ) + v 1 , 2 ⋅ h 2 ( t ) + ⋯ + v 1 , m ⋅ h m ( t ) o_1^{(t)} = v_{1,1} \cdot h_1^{(t)} + v_{1,2} \cdot h_2^{(t)} + \cdots + v_{1,m} \cdot h_m^{(t)} o1(t)=v1,1⋅h1(t)+v1,2⋅h2(t)+⋯+v1,m⋅hm(t)
o 2 ( t ) = v 2 , 1 ⋅ h 1 ( t ) + v 2 , 2 ⋅ h 2 ( t ) + ⋯ + v 2 , m ⋅ h m ( t ) o_2^{(t)} = v_{2,1} \cdot h_1^{(t)} + v_{2,2} \cdot h_2^{(t)} + \cdots + v_{2,m} \cdot h_m^{(t)} o2(t)=v2,1⋅h1(t)+v2,2⋅h2(t)+⋯+v2,m⋅hm(t)
y 1 ( t ) = e o 1 ( t ) e o 1 ( t ) + e o 2 ( t ) y_1^{(t)} = \frac{e^{o_1^{(t)}}}{e^{o_1^{(t)}} + {e^{o_2^{(t)}}}} y1(t)=eo1(t)+eo2(t)eo1(t)
y 2 ( t ) = e o 2 ( t ) e o 1 ( t ) + e o 2 ( t ) y_2^{(t)} = \frac{e^{o_2^{(t)}}}{e^{o_1^{(t)}} + {e^{o_2^{(t)}}}} y2(t)=eo1(t)+eo2(t)eo2(t) -
结合具体任务就可以进行训练了,这个属于分类问题,可以用交叉熵损失函数进行训练。
-
不只是在最后一个子网络可以添加全连接层,更一般的情况下,每个子网络也都可以添加全连接层,在有些任务下,可能会用到所有子网络的输出。
4. 循环神经网络的一般结构


- 引入循环网络的目的之一就是为了处理不定长短文本问题,但是在循环神经网络中,子网络的数量是与句子中的词数量一致的,如何处理不定长的短文本呢?
- 在循环神经网络中子网络的数量与句子中词的数量一样多,但是每个子网络都是一样的,包括子网络中的那些权重W、U、V等,在不同的子网络中都是共享的,也就是每个子网络的权值都是一样的,所以本质上只有一个子网络,只是一个词一个词地输入进来,每输入一个词就可以得到一个输出,直到句子结束就获得了整个句子的输出,我们之所以展开成了多个子网络串联在一起只是为了更容易理解,实际之前图所示的一般的循环神经网络可以画成上图的形式,这种形式更体现出了“循环”神经网络的含义。图中的黑方块“∎”表示延迟一拍的意思,也就是表示前面n-1个词的向量表示与当前词的词向量一起作为输入。这样的话,循环神经网络实际上只有一个子网络,该子网络被一句话中不同的词共享,每输入一个词,都会得到一个输出,句子中的词全部输入结束后,就得到了句子的向量表示。所以,输入的句子长度没有限制,有多少个词都可以,从而达到了处理不定长短文本的目的。
- 下面举例介绍几种循环神经网络的应用,在例子中,只对网络的关键部分加以说明,其他部分就不详细说明了,跟前面的内容大同小异。
5. 举例:中文分词问题
-
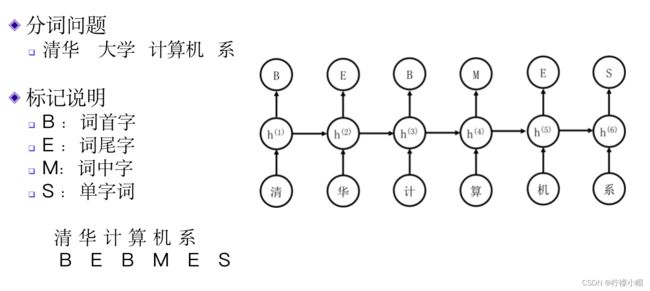
汉语中句子是以字为单位书写的,但是理解是以词为单位的,由于书写时词间没有像空格这样的标记,在汉语自然语言处理时,首先遇到的就是分词问题。分词问题有很多研究,也提出了很多不同的算法。
-
以“清华计算机系”为例,分词结果应该为“清华 计算机 系”。由于分词问题输入是以字为单位的,所以该循环神经网络的输入是一句话中所含字的字向量。字向量与词向量类似,也可以通过神经网络语言模型获得。输出是“B”、“E”、“M”和“S”这四个字母的概率,4个字母的含义为:
-
B:当前字为词首字也就是词的第一个字的概率,比如“计算机”中“计”为词首字。对于单字词则没有词首字,会单独处理;
-
E:当前字为词尾字也就是词的最后一个字的概率,比如“计算机”中“机”为词尾字。同样,对于单字词也没有词尾字。
-
M:当前字为词中字也就是处于词的中间的概率,比如“计算机”中“算”为词中字。一个词的词中字可能有多个,比如“人工智能”中,“工”和“智”都是词中字,也可能没有词中字,比如“清华”一词就没有词中字。
-
S:当前字为单字词的概率。比如“系”就是一个单字词。
-
-
还是以“清华计算机系”为例,正确的标记为:
- 清 华 计 算 机 系
- B E B M E S
-
子网络的输出共4个神经元,分别对应是这4个字母的概率。这样分词问题就变成了对句子中的字进行分类的问题。
6. 举例:看图说话问题

- 用循环神经网络也可以做“看图说话”,如果输入如图所示的照片,神经网络根据照片内容输出:“草地上有一只漂亮的小狗”。
- 首先对于循环神经网络来说,输入是一个序列,比如我们在前面的例子中,输入是词的序列。而看图说话问题输入只有一张图像,可以认为是这张图像重复多次而构成一个序列,或者说对于循环神经网络的每个子网络,其输入都是一样的,都是这张图像。
- 其次,循环神经网络的输入是一个向量,而图像是二维的,需要将二维的图像信息转化为一个向量。最简单的方法就是直接将图像展开成一个向量,比如可以将图像信息看成是一个矩阵,然后一行一行地连接在一起,构成一个向量。另外一种方法就是像前面介绍的处理图像的各种神经网络那样,将图像输入给一个神经网络,最后一层用一个全连接层,得到一个图像的向量表示。
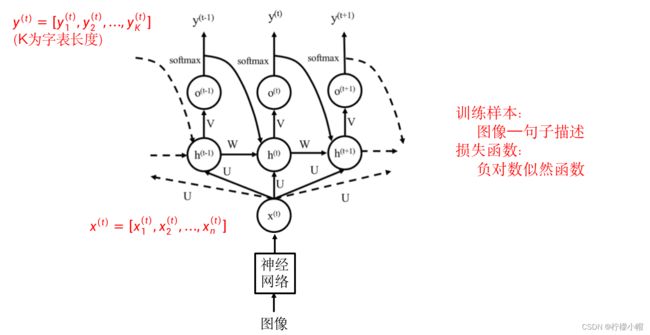
- 上图给出了一个用循环神经网络实现的看图说话系统示意图。图中 x ( t ) x^{(t)} x(t) 为图像的向量表示,就像刚才说过的一样,该图像要输入到循环神经网络的每个子网络中。输出是与图像内容相关的一句话, y ( t ) = [ y 1 ( t ) , y 2 ( t ) , . . . , y K ( t ) ] y^{(t)} = [y_1^{(t)}, y_2^{(t)},... ,y_K^{(t)}] y(t)=[y1(t),y2(t),...,yK(t)] 对应这句话的第t个词,其中K为词表长度, y k ( t ) y_k^{(t)} yk(t) 表示句中第t个词为词表中第k个词的概率。
- 由于一句里中前后词之间是有关联的,所以在普通循环神经网络的基础上,图例增加了第t-1个输出,也就是 y ( t − 1 ) y^{(t-1)} y(t−1) 引入到第t个子网络的输入,以适应这种前后词之间的关联。
- 训练时训练样本就是“图像—内容描述”对,由多个这样的样本组成训练集,训练算法还是BP算法。
- 但是在应用中还存在一些问题。比如,循环神经网络在处理文本时,是从前向后一个词一个词地处理的,当一个句子比较长时,前面的内容就有可能被后面的内容淹没,从而影响了对一句话的全面表达。
- 如何解决这个问题呢?
7. 双向循环神经网络

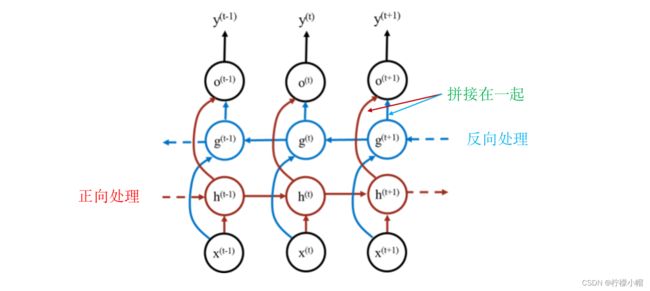
- 为此研究者提出了双向循环神经网络,如上图所示。其基本思路就是对于一个输入序列,正向处理一次,反向处理一次,然后将两次处理的结果拼接在一起用于后续处理。比如“我 喜欢 看 电影”这句话,正向处理就是“我 喜欢 看 电影”,反向处理就是“电影 看 喜欢 我”,这样对于这句话的第i个词我们可以从正向得到一个向量表示 h ( i ) h^{(i)} h(i) ,也可以从反向得到一个向量表示 g ( i ) g^{(i)} g(i) ,然后将 h ( i ) h^{(i)} h(i) 和 g ( i ) g^{(i)} g(i) 连接成一个向量使用,其他就与普通循环神经网络一样了。由于正向、反向各计算了一次,从而削弱了一句话中前面内容被后面内容淹没的问题。
8. 序列到序列循环神经网络
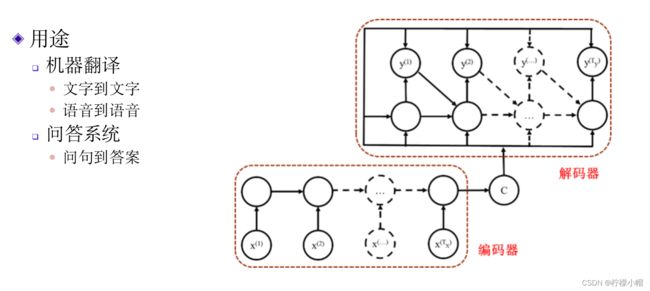
- 在前面介绍的句子情感分类例子中,循环神经网络将一个句子表达为一个向量,然后再分类。而在看图说话例子中,输入是一个向量,通过循环神经网络将向量又表达为一个序列。其实我们也可以把这两种循环神经网络连接在一起,先将一句话表达为一个向量,再通过一个循环神经网络将该向量表达为一个序列。如上图所示。其中将一个句子表达为向量我们常称为编码,而将一个向量又表达为一个序列称为解码。这种循环神经网络我们称为序列到序列循环神经网络。
- 这种循环神经网络有很多用处,比如用作机器翻译。编码部分将一种语言进行编码,而在解码部分将得到的编码解码为另一种语言,就实现了语言翻译。也可以用在问答系统中,编码部分将自然语言表述的问题进行编码,解码部分将编码解码为问题的答案。这样就实现了输入一个问题,得到问题的答案的目的。
- 循环神经网络不仅仅可以求解自然语言处理相关的问题,还可以用于求解很多其他方面的问题,只要该问题可以表达为一个序列求解问题。比如语音识别问题,输入是一个语音序列。
9. 总结

- 循环神经网络主要用于处理序列输入,在序列处理结束时,获得输入序列的向量表示。如果输入的是一个句子,则相当于是词序列,句子处理接受后就可以得到该句子的向量表示。循环神经网络共用一个处理单元,以当前输入(输入序列中的当前处理元素)和此输入之前的序列向量为输入,得到到目前为止的序列向量。
- 循环神经网络的训练需要和一个具体的任务相结合,根据任务目标给出损失函数,用BP算法训练。所以循环神经网络得到的序列表示也是与任务有关的。
- 为了防止当输入序列很长时,序列中处于前面的元素被逐渐淡化的问题,可以采用双向循环神经网络,也就是同一个序列正向处理一次,逆向再处理一次,然后组合在一起使用。
- 循环神经网络可以用到很多任务中,比如机器翻译、看图说话、中文分词等。