聊一聊目前 Web 前端开发的一些困局

导读
2021 年,Web 开发整体上仍然处于比较低效的状态,各种开发,部署工具仍未很好的收敛,开发者仍然要面对选择框架,选择各种库,选择部署方式,沟通前后端接口等,一个完整的 Web 应用开发会牵扯很多不同的工种,而不同分工之间的协作却是很低效的,本文旨在能够很好的梳理当下 Web 开发的 "困局",以及我们通过何种方式,能够走出这些困局,解放生产力,希望能给未来的工具发展给出一定的预测和启发。
困境
设计/前端协作困境
在实际的 Web 开发中,UI/UX 的工作与前端的工作事实上是在两个完全割裂的环境中进行的,比如,UI 会在 Figma 中完成页面与组件的设计,而前端则是根据设计好的原型图,在代码环境中去复现原型图,这其中就出现了几个协作问题。我把它简要总结成四个问题:
应该先设计再开发,还是先开发再设计?(Dev First or Design First?)
如果说设计的原型图是前端开发的上游,那前端应该如何更高效地获取设计的上游更新?
设计图中藏有很多可复用的概念与元素,如何很好的传达给前端?
前端工程师是否有义务参与纯样式的开发?既然 UI 已经完成了样式的设计,为什么前端仍然需要重新实现一遍?
下面我们逐个讨论这些问题,之后给出可能的解决方案。
Dev First Or Design First?
先来讨论第一个问题,这是一个困扰了我很久的问题,在之前的工作经验中,我的处理方式往往是,以功能为主的组件,先开发,再设计(比如富文本编辑器),以展示为主的,先设计,再开发,但是实际的协作仍然会出现很多问题:
Dev First:先开发再设计,往往前端程序员需返工 (比如原来调的现成组件现在不能直接用了,需要自己重新写一个),降低前端程序员工作体验,而在设计图不稳定的时候,前端会反复地 follow 设计图的改动,降低前端程序员的工作体验,有时甚至会引发员工间的矛盾。
Design First:设计对组件逻辑理解较为模糊,难以涵盖组件所有状态的样式,而为了枚举或描述组件的所有可能状态,常常过于繁琐,会有很多长得很像的重复原型图,而缺斤短两的原型图,也容易影响前端工程师的工作体验,甚至会提升责任推卸的可能性 (前端觉得有些组件状态设计图没有给到,就停工了,将责任推卸给 UI)。
之后我们可以看到,如果不改变协作模式和工具,这个 dilemma 是无法消除的。
前端应该如何更高效地获取设计的上游更新?
设想这样一个场景,公司有一个完整的设计团队,它们有时会更新一些组件的图标,当这些图标得到更新后,设计团队可能会手动通知前端工程师,前端工程师再下载到新的 icon 文件,将该文件放入仓库的 src/assets 下,再 push 代码,触发流水线,部署完毕后,icon 得到更新。
上述的过程显然是十分低效的,设想这样一种情形,全公司有上百个网站,几乎每个网站都用到了公司的 logo,但绝大多数网站都是将该 logo 放入 src/assets 这样的形式来部署的,那么当公司更新 logo 的时候,就需要所有代码仓库都更新该 logo,浪费很多团队,很多人的时间,并且更重要的是,公司 logo 的全量更新成为了一个漫长的过程。
除了上面这个例子外,还有很多例子,比如设计经常会给原型图做一些修改,每次修改后,如果我们希望足够敏捷,那 UI 就会当场通知前端,前端再打开 Figma 之类的软件和 VSCode 等开发工具,完成了更改 (更多时候,前端还需要仔细检查到底是哪里更改了,有时需要和 UI 进行同步沟通),在这个场景下,前端像是被 UI 牵着鼻子走的工种,长此以往,前端会觉得自己的工作没有价值,引发更深层次的问题。
那为了防止这样的现象,我们索性牺牲敏捷性,每个月迭代一版,前端统一更新 UI,但这样又抛弃了 Web 的优势之一:用户使用的应用永远都是最新的,在讲究快速迭代的环境中,这种方式越来越少见,一个例子就是现在越来越多的 Web 应用忽略了 版本号 这个概念,因为只要能够很好的追踪 commit history,并规范好 commit message,版本号 这个概念其实也已经变得比较鸡肋,它更多是桌面时代的产物。
设计图中可复用的概念与元素,如何很好的传达给前端?
成熟的设计团队,往往会给有自己的设计系统,会在团队内部沉淀一些复用的概念与元素出来,比如,规定所有卡片组件的 box-shadow 都是同一种格式,规定调色板的基础色号有哪几种,字体大小有哪几级,但这些信息往往并不能在原型图层面很好的展现出来,而 UI 也很少会将这些概念很好的传达给前端,前端也觉得自己没有义务理解这些设计层面的概念,进一步加深了两个工种的分裂。
UI/UX 和 前端工程师之间的概念往往并不互通,而互相也觉得自己并没有义务去了解对方专业中的知识,但日常的协作又有极多的的深度交织,UI/UX 是最了解设计里面的逻辑和复用的,但真正实现逻辑和复用的却是前端工程师。这种职能的错配和重叠是问题的根源所在
设想这样一个情景:一个 Web 应用起初的设计,并未把主题色更换考虑在内,而 UI 团队内部有基础调色板,很多组件都共用一些基础色号,但并未在原型图中展示这些信息,事实上前端工程师也不关心这些,这就导致了几乎所有前端代码中,组件的颜色都是 hardcoded 的,并未体现出逻辑性和复用性,然后过了两个月,UI 团队决定支持主题色更换,于是前端团队又面临着巨量的体力活。
既然 UI 已经完成了样式的设计,为什么前端仍然需要重新实现一遍?
设计师给出原型图,前端再实现一遍,这很契合我们往常的经验,但是仔细思考会发现这是很荒诞的,这就像游戏行业的 建模师 建好了人物模型后,游戏开发者竟然还需要在游戏中重新实现一遍模型。
设备的尺寸布局,responsive 排版方式,这些层面的设计,按理来说应该由 UI/UX 来把控,可事实上却是由前端工程师把控的,前端工程师似乎承担了太多设计层面的 实现任务。
就像上文提到的,造成这四个 UI/前端 的协作困局,根本原因在于 职能的错配和重叠,两个工种深度耦合,互相牵制,用一个图概括就是这样:
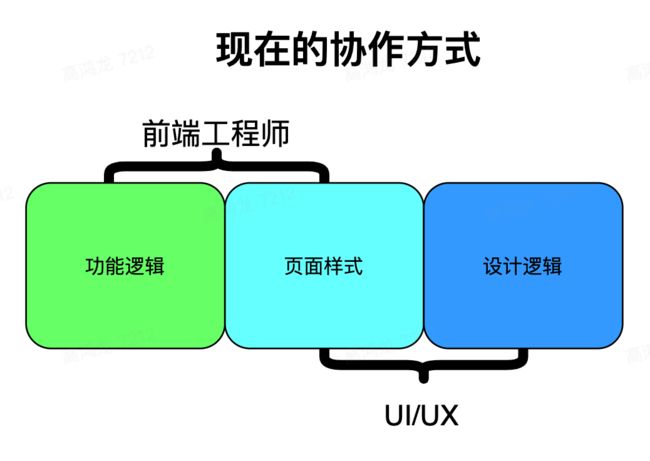
在页面样式这部分,工程师与设计师都参与了进来,这部分就是两个工种的 职能重叠部分,重叠的部分带来了大量的重复劳动与沟通成本。
为了彻底解决上面的问题,我们首先将 职能重叠 的部分尽可能减少,从情理上讲,页面样式 这块工作应该归属于 UI,而前端工程师只需要负责 功能逻辑 即可,这样两个工种的工作就正交了:
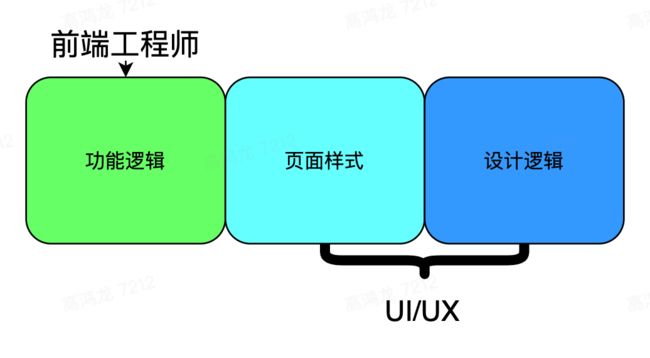
接下来我们需要思考的问题是 为什么当下的工具和生态不允许这样的分工方式?
从工具角度来说,目前 UI 用的工具以 Sketch,Figma 为主,它们都是比较好用的图形化设计软件,都支持组件设计,也支持一定的复用逻辑,原型图也往往直接能够看到元素的 css,这样看起来似乎 前端工程师 只需要无脑复制粘贴 css,就可以复制出一个一模一样的页面了,
但真实情况并不是这么简单,一方面就像上文提到的,直接复制粘贴 css 无法在前端代码层面体现出设计的复用逻辑,而且原型图的 css 往往采用绝对定位,实际的 css 要考虑 responsive,多设备适配等问题,并不能直接搬过来用,所以这条路事实上行不通。
根本原因在于 UI 工程师是在白板上进行设计,而不是在真实的组件上进行设计。
UI 工程师往往都在 Sketch 等软件提供的白板上用各种按钮,图形去拼接出图,这个东西和前端的环境完全分离,做的工作完全不能应用到实际的组件上,一方面我们没有提供给 UI 工程师工具让其将设计应用于某组件上 (你总不能期望 UI 工程师打开 VSCode,从 git 拉代码吧),一方面前端工程师的组件也往往是作为一个 npm package 里面的一个 submodule 存在的,
因此,我们事实上需要一种 UI 工程师和前端工程师互通共享的工作环境,在这个环境中,前端工程师可以实现组件的逻辑,UI 工程师可以直接给组件骨架添加设计样式。
也就是说,次世代的前端开发工具,应该是同时面向 设计师 和 工程师 的,而同时也是 面向组件 的。它应该是一个对于设计师用户友好的平台,可以在这个平台上看到工程师已经产出的,带有逻辑骨架的组件,并且在平台上为这些组件添加样式,有了这样的平台,对于组件的开发,前端工程师只需要关心逻辑即可,剩下的样式工作可以全部交由设计师来完成,这样就实现了两个工种职责的隔离,双方都只需要负责好自己的事情,不需要互相替对方去实现一些想法。
所以概括一下,我认为未来的协作方式应该是这样:
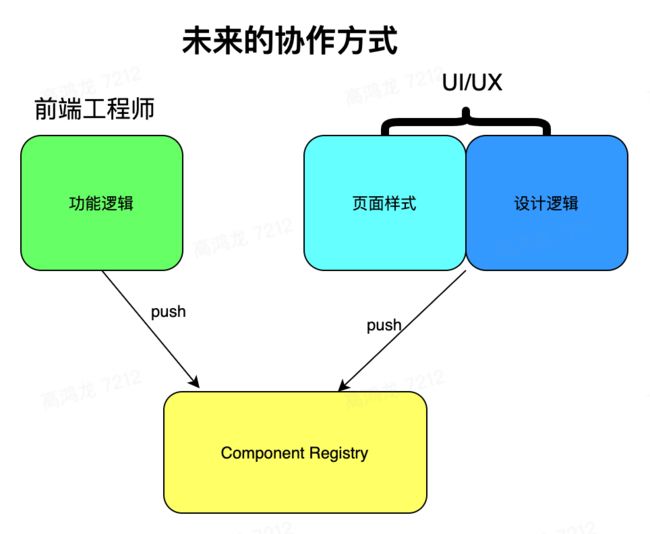
上面这张图中,前端和 UI 都共享一个 Component Registry,也就是 组件注册中心,它一方面向前端工程师暴露代码接口,一方面又向设计师暴露设计面板,在这个 组件中心 里,一个 team 可以共享的看到所有组件,这是个统一的协作平台。
一点小想法:目前 AI 已经可以帮我们设计 Logo 了,日后也可以帮我们设计组件的样式,AI 可以学习一套组件的风格,并且将这种风格自动的应用到其它组件上,,日后这样的方式或许可以帮我们快速地得到设计统一美观的组件库。
对于前端来讲,代码的 commit history,版本控制,它们的 scope 都应该是 组件,开发是针对组件的,而 UI 则可以打开一个组件,然后设计套件会自动将组件的一些基本元素提取出来,为 UI 提供图形化的设计面板,完成设计后,转化成 css in js 之类的东西,最终转化成一条 commit history 提交到组件中。
从图中看到,前端和 UI 都是在向 组件中心 push changes,而设计也可以在设计平台中定义一些全局变量,一些复用的样式,组件也会依赖于设计团队的这些设计变量,于是设计团队可以通过统一更改变量来达到全局组件样式风格切换的效果,到这里为止,设计层面的复用和逻辑职能,甚至是 responsive design,多设备尺寸适配,都收敛到了设计师手里,因此设计师还需要学习流式布局,网格系统等概念,这从职能上看也更为合理,也更容易让设计师来发挥更大的能力。
同时,因为组件在功能逻辑层面,前端已经做好了 composition,它们已经实现了组件之间的相互依赖关系,所以 UI 无需关心组件之间的依赖关系,当一个子组件的样式更新后,在设计套件中,父组件也能看到更新后的子组件,组件逻辑的依赖关系,收敛到了前端手里。
这种协作模式,我称为 面向组件的研发模式,而目前,像 https://bit.dev/ 之类的产品,已经在实践这个想法,但是它们只是给工程师提供了一个面向组件的研发平台,还未给设计师提供设计平台,这是这类产品目前欠缺的地方,很可能也是它们未来的发展方向。
读者可以回顾一下之前讨论的四个问题,我们会发现在新的协作模式下,四个问题都得到了较好的解决。
组件这个层级的协作方式发生改变后,页面级的组件 Composition 问题,也就是由这些组件组合成一个完整的页面时,也可以同样地在这套系统上完成协作,只需要把页面当成一个复合程度很高的组件即可,实际的页面内部会有很多数据 fetch 和处理逻辑,这块的处理方式,在下文中会有提到。
数据交互困境
桌面应用诞生的最早期,客户端是可以直接连接数据库的,在当时,关于怎样获取数据,怎样存数据的逻辑,是放在客户端负责的,之后 Web 的发展,让更多的逻辑放在了后端,后端负责连接数据库,并且将更简单规范的 HTTP (以 Restful 为代表) 请求转换成对应的 SQL 等数据库语句,在后端完成和数据库的交互 (此处的数据库指广义的数据库,可能包含各种中间件,各种形式的存储等),前端只需要消费这些简单的接口即可,看起来是降低了前端的负担 (无需思考如何和后端的数据库等服务交互,后端已经封装好了)。
但在实际的业务场景下,以 Restful[1] 为主的这种后端 API 思路仍然出现了很多问题,我们发现实际的前端场景下,前端往往需要对数据有更精细的控制:
试想这样一个情景:前端显示一个评论列表,这里只用到了每个人的头像和昵称,但是后端提供的 profile 接口却会连着其它的手机号,个性签名等等一系列信息全部返回了,这个时候后端就返回了很多无用信息。
上面的场景说明,如果后端将用于操纵数据的接口封装的抽象层级过高,会出现无法满足前端的灵活使用的问题,除此之外还有处理一对多关系,比如一个班级里面包含很多学生,students 是 class 的一个属性,那使用 GET 请求请求 class 的时候,是否应该返回它的子属性 students 呢?如果前端希望能够控制,那往往又需要引入新的 query parameter 来控制,这又增加了协商成本和文档成本。
基于 Restful 的开发模式,实际体验往往是前端仍然需要去看接口文档,为了让接口有灵活性,需要引入很多自定义的 query params,由于接口本身的灵活性差,导致前端程序员需要思考使用什么样的顺序和方式调用接口,才能实现一个功能,很多时候前端需要被迫拼接,堆积接口调用,甚至会出现在前端手动递归调用后端接口获得一个树状文件夹数据这种现象,可见这种方式是有很大问题的。
除此之外,普通的后端 CRUD 接口,本身的实现很简单,但是由于前后端分离,语言也可能不同,导致前端遇到接口问题时,必须要和后端协商,后端再做出改动,真实情况是 让前端去学习后端 CRUD,并且直接对后端做出改动,比前端和后端协商来的效率高,根本原因第一在于 Restful 本身的灵活性问题,其次在于简单的后端查询业务由于和前端的业务深度耦合,这部分工作应该收敛到一个工种上,并且考虑到传统的后端 CRUD 的代码很大程度可以自动生成,
所以我们接下来要做的事可以总结为:把常规的后端业务实现的任务收敛到前端工种,并且通过更好的 API + SDK + P/F/SaaS 让常规的后端业务尽可能自动化+服务化,从而淘汰掉传统的后端 CRUD 工种,提升整个系统的效率。
回过头来想一下,如果后端希望暴露给前端一个安全的操纵数据的接口,使用 HTTP Path + Method 的这种方式显然不够强,关于数据关系模型是一个关于集合的数学理论,它在数学中一开始的描述方式是使用 关系代数[2] 这样的语言描述的,基于树状关系(HTTP Path 是一种树状的命名空间) + 方法(Get Post Delete Put 等) 的描述方式过弱,远远无法支撑实际的数据操作,
但直接使用 SQL 语言,一方面是安全性的问题(可以通过代理+一些权限验证方式解决,不是问题的关键),一方面是 SQL 语言这种模式和前端的语言环境太过割裂,前端被迫进行字符串拼接,与之相对的是 MongoDB 的查询语言,其和 javascript 语言的贴合度较之 SQL 要好很多,前端程序员可以用很自然的方式写出一个查询语句。
与此同时,基于 Restful 这样的模式,让很多的后端代码变成了非常简单的 CRUD 代码,很多代码就是为了将 restful 接口转化成 SQL 语句,大量的时间被耗费在了这些无聊的事情上,降低了开发效率,这些简单的操作应该被自动化。
在这样的困境下,GraphQL[3] 应运而生,它用一种更优雅的方式实现了声明式数据请求格式,相较于 Restful,它更像是 SQL 这种声明式的语言,从 Restful 到 GraphQL 的转变,对于前端来讲则是命令式到声明式的转变,从思考 "what do I need to get I want" 到直接思考 "what I want"。
但是仅仅依靠 GraphQL 还是没解决这两个问题:
Restful 时代的 CRUD 代码转变成了 GraphQL 的 resolver 代码,后端还是需要手动写,或者使用 codegen 工具来生成代码,仍然没摆脱样板代码的桎梏。
前端对数据的请求的状态管理:重复请求问题,数据依赖更新问题。。。
先讨论第二个问题,在前端的业务场景下,数据依赖可以分为两类:一类是纯前端的数据绑定,一类则是涉及到后端数据的绑定,状态的绑定也是前端这种响应式系统和转换式系统的最显要的差别,这是 Web 要处理的最核心的问题之一。
响应式系统(reactive system) 和 转化式系统 (transformational system) 的最大区别在于,前者更像一个状态机,输入与当前的状态才能决定输出,而转化式系统(典型例子如编译器) 则更着重的是输入和输出。Statecharts:a visual formalism for complex systems - ScienceDirect[4]
我们可以看到几乎所有前端框架,无论基于模板的,还是 jsx 的,都解决了一个核心问题就是状态之间的绑定,UI 状态和内部 js 变量的绑定等,数据之间是有一个依赖关系的,它们可以用一个依赖图表示。
鉴于 Web 的特殊性,我将状态的绑定分为 纯前端绑定 和 前后端绑定,前者的绑定只发生在前端,比如一个 js 内部的变量和 的 value 的绑定,而后者则涉及到前端状态与后端状态的绑定,比如,一个评论列表与后端的评论数据做绑定。
(更多的时候,程序员并没有把后者理解成一种绑定,因为目前的工具还是将这个过程作为一种主动 fetch 的命令式做法,没有像前端框架一样提供了简单的声明式绑定,这也是目前发展的不足之处,我认为未来前后端的绑定,也应该是像纯前端绑定一样简单,命令式,消除显式的 http 请求代码)
试想这样一个场景:一篇文章下面有评论列表,你在评论框中添加了一条评论,这时按道理来说,前端的 UI 列表与后端的评论数据应该是双向绑定的关系,评论列表应该立即得到更新,但这时前端程序员的做法很可能是显式的写一个逻辑,当新建评论后,手动重新请求评论 api,然后得到更新,这种做法像极了使用原生 DOM 和 js 处理前端 UI 和数据的绑定关系,手动维护状态,手动调用 DOM 接口,从这个角度看,两种绑定的发展路线是类似的,只不过 前后端绑定 的相关工具是最近两三年出现的。
处理前后端绑定的框架,代表性的有 React Query[5] (2019 年建仓) 和 Apollo GraphQL Client[6] (2016 年建仓)。它们解决的问题都是使用声明式的语法,处理前后端绑定的场景,都基于 GraphQL,它们往往被人称作数据层的状态管理工具,为了更好的理解本文意图,我将其称为 前后端数据绑定工具。
在上文的 设计/前端协作困境 中提到的基于组件的协作流,只是对单组件的协作,而一个复合型应用需要将这些组件组合起来,填充到页面中,这个场景下多了两个要解决的问题:
组件和后端数据的绑定问题。
纯前端绑定。
前后端绑定方式
拿一个最简单的例子,一个填写个人信息的表单,在传统的 Web 思路中,如果使用框架的话,会将一个组件内部的 r 和表单的 的 value 属性做绑定,当用户点击 "提交" 按钮时,执行一个 onSubmit 方法,方法内部将数据作为 body,一个 POST 请求将数据传给后端。
这样做没问题,但它会阻扰我们理解问题。使用"面向绑定"的方式理解这个问题的时候,这个问题其实变得很简单,我们将后端的个人信息数据与组件内部的状态做绑定,当用户点击提交前,绑定处于 out of sync 的状态,点击 "提交" 进行同步,进入 sync 状态。这样理解问题,前后端的数据交互问题就变得清晰明朗了起来。
那么与此同时,因为页面的右上角可能有你的头像,那个头像的组件也和你的个人信息的子属性 avatar 绑定,这时,当表单进行 sync 后,由于头像组件也绑定了有依赖关系的数据源,所以数据层会自动更新头像:
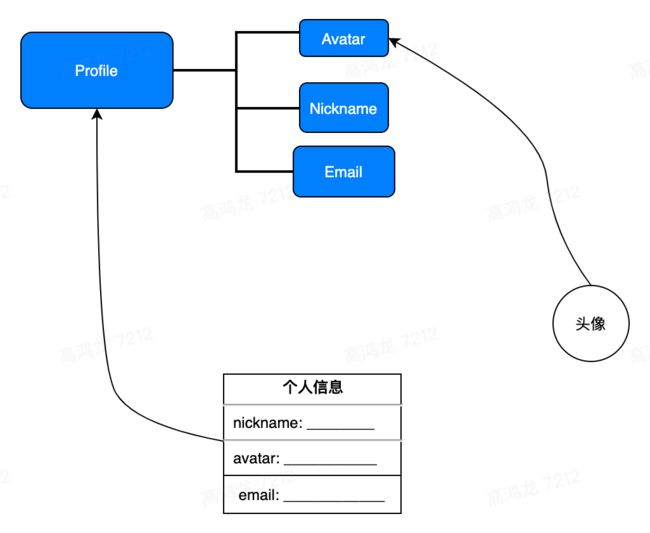
上图中,表单和 Profile 做了绑定,头像和 Avatar 做了绑定,当个人信息点击提交后,数据状态管理层会自动检测到 Avatar 组件所依赖的数据的父节点发生了 Mutation,从而自动触发 refetch,获得更新后的 Avatar。
如果我们能够保证所有的数据源的请求都是以 GraphQL 的话,那么我们可以使用 GraphQL Query 作为前后端数据绑定的声明式语法,而根据对 GraphQL + Endpoint 构成的实时数据图依赖分析,可以实时地解决数据的依赖变化问题,这个过程可以直接在前端完成。在 React Query 中,由于其本身的设计是后端无关的,数据间的依赖关系是通过手动维护 query 的命名数组进行的,尚未达成自动解决依赖的问题。
为了更好地在下面讨论组件,我们先将组件从复用性的高低可以分为两类,一类是 通用型组件,一类是 自治型组件。 前者尽可能地让自己的能力通用化,自己内部不维护网络请求等信息,而是根据传入的 props 来动态地决定与后端数据的依赖,以及数据源和组件内部状态的绑定关系,而自治型组件通常可以独立使用,其自己内部实现了网络请求等逻辑,但是通用型较差,通常只能实现特定功能,类似于 iframe。
举个例子,继续拿表单组件为例,通用型表单组件从外界接受数据源,以及请求后的数据的属性与组件内部的对应关系,除此之外,往往还需要提供一个数组用来生成相应的表单列表,数据从哪来,数据和表单怎么对应,表单的 validation 函数,都从外界传入,组件本身只实现逻辑框架和设计样式。
而对于自治型表单组件,很可能是一个飞书投票组件,从飞书小程序中生成一个组件实例,就可以直接使用,它内部实现了相应的数据逻辑,用户可以直接填写,就可以在飞书投票后台看到该组件收集的投票信息。
对于纯前端的绑定来说,本质上还是组件的树状结构组合,很多页面可以通过代码的方式写成一个大组件,不管是单一功能型组件还是页面,都可以统一的视为组件,使用统一的方式看待和处理。
再来讨论上面的第一个问题,如何解决后端程序员仍然要写很多 GraphQL Resovler 代码浪费很多时间,显然,从数据库的 schema 出发,是可以生成一些默认的 Rosovler 代码的,但是需要程序员手写的原因在于,默认生成的 Resolver 代码往往缺一些和具体业务相关的东西,基于此可以使用约定大于配置的思路,为用户提供默认的 Resolver 能力,并给用户提供自定义的 Custom Resolver 的接口,在这个方向上,Hasura[7] 已经做了一些工作,它们也是从数据库出发,搭配权限验证策略,自动生成统一的 GraphQL API 网关,供各种形式的前端来调用,大幅简化传统的 CRUD 代码:
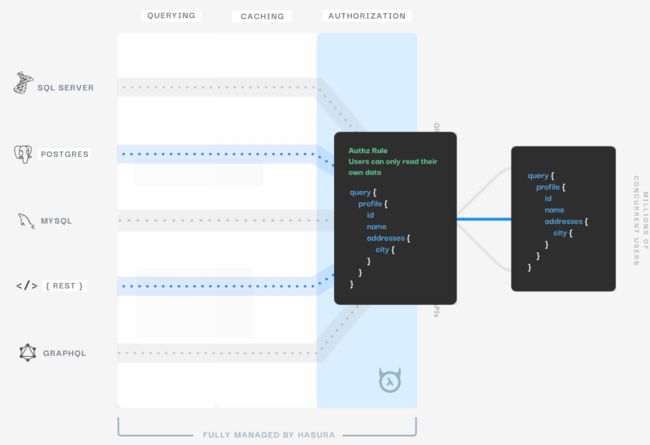
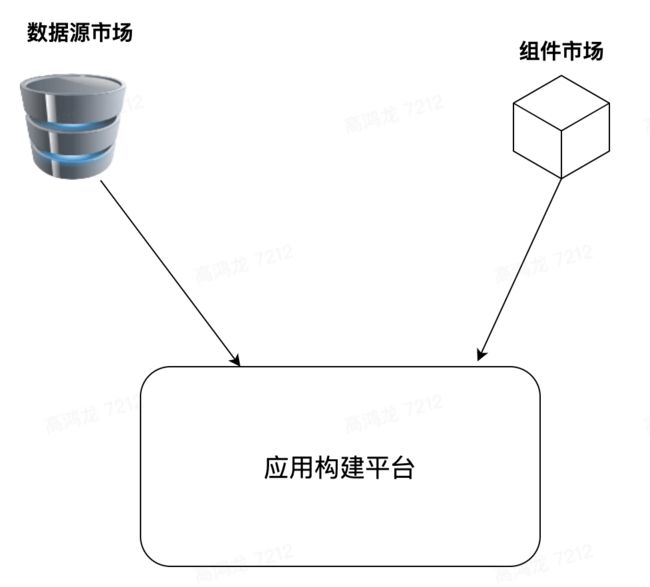
基于此,我设想未来的 Web App 的开发,可能会有很多的数据源提供提供商,比如像 OneGraph - Build Integrations 100x Faster[8] 中,将常用的公开 API 转化成统一的 GraphQL API 网关供调用,这些数据源会像是一个 Market,组件有组件市场 (Component Market),而数据源也有数据源市场 (Datasources Market)。
对于数据源市场来讲,每个人都能在其上发布数据源,可以像 Github 一样做私有付费(Pay For Privacy) 的策略,和组件一样可以供其它人消费,然后很多程序员可以快速借助统一的数据源和组件市场搭建出一个功能完整的现代 web app:
数据源平台将会依托于 Serverless 提供的基础能力,为泛开发者提供一个类似于 AWS Lambda 的函数注册中心,提供几种基本的数据交互场景的定制能力,开发者可以直接使用云 IDE 完成一些轻量的函数开发和更新,去填补单纯根据 Schema 生成的 GraphQL Endpoint 能力的不足,架构设想图如下:
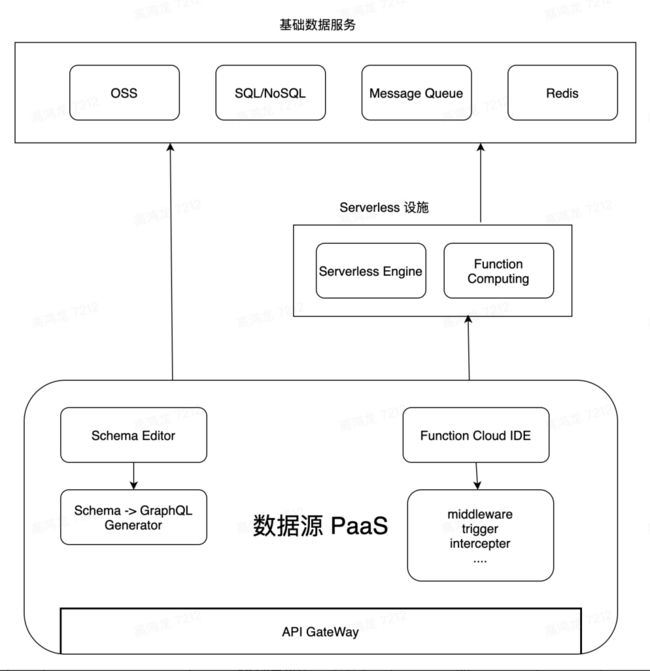
数据源平台会依托于基础存储服务和 Serverless 服务,借助在线的 Schema Editor 来编辑关系型数据 Schema,借由 Schema -> GraphQL Generator 自动生成 GraphQL Endpoint,再由平台提供的函数计算接口,在在线 IDE 中完成函数的逻辑的开发,这些函数可以在数据源中扮演 middleware,trigger,intercepter 等的角色,为数据源能力提供一些补全和增强。
数据源平台会作为现代 web 开发的后台的最高层次抽象,现代的业务侧开发者往往只需要在数据源平台上进行简单的操作即可配置出数据源供前端消费。
有数据源 PaaS 的支持,传统的 CRUD 工作可以很大程度消除,并且将一些剩余的任务收敛到前端(事实上相当于前端与 CRUD 后端工种合并了,但由于 CRUD 的工作大部分被自动化了,所以我们姑且仍然称这种具有全栈 Web App 开发能力的工种叫做"前端")
上面这是一种思路,除此之外,还有将服务端与客户端代码放在一起的开发模式,典型例子如 Blitz[9],它也遵循同样的思路,代码中没有显式的 http 调用,直接通过函数调用的方式直接对数据库做 Query,这样的优势是前后端合并,但是缺点还是有些明显:由于没有 GraphQL 这一层的转换,可能会声明过多的 Query 函数,它将处理 Query 复用的责任迁移给了程序员,并且一个数据源 对接 多终端的场景不太合适,后端和前端的绑定过深,不易抽取出数据源,如果移动端 App 和网页都依赖这个数据源,使用这种方式不太好处理前后端的解耦,个人认为这种方式在前后端聚合程度较高,且只有单一客户端(比如只有 Web,没有移动端 app)的情形下比较适合,适用场景较窄。
构建困境
DevOps 平台是一个资源消耗大户:每当应用仓库的 release 分支发生 commit 的时候,往往就会触发流水线的测试,构建,部署等一系列运维操作,而目前的生态,前端的构建涉及到依赖的拉取,依赖图分析,打包依赖,打包产物优化等步骤,一次完整的构建花费的时间可能是分钟级的:

上图给出了目前 Web 应用构建所要经历的步骤,在敏捷开发的场景下,如果 release 分支经常得到更新的话,流水线将经常阻塞,而且如果是仅仅是更新了某个包的版本,或者更新了 readme,或者是修改了源码中的变量命名,就需要全量的进行上图中繁重的工作的话,这无疑是存在很大的算力和 I/O 浪费的。
我们上文曾提到以组件为中心的协作方式,在那种协作方式下,我们注重组件的快速迭代,而一个 web app 则会重度依赖上游的各种组件,总结一下,目前上图的这种构建/发布模式存在这几个重大问题:
修改一个文件中的一行代码,触发全量构建,大量算力,I/O 浪费。
上游的更新无法触发下游流水线更新,或者说下游无法 "观察" 上游的更新。
对于第一个问题刚才已经解释过,第二个问题可能更为严重,下面解释一下:
包和包之间的依赖,是一个 有向无环图,在 npm package 这种管理模式下,一个包得到更新,往往依靠迭代新的版本号来解决,示意图:
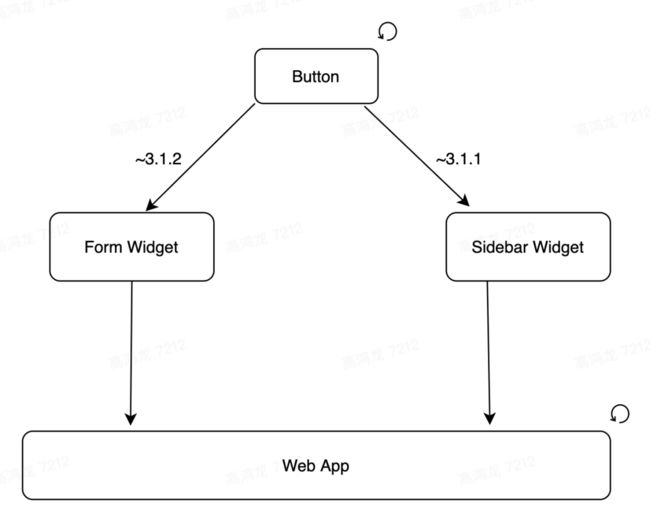
上图中,Web App 依赖于 Form Widget 和 Sidebar Widget ,而这两个组件又依赖于更基础的 Button 组件,而当 Button 组件得到更新之后,比如版本从 3.2.1 迁移到了 3.2.2,这时候 Web App 应用本身是不会收到这个通知的,它必须手动重新运行一次流水线,才能将更新的依赖 3.2.2 打包进构建产物中。
在上面的 Button 更新的场景中,我们自然希望所有依赖 Button 的 Web App,在 Button 得到更新后,立即能够使用新的 Button。
npm 这种基于版本的发布更新方式,虽然 semantic version 本身能够起到对包的兼容性等的基本管控,但它本质上是一种君子协定,包不遵守也没办法,其实,我在上文中曾提到现代的 Web App 倾向于 "无版本号化",只要源码改动能够以极低的成本,极快的速度触发产品更新,那版本号这种方案就可以废弃,如果我们能够很容易的追溯过去任何一个组件在任何一个时间点的状态,那所谓的版本号的意义只是用来声明 break changes 的发生节点。
前端开发在很多场景下被迫使用 monorepo,也是使用 semver (semantic version) 作为迭代的方式的失败证明。若快速迭代一个包,则版本数爆炸增长,若想让版本号慢速增长,则需要累计更新,又失去了敏捷性,这看起来是一个无法调和的矛盾 (关于 monorepo 和其它的替代方案的讨论,会在下面一个 section 深入讨论)。
造成这种构建困境的源头,其实和历史包袱有关,那就是纯浏览器端的 module load 一直在过去都被认为是一个还没有得到良好覆盖的 es6 特性,但是截至目前,es module 在除了 IE 之外的其它主流浏览器中,已经得到了良好的覆盖:
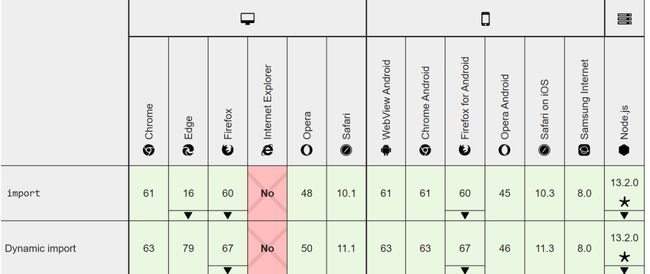
之前基于 webpack,rollup 等工具的生态,是为了既能让开发侧可以享受 module 带来的好处,又能在浏览器侧加载单文件提升加载速度和兼容性,如果我们不再考虑 es module 带来的兼容性问题,那么我们就可以开始进行对 esm 的使用和验证,相关的工具已经不断涌现,典型的例子如 Vite[10] ,Snowpack[11] 等,这类构建工具可以简称为 bundless build tool。
但是目前,拿 Vite 来说,它们仅仅是在开发模式下启用无打包模式,生产环境仍然使用打包,原因在于目前关于生产环境中使用 esm,一些测试结果表明仍然会影响性能,可汗学院曾尝试进行 esm 的全量迁移,即便是在 HTTP2 的加持下,加载速度仍然变慢了:Forgo JS packaging?Not so fast (khanacademy.org)[12]
但是同样也有一些数据表明,在应用本身的体量较小的情况下,全量使用 esm 是完全 OK 的:ES modules in production:my experience so far | Bryan Braun - Designer/Developer[13]
在可汗学院的博客中提到,全量 esm 的性能下降原因主要来源于 HTTP2 的一些加载 issue 和 多个小文件的解压缩开销增大,最后的结果是使用 esm 使得资源下载时间从 0.6s 涨到了 1.7s,最后得出的结论是目前仍然推荐使用 bundle 用于生产。
但是其测试并未考虑 esm 能带来的更多的优势,在这些新的优势和网络协议的发展下,esm 之后做到基本和 bundle 持平或者接近,个人认为是完全有可能的。
esm 能带来的潜在优势如下:
全局依赖缓存。
大幅降低流水线构建的计算和 I/O 负担,甚至可以跳过构建这个步骤。
上游更新后,用户加载页面时,可以直接加载更新后的组件的代码,达到了真正的敏捷更新。
可以看到后两个问题是我们上面提到过的,如果使用了 esm,由于代码的加载是直接通过 import 的方式,那么当上游的一个组件更新后,浏览器侧就可以直接加载到更新后的组件的代码,完全不需要触发任何依赖了该组件的项目的流水线,而且当应用更新的时候,如果是打包模式,用户需要全量加载新的 js 资源,但是在 esm 场景下,用户只需要重新加载更新后的那一小部分即可。
很多 Bug 的发生都是局部的,比如 Bug 发生在组件内部,当修复了这些 Bug 后,工程师只需要将更新 push 到组件注册中心,即可完成 Bug 修复,无需触发下游无数的 app 的流水线。
而下游如果想锁定上游的版本,也可以直接用 commit hash 锁定,这样就不会加载到更新的组件版本,保证了下游的一致性。
第一条:全局依赖缓存 是指,不同的域名,应用之间,有很多的包都是公用的,比如 react,这些包加载了一次之后,就不需要再次加载了,随着用户使用浏览器的增多,本地的缓存就会变得更多,用户访问新网站后,需要加载的新依赖就会变得更少,而这的前提是这些网站都使用同样的 CDN,这种 CDN 应该专为浏览器侧的 esm 做了优化,支持 HTTP2/3 等新的协议, 这种全局依赖缓存的建立,会进一步缩小 esm 和 bundle 之间的性能差距。
第一个将这个思路 built in mind 的,应该是 deno,它原生支持 http import,为服务侧基于 cdn 的 import 的开发做了准备,与之配套的就是相关的开发套件,比如 VSCode 相关插件的支持,以及 CDN for module,对于这种 CDN,已经有了类似的产品:Skypack: search millions of open source JavaScript packages[14]。
个人大胆预测一下,五年之后的 web 开发,不管在 dev 还是 prod,不管是 server 还是 client,都会采用 CDN for module + http import 这种模式,带来前端的新一轮敏捷革命。(现在已经开始了 )
代码管理困境
没有包管理的时代,人们的应用都包含了全部代码,有了包管理后,人们倾向于每个包都有自己独立的 git 仓库来管理,但是有时候又想将一些包放在一起来开发,于是又有了 monorepo:

这样搞来搞去其实没什么意思,都没有根本解决问题,我们引入 Monorepo 是因为我们想要同时对一些包做改动,然后统一发布更新,如果分开,程序员需要每天在不同的仓库中辗转,并且需要不断地 publish&update 才能在另外的包用到更新的包,但是引入了 Monorepo 后,commit history 就混入了各种包的 commit,不方便追踪某个模块的改动,与之相对应的一种代码管理方式是以 Git - Submodules (git-scm.com)[15] 为代表的子仓库模式,父仓库可以依赖于其它的子 git 仓库,在父仓库做的 commit 不会进入到子仓库中,同时在开发父仓库的时候,又可以修改子仓库的代码,甚至进行 commit,它很好的平衡了 作为依赖引入 和 想要随时修改 的两个需求,实测好用。
可惜的是在 npm 这样的生态下,发布的东西和源码可以不是一种东西,发布的包也不再是一个 Git 仓库,其它包引用某包的时候,先不谈有没有 push 某包的权限,本身就无法当作 git submodule 来使用,即便把代码 push 到源 repo 了,也不会触发 package 的更新,还需要手动发布,这个和 Go 语言的基于 git 仓库 + git registry 的依赖管理方式形成了鲜明的对比,个人认为这也是 npm 设计的一大败笔。
我认为新的包管理模式,应该是和 Git 仓库绑定的,参考 Go 语言,我们使用 Git 来进行代码的管理,发布到注册中心的包,仍然是一个 Git 仓库,只不过是一个 remote history,当它作为依赖拉取的时候,会连并构建产物一并拉取,(git clone --depth 1 拉取最新的 snapshot) 而如果想要即时修改该包并且 push 更新,则可以使用提供的新的命令行工具进行 dependency 到 git submodule 模式的转化,转化后,会变成 git submodule,你就可以即时的修改这个包了。
而构建步骤和 semver 相关的东西,可以深度集成流水线和一些 tag,下游使用上游依赖也仍然可以锁定版本,这些都可以解决。
所以我认为未来的包管理中心可能是:
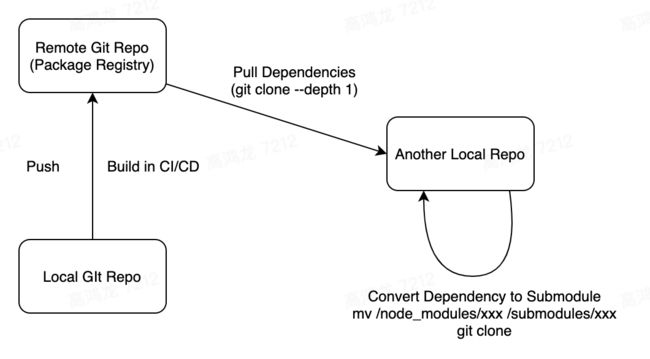
所有的包在 registry 中都是作为一个 git 仓库存在的,而本地开发的时候,既可以将其作为依赖,也可以将其一个命令转化为 git submodule,这样就可以灵活的协调依赖和快速修改反馈之间的矛盾了。
而这个包注册中心,应该和上面所说的组件注册中心其实是一个东西,每个组件也都是一个 package,后者是前者的子集。
总结
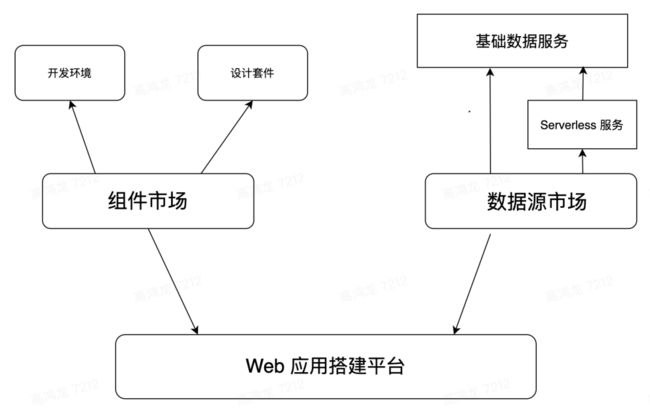
把上面提到的技术设想画成一张大图:
参考资料
[1]
Restful: https://restfulapi.net/
[2]关系代数: https://en.wikipedia.org/wiki/Relational_algebra
[3]GraphQL: https://graphql.org/
[4]Statecharts:a visual formalism for complex systems - ScienceDirect: https://www.sciencedirect.com/science/article/pii/0167642387900359
[5]React Query: https://react-query.tanstack.com/
[6]Apollo GraphQL Client: https://www.apollographql.com/docs/tutorial/queries/
[7]Hasura: https://hasura.io/
[8]OneGraph - Build Integrations 100x Faster: https://www.onegraph.com/
[9]Blitz: https://blitzjs.com/
[10]Vite: https://vitejs.dev/
[11]Snowpack: https://www.snowpack.dev/
[12]Forgo JS packaging?Not so fast (khanacademy.org): https://blog.khanacademy.org/forgo-js-packaging-not-so-fast/
[13]ES modules in production:my experience so far | Bryan Braun - Designer/Developer: https://www.bryanbraun.com/2020/10/23/es-modules-in-production-my-experience-so-far/
[14]Skypack: search millions of open source JavaScript packages: https://www.skypack.dev/
[15]Git - Submodules (git-scm.com): https://git-scm.com/book/en/v2/Git-Tools-Submodules
作者:牛岱 字节跳动 Web Infra Engineer
https://www.zhihu.com/column/p/389935233
- EOF -