Redis缓存应该如何应用?
何时使用Redis缓存?
日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求或者数据读写频繁
比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
Redis 主要以下两个应用场景
- 存储 缓存 用的数据;
- 需要 高速读/写 的场合使用它快速读/写
缓存
在日常对数据库的访问中,读操作的次数远超写操作,比例大概在 1:9 到 3:7,所以需要读的可能性是比写的可能大得多的。当我们使用SQL语句去数据库进行读写操作时,数据库就会去磁盘把对应的数据索引取回来,这是一个相对较慢的过程。
如果我们把数据放在 Redis 中,也就是直接放在内存之中,让服务端直接去读取内存中的数据,那么这样速度明显就会快上不少,并且会极大减小数据库的压力,但是使用内存进行数据存储开销也是比较大的,限于成本的原因,一般我们只是使用 Redis 存储一些常用和主要的数据,比如用户登录的信息等。
一般而言在使用 Redis 进行存储的时候,我们需要从以下几个方面来考虑:
-
业务数据常用吗?命中率如何?如果命中率很低,就没有必要写入缓存; -
该业务数据是读操作多,还是写操作多?如果写操作多,频繁需要写入数据库,也没有必要使用缓存; -
业务数据大小如何?如果要存储几百兆字节的文件,会给缓存带来很大的压力,这样也没有必要; -
在考虑了这些问题之后,如果觉得有必要使用缓存,那么就使用它!使用 Redis 作为缓存的读取逻辑如下图所示:
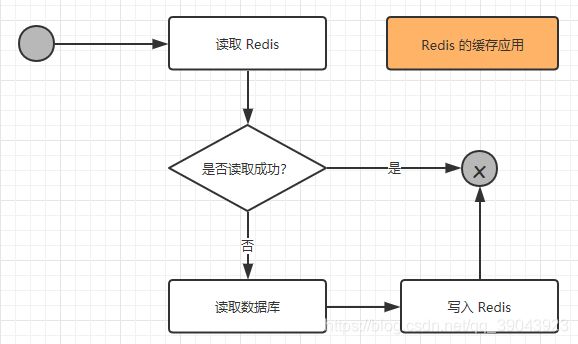
从上图我们可以知道以下两点:
- 当
第一次读取数据的时候,读取 Redis 的数据就会失败,此时就会触发程序读取数据库,把数据读取出来,并且写入 Redis 中; - 当
第二次以及以后需要读取数据时,就会直接读取 Redis,读到数据后就结束了流程,这样速度就大大提高了。
从上面的分析可以知道,读操作的可能性是远大于写操作的,所以使用 Redis 来处理日常中需要经常读取的数据,速度提升是显而易见的,同时也降低了对数据库的依赖,使得数据库的压力大大减少。
分析了读操作的逻辑,下面我们来看看写操作的流程:

从流程可以看出,更新或者写入的操作,需要多个 Redis 的操作,如果业务数据写次数远大于读次数那么就没有必要使用 Redis。
关于使用内存存储数据,我知道谷歌好像就是把所有互联网的数据都存储在内存条的,所以才会有如此高质量、高效的搜索,但它毕竟是谷歌
高速读/写的场合
在如今的互联网中,越来越多的存在高并发的情况
比如天猫双11、抢红包、抢演唱会门票等,这些场合都是在某一个瞬间或者是某一个短暂的时刻有成千上万的请求到达服务器,如果单纯的使用数据库来进行处理,就算不崩,也会很慢的,轻则造成用户体验极差用户量流失,重则数据库瘫痪,服务宕机,而这样的场合都是不允许的!
所以我们需要使用 Redis 来应对这样的高并发需求的场合,我们先来看看一次请求操作的流程图:
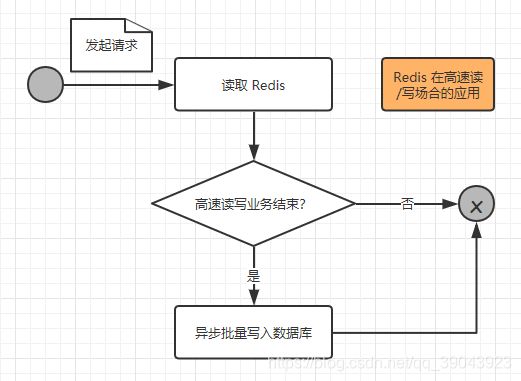
我们来进一步阐述这个过程:
当一个请求到达服务器时,只是把业务数据在 Redis 上进行读写,而没有对数据库进行任何的操作,这样就能大大提高读写的速度,从而满足高速响应的需求;
但是这些缓存的数据仍然需要持久化,也就是存入数据库之中,所以在一个请求操作完 Redis 的读/写之后,会去判断该高速读/写的业务是否结束,这个判断通常会在秒杀商品为0,红包金额为0时成立,如果不成立,则不会操作数据库;如果成立,则触发事件将 Redis 的缓存的数据以批量的形式一次性写入数据库,从而完成持久化的工作。
主要内容转载自Redis【入门】就这一篇!
Redis配合mysql如何应用?
字符串使用场景
缓存功能
典型使用场景:Redis作为缓存层,MySQL作为存储层,绝大部分请求的数据都是从Redis中获取,由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
开发提示:与MySQL等关系型数据库不同的是,Redis没有命令空间,而且也没有对键名有强制要求,但设计合理的键名,有利于防止键冲突和项目的可维护性,比较推荐的方式是使用“
业务名:对象名:id:[属性]”作为键名。
例如MySQL的数据库名为vs,用户表名为user,那么对应的键可以用"vs:user:1","vs:user:1:name“来表示,如果当前Redis只被一个业务使用,甚至可以去掉vs。如果键名比较长,例如”user:{uid}:friends:message:{mid}",可以在能描述含义的前提下适当减少键的长度,例如采用缩写形式,从而减少由于键过长的内存浪费。
计数
典型应用场景:视频播放数计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增1。Redis可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他数据源。
开发提示:实际上一个真实的计数系统要考虑的问题会很多,防作弊、按照不同维度计数,数据持久化到底层数据源等。
共享Session
典型应用场景:用户登陆信息,Redis将用户的Session进行集中管理,每次用户更新或查询登陆信息都直接从Redis中集中获取。
限速
典型应用场景:验证码接口访问频率限制,用户登陆时需要让用户输入手机验证码,从而确定是否是用户本人,但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。
哈希使用场景
缓存用户信息
相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对field-value对应每个用户的属性。
哈希类型和关系型数据库不同之处:
哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为其设置值(即使为NULL)。
关系型数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询开发困难,维护成本高。
三种缓存用户信息优缺点比较:
- 原生字符串类型:每个属性一个键
<优点>:简单直观,每个属性都支持更新操作。
<缺点> :占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以此种方案一般不会在生产环境使用。
- 序列化字符串类型:将用户信息序列化后用一个键保存。
<优点>:简化编程,如果合理的使用序列化可以提高内存的使用效率。
<缺点>:序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中。
- 哈希类型:每个用户属性使用一对field-value,但是只用一个键保存。
<优点>:简单直观,如果使用合理可以减少内存空间的使用。
<缺点>:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
列表使用场景
消息队列
Redis的lpush+brpop命令组合即可实现阻塞队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的"抢"列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
文章列表
每个用户有属于自己的文章列表,现在需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
开发提示
lpush + lpop = Stack(栈)
lpush + rpop = Queue(队列)
lpush + ltrim = Capped Collection(有限集合)
lpush + brpop = Message Queue(消息队列)
集合
标签(tag)
集合类型比较典型的使用场景是标签(tag),例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣就是标签。
开发提示:用户和标签的关系维护应该在一个事物执行,防止部分命令失败造成的数据不一致。
有序集合
排行榜系统
有序集合比较典型的使用场景就是排行榜系统,例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。
主要内容转载自Redis使用场景