深入浅出 Java FileChannel 的堆外内存使用
从一个线上系统 OOM 讲起
在一个风和日丽的下午(标准开头),突然收到用户紧急反馈,线上系统 IoTDB 查询卡住。经过众人一番排查,发现 IoTDB 在读取数据文件时使用到了 FileChannel,而 FileChannel 使用的堆外内存引发了系统 OOM。定位到问题之后,也成功帮助用户解决了问题。由这个线上问题,引出了本文的主题:FileChannel 中堆外内存的使用。
首先介绍一些背景知识:
1、关于 FileChannel:
- Java NIO 是一种基于通道(Channel)和缓冲区(Buffer)的 I/O 方式,而 FileChannel 是 Java NIO 中用于读写文件的通道。区别于传统文件 I/O 面向文件流顺序读写一个或多个字节的方式,FileChannel 是将数据从通道读取到缓冲区中,或者从缓冲区写入到通道中。
- 由于 FileChannel 对读取到缓冲区的数据具备随机访问的能力,因此非常适合于将文件中特定位置的数据块加载到内存中。在 Apache IoTDB 中,每次读取数据文件(即 TsFile 文件)往往只读取一个数据块(Chunk 或 Page),使用 FileChannel 是非常合适的。关于 Apache IoTDB 中对 FileChannel 的使用,可以查阅代码:org.apache.iotdb.tsfile.read.reader.LocalTsFileInput
2、关于堆外内存:
- 堆外内存是直接从操作系统中分配的内存,它不是 JVM 运行时数据区的一部分,也不是 JVM 规范中定义的内存区域,因此不受 Java 堆大小的限制,但仍然会受到本机总内存的大小及处理器寻址空间的限制,也可能导致 OOM 异常出现。
- 堆外内存的最大大小可以通过 -XX:MaxDirectMemorySize 设置;如果不指定,默认与堆的最大值 -Xmx 参数值一致。
- 可以在 Java VisualVM 中安装插件 Buffer Pools 来监控堆外内存。
为什么 FileChannel 要使用堆外内存?
FileChannel 中所有的 I/O 操作需要通过缓冲区进行,常用的是 ByteBuffer,而 Bytebuffer 有两种:
- HeapByteBuffer:堆上的 ByteBuffer 对象,调用 ByteBuffer.allocate() 分配,是在 Java 堆上分配的存储空间,属于 JVM 管理的范围。
- DirectByteBuffer:调用 ByteBuffer.allocateDirect() 分配,在堆外内存上分配存储空间,在 Java 堆上有一个堆外内存的引用对象。
如果使用 HeapByteBuffer,数据在 Java 堆上,操作系统处理时需要把堆上的数据拷贝到操作系统里(JVM 运行内存之外)某一块内存空间中,然后再进行 I/O 操作。
如果使用 DirectByteBuffer,因为数据本来就在堆外内存中,所以跟 I/O 设备交互的时候没有拷贝的过程,提升了效率,这种特性称为“零拷贝”。
那为什么操作系统一定要将数据拷贝到堆外内存呢? 这是由于write、read等函数进行系统调用时,参数传的是内存地址,而 JVM 进行 GC 时,会对 Java 堆进行碎片整理,移动对象在内存中的位置,进而导致内存地址的变化。如果在 I/O 操作进行中发生了 GC,内存地址发生变化,I/O 操作的数据就全乱套了。而堆外内存是不受 GC 控制的,因此需要把数据拷贝到堆外内存之后再进行 I/O 操作。
总结: 在 NIO 中,由于要求操作数据的内存地址在 I/O 过程中保持不变,因此需要将数据拷贝到堆外内存。FileChannel 使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆里面的 DirectByteBuffer 对象作为这块内存的直接引用进行操作,从而避免了在 Java 堆和 Native 堆中来回复制数据,在一些场景下能够显著提高性能。
JDK 源码分析
在以上分析的基础上,我们深入 JDK 的源码(JDK 1.8.0_311),进一步加深理解。
DirectByteBuffer 的分配
基本流程: 首先向 Bits 类申请内存额度,如果申请成功,调用 Unsafe 类分配内存、初始化内存。同时需要创建 cleaner,用于堆外内存的回收。
向 Bits 类申请内存额度:
这里值得注意的一点的是:如果开启 -XX:+DisableExplicitGC,System.gc() 无效,可能导致堆外内存无法有效回收,存在潜在的内存泄露风险。
判断申请额度是否超出限制:
DirectByteBuffer 的回收
DirectByteBuffer 在分配时创建的 Cleaner 继承自虚引用(PhantomReference),当 DirectByteBuffer 仅被 Cleaner 引用(即为虚引用)时,其可以在任意 GC 时段被回收。
虚引用与引用队列(ReferenceQueue)结合使用,可以实现虚引用关联对象被垃圾回收时,进行系统通知、资源清理等功能。如下图所示,当某个被 Cleaner 引用的对象将被回收时,JVM 垃圾收集器会将此对象的引用放入到对象引用中的 pending 链表中,等待 Reference-Handler 进行相关处理。其中,Reference-Handler 为一个拥有最高优先级的守护线程,会循环不断的处理 pending 链表中的对象引用,执行 Cleaner 的 clean 方法进行相关清理工作。
(来源:https://tech.meituan.com/2019/02/14/talk-about-java-magic-class-unsafe.html)
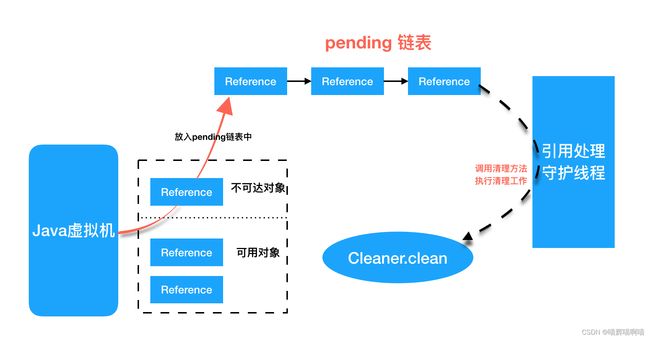
当 DirectByteBuffer 实例对象被回收时,在 Reference-Handler 线程操作中,会调用 Cleaner 的 clean 方法根据创建 Cleaner 时传入的 Deallocator 来进行堆外内存的释放(即调用 Unsafe 类释放内存,如下图所示)。

从以上源码分析中可知,堆外内存并非完全不受 GC 控制。
这里还有一种有趣的描述:虽然 DirectByteBuffer 存在于 Java 堆内的对象很小,但可能对应了一大段堆外内存,这种对象被称为“冰山对象”。这种“冰山对象”可能会引发一些问题,由于 DirectByteBuffer 对象很小,不容易被 GC 回收,占用的大块堆外内存也就不容易释放。

FileChannel 读写中 DirectByteBuffer 的分配与回收
FileChannel 使用 IOUtil 来进行读写,这里仅分析读流程,写流程与之类似。
申请临时 DirectByteBuffer:
其中,有两点值得注意:
- bufferCache 是一个 ThreadLocal 对象。
- MAX_CACHED_BUFFER_SIZE 可以通过 -Djdk.nio.maxCachedBufferSize 配置,否则会设置为 Long.MAX_VALUE。
释放或缓存临时 DirectByteBuffer:
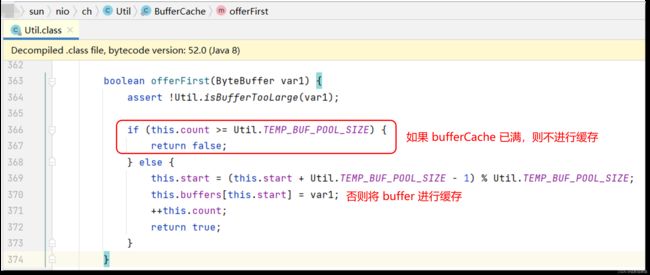
这里的 TEMP_BUF_POOL_SIZE 被设置为 IOUtil.IOV_MAX ,该值与操作系统有关,在 Linux 系统上默认值是 1024,Win10 系统该值为 16。
线上系统 OOM 的原因及解决
回到开头说的线上问题,细心的同学可能已经从上面的源码分析中发现了问题。
如果没有配置 MAX_CACHED_BUFFER_SIZE,由于其默认值非常大,所以几乎不会有直接分配的情况,而是使用 bufferCache 这个 ThreadLocal 变量来进行缓存,从而复用。这意味着,线程越多,这块临时的堆外内存缓存就越大。而在该用户场景下足足开了 80 个查询线程,用户的数据文件中数据块又比较大,所以额外分配这块堆外内存缓存导致了 OOM。
定位了问题,解决方案就呼之欲出了:
- [IOTDB-2195] 对查询线程数进行限制。
- [IOTDB-2061] 限制 FileChannel 每次读取的数据量:对于较大的数据块,分批读取,在内存中拼接返回。
- [IOTDB-2076] 限制合并生成的数据块(Chunk)大小。
- [IOTDB-2061] 通过 -Djdk.nio.maxCachedBufferSize 限制缓存的 buffer 大小。
完结撒花!
========================
Apache loTDB 是由清华大学发起的、全球领先的国际顶级开源项目,是支持物联网时序数据收集、存储、查询与分析一体化的数据管理引擎,支持“端-边-云”一体化部署,适用于高端装备管理、工厂设备、高速网联设备等多种数据管理场景,是工业互联网时序数据管理的核心基础支撑。目前已在能源电力、轨道交通、车联网等多家行业有广泛应用。
作为全球性开源项目,截至目前,Apache IoTDB已拥有 160+ 名贡献者、1.7KStar、500+ Fork。我们为大家提供了参与指南,欢迎越来越多的小伙伴助力 Apache IoTDB项目的不断发展与前进。
参与开源,可以获得公司及社区内外的认可,结交来自各个领域、志同道合的小伙伴;同时也可以提高个人影响力,促进个人发展。参与开源不是开发者的专属,社区、文档等各个方面都可以让大家发挥一技之长。
欢迎迈出加入 Apache IoTDB 社区的第一步!
QQ群:659990460
微信群:添加好友qinchuqing/tietouqiao
github仓库:https://github.com/apache/iotdb
官网:http://iotdb.apache.org/