高性能消息中间件 - Kafka3.x(一)
文章目录
-
- 高性能消息中间件 - Kafka3.x(一)
-
- 搭建Kafka3.2.1集群⭐
-
- Kafka集群机器规划
- 创建3台虚拟机(centos7系统)
- 必要的环境准备(3台虚拟机都要执行如下操作)⭐
-
- 分别修改每个服务器的hosts文件(将上面的ip和主机名配置上去)
- 分别关闭每个服务器的防火墙
- 分别为每个服务器安装jdk8
- 分别为每个服务器安装Docker
-
- 为每个节点的Docker接入阿里云镜像加速器
- 为每个节点的docker设置开机自动启动
- 分别为每个服务器安装zookeeper3.7.1(搭建zookeeper集群)⭐
- 分别为每个服务器安装Kafka3.2.1(搭建Kafka集群)⭐
- 每次重启服务器都要做的环境准备
-
- 给创建的3台服务器启动zookeeper集群
- 给创建的3台服务器启动kafka集群
- kafka的架构图
- kafka的基本概念
- Linux命令行操作⭐
-
- 命令行操作-topic(主题)⭐
-
- 查看topic命令行参数
- 查看指定kafka集群中的所有topic⭐
- 创建一个名为mytopic01的topic⭐
- 查看名为mytopic01的topic的详细描述⭐
- 修改mytopic01的分区数(注意:分区数只能增加,不能减少)⭐
- 删除名为mytopic01的topic⭐
- 命令行操作-producer(生产者)⭐
-
- 查看producer命令行参数
- 发送消息给名为mytopic01的topic⭐
- 命令行操作-consumer(消费者)⭐
-
- 查看consumer命令行参数
- 消费mytopic01主题中的数据⭐
- 消费mytopic01主题中的数据(包括历史消息)⭐
高性能消息中间件 - Kafka3.x(一)
搭建Kafka3.2.1集群⭐
Kafka集群机器规划
| IP地址 | 主机名 | 需要安装的资源 | 操作系统 |
|---|---|---|---|
| 192.168.184.201 | kafka01 | jdk、Docker、zookeeper、Kafka | centos7.9 |
| 192.168.184.202 | kafka02 | jdk、Docker、zookeeper、Kafka | centos7.9 |
| 192.168.184.203 | kafka03 | jdk、Docker、zookeeper、Kafka | centos7.9 |
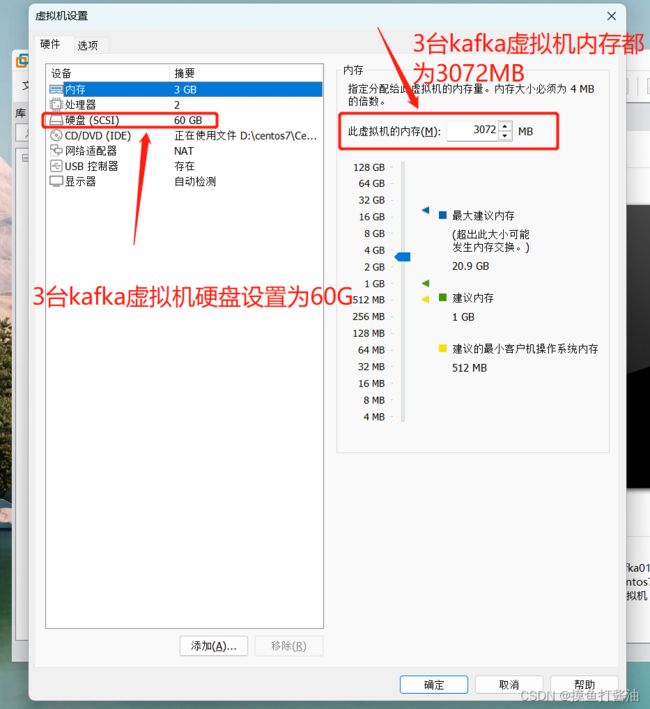
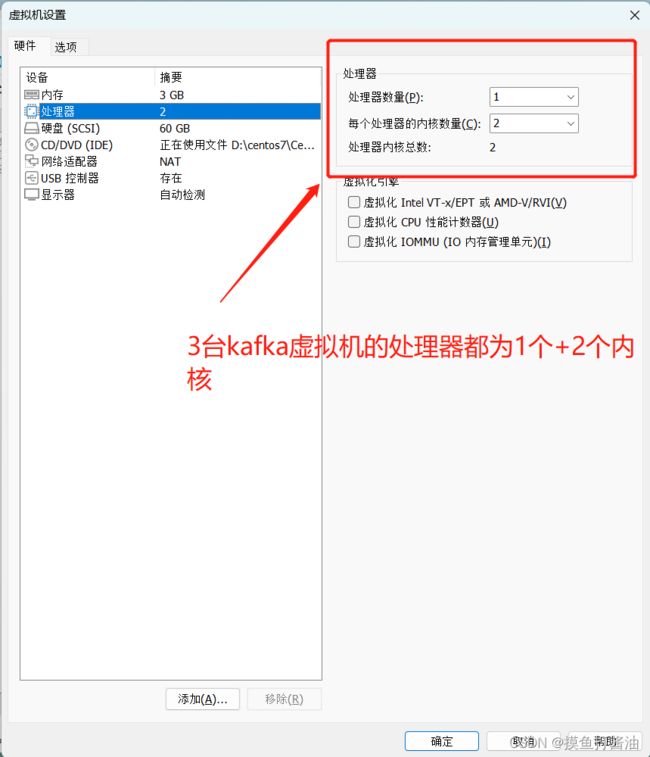
创建3台虚拟机(centos7系统)
必要的环境准备(3台虚拟机都要执行如下操作)⭐
分别修改每个服务器的hosts文件(将上面的ip和主机名配置上去)
- 1:进入hosts文件:
vi /etc/hosts
在最后面追加内容如下:(这个需要根据你自己服务器的ip来配置)
192.168.184.201 kafka01
192.168.184.202 kafka02
192.168.184.203 kafka03
分别关闭每个服务器的防火墙
systemctl stop firewalld
systemctl disable firewalld
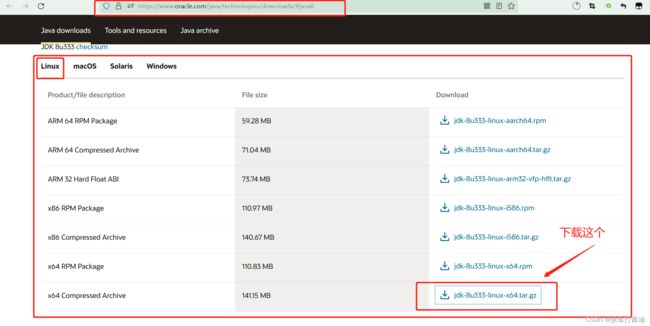
分别为每个服务器安装jdk8
- 1:进入oracle官网下载jdk8的tar.gz包:
-
2:将下载好的包上传到每个服务器上:
-
3:查看是否上传成功:
[root@kafka01 ~]# ls
anaconda-ks.cfg jdk-8u333-linux-x64.tar.gz
- 4:创建文件夹:
mkdir -p /usr/java/
- 5:解压刚刚下载好的包并输出到/usr/java目录下:
tar -zxvf jdk-8u333-linux-x64.tar.gz -C /usr/java/
[root@kafka02 ~]# ls /usr/java/
jdk1.8.0_333
- 6:配置java环境变量:
vi /etc/profile
在文件中末尾添加如下配置:(需要更改的是JAVA_HOME,根据自己的java目录名来更改)
JAVA_HOME=/usr/java/jdk1.8.0_333
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
- 7:让配置立即生效:
source /etc/profile
- 8:查看JDK是否安装成功:
[root@kafka01 ~]# java -version
java version "1.8.0_333"
Java(TM) SE Runtime Environment (build 1.8.0_333-b02)
Java HotSpot(TM) 64-Bit Server VM (build 25.333-b02, mixed mode)
分别为每个服务器安装Docker
- 1:切换镜像源
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
- 2:查看当前镜像源中支持的docker版本
yum list docker-ce --showduplicates | sort -r
- 3:安装特定版本的docker-ce
yum -y install docker-ce-3:20.10.8-3.el7.x86_64 docker-ce-cli-3:20.10.8-3.el7.x86_64 containerd.io
为每个节点的Docker接入阿里云镜像加速器
配置镜像加速器方法。
- 准备工作:
- 1:首先进入阿里云容器镜像服务 https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
- 2:点击镜像工具下面的镜像加速器
- 3:拿到你的加速器地址和下面第二步的registry-mirrors的值替换即可。
针对Docker客户端版本大于 1.10.0 的用户,可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
- 第一步:
mkdir -p /etc/docker
- 第二步:
cat <<EOF> /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://u01jo9qv.mirror.aliyuncs.com",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com"
],
"live-restore": true,
"log-driver":"json-file",
"log-opts": {"max-size":"500m", "max-file":"3"},
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 5,
"storage-driver": "overlay2"
}
EOF
- 第三步:
sudo systemctl daemon-reload
- 第四步:
sudo systemctl restart docker
最后就接入阿里云容器镜像加速器成功啦。
为每个节点的docker设置开机自动启动
sudo systemctl enable docker
分别为每个服务器安装zookeeper3.7.1(搭建zookeeper集群)⭐
- 1:创建zookeeper文件夹,并跳转到/usr/local/zookeeper目录:
mkdir -p /usr/local/zookeeper
cd /usr/local/zookeeper
- 2:在zookeeper官网上面下载zookeeper稳定版(当前为3.7.1)的tar.gz包,并上传到每个服务器上:
zookeeper官网
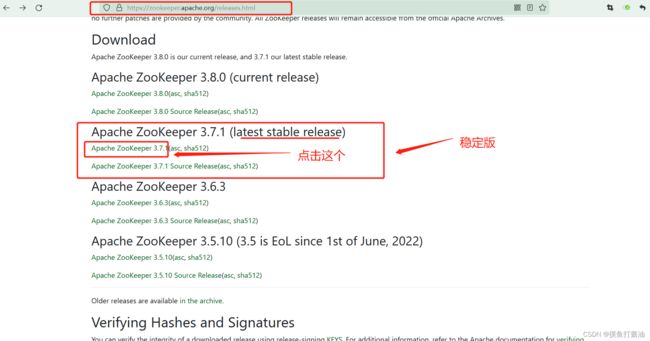
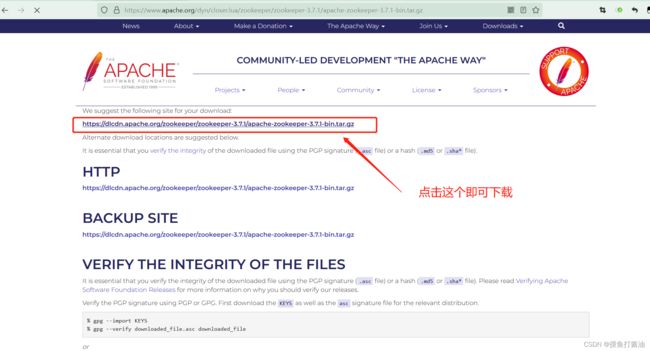
- 3:查看刚刚上传的zookeeper包:
[root@kafka01 zookeeper]# pwd
/usr/local/zookeeper
[root@kafka01 zookeeper]# ls
apache-zookeeper-3.7.1-bin.tar.gz
- 4:解压我们的zookeeper包:
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local/zookeeper
[root@kafka01 zookeeper]# ls
apache-zookeeper-3.7.1-bin apache-zookeeper-3.7.1-bin.tar.gz
- 5:配置关于zookeeper的环境变量:
vi /etc/profile
在文件中末尾添加如下配置:(ZOOKEEPER_HOME需要根据你自己的zookeeper目录来配置)
export ZOOKEEPER_HOME=/usr/local/zookeeper/apache-zookeeper-3.7.1-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH
- 6:让配置立即生效:
source /etc/profile
- 7:创建目录:
cd /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/
sudo mkdir data
- 8;添加配置:
cd conf
sudo vi zoo.cfg
内容如下:(dataDir修改成自己的目录,kafka01/02/03是我们在hosts配置的主机名映射,相当于ip)
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/apache-zookeeper-3.7.1-bin/data
clientPort=2181
server.1=kafka01:2888:3888
server.2=kafka02:2888:3888
server.3=kafka03:2888:3888
initLimit:ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。
当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。
syncLimit:配置follower和leader之间发送消息,请求和应答的最大时间长度。
tickTime:tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。
server.id=host:port1:port2 :其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。
dataDir:其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
- 9:进入data目录:
cd /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/data/
- 10:对每个服务器(kafka01、kafka02、kafka03)配置myid文件:
- 10(1):如果是kafka01服务器,则执行下面这个:(下面的1、2、3就是我们上面指定的server.id,每个zookeeper服务器都要有一个id,并且全局唯一)
echo "1" > myid
- 10(2):如果是kafka02服务器,则执行下面这个:
echo "2" > myid
- 10(3):如果是kafka03服务器,则执行下面这个
echo "3" > myid
- 11:启动zookeeper服务命令:(必须要把全部zookeeper服务器启动之后在执行下一步status命令)
cd /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/bin/
[root@kafka01 bin]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
- 12:对全部的zookeeper服务器执行查看zookeeper集群节点状态命令:(看看哪个是leader节点、哪个是follower节点)。Mode就是某一台zookeeper的角色⭐
[root@kafka01 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@kafka02 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@kafka03 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.7.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
分别为每个服务器安装Kafka3.2.1(搭建Kafka集群)⭐
- 1:进入kafka官网:
Kafka官网
- 2(下载方式1):下载当前kafka的Binary稳定版(截止到2022-08-29,稳定版本为3.2.1),下载会十分缓慢,大约要1个小时的时间(假如你的网速很慢,那么这种方式就不推荐了。):

- 2(下载方式2):使用我上传kafka_2.13-3.2.1.zip包(注意这个不是tgz包,而是zip包)(推荐这种方式),下载速度很快:
kafka3.2.1快速下载地址

- 3:解压kafka_2.13-3.2.1.zip包,拿到kafka的tgz包:

- 4:将解压好的kafka的tgz包上传到每个服务器上。
- 5:查看每个服务器上是否都已经成功上传了kafka_2.13-3.2.1.tgz包:
[root@kafka01 ~]# pwd
/root
[root@kafka01 ~]# ls | grep kafka
kafka_2.13-3.2.1.tgz
- 6:解压kafka.tgz包到/usr/local下:
tar -zxvf kafka_2.13-3.2.1.tgz -C /usr/local/
- 7:修改kafka目录:
cd /usr/local/
mv kafka_2.13-3.2.1/ kafka
-
**8:修改每个服务器的kafka配置文件:(注意:对应的机器要执行对应的命令,不是都在一台服务器执行)**⭐
- 8(1):在kafka01服务器上修改的配置文件,将下面的内容粘贴上去:⭐
[root@kafka01 local]# rm -f /usr/local/kafka/config/server.properties [root@kafka01 local]# vi /usr/local/kafka/config/server.properties内容如下:
注意下面3个地方:
①每一个kafka的broker.id都不可以一样,并且要为数字(比如0、1、2都是可以的)!
②log.dirs为你当前机器的kafka的日志数据存储目录
③zookeeper.connect:配置连接Zookeeper集群地址,下面的kafka01:2181(kafka01的意思是zk所在的服务器的ip地址,因为我们配置了hosts,所以就直接用主机名更方便;2181就是zk配置文件中的clientPort)
#broker 的全局唯一编号,不能重复,只能是数字。 broker.id=1 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/usr/local/kafka/datas #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便我们管理) zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181/kafka- 8(2):在kafka02服务器上修改的配置文件,将下面的内容粘贴上去:⭐
[root@kafka02 local]# rm -f /usr/local/kafka/config/server.properties [root@kafka02 local]# vi /usr/local/kafka/config/server.properties内容如下:
#broker 的全局唯一编号,不能重复,只能是数字。 broker.id=2 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/usr/local/kafka/datas #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便我们管理) zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181/kafka- 8(3):在kafka03服务器上修改的配置文件,将下面的内容粘贴上去:⭐
[root@kafka03 local]# rm -f /usr/local/kafka/config/server.properties [root@kafka03 local]# vi /usr/local/kafka/config/server.properties内容如下:
#broker 的全局唯一编号,不能重复,只能是数字。 broker.id=3 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/usr/local/kafka/datas #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便我们管理) zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181/kafka -
9:给每个服务器都配置kafka的环境变量:
sudo vim /etc/profile
在最后面追加的内容如下:
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
- 10:让配置立即生效:
source /etc/profile
- 11:启动zk集群。依次在 kafka01、kafka02、kafka03节点上启动zookeeper。(zk要先启动,然后再启动kafka)⭐
zkServer.sh start
- 12:后台模式启动kafka集群。依次在 kafka01、kafka02、kafka03节点上启动kafka。
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
- 13:查看kafka是否启动成功:
[root@kafka01 local]# jps
3603 Kafka
3166 QuorumPeerMain
4367 Jps
- 14:关闭kafka集群:(可以暂时不关闭,方便后面继续演示)
- 注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper
集群。
- 注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper
kafka-server-stop.sh
- 15:等kafka集群全部关闭之后再关闭zookeeper:(可以暂时不关闭,方便后面继续演示)
zkServer.sh stop
每次重启服务器都要做的环境准备
给创建的3台服务器启动zookeeper集群
zkServer.sh start
给创建的3台服务器启动kafka集群
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
kafka的架构图
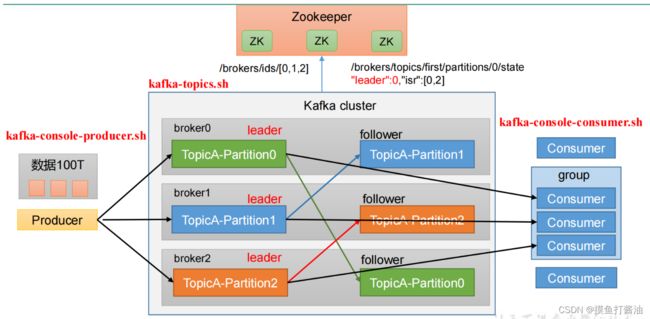
kafka的基本概念
- 1:Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
- 2:Consumer:消息消费者,向 Kafka broker 取消息的客户端。
- 3:Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- 4:Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- 5:Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- 6:Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- 7:Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- 8:Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader
- 9:Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
Linux命令行操作⭐
命令行操作-topic(主题)⭐
查看topic命令行参数
kafka-topics.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server |
指定连接的Kafka Broker服务器的主机名称和端口号 |
| –topic |
指定操作的topic名称 |
| –create | 创建topic |
| –delete | 删除topic |
| –alter | 修改topic |
| –list | 查看所有topic |
| –describe | 查看指定topic详细描述 |
| –partitions |
设置分区数 |
| –replication-factor |
设置分区副本。 |
| –config |
更新系统默认的配置 |
查看指定kafka集群中的所有topic⭐
- –bootstrap-server=kafka集群的ip(主机名)+端口
kafka-topics.sh --bootstrap-server=kafka01:9092 --list
创建一个名为mytopic01的topic⭐
创建一个名为mytopic01并且partitions(分区数)为2并且replication-factor(副本数之和leader+follower)为2的topic。
kafka-topics.sh --bootstrap-server=kafka01:9092 --partitions=2 --replication-factor=2 --topic=mytopic01 --create
查看名为mytopic01的topic的详细描述⭐
- 可以看到如下信息:
- PartitionCount(分区数):2
- ReplicationFactor(副本数):2
- segment.bytes(segment的大小):1073741824(默认是1G,用于存储data)
- 分区副本的详细信息如下:
- Partition: 0(0号分区) Leader: 2(leader副本) Replicas: 2,3(副本=leader+follower) Isr: 2,3(正常运行的副本)
- Partition: 1(1号分区) Leader: 3(leader副本) Replicas: 3,1(副本=leader+follower) Isr: 3,1(正常运行的副本)
[root@kafka01 ~]# kafka-topics.sh --bootstrap-server=kafka01:9092 --topic=mytopic01 --describe
Topic: mytopic01 TopicId: 0dMc88CfRMyxPYsgaGIgmQ PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: mytopic01 Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: mytopic01 Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3,1
修改mytopic01的分区数(注意:分区数只能增加,不能减少)⭐
kafka-topics.sh --bootstrap-server=kafka01:9092 --topic=mytopic01 --partitions=3 --alter
删除名为mytopic01的topic⭐
kafka-topics.sh --bootstrap-server=kafka01:9092 --topic=mytopic01 --delete
命令行操作-producer(生产者)⭐
查看producer命令行参数
| 参数 | 描述 |
|---|---|
| –bootstrap-server |
指定连接的Kafka Broker服务器的主机名称和端口号 |
| –topic |
指定操作的topic名称 |
发送消息给名为mytopic01的topic⭐
- 1:连接集群,并指定操作的topic(名为mytopic01)
kafka-console-producer.sh --bootstrap-server=kafka01:9092 --topic=mytopic01
- 2:此时就可以发送消息了。

命令行操作-consumer(消费者)⭐
查看consumer命令行参数
kafka-console-consumer.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server |
指定连接的Kafka Broker服务器的主机名称和端口号 |
| –-topic |
指定操作的topic名称 |
| –from-beginning | 从头开始消费 |
| –group |
指定消费者组ID(可以是中文) |
消费mytopic01主题中的数据⭐
kafka-console-consumer.sh --bootstrap-server=kafka01:9092 --topic=mytopic01
消费mytopic01主题中的数据(包括历史消息)⭐
kafka-console-consumer.sh --bootstrap-server=kafka01:9092 --topic=mytopic01 --from-beginning