布隆过滤器
1. 布隆过滤器概念
布隆过滤器(Bloom Filter)是一种空间效率很高的数据结构,用于快速检查一个元素是否存在于一个集合中。它基于哈希函数,可以快速进行元素的存在性查询,通常用于减少查询开销。

-
原理:
- 位数组: 布隆过滤器通常由一个位数组构成,初始时所有位都被置为0。
多个哈希函数: 元素被插入时,通过多个哈希函数得到多个哈希值,这些哈希值对应位数组上的位置,将这些位置的位设置为1。 - 检索: 当查询一个元素时,同样使用相同的哈希函数计算哈希值,然后检查对应的位数组位置是否都为1,若有任何一个位为0,则可以确定元素不存在。但若所有位均为1,元素“可能”存在,因为有可能其他元素设置的位值也为1。
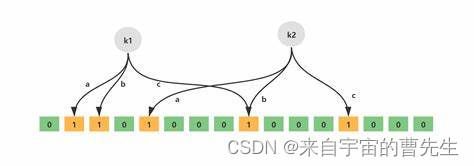
- 位数组: 布隆过滤器通常由一个位数组构成,初始时所有位都被置为0。
-
优点:
- 空间效率高: 布隆过滤器占用的空间很小,相比于其他数据结构,它需要的内存较少。
- 快速查询: 查询速度很快,时间复杂度为常数级别。
-
缺点:
- 可能误判: 由于多个元素映射到位数组上,存在一定的哈希冲突和碰撞,可能导致查询结果不准确。
- 无法删除元素: 一旦插入元素,就无法从布隆过滤器中删除,因为删除会影响其他元素对应的位。
-
应用场景:
- 缓存筛选: 可用于缓存中,快速判断某个内容是否在缓存中,避免频繁访问缓存。
- 网络爬虫: 用于爬虫系统中避免重复抓取相同的URL。
- 拦截器或防止误判系统: 可用于防止一些恶意请求或过滤某些类型的数据。
布隆过滤器是一个非常有用的数据结构,但在应用时需要考虑误判和不可删除的特性,以及如何根据具体需求选择合适的哈希函数和位数组大小。
2. 布隆过滤器应用
2.1 如何使用布隆过滤器?
使用布隆过滤器主要涉及以下几个步骤:
-
选择合适的布隆过滤器实现或库: 选择合适的数据结构或库,比如在 Java 中可使用 Google Guava 库或其他第三方实现。
-
初始化布隆过滤器: 根据预期的数据量和允许的误判率,初始化布隆过滤器。通常需要指定预期插入数量和误判率参数。
-
添加元素: 将待检测的元素使用哈希函数映射到位数组中,并将对应位置的位标记为1。
-
检查元素是否存在: 对要查询的元素进行哈希映射,检查对应的位数组位置,如果所有位置的位都为1,则该元素“可能”存在,如果有任何一个位置的位为0,则可以确定该元素不存在。
例子:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {
public static void main(String[] args) {
int expectedInsertions = 1000; // 预期插入数量
double falsePositiveProbability = 0.03; // 误判率
// 创建布隆过滤器
BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(), expectedInsertions, falsePositiveProbability
);
// 添加元素
bloomFilter.put("exampleKey1");
bloomFilter.put("exampleKey2");
// ...可以继续添加其他元素
// 检查元素是否存在
String keyToCheck = "exampleKey1";
if (bloomFilter.mightContain(keyToCheck)) {
System.out.println(keyToCheck + " 可能存在于布隆过滤器中");
// 元素可能存在,进行相应处理
} else {
System.out.println(keyToCheck + " 不存在于布隆过滤器中");
// 元素肯定不存在,采取相应操作
}
}
}
这个示例展示了如何使用 Google Guava 的布隆过滤器。
2.2 使用布隆过滤器解决缓存穿透
在 Java 中实现布隆过滤器来解决缓存穿透问题可以帮助有效地过滤掉那些确定不存在于缓存中的请求,从而减少对底层存储的频繁访问。下面是一个简单的示例,使用 Google Guava 库中的 BloomFilter 类来实现布隆过滤器:
首先,确保你已经添加了 Guava 依赖到你的项目中。
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>30.1-jreversion>
dependency>
然后,以下是一个使用 Guava 的 BloomFilter 的简单示例:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterCache {
private static final int EXPECTED_INSERTIONS = 1000; // 预期插入数量
private static final double FALSE_POSITIVE_PROBABILITY = 0.03; // 期望的误判率
private BloomFilter<String> bloomFilter;
public BloomFilterCache() {
this.bloomFilter = BloomFilter.create(
Funnels.stringFunnel(),
EXPECTED_INSERTIONS,
FALSE_POSITIVE_PROBABILITY
);
// 可以根据具体需求调整预期插入数量和误判率
}
public void addToCache(String key) {
// 将 key 加入布隆过滤器
bloomFilter.put(key);
}
public boolean mightContain(String key) {
// 检查 key 是否可能存在于布隆过滤器中
return bloomFilter.mightContain(key);
}
public static void main(String[] args) {
BloomFilterCache cache = new BloomFilterCache();
// 模拟数据插入
cache.addToCache("exampleKey1");
cache.addToCache("exampleKey2");
// ... 可以继续添加其他 key
// 模拟查询
String queryKey = "exampleKey1";
if (cache.mightContain(queryKey)) {
System.out.println(queryKey + " 可能存在于缓存中");
// 进行缓存查询逻辑
} else {
System.out.println(queryKey + " 不存在于缓存中");
// 避免缓存穿透,可以进行相应的处理(如设置空值到缓存中,避免对底层存储的频繁访问)
}
}
}
这段代码展示了如何创建一个布隆过滤器对象,将键(假设是缓存中的键)添加到布隆过滤器中,并检查某个键是否可能存在于过滤器中,从而可以在进行实际缓存查询之前避免一些确定不在缓存中的查询操作。
2.3 使用布隆过滤器作为拦截器防止恶意请求
当使用布隆过滤器作为拦截器来防止恶意请求时,你可以创建一个布隆过滤器,将已知的恶意标识(如 IP 地址、用户 ID、恶意请求内容等)添加到过滤器中,然后在收到请求时检查该请求是否被布隆过滤器识别为恶意。
下面是一个简单的 Java 示例,使用 Google Guava 库中的布隆过滤器:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.util.HashSet;
import java.util.Set;
public class MaliciousRequestInterceptor {
private BloomFilter<CharSequence> maliciousFilter;
public MaliciousRequestInterceptor() {
int expectedInsertions = 1000; // 预期插入数量
double falsePositiveProbability = 0.01; // 误判率
// 创建布隆过滤器
maliciousFilter = BloomFilter.create(
Funnels.stringFunnel(), expectedInsertions, falsePositiveProbability
);
// 假设这是一些已知的恶意请求标识,将其添加到布隆过滤器中
Set<String> knownMaliciousRequests = new HashSet<>();
knownMaliciousRequests.add("maliciousIP1");
knownMaliciousRequests.add("maliciousIP2");
// ...可以继续添加其他恶意请求标识
// 将已知的恶意请求标识添加到布隆过滤器
for (String request : knownMaliciousRequests) {
maliciousFilter.put(request);
}
}
public boolean isRequestMalicious(String request) {
// 检查请求是否被布隆过滤器标记为恶意
return maliciousFilter.mightContain(request);
}
public static void main(String[] args) {
MaliciousRequestInterceptor interceptor = new MaliciousRequestInterceptor();
// 模拟收到请求
String incomingRequest = "maliciousIP1";
if (interceptor.isRequestMalicious(incomingRequest)) {
System.out.println("请求来自恶意源,已被拦截");
// 可以采取拦截操作,比如阻止请求继续执行
} else {
System.out.println("请求未被识别为恶意");
// 继续处理正常请求
}
}
}
这个示例展示了如何创建一个简单的拦截器,用布隆过滤器识别已知的恶意请求,然后在收到请求时检查它是否被识别为恶意。根据具体的使用场景,你可以根据实际需求调整误判率和添加恶意请求标识的逻辑。
2.4 布隆过滤器实现去重数据(Redisson)
Redisson 是一个基于 Redis 的 Java 驱动,提供了许多数据结构和分布式工具,包括布隆过滤器。下面是一个使用 Redisson 中布隆过滤器来实现数据去重的简单示例:
首先,确保你已经添加了 Redisson 的依赖到你的项目中。
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.16.1version>
dependency>
然后,以下是使用 Redisson 布隆过滤器实现数据去重的示例:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class DataDeduplicationWithRedissonBloomFilter {
public static void main(String[] args) {
// 配置 Redisson 客户端连接
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379"); // 设置 Redis 地址
// 创建 Redisson 客户端
RedissonClient redisson = Redisson.create(config);
// 创建布隆过滤器,预计插入量为 10000,误差率为 0.03
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("deduplicationFilter");
bloomFilter.tryInit(10000, 0.03);
// 添加数据到布隆过滤器,模拟去重操作
bloomFilter.add("uniqueData1");
bloomFilter.add("uniqueData2");
// ...可以继续添加其他唯一数据
// 检查数据是否重复
if (bloomFilter.contains("uniqueData1")) {
System.out.println("数据 uniqueData1 已存在,是重复数据");
// 执行去重操作,这里仅做示例,具体操作根据实际场景进行
} else {
System.out.println("数据 uniqueData1 不存在,可以处理");
// 可以继续处理数据
}
// 关闭 Redisson 客户端
redisson.shutdown();
}
}
这个示例展示了如何使用 Redisson 中的布隆过滤器实现数据去重。根据实际需求,你可以根据预期插入量和误差率设置布隆过滤器,并使用 add() 方法添加唯一数据。使用 contains() 方法来检查数据是否重复,以避免处理已存在的数据。